Recognition: no theorem link
Cerberus: Cross-Layer ECC Co-Design for Robust and Efficient Memory Protection
Pith reviewed 2026-05-15 06:41 UTC · model grok-4.3
The pith
Cerberus unifies three-layer ECC protection with one encoding reused across device, link, and system.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
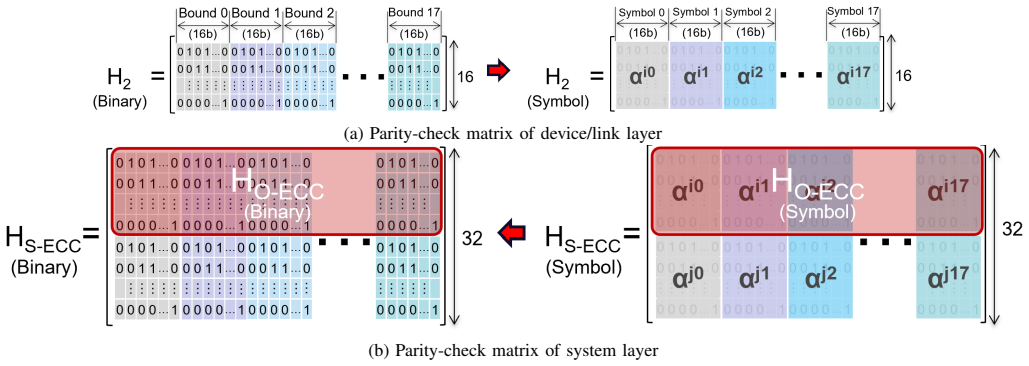
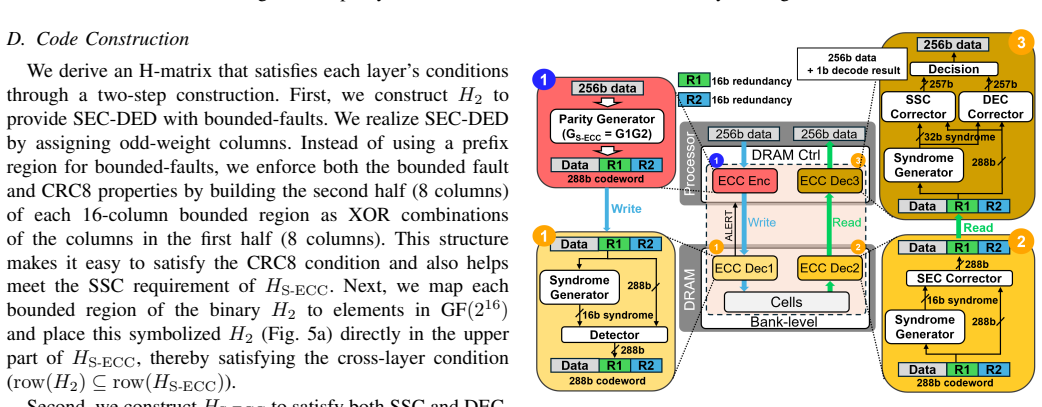
At its core, Cerberus uses an Encode-Once, Decode-Many architecture in which the memory controller performs a single encoding. This redundancy is then reused by link ECC for immediate write-path detection and retry, by on-die ECC for in-device repair on reads, and by system ECC for strong end-to-end recovery. The design jointly creates complementary parity and syndrome structures, orders the decoders, and allocates the correction budget to avoid miscorrection amplification.
What carries the argument
Encode-Once, Decode-Many (EODM) architecture that reuses a single encoding's redundancy across layers through complementary parity and syndrome designs.
Load-bearing premise
A single encoding can be structured to support all three ECC layers simultaneously without introducing new coverage gaps or interference between layers.
What would settle it
Experiments injecting clustered faults into hardware prototypes and measuring whether uncorrectable error rates or miscorrection incidents rise or fall relative to separate ECC implementations.
