Recognition: 2 theorem links
· Lean TheoremEditPropBench: Measuring Factual Edit Propagation in Scientific Manuscripts
Pith reviewed 2026-05-08 19:01 UTC · model grok-4.3
The pith
LLM editors for scientific manuscripts miss roughly 30 percent of required updates after a single factual change.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
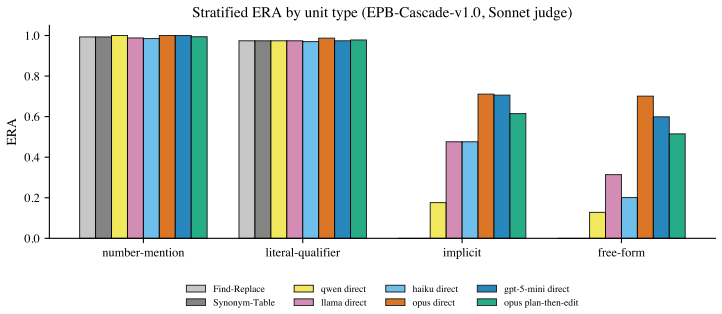
EditPropBench supplies each test item with an ML/NLP-style synthetic manuscript, a targeted factual edit, and a controlled fact graph that annotates direct targets, required downstream updates, and unrelated text that should remain unchanged. Cascade success is measured by Edit-Ripple Adherence (ERA), the fraction of required downstream updates that the editor correctly revises. On the hardest subset, where dependent claims use implicit or free-form wording, five LLM systems produce ERA scores from 0.148 to 0.705; the strongest system still misses roughly 30 percent of the required cascade updates. The performance gap persists in a mixed evaluation that also includes easy substitution cases.
What carries the argument
Edit-Ripple Adherence (ERA), the fraction of required downstream updates that are correctly revised according to the controlled fact graph.
If this is right
- Current LLM editors can repair many but not all implicit consequences of factual edits.
- Reliable scientific revision still requires additional cascade-aware checking beyond single-pass editing.
- Fact-dependent qualitative claims occur in 37.2 percent of recent cs.CL benchmark and dataset papers.
- Performance on propagation varies substantially across editing systems even when easy substitution cases are included.
Where Pith is reading between the lines
- The benchmark could be applied to non-ML domains such as biology or physics papers that contain similar numeric dependencies.
- Future editing tools might benefit from explicit fact-tracking modules that maintain a running graph of manuscript claims.
- The 30 percent miss rate suggests that automated consistency checks should become a standard post-editing step in scientific workflows.
Load-bearing premise
The synthetic manuscripts and sentence-level fact graphs accurately reflect the dependency patterns that appear in real scientific writing.
What would settle it
A manual audit of real scientific manuscripts after a factual edit, counting how many dependent claims remain inconsistent with the new value.
Figures




read the original abstract
Local factual edits in scientific manuscripts often create non-local revision obligations. If a dataset changes from 215 to 80 documents, claims such as 'medium-scale' or 'a few hundred items' may also become stale, even though they do not repeat the edited number. In an audit of recent arXiv cs.CL benchmark and dataset papers, we find fact-dependent qualitative claims in 37.2% of papers, suggesting that this dependency pattern is common in the target genre. We introduce EditPropBench, a benchmark for measuring whether LLM editors propagate factual edits through dependent manuscript claims. Each item contains an ML/NLP-style synthetic manuscript, a targeted edit, and a controlled fact graph with sentence-level labels for direct targets, required downstream updates, and unrelated text that should remain unchanged. We summarize cascade success with Edit-Ripple Adherence (ERA), the fraction of required downstream updates correctly revised, and validate the metric with adversarial probes and stress-test variants. On the hardest cases, where dependent claims use implicit or free-form wording rather than repeating the edited value, five LLM editing systems span ERA 0.148-0.705. Even the strongest misses roughly 30% of required cascade updates. This advantage persists in a mixed evaluation that includes easy cases solvable by deterministic substitution. EditPropBench shows that current LLM editors can repair many implicit consequences of factual edits, but reliable scientific revision still requires cascade-aware checking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that factual edits in scientific manuscripts frequently create obligations to revise dependent non-local claims (e.g., qualitative descriptors after numeric changes), documents this pattern via a 37.2% audit of arXiv cs.CL papers, introduces the EditPropBench benchmark consisting of synthetic ML/NLP-style manuscripts paired with targeted edits and controlled fact graphs that label direct targets, required downstream updates, and unrelated text, defines the Edit-Ripple Adherence (ERA) metric as the fraction of required downstream updates that are correctly revised, validates the metric with adversarial probes, and reports that five LLM editing systems achieve ERA scores of 0.148–0.705 on the hardest implicit/free-form cases while the best system still misses roughly 30% of required cascade updates.
