Recognition: 3 theorem links
· Lean TheoremSubmodular Benchmark Selection
Pith reviewed 2026-05-08 19:18 UTC · model grok-4.3
The pith
Selecting small benchmark subsets with mutual information under a multivariate Gaussian model improves imputation of large language model performance compared to entropy selection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
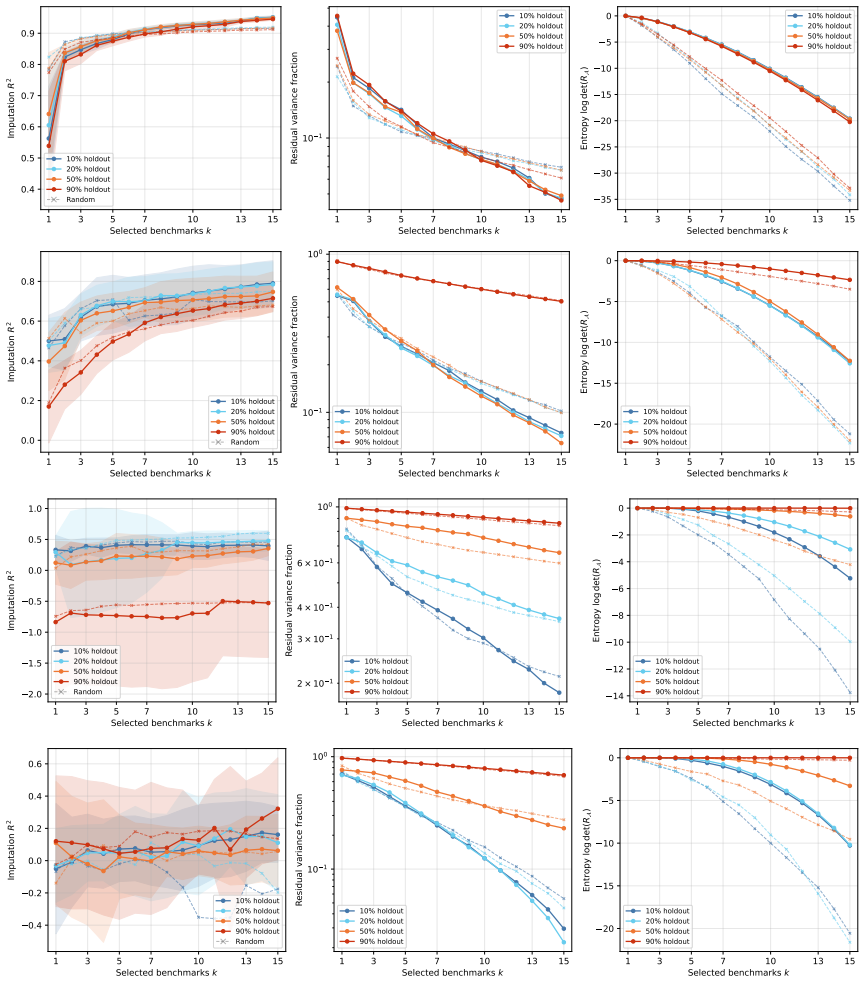
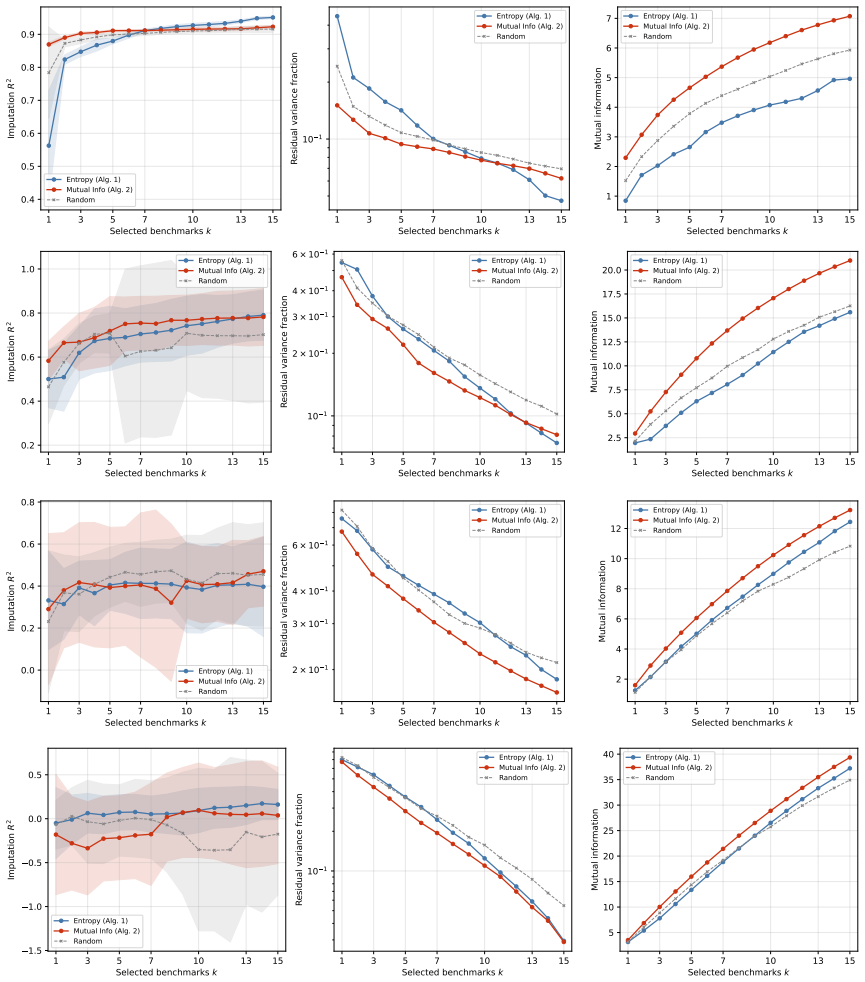
By modeling benchmark scores across models with a multivariate Gaussian, the selection of a small informative subset becomes a submodular maximization problem with natural objectives given by the entropy of the selected covariance or the mutual information between selected and remaining benchmarks. Both objectives are submodular, entropy selection matches pivoted Cholesky with spectral residual bounds, and mutual information, though generally non-monotone, is monotone for small subsets in practice and optimized greedily. Experiments on three matrices from ten public leaderboards demonstrate that mutual information selection outperforms entropy for imputation at small subset sizes.
What carries the argument
The multivariate Gaussian model of benchmark scores, from which entropy and mutual information are derived as submodular objectives for selecting informative subsets.
If this is right
- Entropy selection coincides with pivoted Cholesky and admits spectral residual bounds.
- Mutual information is empirically monotone for small subsets, allowing greedy optimization.
- Mutual information selection outperforms entropy for imputation at small subsets on leaderboard data.
Where Pith is reading between the lines
- This could lower the barrier to thorough model evaluation by minimizing the number of benchmarks needed.
- The technique may generalize to other correlated evaluation metrics beyond language models.
- Further work could explore how the selected subsets change as new models and benchmarks are added to leaderboards.
Load-bearing premise