Figures


read the original abstract
As DRAM scales to higher density and I/O speeds, ensuring data correctness becomes increasingly difficult. Industry has responded with a three-layer stack: on-die ECC (O-ECC), link ECC (L-ECC), and system ECC (S-ECC). However, these layers have evolved independently, often duplicating redundancy, leaving coverage gaps, and occasionally interfering. We propose Cerberus, a cross-layer ECC co-design that unifies protection across device, link, and system while preserving the native role of each layer. At its core is an Encode-Once, Decode-Many (EODM) architecture: the controller performs a single encoding whose redundancy is reused by L-ECC for immediate write-path detection and retry, by O-ECC for in-device repair on reads, and by S-ECC for strong end-to-end recovery. Cerberus jointly designs complementary parity and syndrome structures, orders decoders, and allocates the correction budget to prevent miscorrection amplification and enable selective correction under tight redundancy constraints. Our evaluations show improved resilience to clustered and peripheral faults while reducing redundant overhead, underscoring the importance of coordinated cross-layer protection for next-generation memory systems, such as custom HBMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Cerberus, a cross-layer ECC co-design for DRAM memory protection. It introduces an Encode-Once, Decode-Many (EODM) architecture in which the memory controller performs a single encoding whose redundancy is reused by on-die ECC (O-ECC) for in-device repair, link ECC (L-ECC) for write-path detection and retry, and system ECC (S-ECC) for end-to-end recovery. The design jointly structures complementary parity and syndrome fields, orders the decoders, and allocates a correction budget to avoid miscorrection amplification while claiming improved resilience to clustered and peripheral faults together with lower redundant overhead.
Significance. If the joint parity/syndrome design and decoder ordering prove effective under realistic device and link fault distributions, the work would offer a meaningful advance over the current independent evolution of the three ECC layers. By reducing duplication of redundancy while preserving each layer’s native role, Cerberus could lower overall storage and latency costs in high-density, high-speed memories such as custom HBMs. The emphasis on coordinated protection across device, link, and system levels addresses a practical systems problem that has received limited attention in the literature.
major comments (2)
- [§3] §3 (EODM Architecture): The central claim that a single encoding can be structured to serve O-ECC, L-ECC, and S-ECC without creating new coverage gaps or miscorrection amplification rests on the joint design of complementary parity and syndrome structures together with ordered decoders and budgeted correction. The manuscript must supply the explicit construction (parity-check matrix definitions, syndrome mapping rules, and correction-budget allocation algorithm) and demonstrate that a miscorrection at the O-ECC layer cannot propagate corrupted data that defeats the subsequent S-ECC decoder under clustered fault patterns.
- [§5] §5 (Evaluations): The reported resilience gains and overhead reductions are stated only qualitatively in the abstract. Quantitative results—fault-coverage curves, miscorrection rates, and redundancy overhead percentages—must be shown for both synthetic clustered/peripheral fault models and, if available, real device traces, with direct comparison against the baseline of independently designed O-ECC + L-ECC + S-ECC stacks. Without these numbers the magnitude of improvement cannot be assessed.
minor comments (2)
- The abstract introduces several acronyms (O-ECC, L-ECC, S-ECC, EODM) in rapid succession; a short table or parenthetical expansion on first use in the main text would improve readability.
- Figure captions should explicitly state the fault model (e.g., burst length, spatial correlation) used to generate each plotted curve.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and will revise the manuscript to strengthen the presentation of the EODM construction and quantitative evaluations.
read point-by-point responses
-
Referee: [§3] §3 (EODM Architecture): The central claim that a single encoding can be structured to serve O-ECC, L-ECC, and S-ECC without creating new coverage gaps or miscorrection amplification rests on the joint design of complementary parity and syndrome structures together with ordered decoders and budgeted correction. The manuscript must supply the explicit construction (parity-check matrix definitions, syndrome mapping rules, and correction-budget allocation algorithm) and demonstrate that a miscorrection at the O-ECC layer cannot propagate corrupted data that defeats the subsequent S-ECC decoder under clustered fault patterns.
Authors: We agree that the explicit construction details are required for full verification. In the revised manuscript we will add the complete parity-check matrix definitions for the joint EODM encoding, the precise syndrome mapping rules that enable reuse across the three layers, and the pseudocode for the correction-budget allocation algorithm. We will also include a dedicated subsection with both analytical bounds and simulation results showing that decoder ordering combined with the budgeted correction ensures any O-ECC miscorrection produces a residual error pattern that remains within the correction capability of the subsequent S-ECC decoder, even for the clustered fault patterns considered in the paper. revision: yes
-
Referee: [§5] §5 (Evaluations): The reported resilience gains and overhead reductions are stated only qualitatively in the abstract. Quantitative results—fault-coverage curves, miscorrection rates, and redundancy overhead percentages—must be shown for both synthetic clustered/peripheral fault models and, if available, real device traces, with direct comparison against the baseline of independently designed O-ECC + L-ECC + S-ECC stacks. Without these numbers the magnitude of improvement cannot be assessed.
