Recognition: 2 theorem links
· Lean TheoremMEMAUDIT: An Exact Package-Oracle Evaluation Protocol for Budgeted Long-Term LLM Memory Writing
Pith reviewed 2026-05-08 19:29 UTC · model grok-4.3
The pith
MEMAUDIT turns budgeted LLM memory writing into an exactly solvable optimization problem that isolates what gets preserved.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A MEMAUDIT package fixes an experience stream, candidate memory representations, storage costs, semantic evidence units, future-query requirements, and a budget, turning write-time memory selection into a finite auditable optimization problem with a certified denominator. We instantiate this protocol with a concave-over-modular semantic coverage objective under storage and one-representation-per-experience constraints, and compute exact package optima using branch-and-bound with MILP certification. Across controlled exact packages, validity-heavy stress tests, human-audited natural support slices, and exported Mem0, A-Mem, and Letta stores, MEMAUDIT separates representation quality, validity
What carries the argument
The MEMAUDIT package, which fixes an experience stream, candidate memory representations, storage costs, semantic evidence units, future-query requirements, and a budget to enable exact optimization and auditing of memory writing.
If this is right
- Representation quality, validity-state preservation, and budget-aware selection become separately measurable rather than entangled in final accuracy scores.
- Memory writers from external systems can be scored against certified optimal selections on the same reusable packages.
- Package generators and solvers provide a reproducible way to evaluate what any memory method actually preserves under a given storage budget.
- The protocol supports both synthetic controlled tests and human-audited natural support slices for broader validation.
Where Pith is reading between the lines
- Future memory algorithms could be trained to directly approximate the exact optima defined by the package objective instead of relying only on end-to-end QA signals.
- The fixed-package approach could extend to other resource-constrained agent components such as planning or tool selection.
- Adding uncertainty over possible future queries within packages might better approximate truly open-ended use while retaining exact solvability.
- The separation of effects demonstrated here could inform evaluation protocols for other compressed representations in sequential decision systems.
Load-bearing premise
That the predefined candidate memory representations, semantic evidence units, and future-query requirements chosen for a fixed package can be selected without bias that fails to capture open-ended real-world memory needs.
What would settle it
If the exact optima identified by the solver on a package do not produce measurably higher downstream task performance than suboptimal selections when the same fixed package is used inside actual LLM agent runs.
Figures

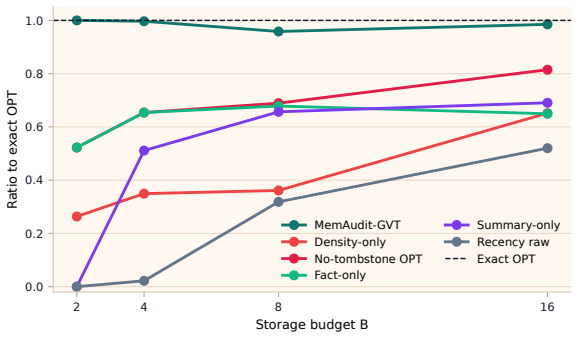


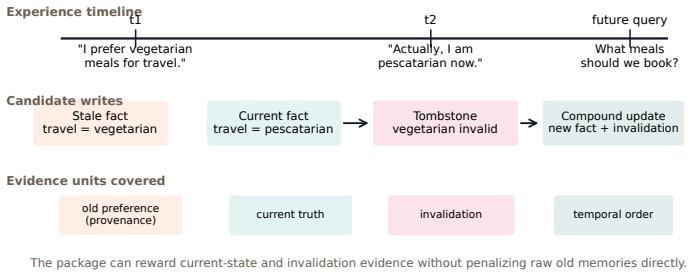
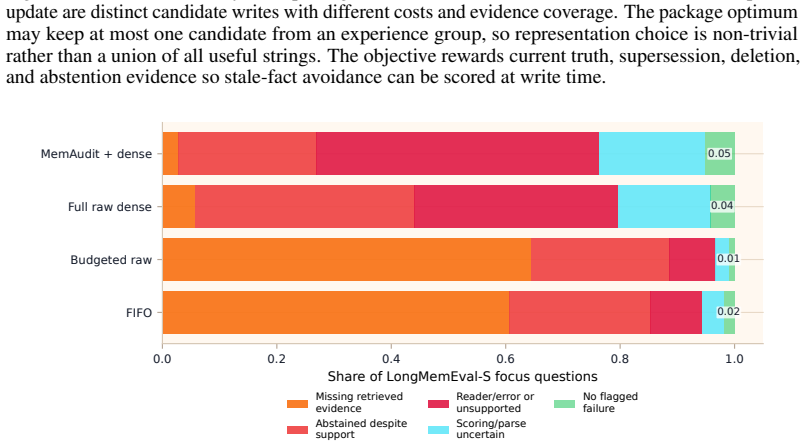

read the original abstract
Long-term LLM agents must compress streams of past interactions into persistent memory before future queries are known. Existing evaluations usually measure final question-answering accuracy, which entangles memory writing with retrieval, prompting, and reader reasoning. We introduce MEMAUDIT, an exact packageoracle evaluation protocol for budgeted long-term memory writing. A MEMAUDIT package fixes an experience stream, candidate memory representations, storage costs, semantic evidence units, future-query requirements, and a budget, turning write-time memory selection into a finite auditable optimization problem with a certified denominator. We instantiate this protocol with a concave-over-modular semantic coverage objective under storage and one-representation-per-experience constraints, and compute exact package optima using branch-and-bound with MILP certification. Across controlled exact packages, validity-heavy stress tests, human-audited natural support slices, and exported Mem0, A-Mem, and Letta stores, MEMAUDIT separates representation quality, validity-state preservation, and budget-aware selection effects that end-to-end QA cannot localize. The resulting artifact provides reusable package generators, certified solvers, natural package exports, external-system scorers, and cached reproducibility metadata for evaluating what memory writers actually preserve under fixed storage budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MEMAUDIT, an exact package-oracle evaluation protocol for budgeted long-term LLM memory writing. It fixes an experience stream, candidate memory representations, storage costs, semantic evidence units, future-query requirements, and a budget to convert write-time selection into a finite auditable optimization problem. The protocol instantiates a concave-over-modular semantic coverage objective under storage and one-representation-per-experience constraints, solved exactly via branch-and-bound with MILP certification. Evaluations across controlled exact packages, validity-heavy stress tests, human-audited natural support slices, and exported stores from Mem0, A-Mem, and Letta claim to separate representation quality, validity-state preservation, and budget-aware selection effects that end-to-end QA cannot localize. Reusable artifacts (package generators, certified solvers, natural exports, external scorers, and cached metadata) are provided.
