Recognition: unknown
AAFLOW: Scalable Patterns for Agentic AI Workflows
Pith reviewed 2026-05-08 17:21 UTC · model grok-4.3
The pith
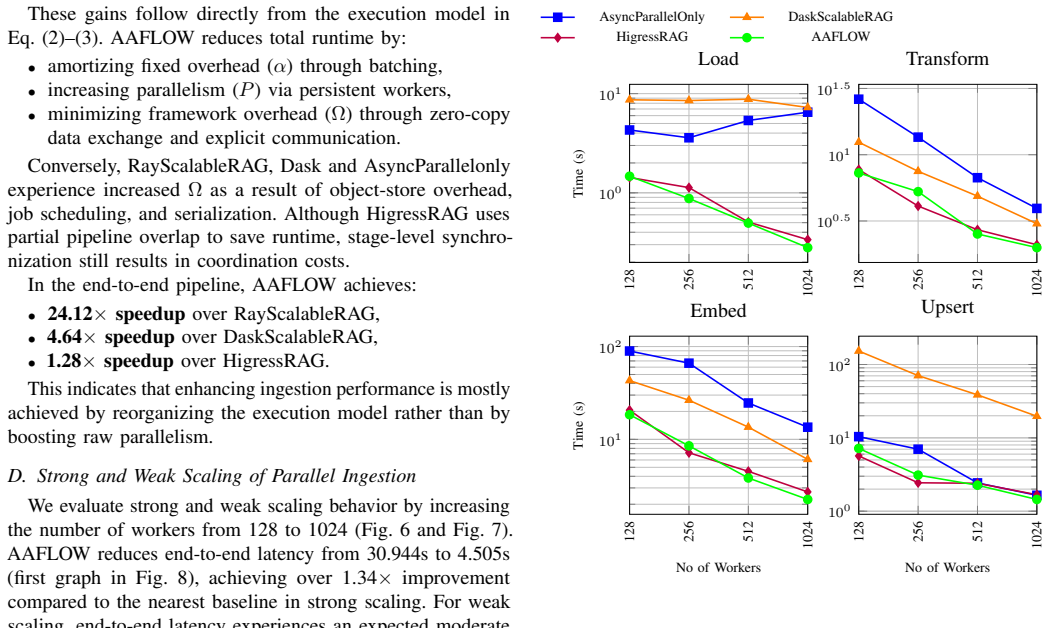
AAFLOW models agentic workflows as operators in a distributed runtime to deliver up to 4.64 times pipeline speedup through zero-copy data flows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AAFLOW is a unified distributed runtime that creates communication-efficient execution plans by modeling agentic workflows as an operator abstraction. Using Apache Arrow and Cylon, it builds a zero-copy data plane for direct interoperability between preprocessing, embedding, and vector retrieval. Resource-deterministic scheduling and asynchronous batching reduce coordination costs, yielding up to 4.64 times pipeline speedup and 2.8 times gains in embedding and upsert phases while LLM generation throughput stays comparable; the gains come from better data flow, batching, and communication efficiency rather than faster inference.
What carries the argument
Operator abstraction of agentic workflows, realized through a zero-copy data plane built on Apache Arrow and Cylon plus resource-deterministic scheduling and asynchronous batching.
If this is right
- Agentic workflows acquire a scalable and reproducible execution model that follows high-performance computing principles.
- Data-intensive phases such as embedding and vector upsert improve by factors of 2.8 without any change to LLM generation speed.
- Preprocessing, embedding, and retrieval stages interoperate directly without serialization costs.
- Coordination overhead drops through deterministic resource scheduling and asynchronous batching in distributed settings.
Where Pith is reading between the lines
- The same operator-plus-zero-copy pattern could be applied to other data-heavy AI pipelines such as fine-tuning or evaluation loops.
- Standardizing on a common data plane might reduce fragmentation across different agent frameworks over time.
- Testing the abstraction on workflows with highly variable or conditional branching would reveal how far the model generalizes.
