Recognition: 3 theorem links
· Lean TheoremBucketing the Good Apples: A Method for Diagnosing and Improving Causal Abstraction
Pith reviewed 2026-05-08 19:08 UTC · model grok-4.3
The pith
Partitioning neural network inputs by pairwise interchange behavior diagnoses where causal interpretations succeed and fail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
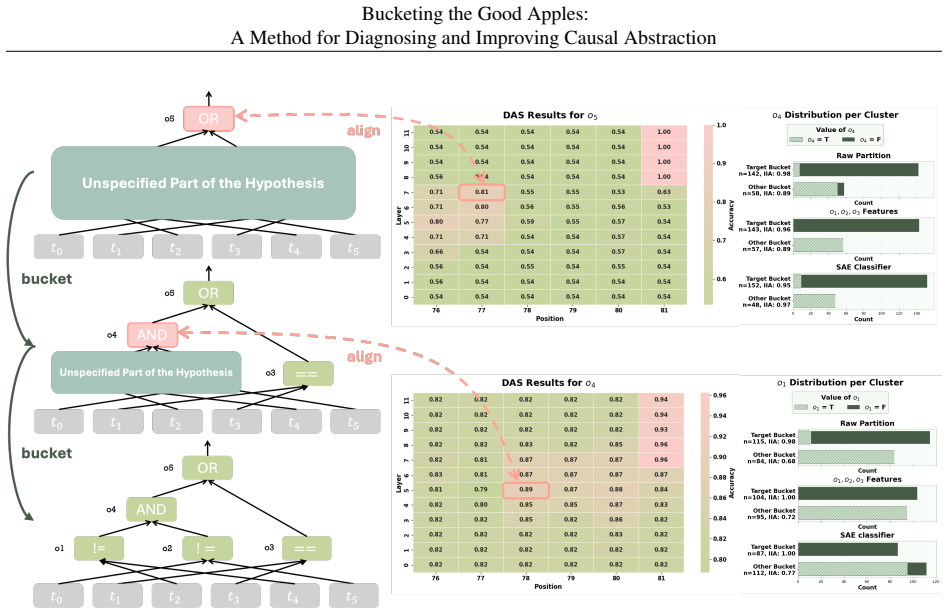
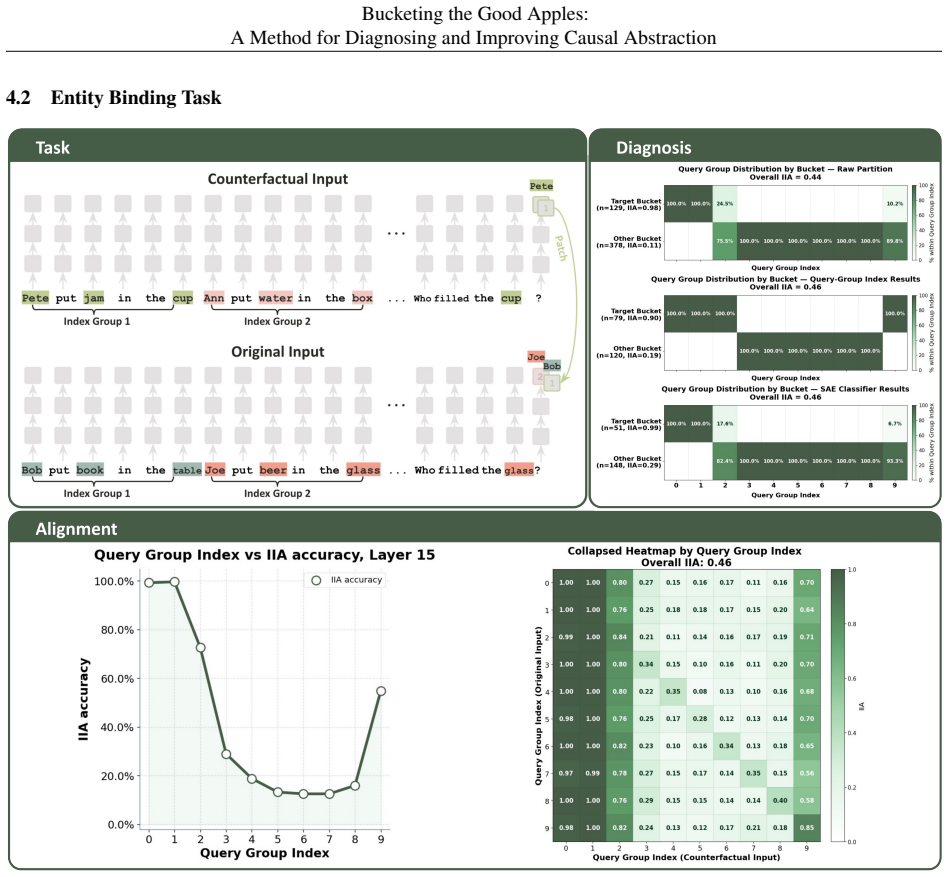
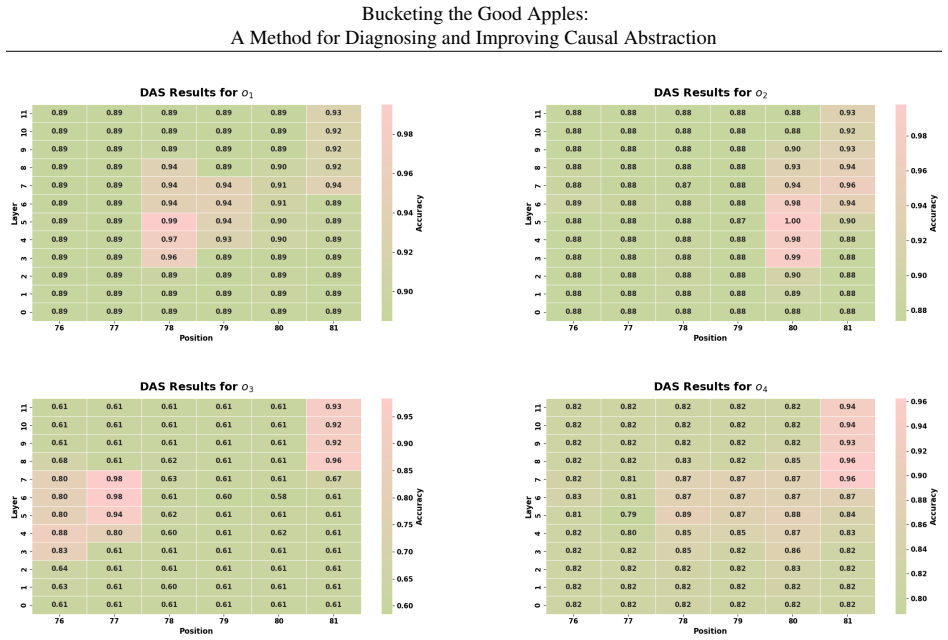
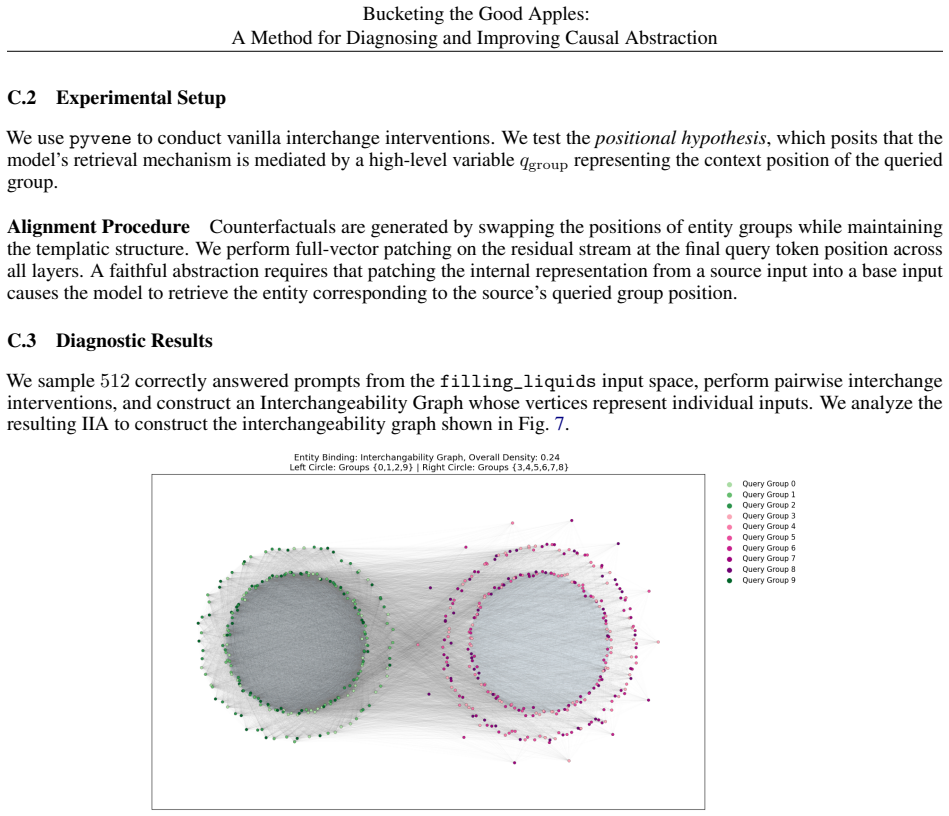
Partitioning the input space into well-interpreted and under-interpreted regions according to pairwise interchange-intervention behavior converts causal abstraction evaluation from a single global metric into a diagnostic procedure that measures faithfulness in specific subspaces, exposes where a proposed high-level hypothesis falls short, and supplies heuristics for locating missing distinctions, unmodeled intermediate variables, and opportunities to merge complementary partial interpretations into a stronger account.
