Recognition: 2 theorem links
A Protocol-Independent Transport Architecture
Pith reviewed 2026-05-08 18:41 UTC · model grok-4.3
The pith
PITA gives NIC hardware a uniform data-path abstraction so multiple transport protocols run at line rate without protocol-specific hardware logic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
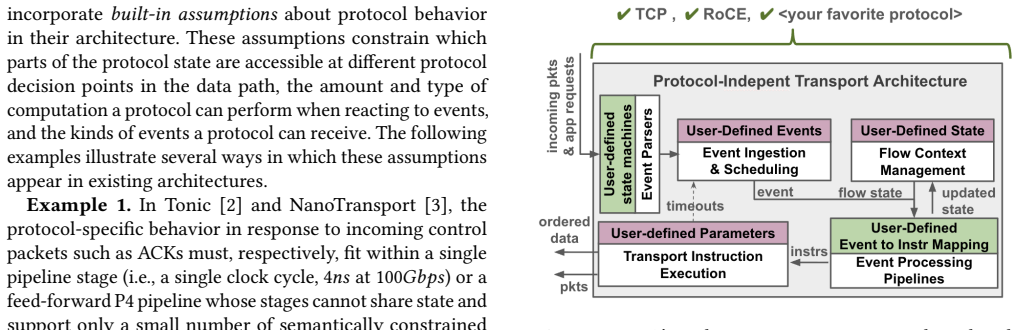
PITA structures the data-path around a uniform abstraction over events, state, and instructions, and rethinks scheduling, packet generation, and data reassembly to operate on this abstraction. This design removes protocol-specific assumptions, allowing the same hardware substrate to implement diverse semantics such as TCP and RoCE while preserving their distinct end-to-end behaviors and sustaining line-rate performance with modest hardware overhead.
What carries the argument
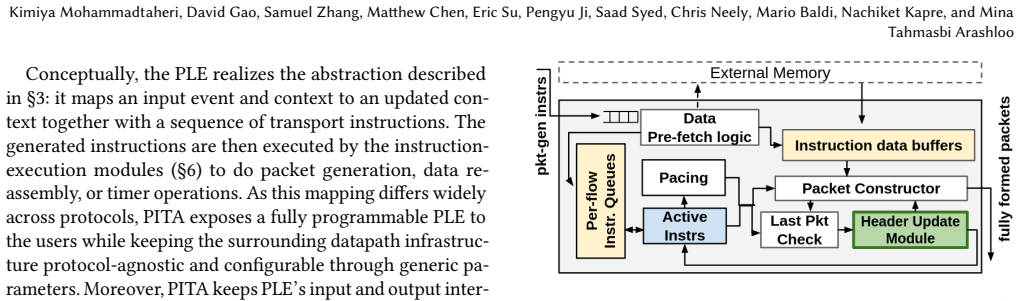
The uniform abstraction over events, state, and instructions, which serves as the single substrate for rethought scheduling, packet generation, and data reassembly components so that protocol logic can be programmed without embedding protocol assumptions in hardware.
If this is right
- Transport protocols can be updated or replaced in the data path by reprogramming rather than replacing NIC hardware.
- The same physical NIC can host multiple protocols simultaneously while each retains its original congestion control and reliability semantics.
- Hardware designers no longer need to embed protocol logic at design time, reducing the risk of locking in obsolete transport behavior.
- Synthesis results show the architecture meets timing at 250 MHz on Alveo U250 cards with only modest resource overhead.
Where Pith is reading between the lines
- Operators could deploy experimental protocols in production data centers without buying new NICs or accepting lower speed.
- The approach might simplify multi-protocol environments where different applications need different transports on the same server fleet.
- Future extensions could add support for in-network computing primitives while still keeping the protocol-independent property.
Load-bearing premise
A single uniform abstraction over events, state, and instructions plus the redesigned components can faithfully support the different requirements of protocols like TCP and RoCE without adding performance overhead or hidden protocol assumptions.
