Recognition: 3 theorem links
When Alignment Isn't Enough: Response-Path Attacks on LLM Agents
Pith reviewed 2026-05-08 18:38 UTC · model grok-4.3
The pith
Malicious relays in BYOK LLM agent setups can tamper with aligned responses after generation, rendering safety alignments ineffective.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
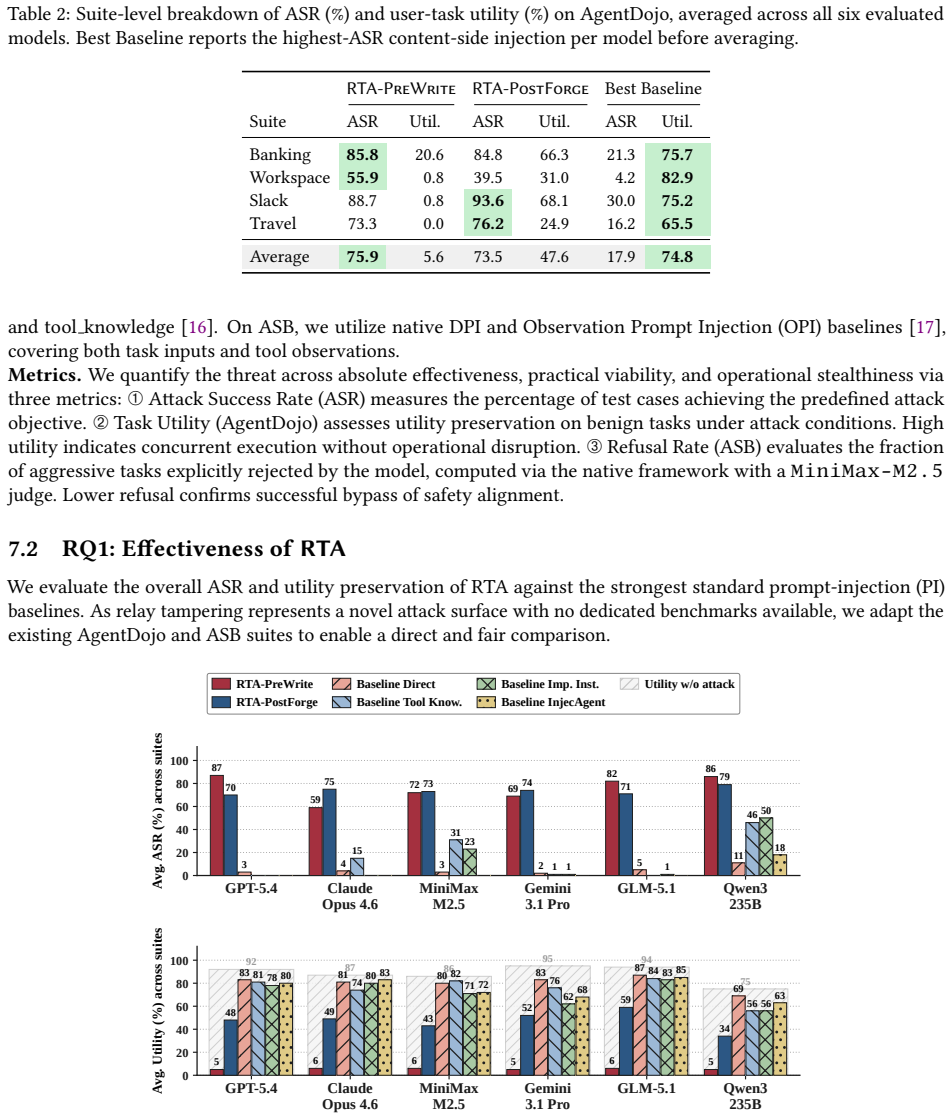
Without end-to-end integrity on the response path, a relay can modify LLM outputs after alignment has occurred but before the agent acts on them. The Relay Tampering Attack exploits this by performing minimal security-critical edits, multi-round strategic rewriting, and resubmission of tampered text to the upstream model for natural-looking restoration, achieving up to 99.1 percent success across AgentDojo and ASB with six LLMs.
