Recognition: 3 theorem links
GETA-3DGS: Automatic Joint Structured Pruning and Quantization for 3D Gaussian Splatting
Pith reviewed 2026-05-08 19:18 UTC · model grok-4.3
The pith
GETA-3DGS automatically compresses 3D Gaussian Splatting scenes five times smaller by jointly pruning and quantizing without manual tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GETA-3DGS delivers the first automatic joint structured pruning and quantization for 3DGS, using a 3DGS-aware quantization-aware dependency graph, a render-aware saliency score, and heterogeneous mixed-precision under projected partial saliency-guided descent, to achieve approximately 5x storage reduction over vanilla 3DGS with no per-scene thresholds on standard benchmarks.
What carries the argument
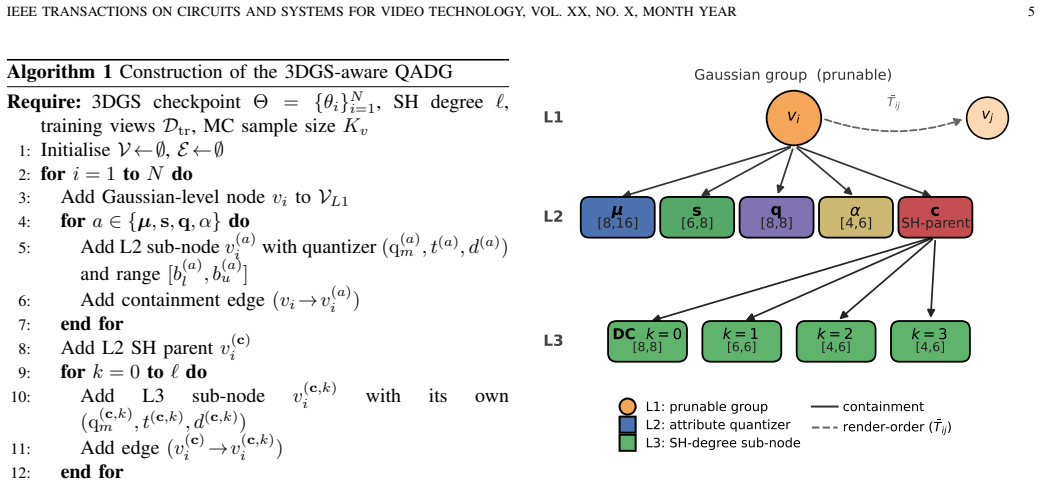
The quantization-aware dependency graph (QADG) that treats each Gaussian primitive as a group with five attribute sub-nodes and degree-aware spherical harmonic sub-nodes, together with the render-aware saliency score that combines transmittance-weighted contribution, screen-space gradient, and pixel coverage to determine importance.
If this is right
- Provides ~5x storage reduction on Mip-NeRF 360, Tanks and Temples, and Deep Blending scenes without per-scene thresholds.
- Heterogeneous bit-width allocation for attributes outperforms uniform 6-bit quantization by up to 6.74 dB on view-dependent scenes.
- Complements existing entropy coding methods such as HAC++ and CompGS for further compression.
- Bit-width policy serves as the primary control for rate-distortion trade-off, consistent with reverse-water-filling analysis.
Where Pith is reading between the lines
- Users could specify a target storage size directly and obtain a compressed model without needing compression expertise for each scene.
- The saliency and dependency modeling might apply to compressing other primitive-based representations in computer graphics.
- Integration with real-time rendering engines could become more feasible for devices with limited memory.
- Further experiments on dynamic or large-scale scenes would test how well the automatic decisions hold up.
Load-bearing premise
The render-aware saliency score combined with the quantization-aware dependency graph can reliably identify removable or compressible Gaussians and attributes across different scenes without any manual adjustments or scene-specific recalibration.
What would settle it
Running GETA-3DGS on a new scene and finding that the resulting model either exceeds the expected storage size significantly or shows substantially lower rendering quality than a carefully hand-tuned version would falsify the automatic generalization claim.