The scores that models achieve on different benchmarks are well approximated by a multivariate Gaussian distribution with a covariance that remains stable and can be estimated from public leaderboards.
What would settle it
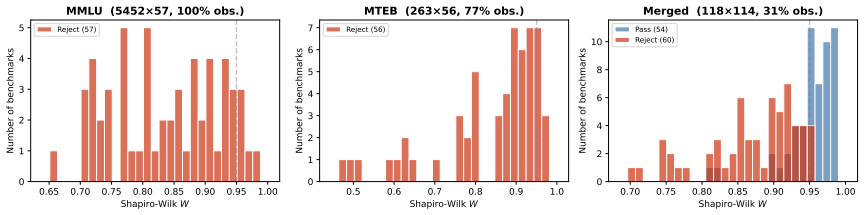
If experiments on additional sets of benchmark scores show that entropy selection achieves lower or equal imputation error compared to mutual information selection for small subsets, the claimed superiority would not hold.
Figures















read the original abstract
Evaluating large language models across many benchmarks is expensive, yet many benchmarks are highly correlated. We formalize the selection of a small, informative subset as submodular maximization under a multivariate Gaussian model. Entropy (log-determinant covariance) and mutual information between selected and remaining benchmarks arise as natural objectives. Both are submodular; entropy selection coincides with pivoted Cholesky and has spectral residual bounds, while mutual information is non-monotone in general but empirically monotone for small subsets, so we optimize it greedily. Experiments on three matrices from ten public leaderboards show that mutual information selection outperforms entropy for imputation at small subsets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes the selection of a small informative subset of benchmarks for LLM evaluation as a submodular maximization problem under a multivariate Gaussian model of benchmark scores. It derives entropy (log-determinant of the covariance) and mutual information (between selected and unselected benchmarks) as natural objectives, proves submodularity for entropy with spectral residual bounds, notes that mutual information is non-monotone in general but empirically monotone for small subsets (allowing greedy optimization), and reports experiments on three matrices derived from ten public leaderboards showing that mutual information selection outperforms entropy-based selection for imputation at small subset sizes.