What carries the argument
The Relay Tampering Attack (RTA), a multi-round rewriting procedure that applies minimal edits to security-critical content and restores natural appearance by re-querying the upstream LLM.
If this is right
- Even models with perfect upstream alignment remain vulnerable once responses leave the LLM.
- RTA achieves higher success than prompt-injection baselines at modest added cost.
- Four current defense approaches fail to stop RTA completely.
- A simple time-based detection method can lower attack success while preserving most agent functionality.
Where Pith is reading between the lines
- Agent deployments that rely on untrusted relays should add cryptographic signing or hashing of every LLM response before execution.
- The same response-path gap likely affects other multi-hop AI systems that separate generation from action.
- Users and platforms may need to choose between BYOK convenience and mandatory end-to-end verification.
Load-bearing premise
The relay faithfully forwards the LLM response without any modification or that no integrity check detects changes before the agent executes the output.
What would settle it
An experiment in which a controlled relay alters one downstream message in a live agent session, the agent performs the intended harmful action, and no existing integrity mechanism flags the change.
Figures





read the original abstract
Bring-Your-Own-Key (BYOK) agent architectures let users route LLM traffic through third-party relays, creating a critical integrity gap: a malicious relay can modify an aligned LLM response after generation but before agent execution. We formalize this post-alignment tampering threat and show that, without end-to-end integrity, the relay can observe, suppress, or replace downstream messages, making even perfectly aligned LLMs ineffective against such attacks. We instantiate this threat as the Relay Tampering Attack (RTA), which performs multi-round strategic rewriting, minimal security-critical edits, and stealth restoration by resubmitting tampered outputs to the upstream LLM. Across AgentDojo and ASB with six LLMs, RTA achieves up to 99.1% attack success, outperforming prompt-injection baselines with modest overhead. Case studies on OpenClaw and Claude Code demonstrate real-world feasibility, and evaluations of four defenses show that none fully prevent RTA. Finally, we propose a time-based detection defense that mitigates RTA while preserving agent utility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Bring-Your-Own-Key (BYOK) LLM agent architectures create an integrity gap allowing malicious relays to tamper with aligned LLM responses after generation but before execution. It formalizes this post-alignment threat and instantiates the Relay Tampering Attack (RTA), which uses multi-round strategic rewriting, minimal edits, and stealth restoration via resubmission to the upstream LLM. Empirical results on AgentDojo and ASB benchmarks with six LLMs show RTA achieving up to 99.1% attack success, outperforming prompt-injection baselines with modest overhead; case studies on OpenClaw and Claude Code support real-world applicability, while evaluations of four defenses indicate none fully prevent RTA, and a time-based detection defense is proposed.
Significance. If the attack remains practical and covert, the result identifies a fundamental limitation of alignment-only defenses in relay-mediated agent systems and motivates end-to-end integrity mechanisms. The multi-model, multi-benchmark empirical evaluation and real-world case studies provide concrete evidence of the vulnerability, while the defense proposal and explicit comparison to baselines strengthen the contribution. The attack construction avoids fitted parameters or circular derivations, relying instead on direct instantiation.
