Recognition: 2 theorem links
· Lean TheoremU-HNSW: An Efficient Graph-based Solution to ANNS Under Universal Lp Metrics
Pith reviewed 2026-05-08 18:57 UTC · model grok-4.3
The pith
U-HNSW uses HNSW graphs on L1 and L2 to answer approximate nearest neighbor queries for arbitrary Lp metrics without per-p indexes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
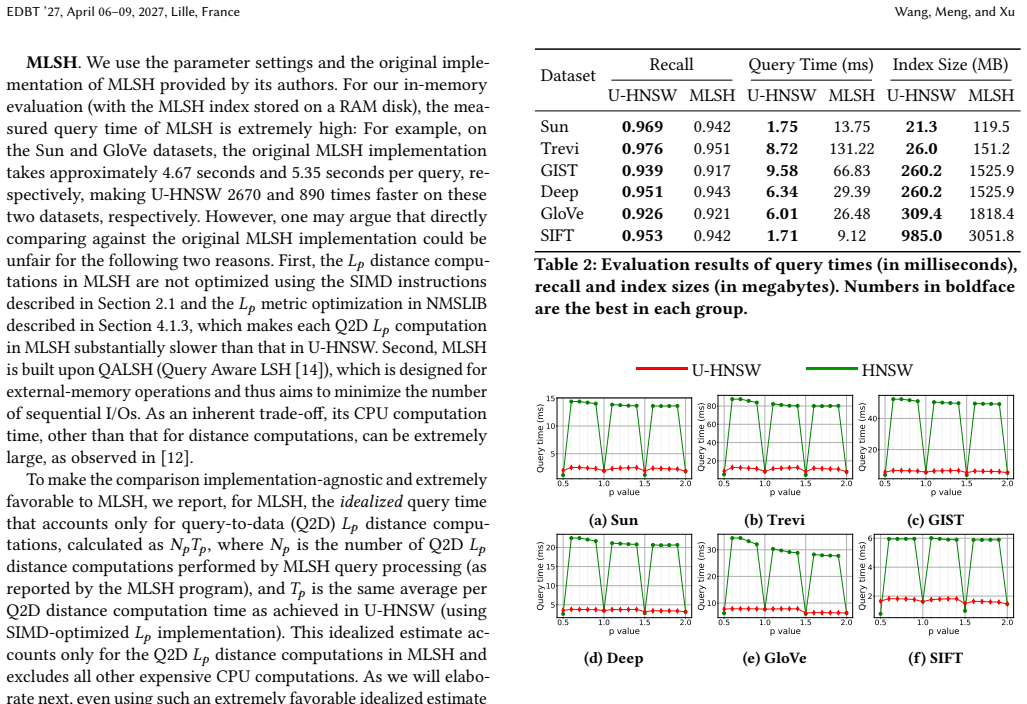
U-HNSW builds HNSW graphs on L1 and L2 base metrics to generate candidate nearest neighbors for queries under any p, then applies an early-termination verification step that greatly cuts the number of full Lp distance computations required. This delivers query times up to 2670 times shorter than the previous MLSH method on RAM disk and up to 15 times shorter than idealized MLSH, while also beating standard HNSW on fixed-p ANNS for most p values.
What carries the argument
The U-HNSW scheme, which combines two HNSW graphs built under L1 and L2 to produce candidate sets for arbitrary Lp queries followed by early-termination verification to limit costly distance calculations.
If this is right
- ANNS queries can be served for any p value using only two fixed indexes instead of one per p.
- Query latency drops dramatically compared to LSH-based universal methods.
- Performance on standard fixed-p problems can exceed that of single HNSW graphs except at a few special p.
- The early termination reduces the total Lp distance evaluations needed during search.
- Support for the full range 0 < p <= 2 becomes practical without index explosion.
Where Pith is reading between the lines
- This dual-base-graph idea might apply to other families of distances where a few representatives can cover the space.
- Applications like adaptive clustering or recommendation engines could switch p on the fly without reindexing costs.
- Testing the method on datasets with varying dimensionality or distributions could reveal when candidate generation from L1/L2 is most reliable.
- Extending the verification to include more base metrics might tighten the approximation for extreme p values.
Load-bearing premise
Candidate sets from the L1 and L2 HNSW graphs plus the early-termination check will always capture the true nearest neighbors for any p without missing relevant items.