What would settle it
A concrete test would be to implement a third transport protocol on the PITA data path, run it at line rate on Alveo U250 hardware at 250 MHz, and check whether its end-to-end semantics remain intact and throughput does not drop compared with a protocol-specific implementation.
Figures




read the original abstract
The network transport layer is increasingly implemented in the NIC hardware to meet the performance demands of modern workloads, but this has made it difficult to evolve or deploy new transport protocols. Existing approaches either fix protocol logic in the data-path or build protocol-specific assumptions into the architecture that limit the range of protocols that can be supported on a single hardware substrate. We present PITA, a protocol-independent transport architecture that enables full data-path programmability while sustaining line-rate performance. PITA eliminates protocol-specific assumptions by structuring the data-path around a uniform abstraction over events, state, and instructions, and rethinks core components, including scheduling, packet generation, and data reassembly, to operate on this abstraction. We evaluate PITA along key dimensions reflecting the goals of its protocol-agnostic datapath design. Specifically, we show that PITA supports diverse protocol semantics by showing it can implement TCP and \roce on the same data path and preserve their distinct end-to-end behavior. Through targeted microbenchmarks and synthesis on Alveo U250 cards, we show that PITA's redesigned components sustain high performance under demanding conditions, with modest hardware overhead and meeting timing at 250MHz.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PITA, a protocol-independent transport architecture for NIC hardware that structures the data path around a uniform abstraction over events, state, and instructions. It rethinks scheduling, packet generation, and data reassembly to support diverse protocol semantics (explicitly TCP byte-stream reliability with congestion control and RoCE RDMA) on the same programmable substrate without protocol-specific assumptions, while sustaining line-rate performance. Evaluation consists of targeted microbenchmarks plus FPGA synthesis on Alveo U250 cards showing modest overhead and timing closure at 250 MHz, with the central demonstration that TCP and RoCE can be implemented on the shared path while preserving their distinct end-to-end behaviors.
Significance. If the core claims are substantiated, PITA would represent a meaningful advance in programmable networking hardware by decoupling transport protocol logic from fixed data-path assumptions, potentially enabling easier evolution and deployment of new protocols at line rate. The synthesis results and microbenchmark data provide concrete evidence of hardware feasibility, which is a strength for a systems paper in this area.
major comments (2)
- [Evaluation] Evaluation section (and abstract): The claim that TCP and RoCE can be implemented on the same data path while preserving their distinct end-to-end behaviors is load-bearing for the protocol-independence thesis, yet it is supported only by targeted microbenchmarks and synthesis results rather than full end-to-end protocol executions, throughput/latency traces against reference stacks, or workload-level verification that state machines and semantics remain unchanged under realistic traffic. This leaves open whether the uniform abstraction truly avoids introducing hidden protocol-specific assumptions or performance artifacts when both protocols run concurrently.
- [Architecture] Architecture description (uniform abstraction and rethought components): The paper asserts that the uniform abstraction over events/state/instructions plus redesigned scheduling, packet generation, and reassembly components support full TCP and RoCE semantics without protocol-specific assumptions, but the manuscript does not provide concrete mappings or invariants showing how TCP's byte-stream ordering and congestion control are realized alongside RoCE's RDMA operations on the shared path; without such detail the no-assumption claim cannot be fully assessed.
minor comments (1)
- [Abstract] Abstract: The LaTeX fragment “and preserve their distinct end-to-end behavior” contains a minor grammatical inconsistency with the plural subject; consider rephrasing for clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for highlighting areas where the manuscript can be strengthened. We address each major comment below with clarifications on the existing evaluation and architecture, and we indicate revisions that will be incorporated.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (and abstract): The claim that TCP and RoCE can be implemented on the same data path while preserving their distinct end-to-end behaviors is load-bearing for the protocol-independence thesis, yet it is supported only by targeted microbenchmarks and synthesis results rather than full end-to-end protocol executions, throughput/latency traces against reference stacks, or workload-level verification that state machines and semantics remain unchanged under realistic traffic. This leaves open whether the uniform abstraction truly avoids introducing hidden protocol-specific assumptions or performance artifacts when both protocols run concurrently.