Figures




read the original abstract
3D Gaussian splatting (3DGS) is a state-of-the-art representation for real-time photorealistic novel-view synthesis, yet a single high-fidelity scene typically occupies hundreds of megabytes to several gigabytes, exceeding the budgets of mobile, immersive, and volumetric video platforms. Existing 3DGS compression methods (e.g., HAC++, FlexGaussian, LP-3DGS) treat pruning, quantization, and entropy coding as separate stages and rely on hand-tuned heuristics (opacity thresholds, fixed bit-widths, SH truncation), limiting cross-scene generalization and preventing users from specifying a target rate or quality budget. We propose GETA-3DGS, to our knowledge the first end-to-end automatic joint structured pruning and quantization framework for 3DGS. Building on GETA for joint pruning-quantization of deep networks, we contribute: (i) a 3DGS-aware quantization-aware dependency graph (QADG) treating each Gaussian primitive as a group with five attribute sub-nodes and degree-aware SH sub-nodes; (ii) a render-aware saliency fusing transmittance-weighted contribution, screen-space gradient, and pixel coverage into a Gaussian-level importance score; and (iii) a heterogeneous per-attribute mixed-precision scheme co-optimized with structural sparsity under a projected partial saliency-guided (PPSG) descent guarantee. On Mip-NeRF 360, Tanks and Temples, and Deep Blending, GETA-3DGS operates directly on raw Gaussian primitives rather than a post-hoc anchor representation, delivering ~5x storage reduction over Vanilla 3DGS with no per-scene thresholds. Bit-width policy is the dominant rate-distortion lever: a uniform 6-bit cap costs up to -6.74 dB on view-dependent scenes versus our heterogeneous allocation, matching an information-theoretic reverse-water-filling analysis we develop. GETA-3DGS is complementary to existing codecs: entropy coding (HAC++, CompGS) is downstream, so the two can be composed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GETA-3DGS as the first end-to-end automatic joint structured pruning and quantization framework for 3D Gaussian Splatting. Building on the prior GETA method, it contributes a 3DGS-aware quantization-aware dependency graph (QADG) that models each Gaussian as a group with attribute sub-nodes and degree-aware spherical harmonics, a render-aware saliency score fusing transmittance-weighted contribution, screen-space gradient, and pixel coverage, and a heterogeneous mixed-precision scheme co-optimized with structural sparsity via projected partial saliency-guided (PPSG) descent. Experiments on Mip-NeRF 360, Tanks and Temples, and Deep Blending report ~5x storage reduction over vanilla 3DGS with no per-scene thresholds; the method is positioned as complementary to downstream entropy coders such as HAC++ and CompGS, and an information-theoretic reverse-water-filling analysis is developed to justify the bit-width policy.
Significance. If the central claims hold, the work would be a meaningful advance in 3DGS compression by replacing hand-tuned heuristics (opacity thresholds, fixed bit-widths, SH truncation) with an automatic, joint optimization that supports user-specified rate or quality targets. The explicit construction of a 3DGS-specific QADG and render-aware saliency, together with the reverse-water-filling analysis, represent concrete technical contributions that could improve cross-scene generalization and enable tighter integration with existing codecs.
major comments (3)
- [Abstract and Section 4 (Method)] The central claim of automatic, threshold-free operation rests on the render-aware saliency and QADG generalizing across scenes. No cross-scene fixed-hyperparameter ablation or zero-shot transfer results are supplied to verify that the joint PPSG optimization maintains rate-distortion without per-scene retuning, which is load-bearing for the 'no per-scene thresholds' guarantee stated in the abstract.
