Recognition: 2 theorem links
· Lean TheoremKANs need curvature: penalties for compositional smoothness
Pith reviewed 2026-05-08 18:50 UTC · model grok-4.3
The pith
A basis-agnostic curvature penalty lets KANs fit data accurately while producing substantially smoother univariate activations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We derive a basis-agnostic curvature penalty and show that penalized models can maintain accuracy while achieving substantially smoother activations. Accounting for how function composition shapes curvature, we prove an upper bound on the full model's curvature relative to the curvature penalty, and use this to motivate richer forms of penalties.
What carries the argument
A basis-agnostic curvature penalty applied directly to the univariate activation functions, which bounds the curvature of the entire compositional model.
If this is right
- Penalized KANs retain predictive accuracy on the tasks examined while exhibiting substantially lower activation curvature.
- The proved upper bound relates the curvature of the full composed model directly to the sum of layer-wise penalties.
- The bound motivates the construction of richer, composition-aware penalty terms beyond the basic form.
- The resulting smoother activations improve the interpretability of the learned univariate functions without changing the network architecture.
Where Pith is reading between the lines
- Similar curvature penalties could be tested on other models whose outputs arise from explicit function compositions, such as certain physics-informed networks.
- If the smoother activations prove easier to inspect, they may allow direct reading of approximate physical laws from the learned univariate pieces on scientific datasets.
- The approach invites experiments that vary the strength of the penalty across layers to find the minimal regularization needed for a target smoothness level.
Load-bearing premise
That the curvature penalty can be added to training without introducing new fitting artifacts or overly restricting the model's ability to fit real data.
What would settle it
Training a KAN with the derived curvature penalty on a standard benchmark where unpenalized KANs reach high accuracy; if the penalized version shows both lower measured curvature in its activations and comparable test accuracy, the claim holds.
Figures



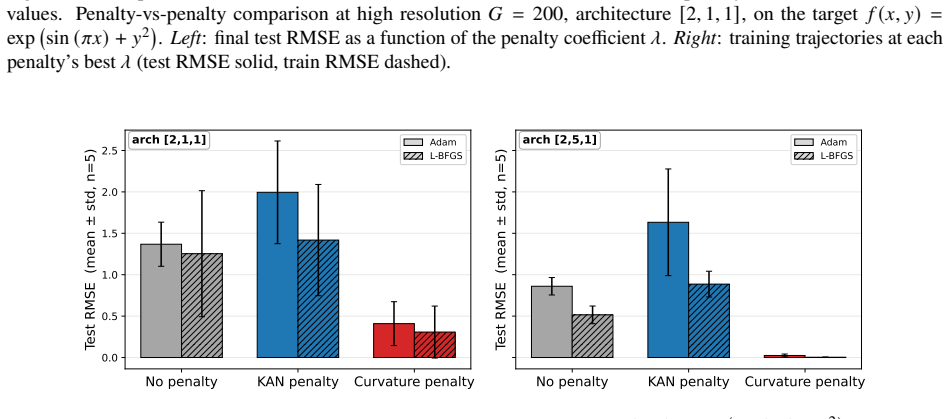
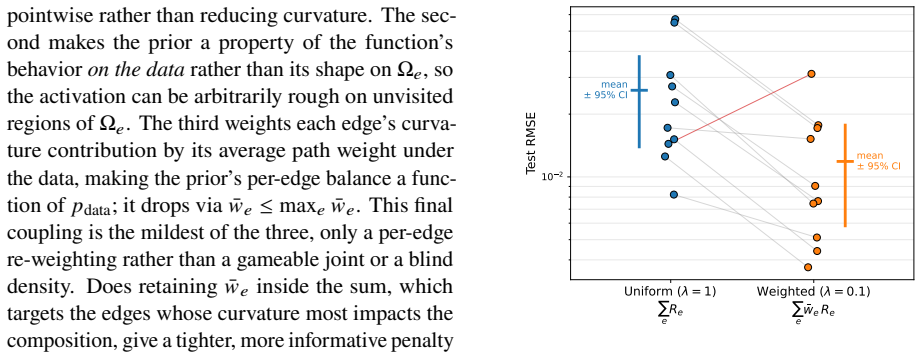

read the original abstract
Kolmogorov-Arnold networks (KANs) offer a potent combination of accuracy and interpretability, thanks to their compositions of learnable univariate activation functions. However, the activations of well-fitting KANs tend to exhibit pathologically high-curvature oscillations, making them difficult to interpret, and standard regularization penalties do not prevent this. Here we derive a basis-agnostic curvature penalty and show that penalized models can maintain accuracy while achieving substantially smoother activations. Accounting for how function composition shapes curvature, we prove an upper bound on the full model's curvature relative to the curvature penalty, and use this to motivate richer forms of penalties. Scientific machine learning is increasingly bottlenecked by the trade-off between accuracy and interpretability. Results such as ours that improve interpretability without sacrificing accuracy will further strengthen KANs as a practical tool for both prediction and insight.