Authors: Section 5 already reports quantitative results under synthetic clustered and peripheral fault models, including coverage and overhead metrics with comparisons to independent layer baselines. To address the request for clearer presentation we will expand the section with additional fault-coverage curves, tabulated miscorrection rates, explicit redundancy overhead percentages, and side-by-side baseline plots. Public real device traces matching the required granularity are not available to us; we therefore rely on synthetic models calibrated to published DRAM fault characterizations and will add an explicit discussion of this modeling choice and its limitations in the revised text. revision: partial
Circularity Check
No circularity: architectural proposal is self-contained
full rationale
The manuscript presents Cerberus as a new Encode-Once Decode-Many (EODM) cross-layer ECC architecture that jointly structures parity/syndrome, orders decoders, and allocates correction budget. No equations, fitted parameters, or self-citation chains appear in the provided text that reduce any central claim to its own inputs by construction. The design choices and claimed resilience improvements rest on the proposed unification itself rather than renaming prior results or predicting quantities already used in fitting. This is the normal case for an engineering co-design paper whose argument is independent of external fitted quantities.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
1T-1C Dynamic Random Access Memory Status, Challenges, and Prospects,
A. Spessot and H. Oh, “1T-1C Dynamic Random Access Memory Status, Challenges, and Prospects,”IEEE Transactions on Electron Devices, vol. 67, no. 4, 2020
work page 2020
-
[2]
DRAM Scaling Error Evaluation Model Using Various Retention Time,
S.-L. Gong, J. Kim, and M. Erez, “DRAM Scaling Error Evaluation Model Using Various Retention Time,” inProceedings of the Annual IEEE/IFIP International Conference on Dependable Systems and Net- works Workshops (DSN-W), 2017
work page 2017
-
[3]
Mutlu,Main Memory Scaling: Challenges and Solution Directions
O. Mutlu,Main Memory Scaling: Challenges and Solution Directions. Springer New York, 2015
work page 2015
-
[4]
CROW: A Low-Cost Substrate for Improving DRAM Performance, Energy Efficiency, and Reliability,
H. Hassan, M. Patel, J. S. Kim, A. G. Yaglikci, N. Vijaykumar, N. M. Ghiasi, S. Ghose, and O. Mutlu, “CROW: A Low-Cost Substrate for Improving DRAM Performance, Energy Efficiency, and Reliability,” in Proceedings of the 46th international symposium on computer architec- ture, 2019
work page 2019
-
[5]
Ha,Understanding and Improving the Energy Efficiency of DRAM
H. Ha,Understanding and Improving the Energy Efficiency of DRAM. Stanford University, 2018
work page 2018
-
[6]
H. Park, S.-M. Yu, and J. Song, “An 11 Gb/s 0.376 pJ/Bit Capacitor- Less Dicode Transceiver With Pattern-Dependent Equalizations TIA Termination for Parallel DRAM Interfaces,”IEEE Access, 2024
work page 2024
-
[7]
Y . Jung, S. Lee, H. Kim, and S. Cho, “A Supply-Noise-Induced Jitter- Cancelling Clock Distribution Network for LPDDR5 Mobile DRAM featuring a 2nd-order Adaptive Filter,” inProceedings of the Interna- tional Solid State Circuits Conference (ISSCC), vol. 65, 2022
work page 2022
-
[8]
Fine-Grained DRAM: Energy-Efficient DRAM for Extreme Bandwidth Systems,
M. O’Connor, N. Chatterjee, D. Lee, J. Wilson, A. Agrawal, S. W. Keck- ler, and W. J. Dally, “Fine-Grained DRAM: Energy-Efficient DRAM for Extreme Bandwidth Systems,” inProceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture, 2017
work page 2017
-
[9]
Hauberk: Lightweight Silent Data Corruption Error Detector for GPGPU,
K. S. Yim, C. Pham, M. Saleheen, Z. Kalbarczyk, and R. Iyer, “Hauberk: Lightweight Silent Data Corruption Error Detector for GPGPU,” in Proceedings of the International Symposium on Parallel and Distributed Processing (IPDPS), 2011
work page 2011
-
[10]
Detection and Correction of Silent Data Corruption for Large-Scale High-Performance Computing,
