Recognition: unknown
LLM-Augmented Semantic Steering of Text Embedding Projection Spaces
Pith reviewed 2026-05-09 16:07 UTC · model grok-4.3
The pith
Grouping a few example documents lets an LLM steer text embedding projections to match an analyst's intended semantic structures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
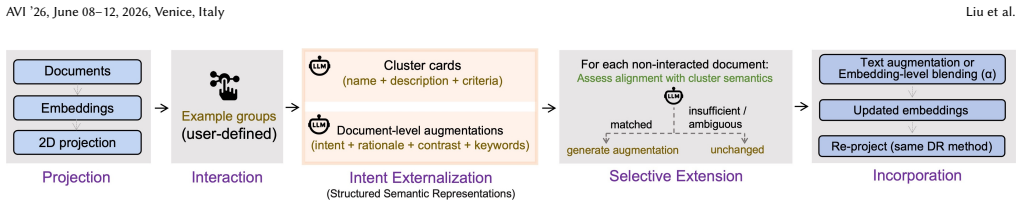
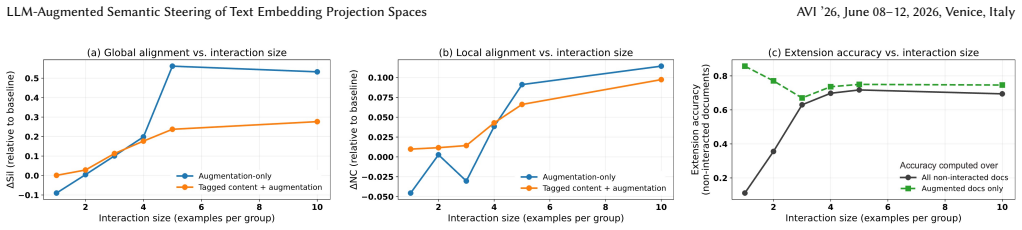
LLM-augmented semantic steering enables analysts to express semantic intent by grouping a small set of example documents within the projection. A large language model externalizes this intent as natural-language representations and selectively extends it to related documents. The semantic information is then incorporated into document representations via text augmentation or embedding-level blending without retraining the underlying models. A case study illustrates how the same corpus can be reorganized from different semantic perspectives, while simulation-based evaluation shows that semantic steering improves global and local alignment with target semantic structures using only minimal 0.5
What carries the argument
LLM-augmented semantic steering, in which small user-provided document groupings are converted by a large language model into extended semantic representations that are blended back into the original embeddings or texts.
If this is right
- The same corpus can be reorganized from different semantic perspectives without retraining models.
- Global and local alignment with target semantic structures improves using only minimal interaction.
- Embedding-level blending enables continuous and controllable steering of projection layouts.
- Projection spaces function as intent-dependent semantic workspaces reshaped through explicit, interpretable, language-mediated interaction.
Where Pith is reading between the lines
- Analysts could rapidly test alternative semantic hypotheses by switching between different example groupings in the same projection space.
- The technique might combine with existing visual analytics systems to support more flexible exploration of high-dimensional document collections.
- Embedding-level blending could allow smooth, real-time adjustment of layouts as user intent evolves during an analysis session.
Load-bearing premise
A large language model can reliably externalize semantic intent from small document groupings and extend it accurately to other documents without introducing biases or errors that degrade projection quality.
What would settle it
A simulation in which the LLM is replaced by random or deliberately incorrect semantic extensions and the resulting projections show no improvement or a decline in alignment metrics relative to the unsteered baseline.
Figures


read the original abstract
Low-dimensional projections of text embeddings support visual analysis of document collections, but their spatial organization may not reflect the relationships an analyst intends to examine. Existing semantic interaction approaches encode semantic intent indirectly through geometric constraints or model updates, limiting interpretability and flexibility. We introduce LLM-augmented semantic steering, which enables analysts to express semantic intent by grouping a small set of example documents within the projection. A large language model externalizes this intent as natural-language representations and selectively extends it to related documents; the resulting semantic information is then incorporated into document representations via text augmentation or embedding-level blending, without retraining the underlying models. A case study illustrates how the same corpus can be reorganized from different semantic perspectives, while simulation-based evaluation shows that semantic steering improves global and local alignment with target semantic structures using only minimal interaction. Embedding-level blending further enables continuous and controllable steering of projection layouts. These results position projection spaces as intent-dependent semantic workspaces that can be reshaped through explicit, interpretable, language-mediated interaction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LLM-augmented semantic steering for low-dimensional projections of text embeddings. Analysts express semantic intent via small groupings of example documents; an LLM externalizes this as natural-language representations and extends it to other documents. The resulting information is incorporated via text augmentation or embedding-level blending without retraining underlying models. A case study shows the same corpus reorganized under different semantic perspectives, while simulation-based evaluation reports improved global and local alignment with target semantic structures using minimal interaction. Embedding-level blending enables continuous, controllable steering of projection layouts.