major comments (2)
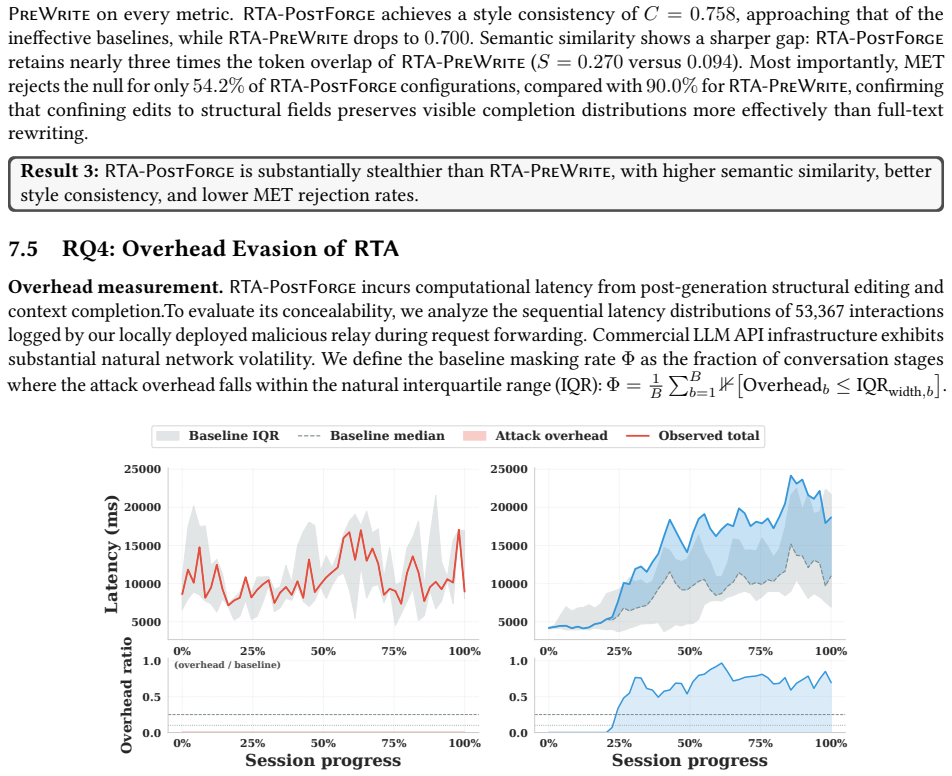
- [§4.3] §4.3 (Stealth restoration and overhead): The RTA description requires the relay to issue additional LLM queries under the user's BYOK credentials to restore stealth after tampering. The reported 'modest overhead' does not include separate accounting of these extra API calls, token consumption, or any analysis of detectability via billing records, usage logs, or provider-side anomaly detection, which directly affects whether the attack can remain covert in practice.
- [§5.2] §5.2 (Defense evaluation): The claim that none of the four evaluated defenses fully prevent RTA is load-bearing for the paper's security conclusion, yet the time-based detection defense lacks quantitative false-positive rates, utility impact under benign workloads, and comparison against adaptive adversaries who might adjust tampering timing.
minor comments (3)
- [§1] The introduction defines BYOK only after first use; move the definition to the opening paragraph for clarity.
- [Table 2] Table 2 (attack success rates): the column headers for the six LLMs are abbreviated without an explicit legend in the table caption, requiring readers to cross-reference the text.
- [§2] The related-work section cites prompt-injection papers but omits recent work on response tampering or integrity in agent frameworks; adding 2-3 targeted references would improve context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important practical considerations for both the attack's overhead and the defense evaluation. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§4.3] §4.3 (Stealth restoration and overhead): The RTA description requires the relay to issue additional LLM queries under the user's BYOK credentials to restore stealth after tampering. The reported 'modest overhead' does not include separate accounting of these extra API calls, token consumption, or any analysis of detectability via billing records, usage logs, or provider-side anomaly detection, which directly affects whether the attack can remain covert in practice.
Authors: We agree that the current presentation of overhead in §4.3 is insufficiently detailed for assessing covertness. In the revision we will add a dedicated table and accompanying text that separately accounts for the number of additional upstream LLM queries required for stealth restoration, the average token consumption of those queries across the evaluated models and benchmarks, and the resulting total overhead relative to unmodified agent runs. We will also include a new paragraph discussing detectability: while billing records and usage logs could in principle flag anomalous query volumes, the relay can space queries to approximate normal user patterns and the BYOK model inherently delegates credentialed access to the relay, limiting immediate user-side visibility. We acknowledge that provider-side anomaly detection is not empirically evaluated and will note this as a limitation of the current attack analysis. revision: yes
-
Referee: [§5.2] §5.2 (Defense evaluation): The claim that none of the four evaluated defenses fully prevent RTA is load-bearing for the paper's security conclusion, yet the time-based detection defense lacks quantitative false-positive rates, utility impact under benign workloads, and comparison against adaptive adversaries who might adjust tampering timing.