D. Fiala, F. Mueller, C. Engelmann, R. Riesen, K. Ferreira, and R. Brightwell, “Detection and Correction of Silent Data Corruption for Large-Scale High-Performance Computing,” inProceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis (SC), 2012
work page 2012
-
[11]
Addressing multiple bit/symbol errors in DRAM subsystem,
R. Yeleswarapu and A. K. Somani, “Addressing multiple bit/symbol errors in DRAM subsystem,”PeerJ Computer Science, vol. 7, 2021
work page 2021
-
[12]
Im- plicit Memory Tagging: No-Overhead Memory Safety Using Alias- Free Tagged ECC,
M. B. Sullivan, M. T. I. Ziad, A. Jaleel, and S. W. Keckler, “Im- plicit Memory Tagging: No-Overhead Memory Safety Using Alias- Free Tagged ECC,” inProceedings of the International Symposium on Computer Architecture (ISCA), 2023
work page 2023
-
[13]
MAGE: Adaptive Granularity and ECC for Resilient and Power Efficient Memory Systems,
S. Li, D. H. Yoon, K. Chen, J. Zhao, J. H. Ahn, J. B. Brockman, Y . Xie, and N. P. Jouppi, “MAGE: Adaptive Granularity and ECC for Resilient and Power Efficient Memory Systems,” inProceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, 2012
work page 2012
-
[14]
Evaluating Built-In ECC of FPGA On-Chip Memories for the Mitigation of Undervolting Faults,
B. Salami, O. S. Unsal, and A. C. Kestelman, “Evaluating Built-In ECC of FPGA On-Chip Memories for the Mitigation of Undervolting Faults,” inProceedings of the 27th Euromicro International Conference on Parallel, Distributed and Network-Based Processing (PDP), 2019
work page 2019
-
[15]
A Systematic Study of DDR4 DRAM Faults in the Field,
M. V . Beigi, Y . Cao, S. Gurumurthi, C. Recchia, A. Walton, and V . Sridharan, “A Systematic Study of DDR4 DRAM Faults in the Field,” inProceedings of the International Symposium on High Performance Computer Architecture (HPCA), 2023
work page 2023
-
[16]
DRAM Fault Classification through Large-Scale Field Monitoring for Robust Memory RAS Management,
H. Chung, E. Oh, S. Baek, H. Yoon, J. Yoo, S. Lee, Y . Lee, A. Bramhanand, B. Dodds, Y . Zhou, and N. S. Kim, “DRAM Fault Classification through Large-Scale Field Monitoring for Robust Memory RAS Management,” inProceedings of the International Symposium on Microarchitecture (MICRO), 2025
work page 2025
-
[17]
Predicting Future-System Reliability with a Component-Level DRAM Fault Model,
J. Jung and M. Erez, “Predicting Future-System Reliability with a Component-Level DRAM Fault Model,” inProceedings of the 56th An- nual IEEE/ACM International Symposium on Microarchitecture, 2023
work page 2023
-
[18]
Characterization of Data Retention Faults in DRAM Devices,
A. Bacchini, M. Rovatti, G. Furano, and M. Ottavi, “Characterization of Data Retention Faults in DRAM Devices,” inProceedings of the International Symposium on Defect and Fault Tolerance in VLSI Systems (DFT), 2014
work page 2014
-
[19]
A Novel Prediction- Based Two-Tiered ECC for Mitigating SWD Errors in HBM,
Y . Moon, S. Shin, S. Jang, D. Won, and S. Kang, “A Novel Prediction- Based Two-Tiered ECC for Mitigating SWD Errors in HBM,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2024
work page 2024
-
[20]
M. Patel, J. S. Kim, H. Hassan, and O. Mutlu, “Understanding and Modeling On-Die Error Correction in Modern DRAM: An Experimental Study using Real Devices,” inProceedings of the International Confer- ence on Dependable Systems and Networks (DSN), 2019
work page 2019
-
[21]
M. Patel, J. S. Kim, T. Shahroodi, H. Hassan, and O. Mutlu, “Bit-Exact ECC Recovery (BEER): Determining DRAM On-Die ECC Functions by Exploiting DRAM Data Retention Characteristics,” inProceedings of the International Symposium on Microarchitecture (MICRO), 2020
work page 2020
-
[22]
Unity ECC: Unified Memory Protection Against Bit and Chip Errors,
D. Kim, J. Lee, W. Jung, M. B. Sullivan, and J. Kim, “Unity ECC: Unified Memory Protection Against Bit and Chip Errors,” inProceed- ings of the International Conference on High Performance Computing, Networking, Storage and Analysis (SC), 2023
work page 2023
-
[23]
