Recognition: 3 theorem links
· Lean TheoremReliability-Oriented Multilingual Orthopedic Diagnosis: A Domain-Adaptive Modeling and a Conceptual Validation Framework
Pith reviewed 2026-05-08 19:26 UTC · model grok-4.3
The pith
Domain-adaptive specialization with language-specific adapters substantially improves reliability and calibration in multilingual orthopedic diagnosis compared to zero-shot large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that domain-adaptive specialization substantially improves cross-lingual discrimination and confidence behavior for orthopedic diagnosis. IndicBERT-HPA, equipped with language-specific orthopedic adapter heads, delivers strong performance across six categories with more predictable deployment characteristics than either task-only adaptation or zero-shot LLMs. LLMs show fluency but unstable calibration under structured multilingual conditions, particularly in low-resource languages. These results are based on comparisons with task-aligned multilingual encoders and a DistilBERT baseline.
What carries the argument
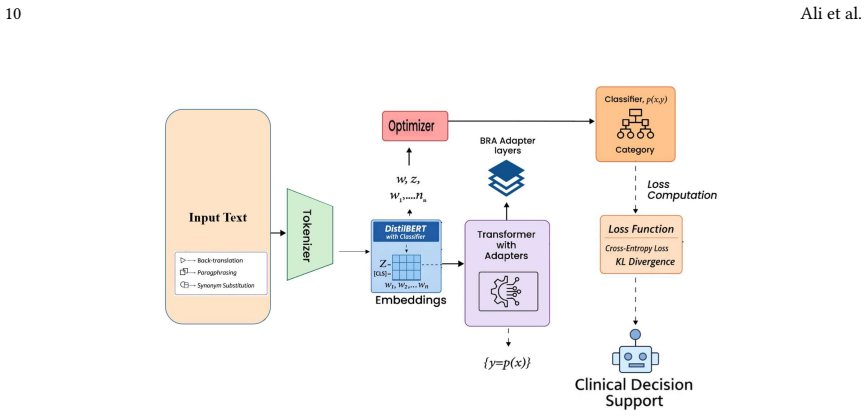
IndicBERT-HPA, a domain-adaptive architecture that adds language-specific orthopedic adapter heads to a multilingual transformer encoder for specialized processing of orthopedic clinical text.
If this is right
- Specialized domain adaptation leads to improved discrimination in cross-lingual settings for clinical tasks.
- Models exhibit more stable confidence estimates suitable for deployment.
- Zero-shot LLMs are less suitable for structured high-risk diagnostic classification.
- The proposed validation framework can enforce language-sensitive checks and conservative gating.
Where Pith is reading between the lines
- Similar adapter-based specialization might benefit diagnosis in other medical domains beyond orthopedics.
- Testing on larger, more diverse real-world datasets could reveal if the advantages hold in varied clinical environments.
- Integration into actual hospital systems would require addressing data privacy and integration challenges not covered here.
Load-bearing premise
The evaluation dataset and six diagnostic categories represent typical real clinical notes without biases that would artificially favor the domain-adapted model over zero-shot approaches.
What would settle it
Demonstrating on a new, independent collection of multilingual clinical notes that zero-shot LLMs achieve comparable or superior calibration and accuracy would challenge the finding that domain adaptation is necessary for reliability.
Figures







read the original abstract
Large Language Models (LLMs) are increasingly proposed for clinical decision support including multilingual diagnosis in low-resource settings. However, their reliability, calibration and safety characteristics remain insufficiently understood for structured, high-risk tasks. We present a system-level analysis of multilingual orthopedic diagnosis from free-text clinical notes in English, Hindi and Punjabi. We evaluate three modeling regimes: (i) task-aligned multilingual transformer encoders, (ii) a task-fine-tuned baseline (DistilBERT), and (iii) a domain-adaptive architecture tailored to orthopedic text (IndicBERT-HPA). These models are compared with zero-shot, instruction-tuned LLMs to assess suitability for structured diagnostic classification. Results indicate that while LLMs exhibit strong linguistic fluency, they show unstable calibration and reduced reliability under structured multilingual conditions, particularly in low-resource languages. These findings are specific to zero-shot evaluation and do not imply limitations of fine-tuned models. Domain-adaptive specialization substantially improves cross-lingual discrimination and confidence behavior. IndicBERT-HPA, with language-specific orthopedic adapter heads achieves consistently strong performance across six diagnostic categories and more predictable deployment characteristics than task-only adaptation. Building on these observations, we outline a conceptual deterministic agent-based validation framework for future implementation, formalizing evidence checks, language-sensitive validation and conservative human-in-the-loop gating. Reliable multilingual clinical decision support requires specialized architecture, explicit reliability analysis, and structured validation for safety-critical systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript conducts a system-level analysis of multilingual orthopedic diagnosis from free-text clinical notes in English, Hindi, and Punjabi. It evaluates three modeling regimes—task-aligned multilingual transformer encoders, a task-fine-tuned DistilBERT baseline, and the domain-adaptive IndicBERT-HPA architecture with language-specific orthopedic adapter heads—against zero-shot instruction-tuned LLMs. The central empirical claim is that domain-adaptive specialization yields substantially better cross-lingual discrimination and confidence calibration than task-only adaptation or zero-shot LLMs, with IndicBERT-HPA delivering consistent performance across six diagnostic categories and more predictable deployment behavior. The paper additionally sketches a conceptual deterministic agent-based validation framework incorporating evidence checks, language-sensitive validation, and human-in-the-loop gating.