Authors: We agree that comprehensive end-to-end traces and workload-level verification against reference stacks would provide stronger substantiation. The current microbenchmarks isolate and verify preservation of TCP byte-stream reliability, ordering, and congestion control alongside RoCE RDMA semantics under concurrent operation on the shared path, confirming no interference in state machines. These tests exercise the uniform abstraction directly. We will revise the evaluation section to include expanded benchmark descriptions, additional concurrent execution results, and explicit discussion of how the results confirm unchanged end-to-end behaviors. revision: partial
-
Referee: [Architecture] Architecture description (uniform abstraction and rethought components): The paper asserts that the uniform abstraction over events/state/instructions plus redesigned scheduling, packet generation, and reassembly components support full TCP and RoCE semantics without protocol-specific assumptions, but the manuscript does not provide concrete mappings or invariants showing how TCP's byte-stream ordering and congestion control are realized alongside RoCE's RDMA operations on the shared path; without such detail the no-assumption claim cannot be fully assessed.
Authors: The architecture section explains the uniform abstraction and how scheduling, packet generation, and reassembly operate on events/state/instructions to support both protocols. To improve clarity, we will add concrete mappings (e.g., TCP byte-stream ordering via sequenced events and separate congestion state; RoCE RDMA via direct memory operations) and explicit invariants ensuring the shared path introduces no protocol-specific assumptions. These additions will be placed in the architecture description. revision: yes
Circularity Check
No circularity: empirical architecture presentation with independent evaluation
full rationale
The paper introduces PITA as a hardware datapath design and evaluates it via direct implementation of TCP and RoCE on the shared abstraction, plus microbenchmarks and Alveo U250 synthesis reporting timing, overhead, and performance numbers. No equations, fitted parameters, or predictions appear in the provided text. Claims of protocol support and line-rate behavior rest on concrete implementation and external hardware measurements rather than any reduction to self-defined inputs, self-citations, or renamed known results. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hardware synthesis on Alveo U250 cards can meet timing at 250 MHz with the redesigned components
invented entities (2)
-
Uniform abstraction over events, state, and instructions
no independent evidence
-
PITA architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mohammad Alizadeh, Albert Greenberg, David A Maltz, Jitendra Pad- hye, Parveen Patel, Balaji Prabhakar, Sudipta Sengupta, and Murari Sridharan. 2010. Data center tcp (dctcp). InProceedings of the ACM SIGCOMM 2010 Conference. 63–74
2010
-
[2]
Mina Tahmasbi Arashloo, Alexey Lavrov, Manya Ghobadi, Jennifer Rexford, David Walker, and David Wentzlaff. 2020. Enabling Pro- grammable Transport Protocols in High-Speed NICs. In17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20). USENIX Association, Santa Clara, CA, 93–109.https://www. usenix.org/conference/nsdi20/presentation...
2020
-
[3]
Serhat Arslan, Stephen Ibanez, Alex Mallery, Changhoon Kim, and Nick McKeown. 2021. NanoTransport: A Low-Latency, Programmable Transport Layer for NICs. InProceedings of the ACM SIGCOMM Sym- posium on SDN Research (SOSR) (SOSR ’21). Association for Comput- ing Machinery, New York, NY, USA, 13–26.https://doi.org/10.1145/ 3482898.3483365
-
[4]
Junehyuk Boo, Yujin Chung, Eunjin Baek, Seongmin Na, Changsu Kim, and Jangwoo Kim. 2023. F4T: A Fast and Flexible FPGA-based Full-stack TCP Acceleration Framework. InProceedings of the 50th Annual International Symposium on Computer Architecture (ISCA ’23). Association for Computing Machinery, New York, NY, USA, Article 55, 13 pages.https://doi.org/10.114...
-
[5]
Pat Bosshart, Glen Gibb, Hun-Seok Kim, George Varghese, Nick McK- eown, Martin Izzard, Fernando Mujica, and Mark Horowitz. 2013. Forwarding metamorphosis: fast programmable match-action process- ing in hardware for SDN. InProceedings of the ACM SIGCOMM 2013 Conference on SIGCOMM (SIGCOMM ’13). Association for Comput- ing Machinery, New York, NY, USA, 99–1...