What carries the argument
The partitioning of the input space into well-interpreted and under-interpreted regions according to pairwise interchange-intervention behavior, which acts as a diagnostic lens revealing the fidelity of a causal abstraction in different input subspaces.
If this is right
- Reveals specific subspaces where the proposed interpretation is highly faithful to the network.
- Identifies distinctions that are missing from the high-level causal hypothesis.
- Discovers previously unmodeled intermediate variables in the computation.
- Guides the combination of complementary partial interpretations into a stronger overall account.
- Supplies concrete heuristics for iteratively improving the quality of the interpretation.
Where Pith is reading between the lines
- The same partitioning step could localize strengths and weaknesses in other intervention-based interpretability techniques beyond causal abstraction.
- Repeated application of the recipe might support automated, incremental construction of high-level models from minimal starting points.
- Global faithfulness scores may systematically mask localized failures that become visible once inputs are divided by intervention behavior.
Load-bearing premise
That differences in interchange behavior across input regions reliably reflect gaps in the high-level causal hypothesis rather than arising from the intervention procedure itself or from the distribution of the data.
What would settle it
If using the structure of under-interpreted regions to add missing distinctions or variables to the high-level hypothesis fails to raise interchange intervention accuracy on held-out inputs, the diagnostic claim would be undermined.