Breaking the HBM Bit Cost Barrier: Domain-Specific ECC for AI Inference Infrastructure,
R. Xie, A. U. Haq, Y . Fang, L. Ma, S. Sen, S. Venkataramani, L. Liu, and T. Zhang, “Breaking the HBM Bit Cost Barrier: Domain-Specific ECC for AI Inference Infrastructure,”IEEE Computer Architecture Letters, 2025
work page 2025
-
[24]
JEDEC standard, “Double Data Rate (DDR) 5,” inJESD79-5C.01, 2024
work page 2024
- [25]
-
[26]
High Bandwidth Memory (HBM4) DRAM,
——, “High Bandwidth Memory (HBM4) DRAM,” inJESD270-4, 2025
work page 2025
-
[27]
Virtualized and Flexible ECC for Main Memory,
D. H. Yoon and M. Erez, “Virtualized and Flexible ECC for Main Memory,” inProceedings of the fifteenth International Conference on Architectural support for programming languages and operating systems, 2010
work page 2010
-
[28]
Improving Memory Reliability by Bounding DRAM Faults: DDR5 improved reliability features,
K. Criss, K. Bains, R. Agarwal, T. Bennett, T. Grunzke, J. K. Kim, H. Chung, and M. Jung, “Improving Memory Reliability by Bounding DRAM Faults: DDR5 improved reliability features,” inProceedings of the International Symposium on Memory Systems (MEMSYS), 2020
work page 2020
-
[29]
Exploiting Correcting Codes: On the Effectiveness of ECC Memory Against Rowhammer Attacks,
L. Cojocar, K. Razavi, C. Giuffrida, and H. Bos, “Exploiting Correcting Codes: On the Effectiveness of ECC Memory Against Rowhammer Attacks,” inProceedings of the IEEE Symposium on Security and Privacy (SP), 2019
work page 2019
-
[30]
Forward-Error Correction with Decision Feedback,
G. I. Davida and S. M. Reddy, “Forward-Error Correction with Decision Feedback,”Information and Control, vol. 21, no. 2, 1972
work page 1972
-
[31]
Error correction and detection for faults on time multi- plexed data lines,
T. J. Holman, “Error correction and detection for faults on time multi- plexed data lines,” Apr. 2001, U.S. Patent 6,219,817
work page 2001
-
[32]
Bamboo ECC: Strong, Safe, and Flexible Codes for Reliable Computer Memory,
J. Kim, M. Sullivan, and M. Erez, “Bamboo ECC: Strong, Safe, and Flexible Codes for Reliable Computer Memory,” inProceedings of the International Symposium on High Performance Computer Architecture (HPCA), 2015
work page 2015
-
[33]
Silent Data Errors: Sources, Detection, and Modeling,
A. Singh, S. Chakravarty, G. Papadimitriou, and D. Gizopoulos, “Silent Data Errors: Sources, Detection, and Modeling,” inProceedings of the VLSI Test Symposium (VTS), 2023
work page 2023
-
[34]
Detecting silent data corruptions in the wild,
H. D. Dixit, L. Boyle, G. Vunnam, S. Pendharkar, M. Beadon, and S. Sankar, “Detecting silent data corruptions in the wild,”arXiv preprint arXiv:2203.08989, 2022
-
[35]
Impact of V oltage Scaling on Soft Errors Susceptibility of Multicore Server CPUs,
D. Agiakatsikas, G. Papadimitriou, V . Karakostas, D. Gizopoulos, M. Psarakis, C. B ´elanger-Champagne, and E. Blackmore, “Impact of V oltage Scaling on Soft Errors Susceptibility of Multicore Server CPUs,” inProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture, 2023
work page 2023
-
[36]
Error Detecting and Error Correcting Codes,
R. W. Hamming, “Error Detecting and Error Correcting Codes,”Bell System Technical Journal, vol. 29, no. 2, 1950
work page 1950
-
[37]
A Class of Optimal Minimum Odd-weight-column SEC- DED Codes,
M. Y . Hsiao, “A Class of Optimal Minimum Odd-weight-column SEC- DED Codes,”IBM Journal of Research and Development, vol. 14, no. 4, 1970
work page 1970
-
[38]
On A Class of Error Correcting Binary Group Codes,
R. C. Bose and D. K. Ray-Chaudhuri, “On A Class of Error Correcting Binary Group Codes,”Information and Control, vol. 3, no. 1, 1960
work page 1960
-
[39]
Polynomial Codes over Certain Finite Fields,
I. S. Reed and G. Solomon, “Polynomial Codes over Certain Finite Fields,”Journal of the Society for Industrial and Applied Mathematics, vol. 8, no. 2, 1960
work page 1960
-
[40]
LOT-ECC: Localized and Tiered Reliability Mechanisms for Commodity Memory Systems,