-
[6]
Qizhe Cai, Mina Tahmasbi Arashloo, and Rachit Agarwal. 2022. dcPIM: Near-optimal proactive datacenter transport. InProceedings of the ACM SIGCOMM 2022 Conference. 53–65
2022
-
[7]
Vitis Developers. [n. d.]. AMD Vitis HLS. https://www.amd.com/en/products/software/adaptive-socs-and- fpgas/vitis/vitis-hls.html. ([n. d.]). Accessed: January 2025
2025
-
[8]
Vivado Developers. [n. d.]. AMD Vivado™Design Suite. https://www.amd.com/en/products/software/adaptive-socs-and- fpgas/vivado.html. ([n. d.]). Accessed: January 2025
2025
-
[9]
Maltz, and Albert Greenberg
Daniel Firestone, Andrew Putnam, Sambhrama Mundkur, Derek Chiou, Alireza Dabagh, Mike Andrewartha, Hari Angepat, Vivek Bhanu, Adrian Caulfield, Eric Chung, Harish Kumar Chandrappa, Somesh Chaturmohta, Matt Humphrey, Jack Lavier, Norman Lam, Fengfen Liu, Kalin Ovtcharov, Jitu Padhye, Gautham Popuri, Shachar Raindel, Tejas Sapre, Mark Shaw, Gabriel Silva, M...
-
[10]
In15th USENIX Symposium on Networked Systems Design and Im- plementation (NSDI 18)
Azure Accelerated Networking: SmartNICs in the Public Cloud. In15th USENIX Symposium on Networked Systems Design and Im- plementation (NSDI 18). USENIX Association, Renton, WA, 51–66. https://www.usenix.org/conference/nsdi18/presentation/firestone
-
[11]
Peter X Gao, Akshay Narayan, Gautam Kumar, Rachit Agarwal, Sylvia Ratnasamy, and Scott Shenker. 2015. pHost: Distributed near-optimal datacenter transport over commodity network fabric. InProceedings of the 11th ACM Conference on Emerging Networking Experiments and Technologies. 1–12
2015
-
[12]
Chuanxiong Guo, Haitao Wu, Zhong Deng, Gaurav Soni, Jianxi Ye, Jitu Padhye, and Marina Lipshteyn. 2016. RDMA over commodity ethernet at scale. InProceedings of the 2016 ACM SIGCOMM Conference. 202–215
2016
-
[13]
Sangtae Ha, Injong Rhee, and Lisong Xu. 2008. CUBIC: a new TCP- friendly high-speed TCP variant.ACM SIGOPS operating systems review42, 5 (2008), 64–74
2008
-
[14]
Mark Handley, Costin Raiciu, Alexandru Agache, Andrei Voinescu, Andrew W Moore, Gianni Antichi, and Marcin Wójcik. 2017. Re- architecting datacenter networks and stacks for low latency and high performance. InProceedings of the Conference of the ACM Special Interest Group on Data Communication. 29–42
2017
-
[15]
Zhenhao He, Dario Korolija, and Gustavo Alonso. 2021. EasyNet: 100 Gbps Network for HLS. In2021 31st International Conference on Field-Programmable Logic and Applications (FPL). 197–203.https://doi. org/10.1109/FPL53798.2021.00040
-
[16]
2025.UEC 1.0: New High-Performance Stan- dard for Scaling HPC-AI
Intersect360 Research. 2025.UEC 1.0: New High-Performance Stan- dard for Scaling HPC-AI. White Paper. Ultra Ethernet Consor- tium.https://ultraethernet.org/wp-content/uploads/sites/20/2025/ 06/UEC1.0Whitepaper.pdf
2025
-
[17]
Cheng Jin, David X Wei, and Steven H Low. 2004. FAST TCP: motiva- tion, architecture, algorithms, performance. InIEEE INFOCOM 2004, Vol. 4. IEEE, 2490–2501
2004
- [18]
-
[19]
Radhika Mittal, Alexander Shpiner, Aurojit Panda, Eitan Zahavi, Arvind Krishnamurthy, Sylvia Ratnasamy, and Scott Shenker. 2018. Revisiting network support for RDMA. InProceedings of the 2018 Con- ference of the ACM Special Interest Group on Data Communication (SIGCOMM ’18). Association for Computing Machinery, New York, NY, USA, 313–326.https://doi.org/1...