Significance. If the separation claims hold without package-induced bias, MEMAUDIT would offer a more precise, localized alternative to entangled end-to-end QA for evaluating LLM memory writers under fixed budgets. The use of exact optimization with branch-and-bound and MILP certification, together with reusable package generators and reproducibility metadata, is a clear strength that supports falsifiable, auditable comparisons.
major comments (1)
- Abstract and protocol definition: The central claim that MEMAUDIT separates representation quality, validity-state preservation, and budget-aware selection effects (independent of end-to-end QA) requires that predefined candidate memory representations, semantic evidence units, and future-query requirements can be chosen without introducing bias that fails to capture open-ended real-world memory needs. The manuscript provides no explicit validation, sensitivity analysis, or neutrality checks for the package generators, which is load-bearing for the separation results and risks making observed effects artifacts of the controlled setup.
minor comments (2)
- Abstract: Define MILP on first use and clarify the precise form of the concave-over-modular objective (e.g., how submodularity and concavity are established for the semantic coverage function).
- Evaluation sections: Specify the auditing protocol, number of auditors, and inter-annotator agreement metrics for the 'human-audited natural support slices' to allow replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the potential for package-induced bias and the need for explicit validation of the separation claims. We address the major comment below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract and protocol definition: The central claim that MEMAUDIT separates representation quality, validity-state preservation, and budget-aware selection effects (independent of end-to-end QA) requires that predefined candidate memory representations, semantic evidence units, and future-query requirements can be chosen without introducing bias that fails to capture open-ended real-world memory needs. The manuscript provides no explicit validation, sensitivity analysis, or neutrality checks for the package generators, which is load-bearing for the separation results and risks making observed effects artifacts of the controlled setup.
Authors: We agree that the separation claims are load-bearing on the neutrality of the chosen candidates, evidence units, and query requirements, and that the manuscript currently lacks dedicated sensitivity analysis or neutrality checks for the package generators. The protocol itself is defined to be general and auditable, with all package generators, certified solvers, natural exports, and reproducibility metadata released as reusable artifacts precisely to enable external inspection and extension. Nevertheless, the current evaluations rely on controlled exact packages, validity stress tests, human-audited natural slices, and exported stores from Mem0/A-Mem/Letta without quantifying robustness to generator parameter choices. In the revision we will add a dedicated subsection in the Evaluations section that performs sensitivity analysis by systematically varying the number of candidate representations per experience, the granularity of semantic evidence units, and the sampling of future-query requirements. We will report how the measured separations between representation quality, validity-state preservation, and budget-aware selection effects change (or remain stable) under these perturbations. We will also expand the Limitations and Discussion sections to explicitly discuss potential setup biases and the mitigating role of the human-audited natural slices. These additions directly address the referee's concern while preserving the core contribution of the exact package-oracle protocol. revision: yes
Circularity Check
No circularity: protocol defined independently with external benchmarks
full rationale
The paper introduces MEMAUDIT as an independent evaluation framework that fixes experience streams, candidates, costs, evidence units, queries, and budgets to create an auditable optimization problem solved exactly via branch-and-bound and MILP. It then applies this to controlled packages, stress tests, human-audited slices, and exported stores from Mem0, A-Mem, and Letta. No step reduces a claimed result to a fitted parameter, self-definition, or self-citation chain; the separation of representation quality, validity preservation, and budget effects follows directly from the oracle setup and external comparisons rather than from any input that presupposes the output.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A concave-over-modular semantic coverage objective meaningfully captures memory utility for unknown future queries
invented entities (2)
-
MEMAUDIT package
no independent evidence
-
semantic evidence units
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith.Cost.FunctionalEquation (Aczél-class classification of reciprocal cost)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
F(X) = Σ_r w_r h_r(Σ_{u∈X} a_ur), where each h_r is concave, nondecreasing, and normalized... Theorem 1 (Semantic coverage is monotone submodular).