Significance. If the results hold, the work could meaningfully advance visual analytics and semantic interaction in HCI by providing an interpretable, language-mediated alternative to geometric-constraint or model-update approaches. Treating projection spaces as intent-dependent semantic workspaces that can be reshaped with minimal analyst input and no retraining has clear practical value for document-collection exploration.
major comments (2)
- [Simulation evaluation] Simulation evaluation section: the paper must explicitly describe how the 'target semantic structures' are constructed and whether they are generated independently of the LLM pipeline used for steering. If targets rely on the same LLM externalization or validation step, measured alignment improvements become vulnerable to LLM-specific biases (hallucination, overgeneralization, prompt sensitivity), rendering the simulation results non-diagnostic for the central claim of faithful intent transfer. This is load-bearing for the simulation claims.
- [Method] Method section on embedding-level blending: the description of how blending is performed and how the continuous control parameter is defined lacks sufficient technical detail (e.g., no equation or pseudocode) to allow replication or assessment of whether the blending truly operates on potentially corrupted extended representations without introducing additional distortions.
minor comments (2)
- [Abstract] Abstract: quantitative metrics, baselines, and error analysis used in the simulation evaluation are not mentioned, which weakens the reader's ability to gauge the strength of the reported improvements.
- [Case study] Case study: the qualitative illustrations would benefit from at least one quantitative comparison (e.g., alignment scores before/after steering) to complement the visual examples.
Simulated Author's Rebuttal
Thank you for your thorough and constructive review of our manuscript. We appreciate the identification of areas where additional clarity is needed and address each major comment point by point below. We will incorporate revisions to strengthen the paper accordingly.
read point-by-point responses
-
Referee: [Simulation evaluation] Simulation evaluation section: the paper must explicitly describe how the 'target semantic structures' are constructed and whether they are generated independently of the LLM pipeline used for steering. If targets rely on the same LLM externalization or validation step, measured alignment improvements become vulnerable to LLM-specific biases (hallucination, overgeneralization, prompt sensitivity), rendering the simulation results non-diagnostic for the central claim of faithful intent transfer. This is load-bearing for the simulation claims.
Authors: We agree that explicit description of target construction is essential to substantiate the simulation claims. The target semantic structures in our evaluation are constructed from independent human-annotated semantic groupings that were collected separately from and without any involvement of the LLM externalization or validation steps used in the steering pipeline. These targets represent ground-truth organizations provided by domain experts. We will revise the Simulation Evaluation section to include a detailed, explicit account of this construction process and its independence from the LLM components, thereby confirming that the measured improvements are diagnostic of intent transfer rather than LLM-specific artifacts. revision: yes
-
Referee: [Method] Method section on embedding-level blending: the description of how blending is performed and how the continuous control parameter is defined lacks sufficient technical detail (e.g., no equation or pseudocode) to allow replication or assessment of whether the blending truly operates on potentially corrupted extended representations without introducing additional distortions.
Authors: We concur that greater technical detail is required for reproducibility and to allow assessment of the blending mechanism. We will revise the Method section to include a formal equation defining the embedding-level blending operation (e.g., as a convex combination controlled by the continuous parameter α) along with pseudocode for the full procedure. The revision will also explicitly discuss how the blending is applied to the LLM-extended representations and why it does not introduce additional distortions beyond those already present in the extensions. revision: yes
Circularity Check
No significant circularity; method and evaluation presented as independent
full rationale
The paper proposes LLM-augmented semantic steering as a new technique: analysts provide small groupings, LLM externalizes natural-language representations, and these are incorporated via text augmentation or embedding blending. Simulation evaluation measures improved global/local alignment with target semantic structures. No equations, self-citations, or definitions are provided in the available text that reduce any central claim to a fit or prior self-result by construction. The approach is self-contained against external simulation benchmarks and case studies, consistent with a normal non-finding of circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can accurately capture and extend semantic intent from small sets of grouped documents without systematic bias or error.
