Recognition: no theorem link
QASecClaw: A Multi-Agent LLM Approach for False Positive Reduction in Static Application Security Testing
Pith reviewed 2026-05-10 15:56 UTC · model grok-4.3
The pith
A multi-agent system of LLM reviewers filters false positives from static security scans with little loss in true detections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
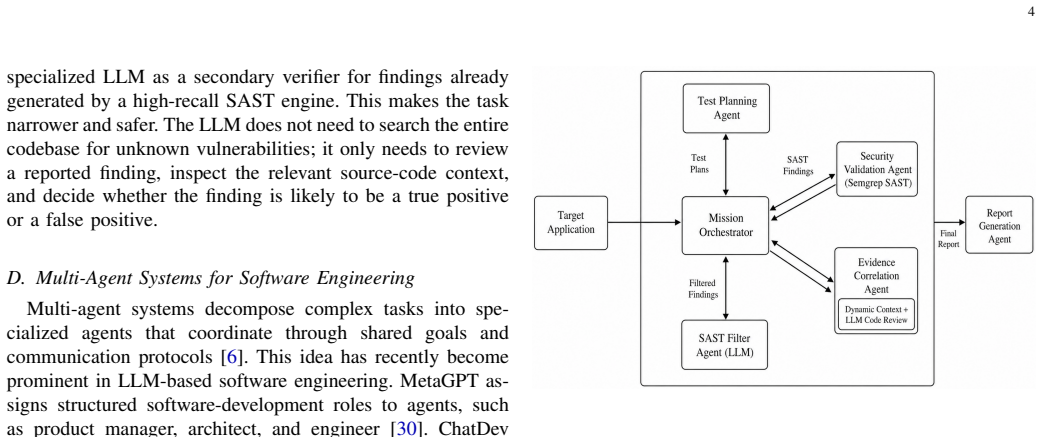
QASecClaw first runs a conventional SAST engine to generate candidate vulnerability reports, then routes each report to a set of LLM-based agents that review the relevant code context and classify the finding as a probable true positive or false positive. A central Mission Orchestrator manages the workflow across specialized agents responsible for test planning, security validation, evidence correlation, filtering decisions, and reporting. The result is a marked drop in erroneous reports with only a small accompanying drop in the ability to surface genuine vulnerabilities.
What carries the argument
The multi-agent architecture in which a Mission Orchestrator coordinates an SAST Filter Agent and supporting agents that together review source code context to classify scanner findings.
If this is right
- Static security reports become more actionable because developers encounter fewer irrelevant alerts.
- The same multi-agent filtering layer can be attached to other SAST engines to improve their output quality.
- Development teams may adopt automated scanning more readily once the signal-to-noise ratio improves.
- The separation of concerns across specialized agents allows targeted improvements to individual review steps without redesigning the entire pipeline.
Where Pith is reading between the lines
- The approach could be tested on code written in languages other than Java to determine whether the filtering gains transfer.
- Agents might later be extended to propose concrete code changes for the issues they confirm as real.
- Integration into continuous integration pipelines could allow the filtering step to run automatically on every commit.
Load-bearing premise
LLM agents can correctly separate real vulnerabilities from scanner mistakes using only the supplied code snippets and general security knowledge, without introducing systematic misclassifications on the tested types of issues.
What would settle it
Applying the same agent workflow to a fresh collection of codebases whose true vulnerability status has been established by independent manual audits and checking whether the false-positive reduction persists or new classification errors appear.
Figures






read the original abstract
Static Application Security Testing tools help developers find security vulnerabilities before release, but they often produce many false positives. This increases manual review effort, reduces developer trust, and may cause real vulnerabilities to be ignored among noisy reports. We present QASecClaw, a multi agent approach that combines conventional Static Application Security Testing with coding specialized Large Language Model based contextual code review. A SAST engine first reports candidate vulnerabilities, and a Large Language Model based SAST Filter Agent then reviews each finding with source code context to decide whether it is likely to be a true positive or a false positive. QASecClaw is coordinated by a Mission Orchestrator and includes specialized agents for test planning, security validation, evidence correlation, filtering, and reporting. We evaluate QASecClaw on OWASP Benchmark v1.2, which contains 2,740 Java test cases across 11 Common Weakness Enumeration categories with ground truth labels. QASecClaw achieves an F1 score of 90.93 percent, compared with 78.39 percent for standalone Semgrep. The improvement is mainly driven by an 88.6 percent reduction in false positives, from 560 to 64, with only a 3.1 percent reduction in recall. These results show that Large Language Model augmented multi agent verification can make Static Application Security Testing output more accurate, useful, and trustworthy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces QASecClaw, a multi-agent LLM framework to reduce false positives in Static Application Security Testing (SAST). It uses a SAST engine like Semgrep to generate candidate vulnerabilities, followed by LLM-based agents for contextual review and filtering. Evaluated on the OWASP Benchmark v1.2 comprising 2,740 Java test cases across 11 CWE categories, QASecClaw achieves an F1 score of 90.93%, outperforming standalone Semgrep's 78.39%, primarily through an 88.6% reduction in false positives (560 to 64) with a small 3.1% recall drop.