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives a basis-agnostic curvature penalty for Kolmogorov-Arnold networks (KANs) to mitigate high-curvature oscillations in learnable univariate activations. It empirically demonstrates that the penalty yields substantially smoother activations while preserving model accuracy, proves an upper bound on the curvature of the full composed model in terms of the penalty (accounting for composition via the chain rule on second derivatives), and uses the bound to motivate richer penalty forms. The work targets the accuracy-interpretability trade-off in scientific machine learning.
Significance. If the derivation, proof, and experiments hold, the result strengthens KANs as a practical tool by directly addressing a documented pathology (pathological oscillations) without sacrificing predictive performance. The proof of the composition-aware upper bound is a notable strength, as it provides a theoretical foundation rather than a purely heuristic fix, and the basis-agnostic penalty could generalize across KAN variants. This aligns with the growing need for interpretable models in scientific applications.
minor comments (3)
- [Proof section] The abstract states that a derivation and proof exist, but the manuscript should include the explicit form of the curvature penalty (e.g., the second-derivative expression) and the chain-rule steps in the proof section to allow direct verification of the upper bound.
- [Experiments] Empirical results would benefit from additional controls, such as ablation on the penalty strength hyperparameter and comparison against standard smoothness regularizers (e.g., total variation or Sobolev penalties), to confirm that the observed smoothness gains are not artifacts of the specific experimental setup.
- [Methods] Notation for the curvature measure (e.g., how it is computed for univariate activations versus the full network) should be defined consistently in the methods section to avoid ambiguity when applying the penalty in practice.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the composition-aware bound as a strength, and recommendation of minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper's central claims consist of deriving a basis-agnostic curvature penalty from first principles, empirically comparing penalized versus unpenalized KANs on accuracy and smoothness, and proving an upper bound on composed-model curvature via the chain rule applied to second derivatives. None of these steps reduce to self-definition, fitted parameters renamed as predictions, or load-bearing self-citations. The proof accounts for function composition explicitly and is independent of training data or model fits. The empirical results are direct observations rather than statistically forced re-expressions. This is the normal case of an independent mathematical and experimental argument.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard properties of curvature under function composition (chain rule and related inequalities)
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.AlphaCoordinateFixationwashburn_uniqueness_aczel; J_uniquely_calibrated_via_higher_derivative unclearWe derive a basis-agnostic curvature penalty ... R(f) = Σ_e (‖D²(β_e c_e)‖² + K_silu α_e²)
-