What would settle it
Run the method on a dataset with known ground truth for a chosen p outside special cases; if recall falls below the target or the returned neighbor is not within the approximation bound of the true one, the claim fails.
Figures



read the original abstract
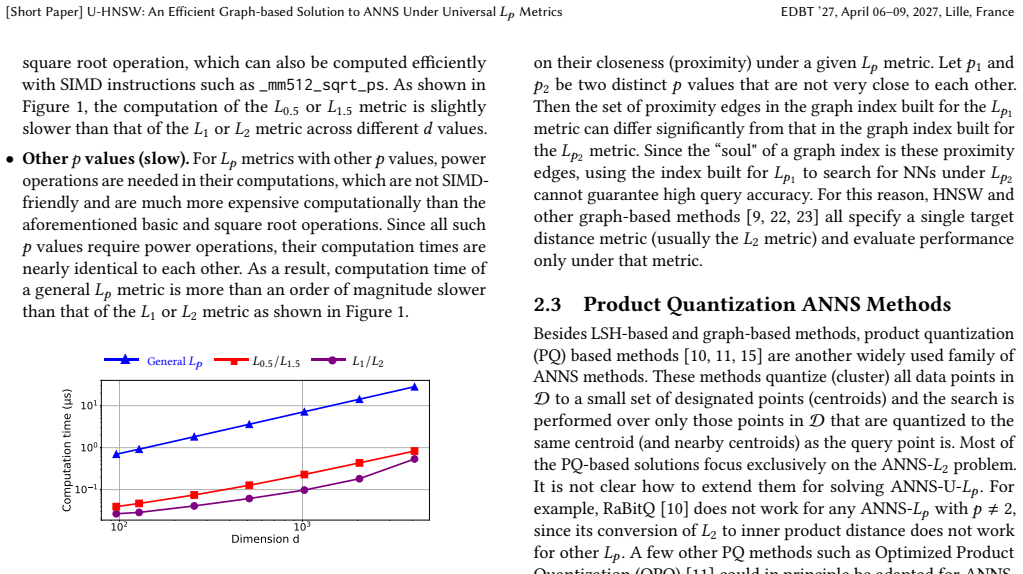
Approximate nearest neighbor search under universal L_p metrics (ANNS-U-L_p) is an important and challenging research problem, as it requires answering queries under all possible p (0<p <= 2) values simultaneously without building an index for each possible p value. The state-of-the-art solution, called MLSH, is a Locality-Sensitive Hashing (LSH)-based ANNS method with barely acceptable query performance. In contrast, graph-based ANNS methods, which offer significantly improved query efficiency on the ANNS-L_p problem (with a fixed p-value), cannot be naively extended to the ANNS-U-$L_p$ problem. In this paper, we propose U-HNSW, the first graph-based method for ANNS-U-L_p. Our scheme uses HNSW graph indexes built on two base metrics ($L_1$ and $L_2$) to generate promising nearest neighbors candidates, and then verifies these candidates with an early-termination strategy that substantially reduces the number of expensive L_p distance computations. Experimental results show that U-HNSW not only achieves up to 2670 times shorter query times than the original MLSH implementation running on a RAM disk (up to 15 times shorter than the idealized MLSH), but also outperforms the original HNSW on the ANNS-L_p problem (with a fixed p-value), except for a few special p values.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents U-HNSW as the first graph-based solution for approximate nearest neighbor search under universal L_p metrics (ANNS-U-L_p), supporting queries for any p in (0,2] from a single index pair. It constructs HNSW graphs under L1 and L2, extracts candidate sets from both, and applies an early-termination verification procedure that computes the target L_p distance only on a reduced candidate pool. The central empirical claim is that this yields up to 2670× shorter query times than the original MLSH implementation (and 15× versus an idealized MLSH) while also outperforming standard fixed-p HNSW except at a few special p values.
Significance. If the reported speedups and coverage hold under rigorous evaluation, the work would be a meaningful practical advance: it extends the efficiency advantages of graph-based ANNS to the universal-metric setting where only LSH-based methods (MLSH) previously existed. The dual-base-metric candidate generation plus early-termination heuristic is a concrete, implementable construction that reuses existing HNSW libraries and directly compares against both MLSH and HNSW baselines.
major comments (2)
- [§3] §3 (Candidate Generation): The method relies on the unproven assumption that the union of approximate neighbors returned by the L1 and L2 HNSW graphs will contain every true (or sufficiently close) L_p nearest neighbor for arbitrary p ∈ (0,2]. No inclusion probability bound, worst-case analysis, or even empirical coverage statistics are supplied for p values distant from 1 and 2 (e.g., p = 0.5), where L_p ball geometry diverges markedly; this assumption is load-bearing for both correctness and the claimed outperformance over fixed-p HNSW.
