Recognition: 2 theorem links
· Lean TheoremWhat Single-Prompt Accuracy Misses: A Multi-Variant Reliability Audit of Language Models
Pith reviewed 2026-05-08 19:25 UTC · model grok-4.3
The pith
Reliability conclusions for language models hinge on the evaluation pipeline as much as on the model itself.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
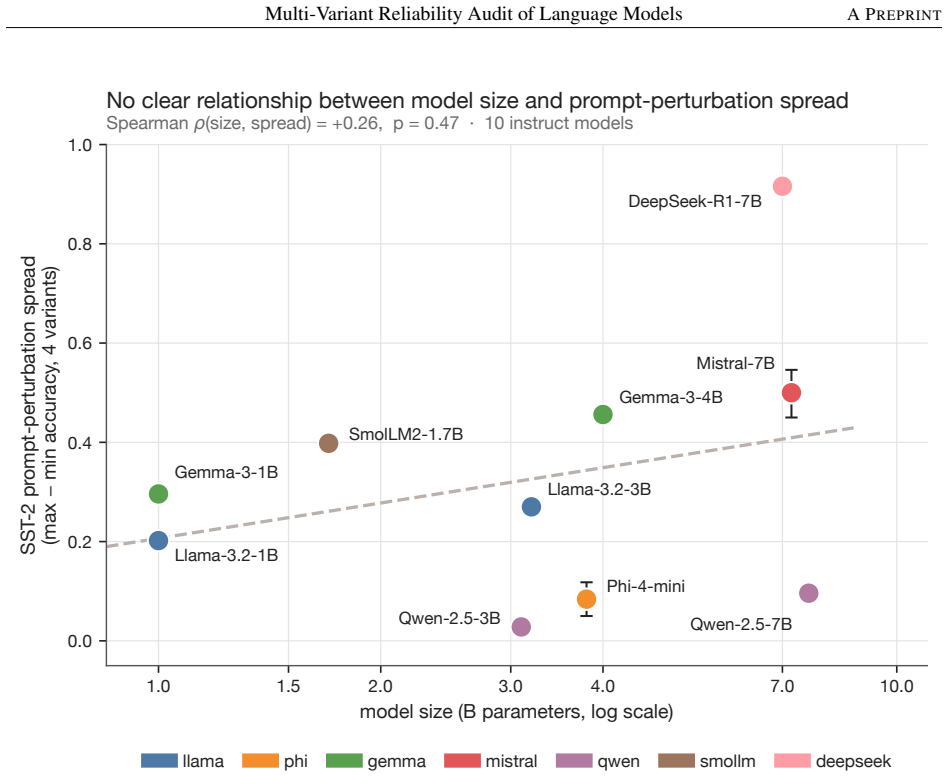
Switching from single-prompt to multi-variant evaluations shows that reliability metrics depend heavily on the pipeline. Changing the definition of expected calibration error shifts per-cell scores by a mean absolute 0.149. Pairing chain-of-thought prompts with first-character evaluators on ARC-Challenge drops accuracy by 72-88 percent due to evaluator failures, recoverable by repairs. Verbal confidence on MMLU-Pro exceeds actual accuracy and token probabilities for all models, with parse rates sometimes collapsing. Prompt-perturbation spread shows weak or inconsistent correlation with model size, ranging from negative to positive values across benchmarks.
What carries the argument
The multi-variant audit framework that applies five prompt variants to each model-dataset pair and computes accuracy alongside token-probability calibration, verbal-confidence calibration, verbal parse rate, and prompt-perturbation spread.
If this is right
- Changing calibration definitions materially changes reliability assessments.
- Evaluator logic in prompts can cause large apparent accuracy drops that are not model faults.
- Verbal confidence signals are often miscalibrated relative to token probabilities and actual accuracy.
- Model size does not reliably predict robustness to prompt changes.
- Explicit reporting of calibration, parseability, and robustness is needed for valid reliability claims.
Where Pith is reading between the lines
- Model rankings based on single-prompt tests may not hold under varied real-world prompts.
- Evaluation protocols could incorporate automatic checks for parse rates and calibration to catch hidden issues.
- Future work might explore whether these pipeline dependencies affect larger models differently.
- Practitioners should test models with multiple variants before deployment decisions.
Load-bearing premise
The selected five benchmarks and five prompt variants along with the chosen metrics sufficiently capture the reliability failures relevant in practice.
What would settle it
Observing consistent reliability conclusions across models when using only single-prompt accuracy on a broad set of additional benchmarks and variants would falsify the dependence on evaluation pipeline.
Figures



read the original abstract
Single-prompt accuracy is the dominant way to benchmark language models, but it can miss reliability failures that matter. We evaluate a 15-model open-weight corpus, with the main reliability analyses focused on 10 instruct models across five classification and reasoning benchmarks under five prompt variants each, measuring accuracy, token-probability calibration, verbal-confidence calibration, verbal parse rate, and prompt-perturbation spread for every (model x dataset x variant) cell. We find three broad results. First, evaluation design can materially change the conclusion. Switching Expected Calibration Error (ECE) token from a raw to a label-set-normalised definition changes per-cell calibration by a mean absolute 0.149. More strikingly, pairing a chain-of-thought prompt with a first-character evaluator on ARC-Challenge reduces apparent accuracy by 72-88% across all five primary models; two independent repair procedures recover 93.8% and 102.7% of the lost performance, indicating an evaluator-side rather than model-side failure. Second, confidence signals are fragile. On MMLU-Pro, every primary model verbally reports confidence substantially above both its accuracy and its token-probability confidence on the same rows, and verbal parse rate can collapse for a single model on a single prompt variant. Third, prompt robustness does not track parameter count reliably. Across 10 instruct models, the correlation between model size and prompt-perturbation spread ranges from -0.244 to 0.474 across benchmarks. Taken together, these results show that reliability conclusions for small language models depend not only on the model being evaluated, but also on the evaluation pipeline used to measure it. We argue that calibration definitions, evaluator logic, verbal parseability, and prompt robustness should be reported explicitly when making reliability claims.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that single-prompt accuracy is insufficient for assessing language model reliability because it can miss failures that depend on the evaluation pipeline. The authors audit 10 instruct models from a 15-model open-weight corpus on five benchmarks using five prompt variants each. They report metrics including accuracy, token-probability calibration, verbal-confidence calibration, verbal parse rate, and prompt-perturbation spread. Their results show that changing the ECE definition alters calibration by a mean absolute 0.149, that CoT prompts with first-character evaluators cause large accuracy drops (72-88%) on ARC-Challenge due to evaluator issues (recoverable by repairs), that verbal confidence is overconfident on MMLU-Pro, and that size-robustness correlations vary widely (-0.244 to 0.474). They conclude that reliability conclusions depend on both the model and the pipeline.