A. N. Udipi, N. Muralimanohar, R. Balsubramonian, A. Davis, and N. P. Jouppi, “LOT-ECC: Localized and Tiered Reliability Mechanisms for Commodity Memory Systems,” inProceedings of the International Symposium on Computer Architecture (ISCA), 2012
work page 2012
-
[41]
PAIR: Pin-aligned In-DRAM ECC architecture using expandability of Reed-Solomon code,
S. Jeong, S. Kang, and J.-S. Yang, “PAIR: Pin-aligned In-DRAM ECC architecture using expandability of Reed-Solomon code,” inProceedings of the Design Automation Conference (DAC), 2020
work page 2020
-
[42]
Implementation of RS-CC Encoder and Decoder using MATLAB,
S. Sonawane and V . S. Baste, “Implementation of RS-CC Encoder and Decoder using MATLAB,”International Journal of Science Technology and Engineering, vol. 5, 2019
work page 2019
-
[43]
Error-correcting codes for semiconductor memories,
C. Chen, “Error-correcting codes for semiconductor memories,” in Proceedings of the 11th annual international symposium on Computer architecture, 1984
work page 1984
-
[44]
M. Hsiao, W. C. Carter, J. W. Thomas, and W. R. Stringfellow, “Reliability, Availability, and Serviceability of IBM Computer Systems: A Quarter Century of Progress,”IBM Journal of Research and Devel- opment, vol. 25, no. 5, 1981
work page 1981
-
[45]
Error Correction Code (ECC) in DDR Memories,
Synopsys, “Error Correction Code (ECC) in DDR Memories,” https: //www.synopsys.com/articles/ecc-memory-error-correction.html, 2020
work page 2020
-
[46]
Advanced Micro Devices, Inc.,BIOS and Kernel Developer’s Guide (BKDG) for AMD Family 15h Models 00h-0Fh Processors, 2013
work page 2013
-
[47]
From Correctable Memory Errors to Uncor- rectable Memory Errors: What Error Bits Tell,
C. Li, Y . Zhang, J. Wang, H. Chen, X. Liu, T. Huang, L. Peng, S. Zhou, L. Wang, and S. Ge, “From Correctable Memory Errors to Uncor- rectable Memory Errors: What Error Bits Tell,” inProceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis (SC), 2022
work page 2022
-
[48]
Fault- Aware Prediction-Guided Page Offlining for Uncorrectable Memory Error Prevention,
X. Du, C. Li, S. Zhou, X. Liu, X. Xu, T. Wang, and S. Ge, “Fault- Aware Prediction-Guided Page Offlining for Uncorrectable Memory Error Prevention,” inProceedings of the International Conference on Computer Design (ICCD), 2021
work page 2021
-
[49]
Co-Architecting Controllers and DRAM to Enhance DRAM Process Scaling,
U. Kang, H.-s. Yu, C. Park, H. Zheng, J. Halbert, K. Bains, S. Jang, and J. S. Choi, “Co-Architecting Controllers and DRAM to Enhance DRAM Process Scaling,” inThe Memory Forum, vol. 14, 2014
work page 2014
-
[50]
I. Alam and P. Gupta, “COMET: On-die and In-controller Collaborative Memory ECC Technique for Safer and Stronger Correction of DRAM Errors,” inProceedings of the International Conference on Dependable Systems and Networks (DSN), 2022
work page 2022
-
[51]
K. C. Chun, Y . K. Kim, Y . Ryu, J. Park, C. S. Oh, Y . Y . Byun, S. Y . Kim, D. H. Shin, J. G. Lee, B.-K. Ho, M.-S. Park, S.-J. Cho, S. Woo, B. M. Moon, B. Kil, S. Ahn, J. H. Lee, S. Y . Kim, S.-K. Choi, J.-S. Jeong, S.-G. Ahn, J. Kim, J. J. Kong, K. Sohn, N. S. Kim, and J.-B. Lee, “A 16-GB 640-GB/s HBM2E DRAM with a Data-Bus Window Extension Technique a...
work page 2020
-
[52]
Y . Ryu, S.-G. Ahn, J. H. Lee, J. Park, Y . K. Kim, H. Kim, Y . G. Song, H.-W. Cho, S. Cho, S. H. Song, H. Lee, U. Shin, J. Ahn, J.-M. Ryu, S. Lee, K.-H. Lim, J. Lee, J. H. Park, J.-S. Jeong, S. Joo, D. Cho, S. Y . Kim, M. Lee, H. Kim, M. Kim, J.-S. Kim, J. Kim, H. G. Kang, M.-K. Lee, S.-R. Kim, Y .-C. Kwon, Y . Y . Byun, K. Lee, S. Park, J. Youn, M.-O. K...
work page 2023
-
[53]
A 3.2 Gbps/pin 8 Gbit 1.0 V LPDDR4 SDRAM With Integrated ECC Engine for Sub-1 V DRAM Core Operation,
T.-Y . Oh, H. Chung, J.-Y . Park, K.-W. Lee, S. Oh, S.-Y . Doo, H.-J. Kim, C. Lee, H.-R. Kim, J.-H. Lee, J.-I. Lee, K.-S. Ha, Y . Choi, Y .- C. Cho, Y .-C. Bae, T. Jang, C. Park, K. Park, S. Jang, and J. S. Choi, “A 3.2 Gbps/pin 8 Gbit 1.0 V LPDDR4 SDRAM With Integrated ECC Engine for Sub-1 V DRAM Core Operation,”IEEE Journal of Solid- State Circuits, vol...