Significance. If the benchmark construction and ERA results hold, the work provides concrete evidence that current LLM editors are insufficiently reliable for maintaining factual consistency during scientific revision and motivates the development of cascade-aware editing methods. The controlled fact-graph design, sentence-level labeling, and adversarial validation probes constitute reproducible strengths that allow direct comparison of systems; the prevalence audit further grounds the problem in the target genre.
major comments (2)
- [Benchmark Construction] Benchmark construction (synthetic manuscripts and fact graphs): the explicit structure and sentence-level labels supplied by the controlled fact graphs may make implicit dependencies easier to detect and execute than in real scientific writing, where dependencies often arise from domain context, rhetorical flow, and unstated implications rather than graph-provided structure. This directly affects the interpretation of the reported ERA range 0.148–0.705 and the claim that even the strongest system misses ~30% of updates.
- [Evaluation] Evaluation design: the 37.2% prevalence audit identifies fact-dependent claims in real papers but does not apply the five LLM systems or compute ERA on those real manuscripts, so the central performance claims rest entirely on synthetic items whose fidelity to real inference complexity remains untested.
minor comments (2)
- [Abstract and Results] The abstract and results sections refer to 'five LLM editing systems' without naming the specific models or providing implementation details; this should be added for reproducibility.
- [Metric Definition] Clarify the exact formula for ERA, including how unrelated text is scored and how adversarial probes are constructed to validate the metric.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our work. We address the major comments below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark construction (synthetic manuscripts and fact graphs): the explicit structure and sentence-level labels supplied by the controlled fact graphs may make implicit dependencies easier to detect and execute than in real scientific writing, where dependencies often arise from domain context, rhetorical flow, and unstated implications rather than graph-provided structure. This directly affects the interpretation of the reported ERA range 0.148–0.705 and the claim that even the strongest system misses ~30% of updates.
Authors: We agree that the provision of explicit fact graphs and sentence-level labels in the benchmark may facilitate dependency detection relative to the more implicit and context-dependent relations in authentic scientific manuscripts. The fact graphs were designed to capture the types of dependencies identified in our audit, including implicit qualitative claims, but we recognize this controlled setting does not fully replicate the rhetorical and domain-specific nuances of real papers. Nevertheless, the low ERA scores even under these conditions (maximum 0.705 on hard cases) underscore the difficulty of the propagation task. In the revised manuscript, we will expand the discussion and limitations sections to explicitly address the synthetic-to-real gap, including how the benchmark's design prioritizes reproducibility and precise measurement over full ecological validity. revision: partial
-
Referee: [Evaluation] Evaluation design: the 37.2% prevalence audit identifies fact-dependent claims in real papers but does not apply the five LLM systems or compute ERA on those real manuscripts, so the central performance claims rest entirely on synthetic items whose fidelity to real inference complexity remains untested.
Authors: The 37.2% audit is intended to demonstrate the prevalence of the phenomenon in real cs.CL papers, thereby motivating the need for a benchmark. Computing ERA on real manuscripts is challenging because it would require exhaustive manual annotation of all required downstream updates for each edit, which is precisely what the controlled fact graphs in EditPropBench provide. Without such labels, any evaluation on real data would lack the ground truth necessary for the metric. The synthetic benchmark enables rigorous, reproducible testing with adversarial probes to validate the metric. We will revise the paper to clarify the distinct roles of the audit (prevalence) and the benchmark (performance measurement), and to note that future work could explore semi-automated evaluation on real papers. revision: partial
Circularity Check
Empirical benchmark evaluation is self-contained with no circular derivation
full rationale
The paper defines EditPropBench via synthetic manuscripts and explicit fact graphs with sentence-level labels, then measures ERA (fraction of required downstream updates correctly revised) by direct testing of external LLM editors. ERA is computed from the test outputs against the provided labels; no parameter is fitted to a subset and then renamed as a prediction, no result reduces to a self-citation chain, and the 37.2% prevalence audit is an independent count on real papers. The central numbers (ERA 0.148-0.705 on implicit cases) are therefore falsifiable measurements on the constructed items rather than tautological restatements of the construction itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic manuscripts and sentence-level fact graphs accurately model the non-local revision obligations present in real scientific writing.
Lean theorems connected to this paper
-
IndisputableMonolith.Cost (J(x) = ½(x+x⁻¹)−1)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CCG = max(0, LES − GCS) · σ((LES − 0.7)/0.05)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URL https://api.semanticscholar.org/CorpusID:265456263. Ge Bai, Jie Liu, Xingyuan Bu, Yancheng He, Jiaheng Liu, Zhanhui Zhou, Zhuoran Lin, Wenbo Su, Tiezheng Ge, Bo Zheng, and Wanli Ouyang. Mt-bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues.ArXiv, abs/2402.14762,
-
[2]
Uniedit: A unified knowledge editing benchmark for large language models
URL https://api.semanticscholar.org/CorpusID:267782920. Qizhou Chen, Dakan Wang, Taolin Zhang, Zaoming Yan, Chengsong You, Chengyu Wang, and Xiaofeng He. Uniedit: A unified knowledge editing benchmark for large language models.ArXiv, abs/2505.12345, 2025a. URLhttps://api.semanticscholar.org/CorpusID:278740306. Yuhao Chen, Yuanjie Lyu, Shuochen Liu, Chao Z...