Foundation.BranchSelectionRCLCombiner_isCoupling_iff unclearf''(x) = φ^(2)''(φ^(1)(x))(φ^(1)'(x))² + φ^(2)'(φ^(1)(x))φ^(1)''(x) ... (Faà di Bruno for second-order)
Reference graph
Works this paper leans on
-
[1]
KAN: Kolmogorov-Arnold Networks
Z. Liu, Y. Wang, S. Vaidya, F. Ruehle, J. Halver- son, M. Solja ˇci´c, T. Y. Hou, and M. Tegmark, “KAN: Kolmogorov-Arnold networks,” inInternational Con- ference on Learning Representations (ICLR), 2025, arXiv:2404.19756. 1, 2, 4, 5
work page internal anchor Pith review arXiv 2025
-
[2]
A survey on Kolmogorov-Arnold network,
S. Somvanshi, S. A. Javed, M. M. Islam, D. Pandit, and S. Das, “A survey on Kolmogorov-Arnold network,”ACM Computing Surveys, vol. 58, no. 2, pp. 1–35, 2025. 1
2025
-
[3]
Kolmogorov-Arnold networks meet science,
Z. Liu, M. Tegmark, P. Ma, W. Matusik, and Y. Wang, “Kolmogorov-Arnold networks meet science,”Physical Review X, vol. 15, no. 4, p. 041051, 2025. 1
2025
-
[4]
Smooth Kolmogorov-Arnold networks enabling structural knowl- edge representation,
M. E. Samadi, Y. M¨ uller, and A. Schuppert, “Smooth Kolmogorov-Arnold networks enabling structural knowl- edge representation,”arXiv preprint arXiv:2405.11318,
-
[5]
Can kan work? exploring the potential of kolmogorov-arnold networks in computer vision
Y. Cang, Y. H. Liu, and L. Shi, “Can KAN work? Ex- ploring the potential of Kolmogorov-Arnold networks in computer vision,”arXiv preprint arXiv:2411.06727, 2024. 1, 3, 9
-
[6]
On the representations of continuous functions of many variables by superposition of continuous functions of one variable and addition,
A. N. Kolmogorov, “On the representations of continuous functions of many variables by superposition of continuous functions of one variable and addition,”Doklady Akademii Nauk SSSR, vol. 114, pp. 953–956, 1957. 1
1957
-
[7]
On functions of three variables,
V. I. Arnold, “On functions of three variables,” inCollected Works: Representations of Functions, Celestial Mechanics and KAM Theory, 1957–1965. Springer, 2009, pp. 5–8. 1
1957
-
[8]
A proof of the existence of analytic functions of several variables not representable by linear superpositions of continuously differentiable functions of fewer variables,
A. G. Vitushkin, “A proof of the existence of analytic functions of several variables not representable by linear superpositions of continuously differentiable functions of fewer variables,”Doklady Akademii Nauk SSSR, vol. 156, pp. 1258–1261, 1964. 1, 10
1964
-
[9]
Kolmogorov-Arnold networks (KANs) for time series analysis,
C. J. Vaca-Rubio, L. Blanco, R. Pereira, and M. Caus, “Kolmogorov-Arnold networks (KANs) for time series analysis,” in2024 IEEE Globecom Workshops (GC Wk- shps). IEEE, 2024, pp. 1–6. 1
2024
-
[10]
Gkan: Graph kolmogorov-arnold networks,
M. Kiamari, M. Kiamari, and B. Krishnamachari, “GKAN: Graph Kolmogorov-Arnold networks,”arXiv preprint arXiv:2406.06470, 2024. 1
-
[11]
Kolmogorov-Arnold Transformer,
X. Yang and X. Wang, “Kolmogorov-Arnold transformer,” arXiv preprint arXiv:2409.10594, 2024. 1
-
[12]
Multi-exit Kolmogorov– Arnold networks: enhancing accuracy and parsimony,
J. Bagrow and J. Bongard, “Multi-exit Kolmogorov– Arnold networks: enhancing accuracy and parsimony,” Machine Learning: Science and Technology, vol. 6, no. 3, p. 035037, 2025. 1
2025
-
[13]
Optimized Architectures for Kolmogorov-Arnold Networks