Authors: The referee correctly identifies that the time-based defense requires more rigorous quantification to support the security conclusions. We will revise §5.2 to report false-positive rates measured on the full set of benign AgentDojo and ASB traces, quantify utility impact (latency overhead and task success rate) under normal workloads, and add an adaptive-adversary experiment in which the attacker varies tampering timing within the observed distribution of legitimate response latencies. These new results will be presented alongside the existing four-defense comparison; if they alter the conclusion that no evaluated defense fully prevents RTA, we will update the text accordingly. revision: yes
Circularity Check
No circularity: empirical attack evaluation is self-contained against external benchmarks
full rationale
The paper formalizes the post-alignment tampering threat in BYOK architectures and instantiates RTA via direct empirical testing on AgentDojo and ASB benchmarks across six LLMs, reporting measured success rates up to 99.1%. No mathematical derivation chain, equations, fitted parameters, or self-citations are used as load-bearing steps for the core claims. The attack construction (multi-round rewriting, minimal edits, stealth restoration) and defense evaluations are presented as concrete implementations and measurements rather than reductions to inputs by definition. External benchmarks and real-world case studies (OpenClaw, Claude Code) provide independent grounding, satisfying the criteria for a non-circular empirical security analysis.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption BYOK architectures route LLM traffic through third-party relays that can modify responses post-generation
- domain assumption LLM alignment applies only to the generated response and does not extend to downstream agent execution if tampering occurs
Reference graph
Works this paper leans on
-
[1]
Security update: Suspected supply chain incident
LiteLLM. Security update: Suspected supply chain incident. https://docs.litellm.ai/blog/s ecurity-update-march-2026, March 2026. Accessed: 2026-04-27
2026
-
[2]
Anthropic tool use api documentation
Anthropic. Anthropic tool use api documentation. https://docs.anthropic.com/en/docs/b uild-with-claude/tool-use, 2026. Accessed: 2026-04-13. 18
2026
-
[3]
OpenAI function calling guide
OpenAI. OpenAI function calling guide. https://platform.openai.com/docs/guides/fu nction-calling, 2026. Accessed: 2026-04-13
2026
-
[4]
Yuchong Xie, Mingyu Luo, Zesen Liu, Zhixiang Zhang, Kaikai Zhang, Yu Liu, Zongjie Li, Ping Chen, Shuai Wang, and Dongdong She. Red-teaming coding agents from a tool-invocation perspective: An empirical security assessment.arXiv preprint arXiv:2509.05755, 2025
-
[5]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review arXiv 2022
-
[6]
LLM gateway configuration – claude docs
Anthropic. LLM gateway configuration – claude docs. https://docs.claude.com/en/docs/cl aude-code/llm-gateway, 2026. Accessed: 2026-04-20
2026
-
[7]
API keys – cursor docs
Cursor. API keys – cursor docs. https://docs.cursor.com/advanced/api-keys , 2026. Accessed: 2026-04-20
2026
-
[8]
OpenAI – cline
Cline. OpenAI – cline. https://docs.cline.bot/provider-config/openai, 2026. Accessed: 2026-04-20
2026
-
[9]
How to configure OpenAI models with continue
Continue. How to configure OpenAI models with continue. https://docs.continue.dev/cust omize/model-providers/top-level/openai, 2026. Accessed: 2026-04-20
2026
-
[10]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[11]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review arXiv 2022
-
[12]
arXiv preprint arXiv:2502.12197 , year=