Significance. If the multivariate Gaussian model and the reported outperformance hold, the work provides a principled, computationally efficient framework for reducing the cost of comprehensive LLM evaluation by identifying redundant benchmarks. The submodular formulation and explicit connection to pivoted Cholesky for entropy selection are strengths, as is the use of real leaderboard data for validation.
major comments (3)
- [Abstract and Experiments] Abstract and Experiments section: The central empirical claim that mutual information selection outperforms entropy for imputation rests on covariance matrices estimated directly from the same leaderboard data used to measure selection quality. No held-out models, external validation set, or cross-validation procedure is described, so the reported gains are not independent of the fitting procedure and may not generalize to new models.
- [Abstract and model description] Abstract and model description: Benchmark scores are bounded in [0,1], frequently discrete or skewed, and the number of models is often modest relative to the number of benchmarks. The paper provides no details on covariance estimation, regularization (to avoid singularity), or any diagnostic checks (e.g., normality tests or Q-Q plots) for the multivariate Gaussian assumption that underlies both objectives and the imputation metric.
- [Theory and Experiments] Theory and Experiments: Mutual information is stated to be non-monotone in general but 'empirically monotone for small subsets,' yet no quantitative details, error bars, or description of the test procedure (e.g., how many subsets were checked, on which matrices) are supplied. Without this, the justification for using the standard greedy algorithm lacks rigor.
minor comments (2)
- [Model section] Notation for the covariance matrix and its estimation procedure should be introduced with an explicit equation early in the model section.
- [Experiments] The three matrices used in experiments should be described with their dimensions (number of models vs. benchmarks) and any preprocessing steps.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. The concerns regarding empirical validation, model assumptions, and theoretical rigor are well-taken and point to opportunities to strengthen the manuscript. We address each major comment below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The central empirical claim that mutual information selection outperforms entropy for imputation rests on covariance matrices estimated directly from the same leaderboard data used to measure selection quality. No held-out models, external validation set, or cross-validation procedure is described, so the reported gains are not independent of the fitting procedure and may not generalize to new models.
Authors: We acknowledge that the current experiments estimate covariance and evaluate imputation performance on the same leaderboard data, which limits claims of generalization to entirely new models. The design was intended to demonstrate the method's behavior on real public leaderboards. In the revision we will add a cross-validation protocol that holds out a subset of models when estimating covariance and then measures imputation error on the held-out models. This will provide an out-of-sample assessment of the reported gains. revision: yes
-
Referee: [Abstract and model description] Abstract and model description: Benchmark scores are bounded in [0,1], frequently discrete or skewed, and the number of models is often modest relative to the number of benchmarks. The paper provides no details on covariance estimation, regularization (to avoid singularity), or any diagnostic checks (e.g., normality tests or Q-Q plots) for the multivariate Gaussian assumption that underlies both objectives and the imputation metric.
Authors: We agree that the manuscript should supply these implementation and diagnostic details. In the revised version we will expand the model section to describe: the covariance estimator employed (sample covariance with shrinkage or ridge regularization to ensure positive-definiteness), the handling of bounded and possibly discrete scores, and any normality diagnostics or explicit limitations of the Gaussian approximation. We will also discuss the implications of having fewer models than benchmarks. revision: yes
-
Referee: [Theory and Experiments] Theory and Experiments: Mutual information is stated to be non-monotone in general but 'empirically monotone for small subsets,' yet no quantitative details, error bars, or description of the test procedure (e.g., how many subsets were checked, on which matrices) are supplied. Without this, the justification for using the standard greedy algorithm lacks rigor.
Authors: We will augment the experimental section with the requested quantitative support. The revision will specify the exact procedure used to assess empirical monotonicity (number of subsets sampled, the three covariance matrices tested, and the observed marginal-gain statistics), include error bars or confidence intervals where appropriate, and present the results in a table or figure. This will make the justification for greedy optimization fully reproducible and rigorous. revision: yes
Circularity Check
MI selection 'outperforms' entropy for imputation by directly optimizing the conditional entropy that defines the imputation metric under the fitted MVN
specific steps
-
fitted input called prediction
[Abstract (experiments paragraph) and model definition sections]
"Experiments on three matrices from ten public leaderboards show that mutual information selection outperforms entropy for imputation at small subsets."