-
Foundation/Atomicity.lean (finite combinatorial scheduling under precedence)atomic_tick unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We instantiate this protocol with a concave-over-modular semantic coverage objective under storage and one-representation-per-experience constraints, and compute exact package optima using branch-and-bound with MILP certification.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Streaming submodular maximization: Massive data summarization on the fly
Ashwinkumar Badanidiyuru, Baharan Mirzasoleiman, Amin Karbasi, and Andreas Krause. Streaming submodular maximization: Massive data summarization on the fly. InProceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 671–680. ACM, 2014
2014
-
[2]
The use of MMR, diversity-based reranking for reordering documents and producing summaries
Jaime Carbonell and Jade Goldstein. The use of MMR, diversity-based reranking for reordering documents and producing summaries. InProceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 335–336. ACM, 1998
1998
-
[3]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready AI agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review arXiv 2025
-
[4]
Streaming algorithms for maxi- mizing monotone submodular functions under a knapsack constraint
Chien-Chung Huang, Naonori Kakimura, and Yuichi Yoshida. Streaming algorithms for maxi- mizing monotone submodular functions under a knapsack constraint. InApproximation, Ran- domization, and Combinatorial Optimization. Algorithms and Techniques (APPROX/RANDOM 2017), volume 81 ofLeibniz International Proceedings in Informatics (LIPIcs), pages 11:1– 11:14,...
2017
-
[5]
BumbleBee: Dynamic KV-cache streaming submodular summarization for infinite-context transformers
Lilly Kumari, Shengjie Wang, Tianyi Zhou, Nikhil Sarda, Anthony Rowe, and Jeff Bilmes. BumbleBee: Dynamic KV-cache streaming submodular summarization for infinite-context transformers. InProceedings of the First Conference on Language Modeling, 2024
2024
-
[6]
Retrieval-augmented generation for knowledge-intensive NLP tasks.Advances in Neural Information Processing Systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks.Advances in Neural Information Processing Systems, 33:9459–9474, 2020
2020
-
[7]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents.arXiv preprint arXiv:2402.17753, 2024
work page internal anchor Pith review arXiv 2024
-
[8]
Nemhauser, Laurence A
George L. Nemhauser, Laurence A. Wolsey, and Marshall L. Fisher. An analysis of approxima- tions for maximizing submodular set functions—I.Mathematical Programming, 14(1):265–294, 1978
1978
-
[9]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems.arXiv preprint arXiv:2310.08560, 2023
work page internal anchor Pith review arXiv 2023
-
[10]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.arXiv preprint arXiv:2303.11366, 2023
work page internal anchor Pith review arXiv 2023
-
[11]
A note on maximizing a submodular set function subject to a knapsack constraint.Operations Research Letters, 32(1):41–43, 2004
Maxim Sviridenko. A note on maximizing a submodular set function subject to a knapsack constraint.Operations Research Letters, 32(1):41–43, 2004
2004
-
[12]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- memeval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813, 2024
work page internal anchor Pith review arXiv 2024
-
[13]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: Agentic memory for LLM agents.arXiv preprint arXiv:2502.12110, 2025
work page internal anchor Pith review arXiv 2025
-
[14]
arXiv preprint arXiv:2409.20163 , year=
Zeyu Zhang, Quanyu Dai, Luyu Chen, Zeren Jiang, Rui Li, Jieming Zhu, Xu Chen, Yi Xie, Zhenhua Dong, and Ji-Rong Wen. MemSim: A bayesian simulator for evaluating memory of LLM-based personal assistants.arXiv preprint arXiv:2409.20163, 2024
-
[15]
Memorybank: Enhancing large language models with long-term memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory.arXiv preprint arXiv:2305.10250, 2023. 10 A Deferred Proofs Proof of Theorem 1. Normalization follows from hr(0) = 0. For monotonicity, adding any element u increases each inner sum by aur ≥0 , and hr is nondecreasing. For submo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.