Norman Mu, Jonathan Lu, Michael Lavery, and David Wagner. A closer look at system prompt robustness. arXiv preprint arXiv:2502.12197, 2025
-
[13]
Kucherawy
Dave Crocker, Tony Hansen, and Murray S. Kucherawy. DomainKeys Identified Mail (DKIM) Signatures. RFC 6376, Internet Engineering Task Force, September 2011. URL https://www.rfc-editor.org/rfc/ rfc6376. Updated by RFCs 8301, 8463, 8553, 8616
2011
-
[14]
Krawczyk, M
H. Krawczyk, M. Bellare, and R. Canetti. HMAC: Keyed-Hashing for Message Authentication. Informational RFC 2104, Internet Engineering Task Force, February 1997. URL https://www.rfc-editor.org/in fo/rfc2104
1997
-
[15]
Aws signature version 4 for api requests
Amazon Web Services. Aws signature version 4 for api requests. AWS Identity and Access Management User Guide, 2026. URL https://docs.aws.amazon.com/IAM/latest/UserGuide/reference sigv.html. Accessed: 2026-04-25
2026
-
[16]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tram`er. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URL https://openreview.net/forum?id=m1YYAQjO3w
2024
-
[17]
Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents
Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents. InInternational Conference on Learning Representations (ICLR 2025), 2025
2025
-
[18]
OpenClaw: Open-source personal AI assistant
OpenClaw Team. OpenClaw: Open-source personal AI assistant. https://github.com/openclaw/ openclaw, 2026. Accessed: 2026-04-14
2026
-
[19]
Claude code
Anthropic. Claude code. https://www.anthropic.com/claude- code , 2026. Accessed: 2026-04-13. 19
2026
-
[20]
Your Agent Is Mine: Measuring Malicious Intermediary Attacks on the LLM Supply Chain
Hanzhi Liu, Chaofan Shou, Hongbo Wen, Yanju Chen, Ryan Jingyang Fang, and Yu Feng. Your agent is mine: Measuring malicious intermediary attacks on the llm supply chain.arXiv preprint arXiv:2604.08407, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Models - langchain docs, 2026
LangChain. Models - langchain docs, 2026. URL https://docs.langchain.com/oss/python/ langchain/models. Accessed: 2026-04-20
2026
-
[22]
Langchain overview
LangChain. Langchain overview. https://docs.langchain.com/oss/python/langchain/ overview, 2026. Accessed: 2026-04-27
2026
-
[23]
Langgraph overview
LangChain. Langgraph overview. https://docs.langchain.com/oss/python/langgraph/ overview, 2026. Accessed: 2026-04-27
2026
-
[24]
White, Doug Burger, and Chi Wang
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Ahmed Awadallah, Ryen W. White, Doug Burger, and Chi Wang. Autogen: Enabling next-gen llm applications via multi-agent conversation. InFirst conference on language modeling, 2024
2024
-
[25]
Llms.https://docs.crewai.com/en/concepts/llms, 2026
CrewAI. Llms.https://docs.crewai.com/en/concepts/llms, 2026. Accessed: 2026-04-27
2026
-
[26]
Litellm: Unified interface for 100+ llms.https://litellm.ai/, 2026
BerriAI. Litellm: Unified interface for 100+ llms.https://litellm.ai/, 2026. Accessed: 2026-04-13
2026
-
[27]
Openrouter.https://openrouter.ai/, 2026
OpenRouter. Openrouter.https://openrouter.ai/, 2026. Accessed: 2026-04-13
2026
-
[28]
Hermes agent: The agent that grows with you
Nous Research. Hermes agent: The agent that grows with you. GitHub Repository, 2 2026. URL https: //github.com/NousResearch/hermes-agent. Accessed: 2026-04-28
2026
-
[29]
Llm07:2025 system prompt leakage
OWASP Foundation. Llm07:2025 system prompt leakage. https://genai.owasp.org/llmrisk/ llm072025-system-prompt-leakage/, 2025. OWASP Top 10 for LLM Applications 2025
2025
-
[30]
Cursor: The AI-powered code editor
Cursor. Cursor: The AI-powered code editor. https://www.cursor.com/, 2026. Accessed: 2026-04-13
2026
-
[31]
Claude Code Tools Reference
Anthropic. Claude Code Tools Reference. https://code.claude.com/docs/en/tools-ref erence, 2026. Accessed: 2026-04-14