Covariance is estimated from the same leaderboard matrices used both to compute the MI/entropy objectives and to evaluate imputation error. Imputation error is the conditional entropy H(remaining | selected) under the fitted MVN; MI selection greedily maximizes I(selected; remaining) which is exactly H(remaining) - H(remaining|selected). Therefore the 'outperformance' for the imputation metric is the expected result of optimizing that metric, not an independent empirical finding.
full rationale
The paper fits a multivariate Gaussian covariance to the leaderboard score matrices, defines both selection objectives and the imputation error via that same model (entropy = log-det, MI = reduction in conditional entropy), then reports that greedy MI selection yields better imputation than entropy selection on the identical fitted matrices. Because the evaluation metric is exactly the quantity being maximized by the MI procedure (I(S; rest) = H(rest) - H(rest|S)), the reported superiority is a direct consequence of optimizing the evaluation criterion rather than an independent test on held-out data or non-Gaussian predictors. No external validation set or parameter-free derivation is described.
Axiom & Free-Parameter Ledger
free parameters (1)
- covariance matrix
axioms (1)
- domain assumption Benchmark scores across models follow a multivariate Gaussian distribution
Lean theorems connected to this paper
-
IndisputableMonolith.Cost.FunctionalEquationwashburn_uniqueness_aczel (canonical RS cost J(x)=½(x+x⁻¹)−1 is unrelated to log-det Gaussian entropy used here) unclearWe model scores as draws from a multivariate Gaussian and select a subset A of benchmarks to maximize either the entropy H(X_A) or the mutual information I(X_A;X_¯A). Both objectives are submodular.
-
IndisputableMonolith.Foundation.Atomicityatomic_tick / sequential_preserves_conservation (RS's combinatorial scheduling/ordering machinery is structurally different from greedy submodular maximization) unclearEntropy greedy is pivoted Cholesky, runs in O(k²N) time... MI is non-monotone in general but empirically monotone for small k, so we use greedy as a heuristic rather than invoking the standard monotone-submodular guarantee.
-
IndisputableMonolith.CostJcost / Jcost_unit0 (RS cost is scale-fixed with unique zero at x=1; paper's entropy is modular-shift-invariant — no overlap with J's rigidity) unclearf1(S) = H(X_S) = ½ log det(2πe Σ_SS) ... maximizing log det(Σ_AA), since additive constants do not affect the argmax.
Forward citations
Cited by 1 Pith paper
-
ProactBench: Beyond What The User Asked For
ProactBench measures LLM conversational proactivity in three phases using 198 multi-agent dialogues and finds recovery behavior hard to predict from existing benchmarks.
Reference graph
Works this paper leans on
-
[1]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models.arXiv preprint arXiv:2108.07732,
-
[2]
GitHub repository; includes the BenchPress method. Stella Biderman, Hailey Schoelkopf, Lintang Sutawika, Leo Gao, Jonathan Tow, Baber Abbasi, Alham Fikri Aji, Pawan Sasanka Ammanamanchi, Sidney Black, Jordan Clive, Anthony DiPofi, Julen Etxaniz, Benjamin Fattori, Jessica Zosa Forde, Charles Foster, Jeffrey Hsu, Mimansa Jaiswal, Wilson Y Lee, Haonan Li, Ch...
-
[3]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harrison Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavar...
work page internal anchor Pith review arXiv
-
[4]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457,
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
-
[6]
TabIm- pute: Universal zero-shot imputation for tabular data.arXiv preprint arXiv:2510.02625,
Jacob Feitelberg, Dwaipayan Saha, Kyuseong Choi, Zaid Ahmad, Anish Agarwal, and Raaz Dwivedi. TabIm- pute: Universal zero-shot imputation for tabular data.arXiv preprint arXiv:2510.02625,
-
[7]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Stein- hardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations, 2021a. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematic...