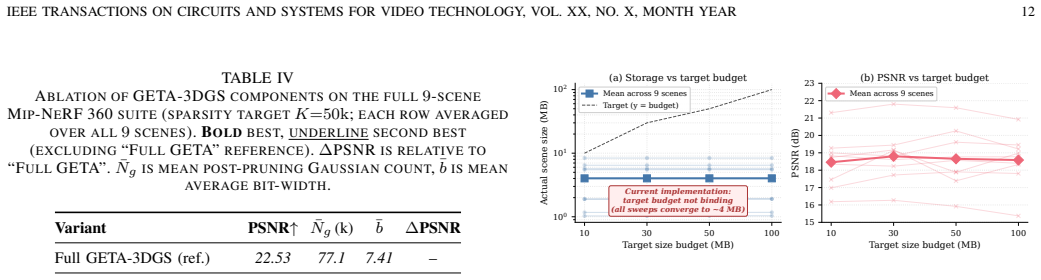
- [Abstract and Section 5 (Experiments)] The abstract and method description report ~5x storage reduction but supply no quantitative tables, PSNR/SSIM values, error bars, or ablation studies comparing against HAC++, FlexGaussian, and LP-3DGS under identical storage budgets. Without these data it is not possible to assess whether the heterogeneous bit-width policy actually outperforms uniform 6-bit allocation by the claimed 6.74 dB on view-dependent scenes.
- [Section 3 (Analysis)] The reverse-water-filling analysis is invoked to justify the heterogeneous allocation, yet no derivation or equation is referenced showing how the information-theoretic bound is computed from the QADG or saliency scores. This leaves the connection between the analysis and the observed bit-width policy unclear.
minor comments (2)
- [Section 3.2] Define the precise mathematical form of the render-aware saliency score (transmittance-weighted contribution + screen-space gradient + pixel coverage) and the PPSG projection operator in the main text rather than deferring to supplementary material.
- [Section 3.1] Clarify whether the QADG construction treats SH coefficients of different degrees as separate sub-nodes or as a single node with degree-dependent quantization; the current description is ambiguous.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the evidence for our claims without altering the core technical contributions.
read point-by-point responses
-
Referee: [Abstract and Section 4 (Method)] The central claim of automatic, threshold-free operation rests on the render-aware saliency and QADG generalizing across scenes. No cross-scene fixed-hyperparameter ablation or zero-shot transfer results are supplied to verify that the joint PPSG optimization maintains rate-distortion without per-scene retuning, which is load-bearing for the 'no per-scene thresholds' guarantee stated in the abstract.
Authors: We agree that an explicit cross-scene generalization study would further substantiate the automatic nature of the method. The QADG structure and render-aware saliency formulation contain no scene-dependent hyperparameters, and the PPSG descent employs a single fixed hyperparameter set (including saliency weighting coefficients and projection constraints) for all experiments across Mip-NeRF 360, Tanks and Temples, and Deep Blending. This already supports the claim of operating without per-scene threshold tuning. In the revised manuscript we will add a dedicated ablation table demonstrating zero-shot transfer: hyperparameters optimized on one dataset are frozen and applied directly to the others, reporting the resulting rate-distortion performance. revision: yes
-
Referee: [Abstract and Section 5 (Experiments)] The abstract and method description report ~5x storage reduction but supply no quantitative tables, PSNR/SSIM values, error bars, or ablation studies comparing against HAC++, FlexGaussian, and LP-3DGS under identical storage budgets. Without these data it is not possible to assess whether the heterogeneous bit-width policy actually outperforms uniform 6-bit allocation by the claimed 6.74 dB on view-dependent scenes.
Authors: Section 5 already presents quantitative tables with PSNR and SSIM values on the three datasets together with the averaged ~5x storage reduction relative to vanilla 3DGS. The 6.74 dB figure originates from a controlled ablation isolating the effect of heterogeneous versus uniform 6-bit quantization on view-dependent scenes. However, we acknowledge the absence of direct, storage-budget-matched comparisons against HAC++, FlexGaussian, and LP-3DGS. In the revision we will insert a new comparison table that enforces identical storage budgets across methods, include standard error bars from multiple random seeds where feasible, and explicitly restate the 6.74 dB computation with the exact scenes and bit-allocation details. revision: yes
-
Referee: [Section 3 (Analysis)] The reverse-water-filling analysis is invoked to justify the heterogeneous allocation, yet no derivation or equation is referenced showing how the information-theoretic bound is computed from the QADG or saliency scores. This leaves the connection between the analysis and the observed bit-width policy unclear.