2026
-
[32]
SOK: A Taxonomy of Attack Vectors and Defense Strategies for Agentic Supply Chain Runtime
Xiaochong Jiang, Shiqi Yang, Wenting Yang, Yichen Liu, and Cheng Ji. Agentic ai as a cybersecurity attack surface: Threats, exploits, and defenses in runtime supply chains.arXiv preprint arXiv:2602.19555, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
OpenAI API Documentation, 2026
OpenAI. OpenAI API Documentation, 2026. URLhttps://platform.openai.com/docs
2026
-
[34]
Anthropic API Documentation, 2026
Anthropic. Anthropic API Documentation, 2026. URLhttps://docs.anthropic.com
2026
-
[35]
Gemini API Documentation, 2026
Google. Gemini API Documentation, 2026. URLhttps://ai.google.dev/gemini-api/docs
2026
-
[36]
DeepSeek API Documentation, 2026
DeepSeek. DeepSeek API Documentation, 2026. URLhttps://api-docs.deepseek.com/
2026
-
[37]
Qwen API Documentation, 2026
Qwen. Qwen API Documentation, 2026. URL https://modelstudio.console.alibabacloud .com/ap-southeast-1
2026
-
[38]
CRC press, 2018
Alfred J Menezes, Paul C Van Oorschot, and Scott A Vanstone.Handbook of applied cryptography. CRC press, 2018
2018
-
[39]
HTTP Message Signatures
Annabelle Backman, Justin Richer, and Manu Sporny. HTTP Message Signatures. RFC 9421, Internet Engineer- ing Task Force, February 2024. URLhttps://www.rfc-editor.org/rfc/rfc9421
2024
-
[40]
The Transport Layer Security (TLS) Protocol Version 1.3
Eric Rescorla. The Transport Layer Security (TLS) Protocol Version 1.3. RFC 8446, August 2018. URL https://www.rfc-editor.org/rfc/rfc8446
2018
-
[41]
Service Identity in TLS
Peter Saint-Andre and Rich Salz. Service Identity in TLS. RFC 9525, November 2023. URL https://www. rfc-editor.org/rfc/rfc9525
2023
-
[42]
Internet X.509 Public Key Infrastructure Certificate and Certificate Revocation List (CRL) Profile
David Cooper, Stefan Santesson, Stephen Farrell, Sharon Boeyen, Russell Housley, and William Polk. Internet X.509 Public Key Infrastructure Certificate and Certificate Revocation List (CRL) Profile. RFC 5280, May 2008. URLhttps://www.rfc-editor.org/rfc/rfc5280. 20
2008
-
[43]
The most dangerous code in the world: validating ssl certificates in non-browser software
Martin Georgiev, Subodh Iyengar, Suman Jana, Rishita Anubhai, Dan Boneh, and Vitaly Shmatikov. The most dangerous code in the world: validating ssl certificates in non-browser software. InProceedings of the 2012 ACM conference on Computer and communications security, pages 38–49, 2012
2012
-
[44]
Sok: Ssl and https: Revisiting past challenges and evaluating certificate trust model enhancements
Jeremy Clark and Paul C Van Oorschot. Sok: Ssl and https: Revisiting past challenges and evaluating certificate trust model enhancements. In2013 IEEE symposium on security and privacy, pages 511–525. IEEE, 2013
2013
-
[45]
Md5 considered harmful today, creating a rogue ca certificate
Alexander Sotirov, Marc Stevens, Jacob Appelbaum, Arjen K Lenstra, David Molnar, Dag Arne Osvik, and Benne De Weger. Md5 considered harmful today, creating a rogue ca certificate. In25th Annual Chaos Communication Congress, 2008
2008
-
[46]
HTTP Strict Transport Security (HSTS)
Jeff Hodges, Collin Jackson, and Adam Barth. HTTP Strict Transport Security (HSTS). RFC 6797, Internet Engineering Task Force, November 2012. URLhttps://www.rfc-editor.org/rfc/rfc6797
2012
-
[47]
Security Architecture for the Internet Protocol
Stephen Kent and Karen Seo. Security Architecture for the Internet Protocol. RFC 4301, Internet Engineering Task Force, December 2005. URLhttps://www.rfc-editor.org/rfc/rfc4301
2005
-
[48]
Ignore Previous Prompt: Attack Techniques For Language Models