Significance. If the performance gains are robust and generalizable, this work could substantially enhance the practicality of SAST tools by minimizing developer review effort and improving trust in automated security analysis. The multi-agent orchestration with specialized roles for planning, validation, and filtering represents an innovative application of LLMs to security verification tasks. The evaluation on a public benchmark with ground truth labels provides a solid empirical foundation.
major comments (3)
- [Evaluation section] The central performance claims (F1 90.93% vs. 78.39%, FP reduction 560→64) are presented in aggregate only. No breakdown by the 11 CWE categories is provided, nor any error analysis of the 3.1% recall loss or the remaining 64 false positives. This makes it difficult to determine whether the LLM filter performs consistently across vulnerability types or if gains are concentrated in categories where false positives are easier to identify.
- [Methods / Agent Design] The description of the SAST Filter Agent and other specialized agents lacks the actual prompts, decision criteria, or examples of reasoning traces used for classifying findings as true or false positives. Without this, it is impossible to assess reproducibility, potential for hallucination, or whether the system relies on benchmark-specific patterns rather than general security knowledge.
- [Evaluation section] No details are given on controls for LLM variability, such as the number of runs, temperature settings, or statistical significance testing of the reported metrics. This is critical for claims involving stochastic LLM components.
minor comments (1)
- [Abstract] The abstract mentions 'coding specialized Large Language Model' but does not specify which LLM or model version is used, which should be clarified for context.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We appreciate the opportunity to improve the clarity and rigor of our work. Below we respond point-by-point to the major comments, indicating the specific revisions we will incorporate.
read point-by-point responses
-
Referee: [Evaluation section] The central performance claims (F1 90.93% vs. 78.39%, FP reduction 560→64) are presented in aggregate only. No breakdown by the 11 CWE categories is provided, nor any error analysis of the 3.1% recall loss or the remaining 64 false positives. This makes it difficult to determine whether the LLM filter performs consistently across vulnerability types or if gains are concentrated in categories where false positives are easier to identify.
Authors: We agree that aggregate metrics alone limit interpretability. In the revised manuscript we will add a new table in the Evaluation section reporting precision, recall, and F1-score broken down by each of the 11 CWE categories for both QASecClaw and the Semgrep baseline. We will also include a concise error analysis characterizing the 3.1% recall loss (e.g., which vulnerability types were most affected) and the nature of the remaining 64 false positives that survived filtering. This addition will allow readers to assess consistency across categories. revision: yes
-
Referee: [Methods / Agent Design] The description of the SAST Filter Agent and other specialized agents lacks the actual prompts, decision criteria, or examples of reasoning traces used for classifying findings as true or false positives. Without this, it is impossible to assess reproducibility, potential for hallucination, or whether the system relies on benchmark-specific patterns rather than general security knowledge.
Authors: We acknowledge that the absence of the concrete prompts and reasoning examples hinders reproducibility assessment. In the revised paper we will expand the Methods section and add an appendix containing the full system prompts for the SAST Filter Agent, Mission Orchestrator, and supporting agents, together with the decision criteria and two representative reasoning traces (one true-positive confirmation and one false-positive rejection). These additions will enable direct evaluation of hallucination risk and generality. revision: yes
-
Referee: [Evaluation section] No details are given on controls for LLM variability, such as the number of runs, temperature settings, or statistical significance testing of the reported metrics. This is critical for claims involving stochastic LLM components.
Authors: We agree that explicit controls for stochasticity are necessary. In the revised Evaluation section we will document the exact LLM configuration (model version, temperature setting, and any other sampling parameters), state the number of independent runs performed, and report statistical significance testing (e.g., McNemar’s test or bootstrap confidence intervals) comparing QASecClaw against the baseline. If additional runs are required to compute these statistics, they will be conducted and the results included. revision: yes
Circularity Check
No circularity: purely empirical evaluation on external benchmark
full rationale
The paper describes a multi-agent LLM system for filtering SAST false positives and reports direct performance measurements (F1, FP count, recall) on the OWASP Benchmark v1.2 against the Semgrep baseline. No equations, fitted parameters, self-referential predictions, or load-bearing self-citations appear in the provided text. The central claims rest on observable outcomes from ground-truth-labeled test cases rather than any derivation that reduces to its own inputs by construction. This is a standard empirical comparison with no detectable circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can accurately classify SAST findings as true or false positives using source code context
Reference graph
Works this paper leans on
-
[1]
2023 official cybercrime report,
S. Morgan, “2023 official cybercrime report,” Cybersecurity Ventures, Tech. Rep., 2023
2023
-
[2]
Chess and J
B. Chess and J. West,Secure Programming with Static Analysis. Addison-Wesley Professional, 2007
2007
-
[3]
Why don’t software developers use static analysis tools to find bugs?