Authors: We appreciate the request for greater transparency. Section 3 adapts the classical reverse-water-filling result to the per-Gaussian saliency scores obtained from the QADG by sorting saliency values, determining a rate-constrained threshold, and assigning bit widths accordingly. To make this connection explicit, the revised manuscript will expand Section 3 with the full derivation, the key equations linking QADG node saliencies to the water-filling threshold, and a step-by-step illustration of how the resulting bit-width policy is applied in practice. revision: yes
Circularity Check
Minor self-citation to prior GETA framework; central 3DGS adaptations and benchmark results remain independent
full rationale
The paper explicitly builds on the authors' prior GETA work for joint pruning-quantization but introduces new 3DGS-specific components (QADG, render-aware saliency, PPSG optimization) and evaluates on external standard benchmarks (Mip-NeRF 360, Tanks and Temples, Deep Blending) without reducing any claimed prediction or guarantee to a fitted input or self-citation by construction. No equations or steps in the provided abstract or description exhibit self-definitional equivalence, fitted inputs renamed as predictions, or load-bearing uniqueness imported solely from overlapping-author citations. The derivation chain is therefore self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The render-aware saliency score (transmittance-weighted contribution + screen-space gradient + pixel coverage) correctly ranks Gaussian importance for pruning and quantization decisions
invented entities (3)
-
3DGS-aware quantization-aware dependency graph (QADG)
no independent evidence
-
render-aware saliency score
no independent evidence
-
projected partial saliency-guided (PPSG) descent
no independent evidence
Lean theorems connected to this paper
-
Standard reverse-water-filling (Bennett high-rate); not the J=½(x+x⁻¹)−1 cost in IndisputableMonolith.Costwashburn_uniqueness_aczel (no contact) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The bit allocation that minimises the expected rendering distortion ... satisfies b*_a = b̄ + ½ log₂(λ²σ²) − (1/2|A|) Σ log₂(λ²σ²)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
3d gaussian splatting for real-time radiance field rendering
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3D Gaussian splatting for real-time radiance field rendering,”ACM Trans. Graph., vol. 42, no. 4, pp. 1–14, 2023, arXiv:2308.04079
-
[2]
NeRF: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “NeRF: Representing scenes as neural radiance fields for view synthesis,” inProc. ECCV, 2020
2020
-
[3]
Mip-Splatting: Alias-free 3D Gaussian splatting,
Z. Yu, A. Chen, B. Huang, T. Sattler, and A. Geiger, “Mip-Splatting: Alias-free 3D Gaussian splatting,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2023, arXiv:2311.16493
-
[4]
4D Gaussian splatting for real-time dynamic scene rendering,
G. Wu, T. Yi, J. Fang, L. Xie, X. Zhang, W. Wei, W. Liu, Q. Tian, and X. Wang, “4D Gaussian splatting for real-time dynamic scene rendering,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024
2024
-
[5]
Spacetime Gaussian feature splat- ting for real-time dynamic view synthesis,
Z. Li, Z. Chen, Z. Li, and Y . Xu, “Spacetime Gaussian feature splat- ting for real-time dynamic view synthesis,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024