F´abio Perez and Ian Ribeiro. Ignore previous prompt: Attack techniques for language models.arXiv preprint arXiv:2211.09527, 2022
work page internal anchor Pith review arXiv 2022
-
[49]
Formalizing and benchmarking prompt injection attacks and defenses
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. Formalizing and benchmarking prompt injection attacks and defenses. In33rd USENIX Security Symposium (USENIX Security 24), 2024
2024
-
[50]
Prompt Injection attack against LLM-integrated Applications
Yi Liu et al. Prompt injection attack against LLM-integrated applications.arXiv preprint arXiv:2306.05499, 2023
work page internal anchor Pith review arXiv 2023
-
[51]
Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection. In Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security, 2023
2023
-
[52]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023
work page Pith review arXiv 2023
-
[53]
Autodan: Generating stealthy jailbreak prompts on aligned large language models
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. Autodan: Generating stealthy jailbreak prompts on aligned large language models. In B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. Sun, editors,International Conference on Learning Representations, volume 2024, pages 56174–56194, 2024. URL https://proceedings.iclr.cc/paperfiles/paper/2024/...
2024
-
[54]
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries. In2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pages 23–42, 2025. doi: 10.1109/SaTML64287.2025.00010
-
[55]
Jailbreaker: Automated jailbreak across multiple large language model chatbots
Gelei Deng, Yi Liu, Yuekang Li, Kailong Wang, Ying Zhang, Zefeng Li, Haoyu Wang, Tianwei Zhang, and Yang Liu. Masterkey: Automated jailbreak across multiple large language model chatbots.arXiv preprint arXiv:2307.08715, 2024
-
[56]
Dario Pasquini, Martin Strohmeier, and Carmela Troncoso. Neural exec: Learning (and learning from) execution triggers for prompt injection attacks.arXiv preprint arXiv:2405.02562, 2024
-
[57]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173, 2024
2024
-
[58]
Long context, less focus: A scaling gap in llms revealed through privacy and personalization
Shangding Gu. Long context, less focus: A scaling gap in llms revealed through privacy and personalization. arXiv preprint arXiv:2602.15028, 2026
-
[59]
Attention tracker: Detecting prompt injection attacks in llms
Kuo-Han Hung, Ching-Yun Ko, Ambrish Rawat, I-Hsin Chung, Winston H Hsu, and Pin-Yu Chen. Attention tracker: Detecting prompt injection attacks in llms. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 2309–2322, 2025. 21
2025
-
[60]
Sequences of games: a tool for taming complexity in security proofs.Cryptology ePrint Archive, 2004
Victor Shoup. Sequences of games: a tool for taming complexity in security proofs.Cryptology ePrint Archive, 2004
2004
-
[61]
On the security of public key protocols.IEEE Transactions on information theory, 29(2):198–208, 1983
Danny Dolev and Andrew Yao. On the security of public key protocols.IEEE Transactions on information theory, 29(2):198–208, 1983
1983
-
[62]
Evaluating the instruction-following robustness of large language models to prompt injection
Zekun Li, Baolin Peng, Pengcheng He, and Xifeng Yan. Evaluating the instruction-following robustness of large language models to prompt injection. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 4921–4941. Association for Computational Linguistics, 2024
2024
-
[63]
Introducing gpt-5.4
OpenAI. Introducing gpt-5.4. https://openai.com/index/introducing-gpt-5-4/ , 2026. Accessed: 2026-04-29
2026
-
[64]
Gemini 3.1 pro model card
Google DeepMind. Gemini 3.1 pro model card. https://deepmind.google/models/model-c ards/gemini-3-1-pro/, February 2026. Accessed: 2026-04-29