-
[20]
Pedro Mizuno, Kimiya Mohammadtaheri, Linfan Qian, Joshua Johnson, Danny Akbarzadeh, Chris Neely, Mario Baldi, Nachiket Kapre, and Mina Tahmasbi Arashloo. 2026. A Target-Agnostic Protocol-Independent Interface for the Transport Layer. (2026). arXiv:cs.NI/2509.21550https://arxiv.org/abs/2509.21550
-
[21]
Behnam Montazeri, Yilong Li, Mohammad Alizadeh, and John Ouster- hout. 2018. Homa: A receiver-driven low-latency transport protocol using network priorities. InProceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication. 221–235
2018
-
[22]
YoungGyoun Moon, SeungEon Lee, Muhammad Asim Jamshed, and KyoungSoo Park. 2020. AccelTCP: Accelerating Network Applications 12 with Stateful TCP Offloading. In17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20). USENIX Association, Santa Clara, CA, 77–92.https://www.usenix.org/conference/nsdi20/ presentation/moon
2020
-
[23]
Akshay Narayan, Frank Cangialosi, Deepti Raghavan, Prateesh Goyal, Srinivas Narayana, Radhika Mittal, Mohammad Alizadeh, and Hari Balakrishnan. 2018. Restructuring endpoint congestion control. In Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication (SIGCOMM ’18). Association for Computing Ma- chinery, New York, NY, US...
-
[24]
Mario Ruiz, David Sidler, Gustavo Sutter, Gustavo Alonso, and Ser- gio López-Buedo. 2019. Limago: An FPGA-Based Open-Source 100 GbE TCP/IP Stack. In2019 29th International Conference on Field Pro- grammable Logic and Applications (FPL). 286–292.https://doi.org/10. 1109/FPL.2019.00053
-
[25]
Leah Shalev, Hani Ayoub, Nafea Bshara, and Erez Sabbag. 2020. A cloud-optimized transport protocol for elastic and scalable hpc.IEEE micro40, 6 (2020), 67–73
2020
-
[26]
Rajath Shashidhara, Tim Stamler, Antoine Kaufmann, and Simon Peter
-
[27]
In19th USENIX Symposium on Networked Systems Design and Imple- mentation (NSDI 22)
FlexTOE: Flexible TCP Offload with Fine-Grained Parallelism. In19th USENIX Symposium on Networked Systems Design and Imple- mentation (NSDI 22). USENIX Association, Renton, WA, 87–102.https: //www.usenix.org/conference/nsdi22/presentation/shashidhara
-
[28]
Arjun Singhvi, Nandita Dukkipati, Prashant Chandra, Hassan MG Wassel, Naveen Kr Sharma, Anthony Rebello, Henry Schuh, Praveen Kumar, Behnam Montazeri, Neelesh Bansod, et al . 2025. Falcon: A reliable, low latency hardware transport. InProceedings of the ACM SIGCOMM 2025 Conference. 248–263
2025
-
[29]
Kun Tan, Jingmin Song, Qian Zhang, and Murad Sridharan. 2006. A compound TCP approach for high-speed and long distance networks. InProceedings-IEEE INFOCOM
2006
-
[30]
Balajee Vamanan, Jahangir Hasan, and TN Vijaykumar. 2012. Deadline- aware datacenter tcp (d2tcp).ACM SIGCOMM Computer Communica- tion Review42, 4 (2012), 115–126. A PITA Parameters Table 3 shows the relevant PITA parameters. Module Parameter Value Global flow count ED event width 64 b (TCP) event type count 4 (TCP) context width 938 b (TCP) serialized dat...
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.