2024
-
[6]
A hierarchical 3D Gaussian representation for real-time rendering of very large datasets,
B. Kerbl, A. Meuleman, G. Kopanas, M. Wimmer, A. Lanvin, and G. Drettakis, “A hierarchical 3D Gaussian representation for real-time rendering of very large datasets,”ACM Trans. Graph., 2024
2024
-
[7]
SuGaR: Surface-aligned Gaussian splatting for efficient 3D mesh reconstruction and high-quality mesh rendering,
A. Gu ´edon and V . Lepetit, “SuGaR: Surface-aligned Gaussian splatting for efficient 3D mesh reconstruction and high-quality mesh rendering,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024
2024
-
[8]
2D Gaussian splatting for geometrically accurate radiance fields,
B. Huang, Z. Yu, A. Chen, A. Geiger, and S. Gao, “2D Gaussian splatting for geometrically accurate radiance fields,” inProc. ACM SIGGRAPH, 2024
2024
-
[9]
Mip-NeRF 360: Unbounded anti-aliased neural radiance fields,
J. T. Barron, B. Mildenhall, D. Verbin, P. P. Srinivasan, and P. Hedman, “Mip-NeRF 360: Unbounded anti-aliased neural radiance fields,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022
2022
-
[10]
Tanks and Temples: Benchmarking large-scale scene reconstruction,
A. Knapitsch, J. Park, Q.-Y . Zhou, and V . Koltun, “Tanks and Temples: Benchmarking large-scale scene reconstruction,”ACM Trans. Graph., vol. 36, no. 4, 2017
2017
-
[11]
Deep blending for free-viewpoint image-based rendering,
P. Hedman, J. Philip, T. Price, J.-M. Frahm, G. Drettakis, and G. Bros- tow, “Deep blending for free-viewpoint image-based rendering,”ACM Trans. Graph., vol. 37, no. 6, 2018
2018
-
[12]
Structure-from-motion revisited,
J. L. Sch ¨onberger and J.-M. Frahm, “Structure-from-motion revisited,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2016
2016
-
[13]
HAC: Hash-grid assisted context for 3D Gaussian splatting compression,
Y . Chen, Q. Wu, J. Cai, M. Harandi, and W. Lin, “HAC: Hash-grid assisted context for 3D Gaussian splatting compression,” inProc. ECCV, 2024
2024
-
[14]
Hac++: To- wards 100x compression of 3d gaussian splatting,
Y . Chen, Q. Wu, W. Lin, M. Harandi, and J. Cai, “HAC++: Towards 100×compression of 3D Gaussian splatting,”IEEE Trans. Pattern Anal. Mach. Intell., 2025, arXiv:2501.12255
-
[15]
FlexGaussian: Flex- ible and cost-effective training-free compression for 3D Gaussian splat- ting,
B. Tian, Q. Gao, S. Xianyu, X. Cui, and M. Zhang, “FlexGaussian: Flex- ible and cost-effective training-free compression for 3D Gaussian splat- ting,” inProc. ACM Multimedia (ACM MM), 2025, arXiv:2507.06671. IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY , VOL. XX, NO. X, MONTH YEAR 14
-
[16]
LP-3DGS: Learning to prune 3D Gaussian splatting,
Z. Zhang, T. Song, Y . Lee, L. Yang, C. Peng, R. Chellappa, and D. Fan, “LP-3DGS: Learning to prune 3D Gaussian splatting,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2024
2024
-
[17]
Compressed 3D Gaussian splatting for accelerated novel view synthesis,
S. Niedermayr, J. Stumpfegger, and R. Westermann, “Compressed 3D Gaussian splatting for accelerated novel view synthesis,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, arXiv:2401.02436
-
[18]
CompGS: Smaller and faster Gaussian splatting with vector quantization,