Load-bearing premise
That agentic workflows can be effectively modeled as an operator abstraction without losing flexibility or that the experimental benchmarks represent typical real-world usage patterns.
What would settle it
A benchmark set of complex agentic workflows that cannot be expressed as operators without major loss of behavior, or real-world runs that show no measurable speedup once data patterns differ from the tested cases.
Figures







read the original abstract
Agentic workflows in large language model systems integrate retrieval, reasoning, and memory, but existing frameworks suffer from scalability and reproducibility limitations due to fragmented data orchestration, serialization overhead, and non-deterministic execution. Although these frameworks increase flexibility, they don't have a formal execution model that adheres to the principles of high-performance computing. We introduce AAFLOW, a unified distributed runtime that creates communication-efficient execution plans by modeling agentic workflows as an operator abstraction. Using Apache Arrow and Cylon, AAFLOW creates a zero-copy data plane that allows direct interoperability between preprocessing, embedding, and vector retrieval without the need for serialization overhead. To lower coordination costs, it uses resource-deterministic scheduling and asynchronous batching. While retaining comparable LLM generation throughput, experimental results demonstrate up to 4.64 times pipeline speedup and 2.8 times gains in embedding and upsert phases. Rather than LLM inference acceleration, these advantages result from enhanced data flow, batching, and communication efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AAFLOW, a unified distributed runtime for agentic AI workflows in LLM systems. It models these workflows as an operator abstraction to generate communication-efficient execution plans, leveraging Apache Arrow and Cylon for a zero-copy data plane that enables direct interoperability between preprocessing, embedding, and vector retrieval. Resource-deterministic scheduling and asynchronous batching are used to reduce coordination costs. The abstract claims that this yields up to 4.64 times pipeline speedup and 2.8 times gains in embedding and upsert phases while preserving LLM generation throughput, with advantages attributed solely to data flow, batching, and communication efficiency rather than inference acceleration.
Significance. If the performance claims and the operator abstraction hold under scrutiny, AAFLOW could represent a meaningful step toward scalable, reproducible agentic workflows by importing HPC-style execution models into LLM orchestration frameworks. The emphasis on zero-copy data planes and deterministic scheduling addresses real pain points in fragmented data handling. However, the absence of any experimental methodology, baselines, or analysis in the manuscript prevents a positive assessment of significance at present.
major comments (2)
- [Abstract] Abstract: The abstract asserts specific quantitative speedups (up to 4.64x pipeline and 2.8x in embedding/upsert phases) but supplies no experimental methodology, baselines, datasets, hardware configuration, error bars, or statistical details, rendering it impossible to evaluate whether the data support the central performance claims.
- [Abstract] Abstract: The operator abstraction is asserted to model agentic workflows without loss of flexibility, yet no description is provided of how dynamic, non-deterministic control flow (conditional branching, loops, and tool selection driven by LLM outputs) is expressed as operators or kept inside the zero-copy plane; if fallback mechanisms or additional coordination layers are required, the reported speedups would not generalize beyond static pipelines.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript introducing AAFLOW. The feedback highlights important areas for improvement in presenting our experimental claims and clarifying the operator abstraction's handling of dynamic workflows. We will revise the manuscript to incorporate detailed methodology and expanded descriptions, as outlined in our point-by-point responses below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts specific quantitative speedups (up to 4.64x pipeline and 2.8x in embedding/upsert phases) but supplies no experimental methodology, baselines, datasets, hardware configuration, error bars, or statistical details, rendering it impossible to evaluate whether the data support the central performance claims.
Authors: We agree that the manuscript as submitted does not include sufficient detail on the experimental methodology to support the quantitative claims in the abstract. The reported speedups derive from our evaluations of data flow, batching, and communication efficiency using Apache Arrow and Cylon, but to enable proper scrutiny we will add a dedicated Experiments section in the revision. This section will specify the baselines (e.g., comparisons against LangChain, LlamaIndex, and AutoGen), datasets and workloads used, hardware configurations, number of runs with error bars, and statistical analysis. The performance gains are isolated to the data plane and scheduling components rather than inference acceleration. revision: yes
-
Referee: [Abstract] Abstract: The operator abstraction is asserted to model agentic workflows without loss of flexibility, yet no description is provided of how dynamic, non-deterministic control flow (conditional branching, loops, and tool selection driven by LLM outputs) is expressed as operators or kept inside the zero-copy plane; if fallback mechanisms or additional coordination layers are required, the reported speedups would not generalize beyond static pipelines.