——, “Optimized architectures for Kolmogorov-Arnold networks,”arXiv preprint arXiv:2512.12448, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Adaptive training of 11 grid-dependent physics-informed Kolmogorov-Arnold net- works,
S. Rigas, M. Papachristou, T. Papadopoulos, F. Anag- nostopoulos, and G. Alexandridis, “Adaptive training of 11 grid-dependent physics-informed Kolmogorov-Arnold net- works,”IEEE Access, vol. 12, pp. 176 982–176 998, 2024. 1
2024
-
[15]
Training deep physics-informed Kolmogorov-Arnold networks,
S. Rigas, F. Anagnostopoulos, M. Papachristou, and G. Alexandridis, “Training deep physics-informed Kolmogorov-Arnold networks,”Computer Methods in Applied Mechanics and Engineering, vol. 452, p. 118761,
-
[16]
Initialization schemes for Kolmogorov–Arnold networks: An empirical study,
S. Rigas, D. Verma, G. Alexandridis, and Y. Wang, “Initialization schemes for Kolmogorov–Arnold networks: An empirical study,” inInternational Conference on Learning Representations (ICLR), 2026. [Online]. Avail- able: https://openreview.net/forum?id=dwNXKkiP51 1
2026
-
[17]
Data- driven model discovery with Kolmogorov-Arnold net- works,
S. Panahi, M. Moradi, E. M. Bollt, and Y.-C. Lai, “Data- driven model discovery with Kolmogorov-Arnold net- works,”Physical Review Research, vol. 7, no. 2, p. 023037,
-
[18]
Opening the black-box: symbolic regression with Kolmogorov- Arnold networks for energy applications,
N. R. Panczyk, O. F. Erdem, and M. I. Radaideh, “Opening the black-box: symbolic regression with Kolmogorov- Arnold networks for energy applications,”arXiv preprint arXiv:2504.03913, 2025. 1
-
[19]
Softly symbolify- ing Kolmogorov-Arnold networks,
J. Bagrow and J. Bongard, “Softly symbolify- ing Kolmogorov-Arnold networks,”arXiv preprint arXiv:2512.07875, 2025. 1
-
[20]
Flexible smoothing with B-splines and penalties,
P. H. C. Eilers and B. D. Marx, “Flexible smoothing with B-splines and penalties,”Statistical Science, vol. 11, no. 2, pp. 89–121, 1996. 3, 9
1996
-
[21]
Splines, knots, and penalties,
——, “Splines, knots, and penalties,”Wiley Interdisci- plinary Reviews: Computational Statistics, vol. 2, no. 6, pp. 637–653, 2010. 3, 9
2010
-
[22]
Twenty years of P-splines,
P. H. C. Eilers, B. D. Marx, and M. Durb´an, “Twenty years of P-splines,”SORT - Statistics and Operations Research Transactions, vol. 39, no. 2, pp. 149–186, 2015. 3, 9, 11
2015
-
[23]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,”arXiv preprint arXiv:1412.6980, 2014. 5
work page internal anchor Pith review arXiv 2014
-
[24]
On the limited memory bfgs method for large scale optimization,
D. C. Liu and J. Nocedal, “On the limited memory bfgs method for large scale optimization,”Mathematical pro- gramming, vol. 45, no. 1, pp. 503–528, 1989. 5
1989
-
[25]
A stochastic estimator of the trace of the influence matrix for laplacian smoothing splines,
M. Hutchinson, “A stochastic estimator of the trace of the influence matrix for laplacian smoothing splines,”Com- munications in Statistics - Simulation and Computation, vol. 19, no. 2, pp. 433–450, 1990. 7
1990
-
[26]
L. N. Zheng, W. E. Zhang, L. Yue, M. Xu, O. Maennel, and W. Chen, “Adaptive spline networks in the Kolmogorov-Arnold framework: Knot analysis and stability enhancement,” inProceedings of the 34th ACM International Conference on Information and Knowledge Management, ser. CIKM ’25. New York, NY, USA: Association for Computing Machinery, 2025, pp. 4434–4443....