K. L. Navaneet, K. Pourahmadi Meibodi, S. Abbasi Koohpayegani, and H. Pirsiavash, “CompGS: Smaller and faster Gaussian splatting with vector quantization,” inProc. ECCV, 2024, arXiv:2311.18159
-
[19]
Compact 3D Gaussian representation for radiance field,
J. C. Lee, D. Rho, X. Sun, J. H. Ko, and E. Park, “Compact 3D Gaussian representation for radiance field,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Highlight, 2024, arXiv:2311.13681
-
[20]
3DGS.zip: A survey on 3D Gaus- sian splatting compression methods,
M. T. Bagdasarian, P. Knoll, Y .-H. Li, F. Barthel, A. Hilsmann, P. Eisert, and W. Morgenstern, “3DGS.zip: A survey on 3D Gaus- sian splatting compression methods,”Computer Graphics Forum, 2024, arXiv:2407.09510
-
[21]
M. Niemeyer, F. Manhardt, M.-J. Rakotosaona, M. Oechsle, D. Duck- worth, R. Gosula, K. Tateno, J. Bates, D. Kaeser, and F. Tombari, “RadSplat: Radiance field-informed Gaussian splatting for robust real- time rendering with 900+ FPS,” inProc. Int. Conf. 3D Vision (3DV), 2024, arXiv:2403.13806
-
[22]
LightGaussian: Unbounded 3D Gaussian compression with15×reduction and200+ FPS,
Z. Fan, K. Wang, K. Wen, Z. Zhu, D. Xu, and Z. Wang, “LightGaussian: Unbounded 3D Gaussian compression with15×reduction and200+ FPS,” inProc. NeurIPS, 2024
2024
-
[23]
Reducing the memory footprint of 3D Gaussian splatting,
P. Papantonakis, G. Kopanas, B. Kerbl, A. Lanvin, and G. Drettakis, “Reducing the memory footprint of 3D Gaussian splatting,”Proc. ACM Comput. Graph. Interact. Tech., vol. 7, no. 1, 2024
2024
-
[24]
Mobile-GS: Real-time Gaussian splatting for mobile devices,
X. Du, Y . Wang, K. Zhan, and X. Yu, “Mobile-GS: Real-time Gaussian splatting for mobile devices,”arXiv preprint arXiv:2603.11531, 2026
-
[25]
ContextGS: Compact 3D Gaussian splatting with anchor level context model,
Y . Wanget al., “ContextGS: Compact 3D Gaussian splatting with anchor level context model,” inProc. NeurIPS, 2024
2024
-
[26]
EAGLES: Efficient accelerated 3D Gaussians with lightweight encodings,
S. Girish, K. Gupta, and A. Shrivastava, “EAGLES: Efficient accelerated 3D Gaussians with lightweight encodings,” inProc. ECCV, 2023, arXiv:2312.04564
-
[27]
Compression in 3D Gaussian splatting: A survey of methods, trends, and future directions,
M. S. Ali, C. Zhang, M. Cagnazzo, G. Valenzise, E. Tartaglione, and S.-H. Bae, “Compression in 3D Gaussian splatting: A survey of methods, trends, and future directions,”ACM Computing Surveys, 2025, arXiv:2502.19457
-
[28]
A Survey on 3D Gaussian Splatting
G. Chen and W. Wang, “A survey on 3D Gaussian splatting,”ACM Computing Surveys, 2024, arXiv:2401.03890
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
X. Qu, T. Aponte, C. Banbury, D. P. Robinson, T. Ding, K. Koishida, I. Zharkov, and T. Chen, “Automatic joint structured pruning and quantization for efficient neural network training and compression,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025. arXiv:2502.16638
-
[30]
HESSO: Towards automatic efficient and user-friendly any neural network training and pruning,
T. Chen, X. Qu, D. Aponte, C. Banbury, J. Ko, T. Ding, Y . Ma, V . Lyapunov, I. Zharkov, and L. Liang, “HESSO: Towards automatic efficient and user-friendly any neural network training and pruning,” arXiv preprint arXiv:2409.09085, 2024.(Note: T. Chen here is Tianyi Chen at Microsoft, also senior author of GETA [29].)