Authors: The operator model in AAFLOW expresses dynamic control flow through composable control operators (e.g., conditional and loop operators) that receive runtime decisions from LLM outputs and schedule subsequent data operators asynchronously. These control signals are passed within the zero-copy Arrow data plane alongside batched data to avoid serialization. We acknowledge that extremely frequent or complex branching may introduce limited coordination overhead outside the pure data plane. In the revised manuscript we will add a dedicated subsection with pseudocode examples illustrating how non-deterministic flows are modeled and will explicitly discuss the scope of the reported speedups (primarily for data-intensive segments) along with any limitations for highly dynamic cases. revision: partial
Circularity Check
No circularity: purely experimental claims with no derivations or self-referential reductions
full rationale
The manuscript introduces AAFLOW as an operator-based runtime for agentic workflows and reports empirical speedups (4.64x pipeline, 2.8x embedding/upsert) from zero-copy data planes, batching, and scheduling. No equations, fitted parameters, uniqueness theorems, or ansatzes appear; the central claims rest on benchmark measurements rather than any derivation that reduces to its own inputs by construction. Self-citations are absent from the load-bearing sections, and the operator abstraction is presented as a design choice whose validity is tested externally via experiments, not presupposed. The work is therefore self-contained against external benchmarks with no circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Agentic workflows integrate retrieval, reasoning, and memory and can be modeled as operator abstractions for execution planning.
invented entities (1)
-
AAFLOW
no independent evidence
Reference graph
Works this paper leans on
-
[1]
W. Ma, Y . Yang, Q. Hu, S. Ying, Z. Jin, B. Du, Z. Xing, T. Li, J. Shi, Y . Liuet al., “Rethinking testing for llm applications: Characteristics, challenges, and a lightweight interaction protocol,” 2025. [Online]. Available: https://arxiv.org/abs/2508.20737
-
[2]
What is llamaindex ?
E. R. Vanna Winland, “What is llamaindex ?” IBM, Tech. Rep., April
-
[3]
Available: https://www .ibm.com/think/topics/llamaindex
[Online]. Available: https://www .ibm.com/think/topics/llamaindex
-
[4]
Optimize vector databases, enhance rag-driven generative ai,
M. B. Cathy Zhang, “Optimize vector databases, enhance rag-driven generative ai,” Intel, Tech. Rep., March 2024. [Online]. Available: https://medium .com/intel-tech/optimize-vector- databases-enhance-rag-driven-generative-ai-90c10416cb9c
2024
-
[5]
Performance comparison of dask and apache spark on hpc systems for neuroimaging,
M. Dugré, V . Hayot-Sasson, and T. Glatard, “Performance comparison of dask and apache spark on hpc systems for neuroimaging,” p. e7635,
-
[6]
Available: https://doi.org/10.1002/cpe.7635
[Online]. Available: https://doi.org/10.1002/cpe.7635
-
[7]
H. Liang, X. Ma, Z. Liu, Z. H. Wong, Z. Zhao, Z. Meng, R. He, C. Shen, Q. Cai, Z. Hanet al., “Dataflow: An llm-driven framework for unified data preparation and workflow automation in the era of data-centric ai,”arXiv preprint arXiv:2512.16676, 2025. [Online]. Available: https://arxiv.org/abs/2512.16676
-
[8]
High performance dataframes from parallel processing patterns,
V . Abeykoon, P. Wickramasinghe, S. Kamburugamuve, H. Maithree, C. Widanage, N. Perera, T. A. Kanewala, A. Uyar, G. Gunduz, and G. Fox, “High performance dataframes from parallel processing patterns,” inParallel Processing and Applied Mathematics: 14th International Conference, PPAM 2022, Gdansk, Poland, September 11–14, 2022, Revised Selected Papers, Par...