B. Johnson, Y . Song, E. Murphy-Hill, and R. Bowdidge, “Why don’t software developers use static analysis tools to find bugs?” inPro- ceedings of the 35th International Conference on Software Engineering (ICSE), 2013, pp. 672–681
2013
-
[4]
Tricorder: Building a program analysis ecosystem,
C. Sadowski, J. van Gogh, C. Jaspan, E. Söderberg, and C. Winter, “Tricorder: Building a program analysis ecosystem,” inProceedings of the 37th IEEE/ACM International Conference on Software Engineering (ICSE), 2015, pp. 598–608
2015
-
[5]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pintoet al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Wooldridge,An Introduction to MultiAgent Systems, 2nd ed
M. Wooldridge,An Introduction to MultiAgent Systems, 2nd ed. Wiley, 2009
2009
-
[7]
Semgrep: Lightweight static analysis for many languages,
Semgrep, “Semgrep: Lightweight static analysis for many languages,” https://semgrep.dev, 2023
2023
-
[8]
SonarQube,
SonarSource, “SonarQube,” https://www.sonarsource.com/products/ sonarqube/, 2023
2023
-
[9]
SpotBugs: Find bugs in Java programs,
SpotBugs Team, “SpotBugs: Find bugs in Java programs,” https:// spotbugs.github.io/, 2023
2023
-
[10]
The Soot framework for Java program analysis: A retrospective,
P. Lam, E. Bodden, O. Lhoták, and L. Hendren, “The Soot framework for Java program analysis: A retrospective,” inCetus Users and Compiler Infrastructure Workshop, 2011
2011
-
[11]
Software verification with validation of results,
D. Beyer, “Software verification with validation of results,” inPro- ceedings of the International Conference on Tools and Algorithms for Construction and Analysis of Systems (TACAS), 2017, pp. 331–349
2017
-
[12]
A systematic literature review of action- able alert identification techniques for automated static code analysis,
S. Heckman and L. Williams, “A systematic literature review of action- able alert identification techniques for automated static code analysis,” Information and Software Technology, vol. 53, no. 4, pp. 363–387, 2011. 10
2011
-
[13]
Prioritizing alerts from multiple static analysis tools, using classification models,
L. Flynn, W. Snavely, D. Svoboda, N. VanHoudnos, R. Qin, J. Burns, D. Zubrow, R. Stoddard, and G. Marce-Santurio, “Prioritizing alerts from multiple static analysis tools, using classification models,” in Proceedings of the IEEE/ACM 1st International Workshop on Software Engineering for Smart Cyber-Physical Systems, 2018, pp. 13–20
2018
-
[14]
Learning a classifier for false positive error reports emitted by static code analysis tools,
U. Koç, P. Saadatpanah, J. S. Foster, and A. A. Porter, “Learning a classifier for false positive error reports emitted by static code analysis tools,” inProceedings of the 1st ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, 2017, pp. 35–42
2017
-
[15]
VulDeePecker: A deep learning-based system for vulnerability detec- tion,
Z. Li, D. Zou, S. Xu, X. Ou, H. Jin, S. Wang, Z. Deng, and Y . Zhong, “VulDeePecker: A deep learning-based system for vulnerability detec- tion,” inProceedings of the Network and Distributed System Security Symposium (NDSS), 2018
2018
-
[16]
µVulDeePecker: A deep learning-based system for multiclass vulnerability detection,
D. Zou, S. Wang, S. Xu, Z. Li, and H. Jin, “µVulDeePecker: A deep learning-based system for multiclass vulnerability detection,”IEEE Transactions on Dependable and Secure Computing, vol. 18, no. 5, pp. 2224–2236, 2021
2021
-
[17]
Devign: Effective vul- nerability identification by learning comprehensive program semantics via graph neural networks,
Y . Zhou, S. Liu, J. Siow, X. Du, and Y . Liu, “Devign: Effective vul- nerability identification by learning comprehensive program semantics via graph neural networks,” inProceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS), 2019
2019
-
[18]
LineVul: A transformer-based line- level vulnerability prediction,
M. Fu and C. Tantithamthavorn, “LineVul: A transformer-based line- level vulnerability prediction,” inProceedings of the 19th IEEE/ACM International Conference on Mining Software Repositories (MSR), 2022, pp. 608–620
2022
-
[19]
Deep learning based vulnerability detection: Are we there yet?