- [§5] §5 (Experimental Results): The headline speedups (2670× vs. MLSH on RAM disk, 15× vs. idealized MLSH) are reported without accompanying recall@k, precision, or false-negative rates, without specifying the datasets (cardinality, dimensionality, distribution), without listing the exact p values tested, and without statistical significance or variance across runs. Consequently the central performance claim cannot be assessed for robustness or for the claimed superiority over HNSW at non-special p.
minor comments (2)
- [Abstract] The abstract and introduction use “ANNS-U-L_p” and “ANNS-L_p” without an explicit one-sentence definition of the universal setting; adding this would aid readers unfamiliar with the distinction.
- [Notation] Notation for the early-termination threshold and candidate-set size parameters is introduced inconsistently between the method description and the experimental tables; a single consolidated table of symbols would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their detailed review and valuable feedback on our manuscript. We appreciate the recognition of U-HNSW as a potential practical advance in ANNS under universal Lp metrics. Below, we provide point-by-point responses to the major comments. We commit to revising the manuscript accordingly to address the concerns raised, particularly by adding missing empirical analyses and experimental details.
read point-by-point responses
-
Referee: [§3] §3 (Candidate Generation): The method relies on the unproven assumption that the union of approximate neighbors returned by the L1 and L2 HNSW graphs will contain every true (or sufficiently close) Lp nearest neighbor for arbitrary p ∈ (0,2]. No inclusion probability bound, worst-case analysis, or even empirical coverage statistics are supplied for p values distant from 1 and 2 (e.g., p = 0.5), where Lp ball geometry diverges markedly; this assumption is load-bearing for both correctness and the claimed outperformance over fixed-p HNSW.
Authors: We agree that the manuscript lacks a formal inclusion probability bound or worst-case analysis for the candidate set generated by the L1 and L2 HNSW indexes. Deriving such theoretical guarantees for arbitrary p is difficult due to the complex geometry of Lp balls for p not equal to 1 or 2. To address this, we will add empirical coverage statistics in a revised §3 or new subsection. Specifically, we will report, for various p including 0.5, the recall of true Lp nearest neighbors within the union of candidates from both graphs, using exact Lp distance computations for ground truth. This will demonstrate high coverage in practice (e.g., >90% for reasonable candidate sizes), justifying the approach. The early-termination verification step ensures that the final output is based on exact Lp distances, mitigating any potential misses. We will also compare against fixed-p HNSW to show where the dual approach provides benefits. revision: yes
-
Referee: [§5] §5 (Experimental Results): The headline speedups (2670× vs. MLSH on RAM disk, 15× vs. idealized MLSH) are reported without accompanying recall@k, precision, or false-negative rates, without specifying the datasets (cardinality, dimensionality, distribution), without listing the exact p values tested, and without statistical significance or variance across runs. Consequently the central performance claim cannot be assessed for robustness or for the claimed superiority over HNSW at non-special p.