2022
-
[9]
On the reproducibility limitations of rag systems,
B. Wang, D. Zhao, N. R. Tallent, and L. Guo, “On the reproducibility limitations of rag systems,” 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2509.18869
-
[10]
Simplify your rag application architecture with llamain- dex + postgresml,
LlamaIndex, “Simplify your rag application architecture with llamain- dex + postgresml,” https://www .llamaindex.ai/blog/simplify-your-rag- application-architecture-with-llamaindex-postgresml, accessed: October 7, 2025
2025
-
[11]
How to achieve 10x perfor- mance with vector database for llm using lancedb and pyarrow,
R. K. Choudhary, “How to achieve 10x perfor- mance with vector database for llm using lancedb and pyarrow,” https://www .rishabhxchoudhary.com/blog/ How_to_Achieve_10x_Performance_with_Vector_Database_for_LLM_using_LanceDB_and_PyArrow, accessed: October 7, 2025
2025
-
[12]
Radical-pilot and parsl: Executing heterogeneous workflows on hpc platforms,
A. Alsaadi, L. Ward, A. Merzky, K. Chard, I. Foster, S. Jha, and M. Turilli, “Radical-pilot and parsl: Executing heterogeneous workflows on hpc platforms,” in2022 IEEE/ACM Workshop on Workflows in Support of Large-Scale Science (WORKS). IEEE, 2022, pp. 27–34. [Online]. Available: https://doi.org/10.1109/WORKS56498.2022.00009
-
[13]
Retrieval-augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive nlp tasks,” inAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates...
2020
-
[14]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” inThe eleventh international conference on learning representations,
-
[15]
Available: https://openreview .net/pdf?id=WE_vluYUL-X
[Online]. Available: https://openreview .net/pdf?id=WE_vluYUL-X
-
[16]
Reflexion: language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: language agents with verbal reinforcement learning,” inProceedings of the 37th International Conference on Neural Information Processing Systems, ser. NIPS ’23. Red Hook, NY , USA: Curran Associates Inc., 2023. [Online]. Available: https://dl.acm.org/doi/10.5555/3666122.3666499
-
[17]
Retrieval-augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive nlp tasks,” inProceedings of the 34th International Conference on Neural Information Processing Systems, ser. NIPS ’20. Red Hook, NY , USA: Curran Associates I...
-
[18]
Accelerating embarrassingly parallel algorithm on intel mic,
Q. Wang, J. Liu, X. Tang, F. Wang, G. Fu, and Z. Xing, “Accelerating embarrassingly parallel algorithm on intel mic,” in 2014 IEEE International Conference on Progress in Informatics and Computing, 2014, pp. 213–218. [Online]. Available: https: //doi.org/10.1109/PIC.2014.6972327
-
[19]
Ucx: An open source framework for hpc network apis and beyond,
P. Shamis, M. G. Venkata, M. G. Lopez, M. B. Baker, O. Hernandez, Y . Itigin, M. Dubman, G. Shainer, R. L. Graham, L. Liss, Y . Shahar, S. Potluri, D. Rossetti, D. Becker, D. Poole, C. Lamb, S. Kumar, C. Stunkel, G. Bosilca, and A. Bouteiller, “Ucx: An open source framework for hpc network apis and beyond,” in2015 IEEE 23rd Annual Symposium on High-Perfor...