Figures




read the original abstract
We present a method for diagnosing interpretation in neural networks by identifying an input subspace where a proposed interpretation is highly faithful. Our method is particularly useful for causal-abstraction-style interpretability, where a high-level causal hypothesis is evaluated by interchange interventions. Rather than treating interchange intervention accuracy as a single global summary, we refine this framework by partitioning the input space into well-interpreted and under-interpreted regions according to pairwise interchange-intervention behavior. This turns causal abstraction from a purely global evaluation into a more diagnostic tool: it not only measures whether an interpretation works, but also reveals where it works, where it fails, and what distinguishes the two cases. This diagnostic view also provides practical heuristics for improving interpretations. By analyzing the structure of the well-interpreted and under-interpreted regions, we can identify missing distinctions in a high-level hypothesis, discover previously unmodeled intermediate variables, and combine complementary partial interpretations into a stronger one. We instantiate this idea as a simple four-step recipe and show that it yields informative error analyses across multiple causal abstraction settings. In a toy logic task, recursively applying the recipe recovers a high-level hypothesis from scratch. More broadly, our results suggest that partitioning the input space is a useful step toward more precise, constructive, and scalable mechanistic interpretability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a 'bucketing' method that partitions the input space into well-interpreted and under-interpreted regions according to pairwise interchange-intervention accuracy. This refines causal-abstraction evaluation from a single global metric into a diagnostic tool that localizes where a high-level causal hypothesis is faithful, identifies missing distinctions or unmodeled variables, and supplies heuristics for combining partial interpretations or improving the model. The approach is instantiated as a four-step recipe and demonstrated on multiple causal-abstraction settings, including a toy logic task in which recursive application recovers a high-level hypothesis from scratch.
Significance. If the partitions reliably track structural gaps in the high-level model rather than intervention artifacts or input correlations, the method would meaningfully advance mechanistic interpretability by converting causal abstraction from a pass/fail test into a constructive diagnostic with actionable improvement steps. The toy-task recovery result and the parameter-free character of the partitioning (no free parameters or ad-hoc axioms listed in the ledger) are concrete strengths that would support broader adoption if the central assumption holds.
major comments (2)
- [abstract and four-step recipe description] The central diagnostic claim—that high vs. low pairwise interchange regions correspond to missing distinctions or unmodeled intermediates in the high-level hypothesis rather than data-distribution or intervention artifacts—is load-bearing but not directly tested. The manuscript reports success on the toy logic task but does not include controls (e.g., shuffled base/source pairs or distribution-matched null models) that would falsify the alternative explanation raised in the skeptic note.
- [toy logic task experiment] The improvement heuristics (identifying missing distinctions, discovering intermediates, combining partial interpretations) are presented as direct consequences of the bucketing structure, yet no quantitative metric is given showing that the recovered partitions in the toy task align with the known causal variables beyond overall accuracy recovery.
minor comments (2)
- [abstract] The abstract states that the method 'yields informative error analyses across multiple causal abstraction settings' but does not specify what quantitative or qualitative criteria define 'informative' or how many settings were examined beyond the toy example.
- [method] Notation for 'pairwise interchange-intervention behavior' is introduced without an explicit equation or pseudocode in the summary; readers would benefit from a compact formal definition early in the method section.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. We address each major comment below and have revised the manuscript to incorporate additional controls and quantitative metrics where these strengthen the presentation without altering the core claims.
read point-by-point responses
-
Referee: The central diagnostic claim—that high vs. low pairwise interchange regions correspond to missing distinctions or unmodeled intermediates in the high-level hypothesis rather than data-distribution or intervention artifacts—is load-bearing but not directly tested. The manuscript reports success on the toy logic task but does not include controls (e.g., shuffled base/source pairs or distribution-matched null models) that would falsify the alternative explanation raised in the skeptic note.
Authors: We agree that explicit controls against distribution or intervention artifacts would provide stronger falsification of alternatives. The toy logic task offers indirect support because the procedure begins from a null hypothesis and recovers the exact high-level structure through iterative bucketing; such recovery is unlikely to occur if partitions were driven primarily by artifacts. Nevertheless, we have added a new subsection with shuffled base/source pair controls and distribution-matched null models. These experiments show that high-accuracy buckets do not emerge under randomization, supporting the structural interpretation of the partitions. revision: yes
-
Referee: The improvement heuristics (identifying missing distinctions, discovering intermediates, combining partial interpretations) are presented as direct consequences of the bucketing structure, yet no quantitative metric is given showing that the recovered partitions in the toy task align with the known causal variables beyond overall accuracy recovery.