work page 2014
-
[54]
M.-J. Park, J. Lee, K. Cho, J. Park, J. Moon, S.-H. Lee, T.-K. Kim, S. Oh, S. Choi, Y . Choiet al., “A 192-Gb 12-High 896-GB/s HBM3 DRAM With a TSV Auto-Calibration Scheme and Machine-Learning-Based Layout Optimization,”IEEE Journal of Solid-State Circuits, vol. 58, no. 1, 2022
work page 2022
-
[55]
All-Inclusive ECC: Thorough End-to-End Protection for Reliable Computer Memory,
J. Kim, M. Sullivan, S. Lym, and M. Erez, “All-Inclusive ECC: Thorough End-to-End Protection for Reliable Computer Memory,” in Proceedings of the International Symposium on Computer Architecture (ISCA), 2016
work page 2016
-
[56]
On the Use of DRAM with Unrepaired Weak Cells in Computing Systems,
H. Wang, Y . Li, X. Zhang, X. Zhao, H. Sun, and T. Zhang, “On the Use of DRAM with Unrepaired Weak Cells in Computing Systems,” inProceedings of the Second International Symposium on Memory Systems, 2016
work page 2016
-
[57]
Cyclic Codes for Error Detection,
W. W. Peterson and D. T. Brown, “Cyclic Codes for Error Detection,” Proceedings of the IRE, vol. 49, no. 1, 1961
work page 1961
-
[58]
Removing Obstacles before Breaking Through the Memory Wall: A Close Look at HBM Errors in the Field,
R. Wu, S. Zhou, J. Lu, Z. Shen, Z. Xu, J. Shu, K. Yang, F. Lin, and Y . Zhang, “Removing Obstacles before Breaking Through the Memory Wall: A Close Look at HBM Errors in the Field,” inProceedings of the USENIX Annual Technical Conference (USENIX), 2024
work page 2024
-
[59]
X. Du and C. Li, “Predicting Uncorrectable Memory Errors from the Correctable Error History: No Free Predictors in the Field,” in Proceedings of the International Symposium on Memory Systems, 2021
work page 2021
-
[60]
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fanet al., “The Llama 3 Herd of Models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
J. Meza, Q. Wu, S. Kumar, and O. Mutlu, “Revisiting Memory Errors in Large-Scale Production Data Centers: Analysis and Modeling of New Trends from the Field,” inProceedings of the International Conference on Dependable Systems and Networks (DSN), 2015
work page 2015
-
[62]
Design for Soft Error Mitigation,
M. Nicolaidis, “Design for Soft Error Mitigation,”IEEE Transactions on Device and Materials Reliability, vol. 5, no. 3, 2005
work page 2005
-
[63]
DDR5 DRAM Faults in the Field,
M. V . Beigi, Y . Cao, G. Tsai, S. Gurumurthi, and V . Sridharan, “DDR5 DRAM Faults in the Field,” inProceedings of the International Conference on Dependable Systems and Networks-Supplemental Volume (DSN-S), 2025
work page 2025
-
[64]
Efficient RAS Support for Die- stacked DRAM,
H. Jeon, G. H. Loh, and M. Annavaram, “Efficient RAS Support for Die- stacked DRAM,” inProceedings of the International Test Conference (ITC), 2014
work page 2014
-
[65]
XED: Exposing On- Die Error Detection Information for Strong Memory Reliability,
P. J. Nair, V . Sridharan, and M. K. Qureshi, “XED: Exposing On- Die Error Detection Information for Strong Memory Reliability,” in Proceedings of the International Symposium on Computer Architecture (ISCA), 2016
work page 2016
-
[66]
Memory device on-die error checking and correcting code,
J. B. Halbert, K. S. Bains, and K. E. Criss, “Memory device on-die error checking and correcting code,” US Patent, Nov. 2017, issued Nov. 14, 2017. [Online]. Available: https://patents.google.com/patent/ US9817714B2/en
work page 2017
-
[67]
High Bandwidth Memory DRAM (HBM3),
JEDEC standard, “High Bandwidth Memory DRAM (HBM3),” in JESD238, 2022
work page 2022
-
[68]
DUO: Exposing On-Chip Redundancy to Rank-Level ECC for High Reliability,
S.-L. Gong, J. Kim, S. Lym, M. Sullivan, H. David, and M. Erez, “DUO: Exposing On-Chip Redundancy to Rank-Level ECC for High Reliability,” inProceedings of the International Symposium on High Performance Computer Architecture (HPCA), 2018