Authors: We apologize for the insufficient detail in the experimental evaluation. The current manuscript does not adequately present the supporting metrics and specifications as noted. In the revised version, we will expand §5 to include: full dataset descriptions (cardinalities, dimensions, distributions); the complete list of p values evaluated; tables showing recall@k, precision, and false-negative rates for U-HNSW, MLSH, and HNSW at each p; and results with means and standard deviations over multiple independent runs, along with statistical tests where appropriate. We will ensure that all speedup claims are accompanied by these quality metrics to allow proper assessment of the trade-offs and robustness. revision: yes
Circularity Check
No circularity: algorithmic construction with external empirical validation
full rationale
The paper describes a concrete graph-based algorithm (U-HNSW) that builds fixed HNSW indexes under L1 and L2, generates candidate sets from them, and applies early-termination verification under target Lp. All performance claims (speedups vs. MLSH and HNSW) are obtained by direct measurement on external datasets and baselines rather than by any derivation that reduces to fitted parameters, self-definitions, or self-citation chains. The central premise is an engineering construction whose correctness is asserted empirically; no equation or theorem in the provided text equates a result to its own inputs by construction. This is the normal non-circular case for an applied systems paper.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
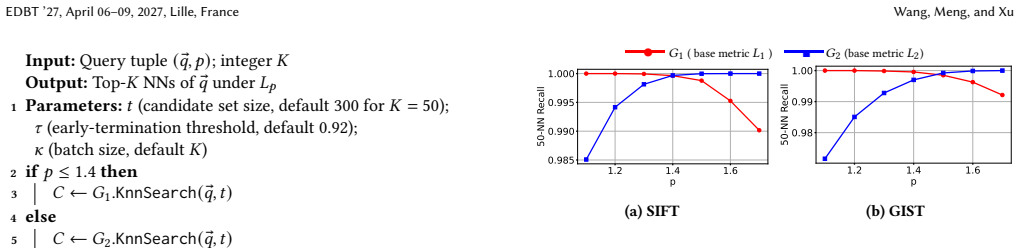
Cost/FunctionalEquation (J uniqueness)washburn_uniqueness_aczel unclearWe use 1.4 as the default cutoff value... For K = 50 ... t = 300 is large enough... we set τ = 0.92
Reference graph
Works this paper leans on
-
[1]
[n. d.]. HNSWlib—fast approximate nearest neighbor search. https://github.com/ nmslib/hnswlib
-
[2]
[n. d.]. Milvus: The High-Performance Vector Database Built for Scale. https: //milvus.io/
-
[3]
[n. d.]. Non-Metric Space Library (NMSLIB). https://github.com/nmslib/nmslib
-
[4]
[n. d.]. Pinecone: The vector database for scale in production. https://www. pinecone.io/. [Short Paper] U-HNSW: An Efficient Graph-based Solution to ANNS Under Universal𝐿 𝑝 Metrics EDBT ’27, April 06–09, 2027, Lille, France
2027
-
[5]
[n. d.]. U-HNSW: An Efficient Graph-based Solution to ANNS Under Universal Lp Metrics. https://anonymous.4open.science/r/hnsw_lp/README.md
-
[6]
Laurent Amsaleg and Hervé Jégou. 2010. Datasets for ANN neighbor search. http://corpus-texmex.irisa.fr/
2010
-
[7]
Mirrokni
Mayur Datar, Nicole Immorlica, Piotr Indyk, and Vahab S. Mirrokni. 2004. Locality- sensitive hashing scheme based on p-stable distributions. InProceedings of the Twentieth Annual Symposium on Computational Geometry(Brooklyn, New York, USA). Association for Computing Machinery, New York, NY, USA, 253–262
2004
-
[8]
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models. InProceedings of the 30th ACM SIGKDD Conference(Barcelona, Spain). Association for Computing Machinery, New York, NY, USA, 6491–6501
2024
-
[9]
Cong Fu, Chao Xiang, Changxu Wang, and Deng Cai. 2019. Fast approximate nearest neighbor search with the navigating spreading-out graph.Proc. VLDB Endow.12, 5 (Jan. 2019), 461–474
2019
-
[10]
Jianyang Gao and Cheng Long. 2024. RaBitQ: Quantizing High-Dimensional Vectors with a Theoretical Error Bound for Approximate Nearest Neighbor Search. Proc. ACM Manag. Data2, 3, Article 167 (May 2024), 27 pages. doi:10.1145/3654970
-
[11]
Tiezheng Ge, Kaiming He, Qifa Ke, and Jian Sun. 2014. Optimized Product Quantization.IEEE Trans. Pattern Anal. Mach. Intell.36, 4 (April 2014), 744–755. doi:10.1109/TPAMI.2013.240
-
[12]
Long Gong, Huayi Wang, Mitsunori Ogihara, and Jun Xu. 2020. iDEC: indexable distance estimating codes for approximate nearest neighbor search.Proc. VLDB Endow.13, 9 (May 2020), 1483–1497
2020
-
[13]