S. Chakraborty, R. Krishna, Y . Ding, and B. Ray, “Deep learning based vulnerability detection: Are we there yet?”IEEE Transactions on Software Engineering, vol. 48, no. 9, pp. 3280–3296, 2022
2022
-
[20]
An empirical study of deep learning models for vulnerability detection,
B. Steenhoek, M. M. Rahman, R. Jiles, and W. Le, “An empirical study of deep learning models for vulnerability detection,” inProceedings of the 45th IEEE/ACM International Conference on Software Engineering (ICSE), 2023, pp. 2237–2248
2023
-
[21]
CodeBERT: A pre-trained model for programming and natural languages,
Z. Feng, D. Guo, D. Tang, N. Duan, X. Feng, M. Gong, L. Shou, B. Qin, T. Liu, D. Jiang, and M. Zhou, “CodeBERT: A pre-trained model for programming and natural languages,” inFindings of the Association for Computational Linguistics: EMNLP, 2020, pp. 1536–1547
2020
-
[22]
Code Llama: Open Foundation Models for Code
B. Rozièreet al., “Code Llama: Open foundation models for code,” arXiv preprint arXiv:2308.12950, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
A. Yanget al., “Qwen2 technical report,”arXiv preprint arXiv:2407.10671, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Examining zero-shot vulnerability repair with large language models,
H. Pearce, B. Ahmad, B. Tan, B. Dolan-Gavitt, and R. Karri, “Examining zero-shot vulnerability repair with large language models,” inProceed- ings of the IEEE Symposium on Security and Privacy (S&P), 2023, pp. 2339–2356
2023
-
[25]
Automated program repair in the era of large pre-trained language models,
C. S. Xia, Y . Wei, and L. Zhang, “Automated program repair in the era of large pre-trained language models,” inProceedings of the 45th IEEE/ACM International Conference on Software Engineering (ICSE), 2023, pp. 1482–1494
2023
-
[26]
The hitchhiker’s guide to program analysis: A journey with large language models,
H. Li, Y . Hao, Y . Zhai, and Z. Qian, “The hitchhiker’s guide to program analysis: A journey with large language models,”arXiv preprint arXiv:2308.00245, 2023
-
[27]
Understanding the effectiveness of large language models in detecting security vulnerabilities,
A. Khare, S. Dutta, Z. Li, A. Solko-Breslin, R. Alur, and M. Naik, “Understanding the effectiveness of large language models in detecting security vulnerabilities,”arXiv preprint arXiv:2311.16169, 2023
-
[28]
Evaluation of ChatGPT model for vulnerability detection,
A. Cheshkov, P. Zadorozhny, and R. Levichev, “Evaluation of ChatGPT model for vulnerability detection,”arXiv preprint arXiv:2304.07232, 2023
-
[29]
LLM4Vuln: A Unified Evaluation Framework for Decoupling and Enhancing LLMs’ Vulnerability Reasoning,
Y . Sun, D. Wu, Y . Xue, H. Liu, H. Wang, Z. Xu, X. Xie, and Y . Liu, “LLM4Vuln: A unified evaluation framework for decou- pling and enhancing LLMs’ vulnerability reasoning,”arXiv preprint arXiv:2401.16185, 2024
-
[30]
MetaGPT: Meta programming for a multi-agent collaborative framework,
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, J. Wang, C. Zhang, Z. Wang, S. K. S. Yau, Z. Lin, L. Zhou, C. Ran, L. Xiao, C. Wu, and J. Schmidhuber, “MetaGPT: Meta programming for a multi-agent collaborative framework,” inProceedings of the 12th International Conference on Learning Representations (ICLR), 2024
2024
-
[31]
ChatDev: Communicative agents for software development,
C. Qian, W. Liu, H. Liu, N. Chen, Y . Dang, J. Li, C. Yang, W. Chen, Y . Su, X. Cong, J. Xu, D. Li, Z. Liu, and M. Sun, “ChatDev: Communicative agents for software development,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024, pp. 15 174–15 186
2024
-
[32]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, A. H. Awadallah, R. W. White, D. Burger, and C. Wang, “AutoGen: Enabling next-gen LLM applications via multi- agent conversation,”arXiv preprint arXiv:2308.08155, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
OW ASP benchmark project,
OW ASP Foundation, “OW ASP benchmark project,” https://owasp.org/ www-project-benchmark/, 2023
2023
-
[34]
Evaluating bug finders—test and measurement of static code analyzers,
A. M. Delaitre, B. C. Stivalet, E. Fong, and V . Okun, “Evaluating bug finders—test and measurement of static code analyzers,” inProceedings of the IEEE/ACM 1st International Workshop on Complex Faults and Failures in Large Software Systems (COUFLESS), 2015, pp. 14–20
2015
-
[35]
Index for rating diagnostic tests,
W. J. Youden, “Index for rating diagnostic tests,”Cancer, vol. 3, no. 1, pp. 32–35, 1950
1950
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.