-
[27]
A Dynamic Framework for Grid Adaptation in Kolmogorov-Arnold Networks
S. Rigas, T. Papaioannou, P. Trakadas, and G. Alexandridis, “A dynamic framework for grid adaptation in Kolmogorov- Arnold networks,”arXiv preprint arXiv:2601.18672, 2026. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Improving generalization performance using double backpropagation,
H. Drucker and Y. LeCun, “Improving generalization performance using double backpropagation,”IEEE Trans- actions on Neural Networks, vol. 3, no. 6, pp. 991–997,
-
[29]
Contractive auto-encoders: Explicit invariance during feature extraction,
S. Rifai, P. Vincent, X. Muller, X. Glorot, and Y. Bengio, “Contractive auto-encoders: Explicit invariance during feature extraction,” inProceedings of the 28th interna- tional conference on international conference on machine learning, 2011, pp. 833–840. 10
2011
-
[30]
Sobolev training for neural networks,
W. M. Czarnecki, S. Osindero, M. Jaderberg, G.´Swirszcz, and R. Pascanu, “Sobolev training for neural networks,” inAdvances in Neural Information Processing Systems (NeurIPS), 2017, arXiv:1706.04859. 10
-
[31]
Sorting out Lipschitz function approximation,
C. Anil, J. Lucas, and R. Grosse, “Sorting out Lipschitz function approximation,” inInternational Conference on Machine Learning (ICML), 2019. 10
2019
-
[32]
Spectral Normalization for Generative Adversarial Networks
T. Miyato, T. Kataoka, M. Koyama, and Y. Yoshida, “Spec- tral normalization for generative adversarial networks,” in International Conference on Learning Representations (ICLR), 2018, arXiv:1802.05957. 10
work page Pith review arXiv 2018
-
[33]
Lipschitz regularity of deep neural networks: analysis and efficient estimation,
A. Virmaux and K. Scaman, “Lipschitz regularity of deep neural networks: analysis and efficient estimation,” inAdvances in Neural Information Processing Systems (NeurIPS), 2018. 10
2018
-
[34]
Regu- larisation of neural networks by enforcing Lipschitz conti- nuity,
H. Gouk, E. Frank, B. Pfahringer, and M. J. Cree, “Regu- larisation of neural networks by enforcing Lipschitz conti- nuity,”Machine Learning, vol. 110, no. 2, pp. 393–416,
-
[35]
Learning smooth neural functions via Lipschitz regularization,
H.-T. D. Liu, F. Williams, A. Jacobson, S. Fidler, and O. Litany, “Learning smooth neural functions via Lipschitz regularization,” inACM SIGGRAPH 2022 Conference Proceedings, 2022. 10
2022
-
[36]
Beyond uniformity: Regu- larizing implicit neural representations through a Lipschitz lens,
J. McGinnis, S. Shit, F. A. H¨olzl, P. Friedrich, P. B¨ uschl, V. Sideri-Lampretsa, M. M¨ uhlau, P. C. Cattin, B. Menze, D. Rueckert, and B. Wiestler, “Beyond uniformity: Regu- larizing implicit neural representations through a Lipschitz lens,” inInternational Conference on Learning Represen- tations (ICLR), 2026. 10
2026
-
[37]
Robustness via curvature regularization, and vice versa,
S.-M. Moosavi-Dezfooli, A. Fawzi, J. Uesato, and P. Frossard, “Robustness via curvature regularization, and vice versa,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019. 10
2019
-
[38]
The curvature rate 𝜆: A scalar measure of input-space sharpness in neural networks,
J. Poschl, “The curvature rate 𝜆: A scalar measure of input-space sharpness in neural networks,”arXiv preprint arXiv:2511.01438, 2025. 10
-
[39]
Hessian regularization of deep neural networks: A novel approach based on stochastic estimators of Hessian trace,
Y. Liu, S. Yu, and T. Lin, “Hessian regularization of deep neural networks: A novel approach based on stochastic estimators of Hessian trace,”Neurocomputing, vol. 536, pp. 13–20, 2023. 10 12
2023
-
[40]
CR-SAM: Curvature regularized sharpness-aware minimization,
T. Wu, T. Luo, and D. C. Wunsch, “CR-SAM: Curvature regularized sharpness-aware minimization,” inProceed- ings of the AAAI Conference on Artificial Intelligence, 2024, arXiv:2312.13555. 10
-
[41]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga et al., “Pytorch: An imperative style, high-performance deep learning library,”Advances in neural information processing systems, vol. 32, 2019. 13
2019
-
[42]
Available: https://arxiv.org/abs/2405.06721
Z. Li, “Kolmogorov–Arnold Networks are radial basis function networks,”arXiv preprint arXiv:2405.06721,
-
[43]
FastKAN ablation in App
13 A Methods All experiments use PyTorch v2.5.1 [ 41] on CPU. FastKAN ablation in App. B uses the original im- plementation [42]. Every B-spline KAN edge uses cubic (𝑘=3 ) splines on a fixed, uniform knot grid of size 𝐺, with a SiLU base. Each experiment draws 𝑛train =1024 training and 𝑛test ∈ {256,1024} test inputs uniformly from the target’s domainΩ⊂R 𝑑...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.