-
[3]
Nicola De Cao, Wilker Aziz, and Ivan Titov
URLhttps://api.semanticscholar.org/CorpusID:260356612. Nicola De Cao, Wilker Aziz, and Ivan Titov. Editing factual knowledge in language models. In Marie- Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors,Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6491–6506, Online and Punta Can...
2021
-
[4]
doi: 10.18653/V1/2021.EMNLP-MAIN.522
Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.522. URL https://aclanthology.org/2021. emnlp-main.522/. Yufang Hou, Alessandra Pascale, Javier Carnerero-Cano, Tigran T. Tchrakian, Radu Marinescu, Elizabeth Daly, Inkit Padhi, and Prasanna Sattigeri. Wikicontradict: A benchmark for evaluating llms on real-world knowledge conflic...
-
[5]
Association for Computational Linguistics. doi: 10.18653/v1/W19-8606. URLhttps://aclanthology.org/W19-8606/. Takumi Ito, Tatsuki Kuribayashi, Masatoshi Hidaka, Jun Suzuki, and Kentaro Inui. Langsmith: An interactive academic text revision system. In Qun Liu and David Schlangen, editors,Proceedings of the 2020 Conference on Empirical Methods in Natural Lan...
-
[6]
doi: 10.18653/v1/2020.emnlp-demos.28
Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-demos.28. URL https://aclanthology.org/2020.emnlp-demos. 28/. Léane Jourdan, Florian Boudin, Nicolas Hernandez, and Richard Dufour. CASIMIR: A corpus of scientific articles enhanced with multiple author-integrated revisions. In Nicoletta Calzolari, Min-Yen Kan, Veronique Hoste, Alessan...
-
[7]
URLhttps://aclanthology.org/2024.lrec-main.257/
ELRA and ICCL. URLhttps://aclanthology.org/2024.lrec-main.257/. Léane Jourdan, Florian Boudin, Richard Dufour, and Nicolas Hernandez. Identifying reliable evaluation metrics for scientific text revision.ArXiv, abs/2506.04772, 2025a. URL https: //api.semanticscholar.org/CorpusID:279244871. Léane Jourdan, Florian Boudin, Richard Dufour, Nicolas Hernandez, a...
-
[8]
URLhttps://api.semanticscholar.org/CorpusID:204976362. Wai-Chung Kwan, Xingshan Zeng, Yuxin Jiang, Yufei Wang, Liangyou Li, Lifeng Shang, Xin Jiang, Qun Liu, and Kam-Fai Wong. Mt-eval: A multi-turn capabilities evaluation benchmark for large language models.ArXiv, abs/2401.16745,
-
[9]
Mass-Editing Memory in a Transformer
URL https://api.semanticscholar.org/ CorpusID:244345901. Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt.Advances in Neural Information Processing Systems 35, 2022a. URL https: //api.semanticscholar.org/CorpusID:255825985. Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David ...
work page internal anchor Pith review arXiv
-
[10]
Coedit: Text editing by task-specific instruction tuning
URL https://api. semanticscholar.org/CorpusID:249642147. Vipul Raheja, Dhruv Kumar, Ryan Koo, and Dongyeop Kang. Coedit: Text editing by task-specific instruction tuning.ArXiv, abs/2305.09857,
-
[11]
URL https://api.semanticscholar.org/ CorpusID:258741409. Domenic Rosati, Robie Gonzales, Jinkun Chen, Xuemin Yu, Melis Erkan, Yahya Kayani, Satya Deepika Chavatapalli, Frank Rudzicz, and Hassan Sajjad. Long-form evaluation of model editing.ArXiv, abs/2402.09394,
-
[12]
semanticscholar.org/CorpusID:258833129
URLhttps://api. semanticscholar.org/CorpusID:258833129. Li Zeng, Zeming Liu, Chong Feng, Heyan Huang, and Yuhang Guo. Docmedit: Towards document- level model editing.ArXiv, abs/2505.19572,
-
[13]
A comprehensive study of knowledge editing for large language models,
URL https://api.semanticscholar. org/CorpusID:278904570. Ningyu Zhang, Yunzhi Yao, Bo Tian, Peng Wang, Shumin Deng, Mengru Wang, Zekun Xi, Shengyu Mao, Jintian Zhang, Yuansheng Ni, Siyuan Cheng, Ziwen Xu, Xin Xu, Jia-Chen Gu, Yong Jiang, Pengjun Xie, Fei Huang, Lei Liang, Zhiqiang Zhang, Xiaowei Zhu, Jun Zhou, and Huajun Chen. A comprehensive study of kno...
-
[14]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
URLhttps://api.semanticscholar.org/CorpusID:266725300. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Haotong Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena.ArXiv, abs/2306.05685,
work page internal anchor Pith review arXiv
-
[15]
Qual.” indicates whether the benchmark scores implicit qualitative claims whose meaning depends on an edited fact. “Doc
URL https://api. semanticscholar.org/CorpusID:258865984. A Stress-test cross-validation figure Figure 5 plots the cascade gap on the hard-stratum main-corpus analysis against the aggregate gap on the stress-test corpus, in support of Section 5.2. Main corpus (hard-cell stratum, exploratory) Fully-rewritten corpus (aggregate, confirmatory) 0.0 0.2 0.4 0.6 ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.