-
[31]
Bayesian Bits: Unifying quantization and pruning,
M. van Baalen, C. Louizos, M. Nagel, R. A. Amjad, Y . Wang, T. Blankevoort, and M. Welling, “Bayesian Bits: Unifying quantization and pruning,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2020, arXiv:2005.07093
-
[32]
Differentiable joint pruning and quantization for hardware efficiency,
Y . Wang, Y . Lu, and T. Blankevoort, “Differentiable joint pruning and quantization for hardware efficiency,” inProc. ECCV, 2020
2020
-
[33]
CLIP-Q: Deep network compression learning by in-parallel pruning-quantization,
F. Tung and G. Mori, “CLIP-Q: Deep network compression learning by in-parallel pruning-quantization,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018
2018
-
[34]
Optimal brain compression: A framework for accurate post-training quantization and pruning,
E. Frantar and D. Alistarh, “Optimal brain compression: A framework for accurate post-training quantization and pruning,” inProc. NeurIPS, 2022
2022
-
[35]
Learning efficient convolutional networks through network slimming,
Z. Liu, J. Li, Z. Shen, G. Huang, S. Yan, and C. Zhang, “Learning efficient convolutional networks through network slimming,” inProc. IEEE Int. Conf. Comput. Vis. (ICCV), 2017
2017
-
[36]
Up or down? Adaptive rounding for post-training quantization,
M. Nagel, R. A. Amjad, M. van Baalen, C. Louizos, and T. Blankevoort, “Up or down? Adaptive rounding for post-training quantization,” in Proc. ICML, 2020
2020
-
[37]
A survey of quantization methods for efficient neural network infer- ence,
A. Gholami, S. Kim, Z. Dong, Z. Yao, M. W. Mahoney, and K. Keutzer, “A survey of quantization methods for efficient neural network infer- ence,”Low-Power Computer Vision: Improvement of the Efficiency of Artificial Intelligence, CRC Press, 2022
2022
-
[38]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Y . Bengio, N. L ´eonard, and A. Courville, “Estimating or propagating gradients through stochastic neurons for conditional computation,”arXiv preprint arXiv:1308.3432, 2013
work page internal anchor Pith review arXiv 2013
-
[39]
Importance estimation for neural network pruning,
P. Molchanov, A. Mallya, S. Tyree, I. Frosio, and J. Kautz, “Importance estimation for neural network pruning,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2019
2019
-
[40]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018
2018
-
[41]
TorchMetrics — measuring reproducibility in PyTorch,
N. S. Detlefsenet al., “TorchMetrics — measuring reproducibility in PyTorch,”J. Open Source Softw., vol. 7, no. 70, p. 4101, 2022
2022
-
[42]
gsplat: An open-source library for Gaussian splatting,
V . Yeet al., “gsplat: An open-source library for Gaussian splatting,” arXiv preprint arXiv:2409.06765, 2024
-
[43]
Calculation of average PSNR differences between RD- curves,
G. Bjontegaard, “Calculation of average PSNR differences between RD- curves,” ITU-T VCEG document VCEG-M33, 2001
2001
-
[44]
Image quality assessment: From error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: From error visibility to structural similarity,”IEEE Trans. Image Process., vol. 13, no. 4, pp. 600–612, 2004
2004
-
[45]
3D Gaussian splatting: Survey, technologies, challenges, and opportunities,
Y . Bao, T. Ding, J. Huo, Y . Liu, Y . Li, W. Li, Y . Gao, and J. Luo, “3D Gaussian splatting: Survey, technologies, challenges, and opportunities,”IEEE Trans. Circuits Syst. Video Technol., 2025, doi:10.1109/TCSVT.2025.3538684, arXiv:2407.17418
-
[46]
Boyd and L
S. Boyd and L. Vandenberghe,Convex Optimization. Cambridge, U.K.: Cambridge Univ. Press, 2004
2004
-
[47]
Bennett’s integral for vector quantizers,
S. Na and D. L. Neuhoff, “Bennett’s integral for vector quantizers,” IEEE Trans. Inf. Theory, vol. 58, no. 6, pp. 3654–3679, 2012
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.