work page internal anchor Pith review arXiv
-
[8]
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E Gonzalez, and Ion Stoica. From crowdsourced data to high-quality benchmarks: Arena-Hard and BenchBuilder pipeline. arXiv preprint arXiv:2406.11939,
-
[9]
Bill Yuchen Lin, Yuntian Deng, Khyathi Chandu, Faeze Brahman, Abhilasha Ravichander, Valentina Pyatkin, Nouha Dziri, Ronan Le Bras, and Yejin Choi. WildBench: Benchmarking LLMs with challenging tasks from real users in the wild.arXiv preprint arXiv:2406.04770,
-
[10]
MTEB: Massive text embedding benchmark
11 Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers. MTEB: Massive text embedding benchmark. InProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 2014–2037,
2014
-
[11]
Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jessica Thompson, Phu Mon Htut, and Samuel R Bowman
Hugging Face collection. Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jessica Thompson, Phu Mon Htut, and Samuel R Bowman. BBQ: A hand-built bias benchmark for question answering. InFindings of the Association for Computational Linguistics: ACL 2022,
2022
-
[12]
Do these LLM benchmarks agree? fixing benchmark evaluation with BenchBench
Yotam Perlitz, Ariel Gera, Ofir Arviv, Asaf Yehudai, Elron Bandel, Eyal Shnarch, Michal Shmueli-Scheuer, and Leshem Choshen. Do these LLM benchmarks agree? fixing benchmark evaluation with BenchBench. arXiv preprint arXiv:2407.13696,
-
[13]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911,
work page internal anchor Pith review arXiv
-
[14]
[2023], BIG-BENCHHARD, MATH LEVEL5, GPQA Rein et al
replaced them with 6 harder alternatives: IFEVALZhou et al. [2023], BIG-BENCHHARD, MATH LEVEL5, GPQA Rein et al. [2024], MUSR Sprague et al. [2024], and MMLU-PROWang et al. [2024]. EleutherAI’s Language Model Evaluation Harness Biderman et al
2023
-
[15]
propose a modified greedy algorithm that runs two strategies in parallel. The first is acost-effective greedy: at each step, select the affordable element with the largest ratio of marginal gain to cost, ∆(v|S)/c(v) , and continue until the budget is exhausted. The second is abest-singleton strategy: simply pick the single element with the highest f-value...
2005
-
[16]
B.3 Budget Constraint for Entropy When benchmarks have non-uniform costs cj >0 , the cardinality constraint is replaced by P j∈A cj ≤ C
suffices. B.3 Budget Constraint for Entropy When benchmarks have non-uniform costs cj >0 , the cardinality constraint is replaced by P j∈A cj ≤ C . Following Krause and Guestrin [2005], two strategies are run in parallel: a cost-effective greedy that selects the affordable element with the largest gain-to-cost ratio ∆c(j| A)/c j until the budget is exhaus...
2005
-
[17]
Since the greedy algorithmgrows S one element at a time, we can maintain a Cholesky factorization ofΣ SS via rank-one updates at costO(k 2n)overall
Both conditional variances have closed forms via the Schur complement: σ2 v|S = Σvv −Σ vS Σ−1 SS ΣSv ,(11) σ2 v| ¯Sv = Σvv −Σ v ¯Sv Σ−1 ¯Sv ¯Sv Σ ¯Svv.(12) For the entropy objective f1, only (11) is needed. Since the greedy algorithmgrows S one element at a time, we can maintain a Cholesky factorization ofΣ SS via rank-one updates at costO(k 2n)overall. F...
2013
-
[18]
Lazy evaluation applies to the selection criterion but not to the refactorization, which must be performed eagerly
rank-one downdate (13), but for N in the hundreds and k≤15 the wall-clock overhead is negligible (under one second on all our datasets). Lazy evaluation applies to the selection criterion but not to the refactorization, which must be performed eagerly. D Dataset Details We assemble score matrices from ten public leaderboards spanning general language unde...
2024
-
[19]
E Model Canonicalization To merge score matrices from different benchmark collections into a unified table, we must identify when the same model appears under different names
Auxiliary count, uncertainty, and length columns are excluded so that all columns represent benchmark scores or win rates. E Model Canonicalization To merge score matrices from different benchmark collections into a unified table, we must identify when the same model appears under different names. Table 2 lists the 118 models that we identified across at ...
2024
-
[20]
MassiveIntentClassification is the most stable top pick (10/10, mean rank 2.9), followed by STS15 and STS17
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Selection position k MassiveIntentClassification STS15 STS17 AmazonPolarityClassification BiorxivClusteringS2S MedrxivClusteringP2P NQ SciFact SciDocsRR ArxivClusteringS2S RedditClustering AskUbuntuDupQuestions ArxivClusteringP2P StackExchangeClustering STS13 STS14 DBPedia SprintDuplicateQuestions T oxicConversationsCla...
2014
-
[21]
= 3,363). Implications.The formal rejection of Gaussianity is unsurprising: with M= 5,452 observations, even minor departures from normality are statistically detectable, and benchmark scores are bounded, discrete, and occasionally multimodal. The important question is whether these departures undermine thepracticalutility of the Gaussian imputation. The ...
2026
-
[22]
Entropy and random selection are com- parable; MI remains unstable
Random (d) BENCHPRESS. Entropy and random selection are com- parable; MI remains unstable. Figure 15: TABIMPUTEV2 imputation R2 on all four datasets (10-fold CV , 10% holdout). Compare with Figures 5–7 (Gaussian imputation), whereR 2 is substantially higher across the board. Discussion.The Gaussian model’s advantage is not surprising: it estimates the cov...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.