-
[20]
L. Dalcin, R. Paz, and M. Storti, “Mpi for python,”Journal of Parallel and Distributed Computing, vol. 65, no. 9, pp. 1108–1115, Sep. 2005. [Online]. Available: https://doi.org/10.1016/j.jpdc.2005.03.010
-
[21]
High performance data engineering everywhere,
C. Widanage, N. Perera, V . Abeykoon, S. Kamburugamuve, T. A. Kanewala, H. Maithree, P. Wickramasinghe, A. Uyar, G. Gunduz, and G. Fox, “High performance data engineering everywhere,” in2020 IEEE International Conference on Smart Data Services (SMDS). IEEE, 2020, pp. 122–132. [Online]. Available: https: //doi.org/10.1109/SMDS49396.2020.00022
-
[22]
In-depth analysis on parallel processing patterns for high-performance dataframes,
N. Perera, A. K. Sarker, M. Staylor, G. von Laszewski, K. Shan, S. Kamburugamuve, C. Widanage, V . Abeykoon, T. A. Kanewela, and G. Fox, “In-depth analysis on parallel processing patterns for high-performance dataframes,”Future Generation Computer Systems, vol. 149, pp. 250–264, 2023. [Online]. Available: https: //doi.org/10.1016/j.future.2023.07.007
-
[23]
Deep rc: A scalable data engineering and deep learning pipeline,
A. K. Sarker, A. Alsaadi, A. J. Halpern, P. Tangella, M. Titov, N. Perera, M. Staylor, G. von Laszewski, S. Jha, and G. Fox, “Deep rc: A scalable data engineering and deep learning pipeline,” inJob Scheduling Strategies for Parallel Processing: 28th International Workshop, JSSPP 2025, Milan, Italy, June 3–4, 2025, Revised Selected Papers. Berlin, Heidelbe...
-
[25]
Available: https://arxiv.org/abs/2512.20795
[Online]. Available: https://arxiv.org/abs/2512.20795
-
[26]
Architecture,
S. K. Niranda Perera, “Architecture,” Cylon, Tech. Rep., May 2022. [Online]. Available: https://cylondata.org/docs/arch/
2022
-
[27]
Radical-cylon: A heterogeneous data pipeline for scientific computing,
A. K. Sarker, A. Alsaadi, N. Perera, M. Staylor, G. von Laszewski, M. Turilli, O. O. Kilic, M. Titov, A. Merzky, S. Jha et al., “Radical-cylon: A heterogeneous data pipeline for scientific computing,” inJob Scheduling Strategies for Parallel Processing. Springer Nature Switzerland, 2024, pp. 84–102. [Online]. Available: https://doi.org/10.1007/978-3-031-74430-3_5
-
[28]
Design and performance characterization of radical-pilot on leadership-class platforms,
A. Merzky, M. Turilli, M. Titov, A. Al-Saadi, and S. Jha, “Design and performance characterization of radical-pilot on leadership-class platforms,”IEEE Transactions on Parallel and amp; Distributed Systems, vol. 33, no. 04, pp. 818–829, apr 2022. [Online]. Available: https://doi.org/10.1109/TPDS.2021.3105994
-
[29]
Gloo: Collective communications library with various primitives for multi-machine training,
Facebookincubator, “Gloo: Collective communications library with various primitives for multi-machine training,” Facebook, Tech. Rep., March 2023. [Online]. Available: https://github .com/facebookincubator/ gloo"
2023
-
[30]
Combining serverless and high-performance computing paradigms to support ml data-intensive applications,
M. Staylor, A. K. Sarker, G. von Laszewski, G. Fox, Y . Cheng, and J. Fox, “Combining serverless and high-performance computing paradigms to support ml data-intensive applications,”Frontiers in High Performance Computing, 2026
2026
-
[31]
K. Shan, N. Perera, D. Lenadora, T. Zhong, A. Kumar Sarker, S. Kamburugamuve, T. Amila Kanewela, C. Widanage, and G. Fox, “Hybrid cloud and hpc approach to high-performance dataframes,” in2022 IEEE International Conference on Big Data (Big Data), 2022, pp. 2728–2736. [Online]. Available: https://doi .org/10.1109/ BigData55660.2022.10020958
-
[32]
Supercharging distributed computing environments for high-performance data engineering,
N. Perera, A. K. Sarker, K. Shan, A. Fetea, S. Kamburugamuve, T. A. Kanewala, C. Widanage, M. Staylor, T. Zhong, V . Abeykoon, G. von Laszewski, and G. Fox, “Supercharging distributed computing environments for high-performance data engineering,”Frontiers in High Performance Computing, vol. V olume 2 - 2024, 2024. [Online]. Available: https://doi.org/10.3...