Significance. This work is significant because it provides concrete, quantified evidence that common benchmarking practices can lead to incorrect reliability assessments. The specific examples of pipeline sensitivity, including the large accuracy drops attributable to evaluator logic rather than the model, and the fragility of verbal confidence, offer clear illustrations of the problem. These findings, if they hold under scrutiny, could prompt the community to adopt more comprehensive evaluation standards that include multiple variants and explicit reporting of calibration and robustness metrics.
minor comments (4)
- The abstract reports numerical results (e.g., 0.149 MAE shift, 72-88% accuracy drop) without referencing the corresponding tables, figures, or sections in the main text where methods, statistical tests, and derivations of these values are detailed.
- Exact prompt texts for the five variants, full evaluator logic (including the first-character and repair procedures), and any code or raw data for the (model x dataset x variant) cells should be included in an appendix to support verification and replication of the reported metrics.
- The correlation range (-0.244 to 0.474) between model size and prompt-perturbation spread would benefit from accompanying p-values, confidence intervals, or per-benchmark breakdowns to strengthen the claim that robustness does not track parameter count reliably.
- Clarify the exact composition of the 15-model open-weight corpus relative to the 10 instruct models used for the primary reliability analyses, including any selection criteria.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work, the recognition of its significance, and the recommendation for minor revision. The referee's description accurately reflects our core claims regarding the sensitivity of reliability assessments to prompt variants, evaluator choices, and calibration definitions.
Circularity Check
No significant circularity; purely empirical measurements
full rationale
The paper conducts an empirical audit of language model reliability across 15 models, five benchmarks, and five prompt variants, directly measuring accuracy, token-probability calibration (ECE), verbal-confidence calibration, parse rates, and perturbation spread for each (model × dataset × variant) combination. No derivations, equations, fitted parameters, or self-citations are used to generate the reported quantities; all results are computed from raw model outputs and evaluator logic applied to the data. The central claim—that reliability conclusions depend on the evaluation pipeline—is substantiated by concrete, quantified differences (e.g., ECE normalization shift of 0.149, accuracy drops of 72-88% recoverable by evaluator repairs) rather than by any internal reduction or ansatz. This is a standard empirical study with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The five selected benchmarks and five prompt variants adequately sample the space of reliability-relevant behaviors.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost (Jcost, ECE in RS sense is unrelated)N/A — paper's ECE is binned reliability statistic, not RS J-cost unclearSwitching Expected Calibration Error (ECE) token from a raw to a label-set-normalised definition changes per-cell calibration by a mean absolute 0.149.
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905,
work page internal anchor Pith review arXiv
-
[2]
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Gabriel Martín Blázquez, Guilherme Penedo, Lewis Tunstall, Andrés Marafioti, Hynek Kydlíˇcek, Agustín Piqueres Lajarín, Vaibhav Srivastav, et al. Smollm2: When smol goes big–data-centric training of a small language model.arXiv preprint arXiv:2502.02737,
work page internal anchor Pith review arXiv
-
[3]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Let- man, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review arXiv
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review arXiv
-
[5]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221,
work page internal anchor Pith review arXiv
-
[6]
Holistic Evaluation of Language Models
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. Holistic evaluation of language models.arXiv preprint arXiv:2211.09110,
work page internal anchor Pith review arXiv
-
[7]
Teaching models to express their uncertainty in words
Stephanie Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words.arXiv preprint arXiv:2205.14334,
-
[8]
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting.arXiv preprint arXiv:2310.11324,
-
[9]
Gemma Team. Gemma 3 technical report.ArXiv, abs/2503.19786,
work page internal anchor Pith review arXiv
-
[10]
Language Model Cascades: Token-Level Uncertainty and Beyond
URL https://doi.org/10.48550/arXiv. 2503.19786. Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christo- pher D Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. InProceedings of the 2023 Conference on Empiri...
work page internal anchor Pith review doi:10.48550/arxiv 2023
-
[11]
Albert Webson and Ellie Pavlick. Do prompt-based models really understand the meaning of their prompts? In Proceedings of the 2022 conference of the north american chapter of the association for computational linguistics: Human language technologies, pages 2300–2344,
2022
-
[12]
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms.arXiv preprint arXiv:2306.13063,
work page internal anchor Pith review arXiv
-
[13]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review arXiv
-
[14]
Reasoning prompt variants(placeholders: {input}= question with lettered choice list; {label_list}= comma- separated labels;{fewshot_examples}=rendered few-shot block): •surface_paraphrase (baseline): “Answer the following multiple-choice question. {input} Answer with only the letter of the correct option. Answer:” •instruction_reorder (instruction placed ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.