Authors: The toy task demonstrates the heuristics via exact recovery of the ground-truth causal variables and structure. We acknowledge that a quantitative alignment metric would make the correspondence more precise. In the revision we introduce such a metric (adjusted Rand index between the learned buckets and the true variable partitions) and report that it indicates strong alignment beyond the global accuracy figure, thereby quantifying the support for the heuristics. revision: yes
Circularity Check
No significant circularity; method extends interchange interventions via explicit partitioning without reduction to inputs
full rationale
The paper takes the existing interchange intervention accuracy metric as an established input and defines partitions directly from pairwise behavior on that metric. The diagnostic claims (identifying missing distinctions, unmodeled variables, or complementary interpretations) are interpretive consequences of inspecting the resulting regions rather than any equation or definition that reduces the output to the input by construction. No self-citation is invoked to justify a uniqueness theorem or to smuggle an ansatz; the framework is used as a black-box tool whose prior validation is external to this work. The toy logic recovery is an empirical demonstration, not a forced mathematical identity. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Interchange interventions on neural networks can be used to evaluate the faithfulness of a high-level causal hypothesis
Reference graph
Works this paper leans on
-
[1]
URLhttps://aclanthology.org/2024.acl-long.785
Association for Computational Linguistics. URLhttps://aclanthology.org/2024.acl-long.785. Sasha Boguraev, Christopher Potts, and Kyle Mahowald. Causal interventions reveal shared structure across English filler–gap constructions. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Findings of the Association for Comp...
2024
-
[2]
URL https://aclanthology.org/2025.emnlp-main
Association for Computational Linguistics. URL https://aclanthology.org/2025.emnlp-main. 1271/. Adly Bricken, Adni Templeton, Joshua Batson, Brian Chen, Adam Jerome, Scott Moore, Shahar Tamkin, Landon Jones, Dustin Conerly, Hoagy Cunningham, et al. Towards monosemanticity: Decomposing language models with sparse autoencoders.Transformer Circuits Thread,
2025
-
[3]
Visual causal feature learning.arXiv preprint arXiv:1412.2309, 2014
Krzysztof Chalupka, Pietro Perona, and Frederick Eberhardt. Visual causal feature learning.arXiv preprint arXiv:1412.2309,
-
[4]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600,
-
[5]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, et al. Toy models of superposition.arXiv preprint arXiv:2209.10652,
work page internal anchor Pith review arXiv
-
[6]
Neural natural language inference models partially embed theories of lexical entailment and negation
Atticus Geiger, Kyle Richardson, and Christopher Potts. Neural natural language inference models partially embed theories of lexical entailment and negation. InProceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP, pages 163–173, Online, November 2020a. Association for Computa- tional Linguistics. doi: 10.1865...
-
[7]
Atticus Geiger, Duligur Ibeling, Amir Zur, Maheep Chaudhary, Sonakshi Chauhan, Jing Huang, Aryaman Arora, Zhengxuan Wu, Noah Goodman, Christopher Potts, et al. Causal abstraction: A theoretical foundation for mechanistic interpretability.arXiv preprint arXiv:2301.04709, 2023a. Atticus Geiger, Zhengxuan Wu, Christopher Potts, Thomas Icard, and Noah Goodman...