-
[33]
Context rot: How increasing input tokens impacts llm performance,
K. Hong, A. Troynikov, and J. Huber, “Context rot: How increasing input tokens impacts llm performance,” Chroma, Tech. Rep., July 2025. [Online]. Available: https://trychroma.com/research/context-rot
2025
-
[34]
Generative benchmarking,
K. Hong, A. Troynikov, J. Huber, and M. McGuire, “Generative benchmarking,” Chroma, Tech. Rep., April 2025. [Online]. Available: https://trychroma.com/research/generative-benchmarking
2025
-
[35]
Billion-scale similarity search with GPUs
J. Johnson, M. Douze, and H. Jégou, “Billion-scale similarity search with gpus,”IEEE Transactions on Big Data, vol. 7, no. 3, pp. 535–547, 2021. [Online]. Available: https://doi.org/10.1109/TBDATA.2019.2921572
-
[36]
Llamaindex: Data framework for connecting large language models to data,
J. Liu, “Llamaindex: Data framework for connecting large language models to data,” LlamaIndex, Tech. Rep., 2023. [Online]. Available: https://github.com/jerryjliu/llama_index
2023
-
[37]
Evaluating chunking strategies for retrieval,
B. Smith and A. Troynikov, “Evaluating chunking strategies for retrieval,” Chroma, Tech. Rep., July 2024. [Online]. Available: https://trychroma.com/research/evaluating-chunking
2024
-
[38]
Pinecone: Scalable vector database for machine learning applications,
P. Developers, “Pinecone: Scalable vector database for machine learning applications,” Pinecone Systems Inc., Tech. Rep., May 2023. [Online]. Available: https://www.pinecone.io/
2023
-
[39]
From rag to agents: Building intelligent systems with memory and tools,
A. Karpathy, “From rag to agents: Building intelligent systems with memory and tools,” Eureka Labs, Tech. Rep., January 2022. [Online]. Available: https://karpathy.ai/agents-rag-memory
2022
-
[40]
Building custom ai workflows using langchain tools,
E. Davis, “Building custom ai workflows using langchain tools,” ThinkTide Global Research Journal, vol. 5, no. 4, pp. 54–62, 2024. [Online]. Available: https://thinktidejournal .com/index.php/TGRJ/article/ view/53/63
2024
-
[41]
Langgraph: Stateful multi-agent workflows,
L. Developer, “Langgraph: Stateful multi-agent workflows,” LangChain Inc, Tech. Rep., Jan 2024. [Online]. Available: https://blog.langchain.com/ langgraph-multi-agent-workflows
2024
-
[42]
Exploration of llm multi- agent application implementation based on langgraph+ crewai,
Z. Duan and J. Wang, “Exploration of llm multi- agent application implementation based on langgraph+ crewai,” arXiv preprint arXiv:2411.18241, 2024. [Online]. Available: https://doi.org/10.32388/R27SW4
-
[43]
[Online]
CrewAI Team,Kickoff Crew Asynchronously, 2026, accessed: 2026-02-18. [Online]. Available: https://docs.crewai.com/en/learn/kickoff-async
2026
-
[44]
Autogen: Enabling next-gen llm applications via multi-agent conversation,
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. E. Zhu, L. Jiang, X. Zhang, S. Zhang, A. Awadallah, R. W. White, D. Burger, and C. Wang, “Autogen: Enabling next-gen llm applications via multi-agent conversation,” inCOLM 2024, August 2024. [Online]. Available: https: //www.microsoft.com/en-us/research/publication/autogen-enabling- next-gen-llm-applications-v...