work page 2018
-
[69]
Dual-Axis ECC: Vertical and Horizontal Error Correction for Storage and Transfer Errors,
G. Jung, H. J. Na, S.-H. Kim, and J. Kim, “Dual-Axis ECC: Vertical and Horizontal Error Correction for Storage and Transfer Errors,” inProceedings of the International Conference on Computer Design (ICCD), 2024
work page 2024
-
[70]
M. Patel, G. F. de Oliveira, and O. Mutlu, “HARP: Practically and Effectively Identifying Uncorrectable Errors in Memory Chips that Use On-Die Error-Correcting Codes,” inProceedings of the International Symposium on Microarchitecture (MICRO), 2021
work page 2021
-
[71]
Low Power Double Data Rate (LPDDR) 5/5X,
JEDEC standard, “Low Power Double Data Rate (LPDDR) 5/5X,” in JESD209-5C, 2023
work page 2023
-
[72]
High-Speed Architectures for Reed–Solomon Decoders,
D. Sarwate and N. Shanbhag, “High-Speed Architectures for Reed–Solomon Decoders,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 9, no. 5, 2001
work page 2001
-
[73]
Reducing the Overhead of BCH Codes: New Double Error Correction Codes,
L. Saiz, J. Gracia, D. Gil, J.-C. Baraza-Calvo, and P. Gil-Vicente, “Reducing the Overhead of BCH Codes: New Double Error Correction Codes,”Electronics, vol. 9, 2020
work page 2020
-
[74]
Memory Errors in Modern Systems: The Good, The Bad, and The Ugly,
V . Sridharan, N. DeBardeleben, S. Blanchard, K. B. Ferreira, J. Stearley, J. Shalf, and S. Gurumurthi, “Memory Errors in Modern Systems: The Good, The Bad, and The Ugly,”ACM SIGARCH Computer Architecture News, vol. 50, no. 4, 2015
work page 2015
-
[75]
Accel-Sim: An Extensible Simulation Framework for Validated GPU Modeling,
M. Khairy, Z. Shen, T. M. Aamodt, and T. G. Rogers, “Accel-Sim: An Extensible Simulation Framework for Validated GPU Modeling,” in Proceedings of the 47th Annual International Symposium on Computer Architecture (ISCA), 2020
work page 2020
-
[76]
A Characterization of the Rodinia Benchmark Suite with Comparison to Contemporary CMP Workloads,
S. Che, J. W. Sheaffer, M. Boyer, L. G. Szafaryn, L. Wang, and K. Skadron, “A Characterization of the Rodinia Benchmark Suite with Comparison to Contemporary CMP Workloads,” inProceedings of the International Symposium on Workload Characterization (IISWC), 2010
work page 2010
-
[77]
Parboil: A Revised Benchmark Suite for Scientific and Commercial Throughput Computing,
J. A. Stratton, C. I. Rodrigues, I.-J. Sung, N. Obeid, L.-W. Chang, N. Anssari, G. Liu, and W. mei W. Hwu, “Parboil: A Revised Benchmark Suite for Scientific and Commercial Throughput Computing,”Center for Reliable and High-Performance Computing, vol. 127, no. 7.2, 2012
work page 2012
-
[78]
GraphBIG: Understanding Graph Computing in the Context of Industrial Solutions,
L. Nai, Y . Xia, I. G. Tanase, H. Kim, and C.-Y . Lin, “GraphBIG: Understanding Graph Computing in the Context of Industrial Solutions,” inProceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis (SC), 2015
work page 2015
-
[79]
PolyBench/Python: Benchmarking Python Environments with Polyhedral Optimizations,
M. A. Abella-Gonz ´alez, P. Carollo-Fern ´andez, L.-N. Pouchet, F. Rastello, and G. Rodr ´ıguez, “PolyBench/Python: Benchmarking Python Environments with Polyhedral Optimizations,” inProceedings of the 30th ACM SIGPLAN International Conference on Compiler Construction, 2021
work page 2021
-
[80]
Defect Analysis and Cost-Effective Resilience Architecture for Future DRAM Devices,
S. Cha, O. Seongil, H. Shin, S. Hwang, K. Park, S. J. Jang, J. S. Choi, G. Y . Jin, Y . H. Son, H. Cho, J. H. Ahn, and N. S. Kim, “Defect Analysis and Cost-Effective Resilience Architecture for Future DRAM Devices,” inProceedings of the International Symposium on High Performance Computer Architecture (HPCA), 2017
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.