Peter Howarth and Stefan Rüger. 2005. Fractional distance measures for content- based image retrieval. InEuropean Conference on Information Retrieval. Springer, 447–456
2005
-
[14]
Qiang Huang, Jianlin Feng, Qiong Fang, Wilfred Ng, and Wei Wang. 2017. Query- aware locality-sensitive hashing scheme for 𝑙𝑝 norm.The VLDB Journal26, 5 (Oct. 2017), 683–708
2017
-
[15]
Herve Jegou, Matthijs Douze, and Cordelia Schmid. 2011. Product Quantization for Nearest Neighbor Search.IEEE Trans. Pattern Anal. Mach. Intell.33, 1 (Jan. 2011), 117–128. doi:10.1109/TPAMI.2010.57
-
[16]
Benjamin Klein and Lior Wolf. 2019. End-to-end supervised product quantization for image search and retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5041–5050
2019
-
[17]
Xiang-Zhen Kong, Yu Song, Jin-Xing Liu, Chun-Hou Zheng, Sha-Sha Yuan, Juan Wang, and Ling-Yun Dai. 2021. Joint 𝐿𝑝 -norm and L2, 1-norm constrained graph laplacian PCA for robust tumor sample clustering and gene network module discovery.Frontiers in Genetics12 (2021), 621317
2021
-
[18]
1991.Introductory functional analysis with applications
Erwin Kreyszig. 1991.Introductory functional analysis with applications. John Wiley & Sons
1991
-
[19]
Wen Li, Ying Zhang, Yifang Sun, Wei Wang, Mingjie Li, Wenjie Zhang, and Xuemin Lin. 2019. Approximate nearest neighbor search on high dimensional data—experiments, analyses, and improvement.IEEE Transactions on Knowledge and Data Engineering32, 8 (2019), 1475–1488
2019
-
[20]
Kevin Lin, Huei-Fang Yang, Jen-Hao Hsiao, and Chu-Song Chen. 2015. Deep learning of binary hash codes for fast image retrieval. InConf. on Comput. Vis. and Pattern Recognit. Workshops (CVPRW). IEEE, Boston, USA, 27–35
2015
-
[21]
Kejing Lu and Mineichi Kudo. 2021. MLSH: Mixed Hash Function Family for Approximate Nearest Neighbor Search in Multiple Fractional Metrics. InDatabase Systems for Advanced Applications: 26th International Conference, DASFAA 2021, Taipei, Taiwan, April 11–14, 2021, Proceedings, Part II(Taipei, Taiwan). Springer- Verlag, Berlin, Heidelberg, 569–584
2021
-
[22]
Kejing Lu, Mineichi Kudo, Chuan Xiao, and Yoshiharu Ishikawa. 2021. HVS: hierarchical graph structure based on voronoi diagrams for solving approximate nearest neighbor search.Proc. VLDB Endow.15, 2 (Oct. 2021), 246–258
2021
-
[23]
Malkov and D
Yu A. Malkov and D. A. Yashunin. 2020. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs. IEEE Transactions on Pattern Analysis and Machine Intelligence42, 4 (2020), 824– 836
2020
-
[24]
Hiroyuki Ootomo, Akira Naruse, Corey Nolet, Ray Wang, Tamas Feher, and Yong Wang. 2024. CAGRA: Highly Parallel Graph Construction and Approximate Nearest Neighbor Search for GPUs. In2024 IEEE 40th International Conference on Data Engineering (ICDE). 4236–4247. doi:10.1109/ICDE60146.2024.00323
-
[25]
Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global Vectors for Word Representation. https://nlp.stanford.edu/projects/glove/
2014
-
[26]
Simon Winder, Matt Brown, Noah Snavely, Steven Seitz, and Richard Szeliski
-
[27]
http://phototour.cs.washington.edu/ patches/default.htm
Trevi: Local Image Descriptors Data. http://phototour.cs.washington.edu/ patches/default.htm
-
[28]
Ehinger, James Hays, Antonio Torralba, and Aude Oliva
Jianxiong Xiao, Krista A. Ehinger, James Hays, Antonio Torralba, and Aude Oliva
-
[29]
SUN Database: Exploring a Large Collection of Scene Categories.Int. J. Comput. Vision119, 1 (Aug. 2016), 3–22
2016
-
[30]
Xu, Uri Alon, and Graham Neubig
Frank F. Xu, Uri Alon, and Graham Neubig. 2023. Why do nearest neighbor language models work?. InProceedings of the 40th International Conference on Machine Learning(Honolulu, Hawaii, USA)(ICML’23). JMLR.org, Article 1596, 17 pages
2023
-
[31]
Tung, and Sai Wu
Yuxin Zheng, Qi Guo, Anthony K.H. Tung, and Sai Wu. 2016. LazyLSH: Approx- imate Nearest Neighbor Search for Multiple Distance Functions with a Single Index. InProceedings of the 2016 International Conference on Management of Data (San Francisco, California, USA). Association for Computing Machinery, New York, NY, USA, 2023–2037
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.