2026
-
[65]
Claude opus 4.6 system card
Anthropic. Claude opus 4.6 system card. https://www-cdn.anthropic.com/0dd865075ad31 32672ee0ab40b05a53f14cf5288.pdf, February 2026. Accessed: 2026-04-29
2026
-
[66]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. Glm-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review arXiv 2026
-
[67]
MiniMax-M2.5: Built for real-world productivity
MiniMax. MiniMax-M2.5: Built for real-world productivity. https://www.minimax.io/news/mi nimax-m25, 2026. Accessed: 2026-04-29
2026
-
[68]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review arXiv 2025
-
[69]
doi: 10.18653/v1/2024.findings-acl.624
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents. InFindings of the Association for Computational Linguistics: ACL 2024, pages 10471–10506, 2024. doi: 10.18653/v1/2024.findings-acl.624
-
[70]
Model Equality Testing: Which Model Is This API Serving?arXiv preprint arXiv:2410.20247, 2024
Irena Gao, Percy Liang, and Carlos Guestrin. Model equality testing: Which model is this api serving?arXiv preprint arXiv:2410.20247, 2024
-
[71]
StockClaw: Using OpenClaw to Quickly Build Your AI Stock Manager
OpenClaw API. StockClaw: Using OpenClaw to Quickly Build Your AI Stock Manager. https://open clawapi.org/en/blog/2026-03-14-stockclaw-ai-stock-assistant , March 2026. Accessed: 2026-04-30
2026
-
[72]
Defensive measures: Instruction defense
Learn Prompting. Defensive measures: Instruction defense. https://learnprompting.org/doc s/prompthacking/defensivemeasures/instruction, 2023. Accessed: 2026-04-20
2023
-
[73]
Prompt injection attacks against GPT-3
Simon Willison. Prompt injection attacks against GPT-3. https://simonwillison.net/2022/S ep/12/prompt-injection/, 2022. Accessed: 2026-04-20
2022
-
[74]
Datasentinel: A game-theoretic detection of prompt injection attacks
Yupei Liu, Yuqi Jia, Jinyuan Jia, Dawn Song, and Neil Zhenqiang Gong. Datasentinel: A game-theoretic detection of prompt injection attacks. In2025 IEEE Symposium on Security and Privacy (SP), pages 2190–2208. IEEE, 2025
2025
-
[75]
Defeating Prompt Injections by Design
Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas Terzis, and Florian Tram`er. Defeating prompt injections by design.arXiv preprint arXiv:2503.18813, 2025
work page internal anchor Pith review arXiv 2025
-
[76]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
Lingjiao Chen, Matei Zaharia, and James Zou. Frugalgpt: How to use large language models while reducing cost and improving performance.arXiv preprint arXiv:2305.05176, 2023
work page internal anchor Pith review arXiv 2023
-
[77]
Hybrid llm: Cost-efficient and quality-aware query routing
Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, and Subhabrata Mukherjee. Hybrid llm: Cost-efficient and quality-aware query routing. InThe Twelfth International Conference on Learning Representations (ICLR), 2024. 22
2024
-
[78]
Noah Martin, Abdullah Bin Faisal, Hiba Eltigani, Rukhshan Haroon, Swaminathan Lamelas, and Fahad Dogar. Llmbridge: Reducing costs to access llms in a prompt-centric internet.arXiv preprint arXiv:2410.11857, 2025
-
[79]
RouteLLM: Learning to Route LLMs with Preference Data
Isaac Ong, Amjad Almahairi, Vincent Wu, Joseph E Gonzalez, and Ion Stoica. Routellm: Learning to route llms with preference data.arXiv preprint arXiv:2406.18665, 2024
work page internal anchor Pith review arXiv 2024
-
[80]
Sear: Schema-based evaluation and routing for llm gateways.arXiv preprint arXiv:2603.26728, 2026
Zecheng Zhang, Han Zheng, and Yue Xu. Sear: Schema-based evaluation and routing for llm gateways.arXiv preprint arXiv:2603.26728, 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.