Reference graph
Works this paper leans on
-
[1]
Daniel Atzberger, Tim Barz-Cech, Willy Scheibel, Jürgen Döllner, and Tobias Schreck. 2026. Evaluating text embeddings for two-dimensional text corpora representations.Information Visualization25, 1 (2026), 3–20. LLM-Augmented Semantic Steering of Text Embedding Projection Spaces AVI ’26, June 08–12, 2026, Venice, Italy
2026
-
[2]
Yali Bian and Chris North. 2021. Deepsi: Interactive deep learning for semantic interaction. In26th International Conference on Intelligent User Interfaces. 197–207
2021
-
[3]
Yali Bian, John Wenskovitch, and Chris North. 2019. Deepva: Bridging cogni- tion and computation through semantic interaction and deep learning. In2019 IEEE Workshop on Machine Learning from User Interaction for Visualization and Analytics (MLUI). IEEE, 1–10
2019
-
[4]
Lauren Bradel, Chris North, Leanna House, and Scotland Leman. 2014. Multi- model semantic interaction for text analytics. In2014 IEEE Conference on Visual Analytics Science and Technology (V AST). IEEE, 163–172
2014
-
[5]
Eli T Brown, Jingjing Liu, Carla E Brodley, and Remco Chang. 2012. Dis-function: Learning distance functions interactively. In2012 IEEE conference on visual ana- lytics science and technology (V AST). IEEE, 83–92
2012
-
[6]
Michelle Dowling, John Wenskovitch, JT Fry, Leanna House, and Chris North
-
[7]
SIRIUS: Dual, symmetric, interactive dimension reductions.IEEE transac- tions on visualization and computer graphics25, 1 (2018), 172–182
2018
-
[8]
Michelle Dowling, John Wenskovitch, Peter Hauck, Adam Binford, Nicholas Polys, and Chris North. 2018. A bidirectional pipeline for semantic interaction. In 2018 IEEE Workshop on Machine Learning from User Interaction for Visualization and Analytics (MLUI). IEEE, 1–11
2018
-
[9]
Michelle Dowling, Nathan Wycoff, Brian Mayer, John Wenskovitch, Leanna House, Nicholas Polys, Chris North, and Peter Hauck. 2019. Interactive visual analytics for sensemaking with big text.Big Data Research16 (2019), 49–58
2019
-
[10]
Mennatallah El-Assady, Rebecca Kehlbeck, Christopher Collins, Daniel Keim, and Oliver Deussen. 2019. Semantic concept spaces: Guided topic model refine- ment using word-embedding projections.IEEE transactions on visualization and computer graphics26, 1 (2019), 1001–1011
2019
-
[11]
Alex Endert, Patrick Fiaux, and Chris North. 2012. Semantic interaction for visual text analytics. InProceedings of the SIGCHI conference on Human factors in computing systems. 473–482
2012
-
[12]
Alex Endert, Seth Fox, Dipayan Maiti, Scotland Leman, and Chris North. 2012. The semantics of clustering: analysis of user-generated spatializations of text documents. InProceedings of the International Working Conference on Advanced Visual Interfaces. 555–562
2012
-
[13]
Jie Gao, Simret Araya Gebreegziabher, Kenny Tsu Wei Choo, Toby Jia-Jun Li, Simon Tangi Perrault, and Thomas W Malone. 2024. A taxonomy for human- llm interaction modes: An initial exploration. InExtended Abstracts of the CHI Conference on Human Factors in Computing Systems. 1–11
2024
-
[14]
Sebastian Gehrmann, Hendrik Strobelt, Robert Krüger, Hanspeter Pfister, and Alexander M Rush. 2019. Visual interaction with deep learning models through collaborative semantic inference.IEEE transactions on visualization and computer graphics26, 1 (2019), 884–894
2019
-
[15]
Huimin Han, Rebecca Faust, Brian Felipe Keith Norambuena, Jiayue Lin, Song Li, and Chris North. 2023. Explainable interactive projections of images.Machine Vision and Applications34, 6 (2023), 100
2023
-
[16]
Zeyang Huang, Daniel Witschard, Kostiantyn Kucher, and Andreas Kerren. 2023. VA+ Embeddings STAR: A State-of-the-Art Report on the Use of Embeddings in Visual Analytics. InComputer Graphics Forum, Vol. 42. Wiley Online Library, 539–571