2024
-
[45]
Ray: A distributed framework for emerging {AI} applications,
P. Moritz, R. Nishihara, S. Wang, A. Tumanov, R. Liaw, E. Liang, M. Elibol, Z. Yang, W. Paul, M. I. Jordanet al., “Ray: A distributed framework for emerging {AI} applications,” in 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), 2018, pp. 561–577. [Online]. Available: https://www.usenix.org/system/files/osdi18-moritz.pdf
2018
-
[46]
[Online]
LlamaIndex Developers,Parallel Execution Ingestion Pipeline, LlamaIndex, 2024, accessed: 2026-02-13. [Online]. Available: https://developers .llamaindex.ai/python/examples/ingestion/ parallel_execution_ingestion_pipeline/
2024
-
[47]
Dask: Parallel computation with blocked algorithms and task scheduling,
M. Rocklin, “Dask: Parallel computation with blocked algorithms and task scheduling,” inProceedings of the 14th python in science conference, vol. 130. Citeseer, 2015, p. 136. [Online]. Available: https://proceedings.scipy.org/articles/Majora-7b98e3ed-013.pdf
2015
-
[48]
W. Lin, “Higress-rag: A holistic optimization framework for enterprise retrieval-augmented generation via dual hybrid retrieval, adaptive routing, and crag,”arXiv preprint arXiv:2602.23374, 2025. [Online]. Available: https://arxiv.org/abs/2602.23374
-
[49]
Higress,
Alibaba Cloud and the Higress Authors, “Higress,” https://github .com/ alibaba/higress, 2026, gitHub repository. Accessed: 2026-01-25
2026
-
[50]
Apache spark: a unified engine for big data processing,
M. Zaharia, R. S. Xin, P. Wendell, T. Das, M. Armbrust, A. Dave, X. Meng, J. Rosen, S. Venkataraman, M. J. Franklin, A. Ghodsi, J. Gonzalez, S. Shenker, and I. Stoica, “Apache spark: a unified engine for big data processing,”Commun. ACM, vol. 59, no. 11, p. 56–65, Oct
-
[51]
Apache Spark: A unified engine for big data processing,
[Online]. Available: https://doi.org/10.1145/2934664
-
[52]
Apache flink: Stream and batch processing in a single engine,
P. Carbone, A. Katsifodimos, S. Ewen, V . Markl, S. Haridi, and K. Tzoumas, “Apache flink: Stream and batch processing in a single engine,”The Bulletin of the Technical Committee on Data Engineering, vol. 38, no. 4, 2015. [Online]. Available: https://asterios.katsifodimos.com/assets/publications/flink-deb.pdf
2015
-
[53]
Towards scalable dataframe systems,
M. Petersohn, S. Macke, D. Xin, W. Ma, J. K. Wittenauer, S. Hoyer, R. Marcus, M. Zaharia, and B. Recht, “Towards scalable dataframe systems,”Proceedings of the VLDB Endowment (PVLDB), vol. 13, no. 12, pp. 2033–2046, 2020. [Online]. Available: https://doi.org/10.14778/3407790.3407807
-
[54]
Incremental perception on real time 3d data,
A. K. Sarker and F. X. Lin, “Incremental perception on real time 3d data,” inProceedings of the 23rd Annual International Workshop on Mobile Computing Systems and Applications, ser. HotMobile ’22. New York, NY , USA: Association for Computing Machinery, 2022, p. 68–73. [Online]. Available: https://doi.org/10.1145/3508396.3512875
-
[55]
Parsl: Pervasive parallel programming in python,
Y . Babuji, A. Woodard, Z. Li, D. S. Katz, B. Clifford, R. Kumar, L. Lacinski, R. Chard, J. M. Wozniak, I. Foster, M. Wilde, and K. Chard, “Parsl: Pervasive parallel programming in python,” in Proceedings of the 28th International Symposium on High-Performance Parallel and Distributed Computing, ser. HPDC ’19. New York, NY , USA: Association for Computing...