-
[8]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495,
2021
-
[9]
Dissecting recall of factual associations in auto- regressive language models
Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson. Dissecting recall of factual associations in auto- regressive language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12216–12235,
2023
-
[10]
arXiv preprint arXiv:2510.06182 , year=
Yoav Gur-Arieh, Mor Geva, and Atticus Geiger. Mixing mechanisms: How language models retrieve bound entities in-context.arXiv preprint arXiv:2510.06182,
-
[11]
Stefan Heimersheim and Neel Nanda
10 Bucketing the Good Apples: A Method for Diagnosing and Improving Causal Abstraction Zhengfu He, Wentao Shu, Xuyang Ge, Lingjie Chen, Junxuan Wang, Yunhua Zhou, Frances Liu, Qipeng Guo, Xuanjing Huang, Zuxuan Wu, et al. Llama scope: Extracting millions of features from llama-3.1-8b with sparse autoencoders. arXiv preprint arXiv:2410.20526,
-
[12]
arXiv preprint arXiv:2308.09124 , year=
Evan Hernandez, Arnab Sen Sharma, Tal Haklay, Kevin Meng, Martin Wattenberg, Jacob Andreas, Yonatan Belinkov, and David Bau. Linearity of relation decoding in transformer language models.arXiv preprint arXiv:2308.09124,
-
[13]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on
Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Nicolas Sonnerat, Vikrant Varma, János Kramár, Anca Dragan, Rohin Shah, and Neel Nanda. Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2.arXiv preprint arXiv:2408.05147,
-
[14]
Aleksandar Makelov, Georg Lange, and Neel Nanda. Is this the subspace you are looking for? an interpretability illusion for subspace activation patching.arXiv preprint arXiv:2311.17030,
-
[15]
Maxime Méloux, Silviu Maniu, François Portet, and Maxime Peyrard. Everything, everywhere, all at once: is mechanistic interpretability identifiable?arXiv preprint arXiv:2502.20914,
-
[16]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT. Advances in Neural Information Processing Systems, 36, 2022a. Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. Mass-editing memory in a transformer.arXiv preprint arXiv:2210.07229, 2022b. Chris Olah, Nick Cammarata, Lu...
-
[17]
Zoom in: An introduction to circuits
doi: 10.23915/distill.00024.001. https://distill.pub/2020/circuits/zoom-in. Judea Pearl.Causality. Cambridge university press,
-
[18]
Theodora-Mara Pîslar, Sara Magliacane, and Atticus Geiger. Combining causal models for more accurate abstractions of neural networks.arXiv preprint arXiv:2503.11429,
-
[19]
Adam Scherlis, Kshitij Sachan, Adam S. Jermyn, Joe Benton, and Buck Shlegeris. Polysemanticity and capacity in neural networks.CoRR, abs/2210.01892,
-
[20]
Language Model Cascades: Token-Level Uncertainty and Beyond
doi: 10.48550/ARXIV .2210.01892. URL https://doi.org/10. 48550/arXiv.2210.01892. Paul Smolensky. Neural and conceptual interpretation of pdp models.Parallel distributed processing: Explorations in the microstructure of cognition, 2:390–431,
work page internal anchor Pith review doi:10.48550/arxiv
-
[21]
Zhengxuan Wu, Atticus Geiger, Aryaman Arora, Jing Huang, Zheng Wang, Noah D Goodman, Christopher D Manning, and Christopher Potts. pyvene: A library for understanding and improving pytorch models via interventions.arXiv preprint arXiv:2403.07809, 2024a. Zhengxuan Wu, Atticus Geiger, Jing Huang, Aryaman Arora, Thomas Icard, Christopher Potts, and Noah D Go...
-
[22]
t0,t1,t2,t3,t4,t5=
o4 :=o 1 ∧o 2 o5 :=o 4 ∨o 3 Dataset ConstructionTo format the inputs for the language model, we use an in-context learning template. Each prompt consists of 5 randomly sampled context examples (with their corresponding ground-truth Boolean labels) to establish the task format, followed by the target six-token sequence formatted as “t0,t1,t2,t3,t4,t5=”. Th...
2048
-
[23]
People in San Francisco speak
to determine if the boundaries between well-interpreted and under-interpreted regions are explicitly encoded in the model’s feature space. D Entangled Factual Recall Task Details D.1 Task Specification and Dataset We evaluate the entangled factual recall setting using the RA VEL benchmark [Huang et al., 2024] on theLlama-3.1-8B model. We focus on the LANG...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.