2023
-
[17]
IEEE VIS. 2026. IEEE Visualization and Visual Analytics Conference (VIS). https: //ieeevis.org/. Accessed: 2026-01-23
2026
- [18]
-
[19]
Brian Felipe Keith Norambuena, Tanushree Mitra, and Chris North. 2023. Mixed multi-model semantic interaction for graph-based narrative visualizations. In Proceedings of the 28th International Conference on Intelligent User Interfaces. 866–888
2023
-
[20]
Phillip Keung, Yichao Lu, György Szarvas, and Noah A Smith. 2020. The multi- lingual amazon reviews corpus. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP). 4563–4568
2020
- [21]
-
[22]
Jie Li and Chun-qi Zhou. 2022. Incorporation of human knowledge into data em- beddings to improve pattern significance and interpretability.IEEE Transactions on Visualization and Computer Graphics29, 1 (2022), 723–733
2022
-
[23]
Jiayue Lin, Rebecca Faust, and Chris North. 2024. ImageSI: Semantic Interaction for Deep Learning Image Projections. In2024 IEEE Visualization and Visual Analytics (VIS). IEEE, 91–95
2024
- [24]
-
[25]
Leland McInnes, John Healy, and James Melville. 2018. Umap: Uniform man- ifold approximation and projection for dimension reduction.arXiv preprint arXiv:1802.03426(2018)
work page internal anchor Pith review arXiv 2018
- [26]
-
[27]
OpenAI. 2026. OpenAI API Documentation. https://platform.openai.com/docs. Accessed: 2026-01-23
2026
-
[28]
Peter J Rousseeuw. 1987. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis.Journal of computational and applied mathematics 20 (1987), 53–65
1987
-
[29]
Dominik Sacha, Leishi Zhang, Michael Sedlmair, John A Lee, Jaakko Peltonen, Daniel Weiskopf, Stephen C North, and Daniel A Keim. 2016. Visual interaction with dimensionality reduction: A structured literature analysis.IEEE transactions on visualization and computer graphics23, 1 (2016), 241–250
2016
-
[30]
Jessica Zeitz Self, Michelle Dowling, John Wenskovitch, Ian Crandell, Ming Wang, Leanna House, Scotland Leman, and Chris North. 2018. Observation-level and parametric interaction for high-dimensional data analysis.ACM Transactions on Interactive Intelligent Systems (TiiS)8, 2 (2018), 1–36
2018
-
[31]
Priyan Vaithilingam, Munyeong Kim, Frida-Cecilia Acosta-Parenteau, Daniel Lee, Amine Mhedhbi, Elena L Glassman, and Ian Arawjo. 2025. Semantic Commit: Helping Users Update Intent Specifications for AI Memory at Scale. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology. 1–18
2025
- [32]
-
[33]
Zehuan Wang, Jiaqi Xiao, Jingwei Sun, and Can Liu. 2025. IntentPrism: Human-AI Intent Manifestation for Web Information Foraging. InProceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems. 1–11
2025
-
[34]
Jiafu Wei, Ding Xia, Haoran Xie, Chia-Ming Chang, Chuntao Li, and Xi Yang
-
[35]
InProceedings of the 29th International Conference on Intelligent User Interfaces
SpaceEditing: A Latent Space Editing Interface for Integrating Human Knowledge into Deep Neural Networks. InProceedings of the 29th International Conference on Intelligent User Interfaces. 489–503
-
[36]
Shujin Wu, Yi R Fung, Cheng Qian, Jeonghwan Kim, Dilek Hakkani-Tur, and Heng Ji. 2025. Aligning llms with individual preferences via interaction. In Proceedings of the 31st International Conference on Computational Linguistics. 7648–7662
2025
-
[37]
Yuheng Zhao, Junjie Wang, Linbing Xiang, Xiaowen Zhang, Zifei Guo, Cagatay Turkay, Yu Zhang, and Siming Chen. 2024. Lightva: Lightweight visual ana- lytics with llm agent-based task planning and execution.IEEE Transactions on Visualization and Computer Graphics31, 9 (2024), 6162–6177
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.