-
[56]
High-level messaging patterns,
ZMQ, “High-level messaging patterns,” Zeromq, Tech. Rep., October
-
[57]
Available: https://zguide .zeromq.org/docs/chapter2/ #High-Level-Messaging-Patterns"
[Online]. Available: https://zguide .zeromq.org/docs/chapter2/ #High-Level-Messaging-Patterns"
-
[58]
Pathways: Asynchronous distributed dataflow for ml,
P. Barham, A. Chowdhery, J. Dean, S. Ghemawat, S. Hand, D. Hurt, M. Isard, H. Lim, R. Pang, S. Royet al., “Pathways: Asynchronous distributed dataflow for ml,”Proceedings of Machine Learning and Systems, vol. 4, pp. 430–449, 2022. [Online]. Available: https://proceedings .mlsys.org/paper_files/paper/ 2022/file/37385144cac01dff38247ab11c119e3c-Paper.pdf
-
[59]
45 Geng Zhang, Xuanlei Zhao, Kai Wang, and Yang You
J. Yuan, X. Li, C. Cheng, J. Liu, R. Guo, S. Cai, C. Yao, F. Yang, X. Yi, C. Wuet al., “Oneflow: Redesign the distributed deep learning framework from scratch,”arXiv preprint arXiv:2110.15032, 2021. [Online]. Available: https://arxiv.org/abs/2110.15032
-
[60]
Dspy: Compiling declarative language model calls into self-improving pipelines,
O. Khattab, A. Singhvi, P. Maheshwari, Z. Zhang, K. Santhanam, S. Vardhamanan, S. Haq, A. Sharma, T. T. Joshi, H. Moazam, H. Miller, M. Zaharia, and C. Potts, “Dspy: Compiling declarative language model calls into self-improving pipelines,”The Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/p...
2024
-
[61]
and Zhang, Hao and Stoica, Ion , booktitle =
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the 29th Symposium on Operating Systems Principles, ser. SOSP ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 611–626. [Online]. Availabl...
-
[62]
Sglang: efficient execution of structured language model programs,
L. Zheng, L. Yin, Z. Xie, C. Sun, J. Huang, C. H. Yu, S. Cao, C. Kozyrakis, I. Stoica, J. E. Gonzalez, C. Barrett, and Y . Sheng, “Sglang: efficient execution of structured language model programs,” inProceedings of the 38th International Conference on Neural Information Processing Systems, ser. NIPS ’24. Red Hook, NY , USA: Curran Associates Inc., 2024. ...
-
[63]
Memorag: Boosting long context processing with global memory-enhanced retrieval augmentation,
H. Qian, Z. Liu, P. Zhang, K. Mao, D. Lian, Z. Dou, and T. Huang, “Memorag: Boosting long context processing with global memory-enhanced retrieval augmentation,” inProceedings of the ACM on Web Conference 2025, ser. WWW ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 2366–2377. [Online]. Available: https://doi.org/10.1145/3696410.3714805
-
[64]
Tuning llms by rag principles: Towards llm-native memory,
J. Wei, S. Wu, R. Liu, X. Ying, J. Shang, and F. Tao, “Tuning llms by rag principles: Towards llm-native memory,” arXiv preprint arXiv:2503.16071, 2025. [Online]. Available: https: //arxiv.org/abs/2503.16071
-
[65]
From RAG to memory: Non-parametric continual learning for large language models,
B. J. Gutiérrez, Y . Shu, W. Qi, S. Zhou, and Y . Su, “From RAG to memory: Non-parametric continual learning for large language models,” inForty-second International Conference on Machine Learning, 2025. [Online]. Available: https://openreview.net/forum?id=LWH8yn4HS2
2025
-
[66]
Cue rag: Dynamic multi-output cue memory under h framework for retrieval-augmented generation,
Y . Fu, D. Liu, B. Zhang, Z. Jiang, H. Mei, and J. Guan, “Cue rag: Dynamic multi-output cue memory under h framework for retrieval-augmented generation,”Neurocomputing, vol. 639, p. 130235,
-
[67]
Available: https://www .sciencedirect.com/science/article/ pii/S0925231225009075
[Online]. Available: https://www .sciencedirect.com/science/article/ pii/S0925231225009075
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.