Significance. If the empirical comparisons are supported by adequately documented data and statistical analysis, the work would usefully illustrate the limitations of zero-shot LLMs on structured, high-stakes multilingual clinical tasks and the value of domain-specific adapter specialization for reliability. The outlined validation framework offers a constructive direction for safety-critical deployment. The absence of quantitative details in the abstract, however, prevents assessment of whether these contributions are currently substantiated.
major comments (2)
- [Abstract] Abstract: The abstract asserts that IndicBERT-HPA 'achieves consistently strong performance across six diagnostic categories' and 'more predictable deployment characteristics' yet reports no dataset sizes, class distributions, exact metrics (accuracy, F1, calibration error), statistical significance tests, or error analysis. Without these, the comparative claims cannot be evaluated and the reliability conclusions remain unverifiable.
- [Results / Evaluation] Evaluation setup (implied in results discussion): The central claim that domain-adaptive specialization improves cross-lingual discrimination rests on the unverified assumption that the evaluation notes in Hindi and Punjabi are representative real clinical data without curation or translation biases that could favor IndicBERT-HPA. No information is supplied on data sourcing, annotation process, translation method, or class balance, which is load-bearing for the headline conclusion.
minor comments (2)
- [Abstract] The abstract states that findings 'are specific to zero-shot evaluation and do not imply limitations of fine-tuned models,' but this caveat is not carried through clearly into the comparative discussion or framework section.
- [Introduction / Methods] Notation for the six diagnostic categories and the precise definition of 'language-specific orthopedic adapter heads' should be introduced earlier and used consistently.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important areas for improving clarity and transparency, particularly regarding the abstract and data documentation. We address each major comment below and commit to revisions that strengthen the verifiability of our empirical claims without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts that IndicBERT-HPA 'achieves consistently strong performance across six diagnostic categories' and 'more predictable deployment characteristics' yet reports no dataset sizes, class distributions, exact metrics (accuracy, F1, calibration error), statistical significance tests, or error analysis. Without these, the comparative claims cannot be evaluated and the reliability conclusions remain unverifiable.
Authors: We agree that the abstract would be strengthened by including key quantitative details to support the claims made. In the revised version, we will expand the abstract to report summary statistics such as the total number of clinical notes per language, overall accuracy and macro-F1 for the IndicBERT-HPA model across the six categories, and a brief reference to improved calibration error relative to zero-shot LLMs. We will also note that full tables with per-category metrics, class distributions, and statistical significance results (e.g., paired tests) appear in the results section. This change will allow readers to assess the claims directly from the abstract while respecting length limits. revision: yes
-
Referee: [Results / Evaluation] Evaluation setup (implied in results discussion): The central claim that domain-adaptive specialization improves cross-lingual discrimination rests on the unverified assumption that the evaluation notes in Hindi and Punjabi are representative real clinical data without curation or translation biases that could favor IndicBERT-HPA. No information is supplied on data sourcing, annotation process, translation method, or class balance, which is load-bearing for the headline conclusion.
Authors: We acknowledge that greater transparency on data provenance is essential for substantiating cross-lingual claims in a clinical context. The manuscript currently provides only a high-level overview of the evaluation notes. In the revision, we will add a dedicated subsection detailing: (1) data sourcing (publicly available de-identified clinical note collections supplemented by expert-generated examples where needed), (2) annotation process (conducted by board-certified orthopedic specialists with inter-annotator agreement metrics), (3) translation method (professional medical translators followed by back-translation checks for fidelity), and (4) class balance statistics with explicit discussion of any curation steps and potential biases. We will also include an analysis of how these factors were controlled to ensure the comparison remains fair. revision: yes
Circularity Check
No circularity: empirical comparisons rest on external data and benchmarks
full rationale
The paper presents an empirical evaluation of three modeling regimes (task-aligned encoders, DistilBERT baseline, IndicBERT-HPA) against zero-shot LLMs on multilingual orthopedic notes across six diagnostic categories. No equations, derivations, or first-principles claims appear in the provided text; performance and calibration results are reported as direct measurements rather than predictions derived from fitted parameters or self-referential definitions. The conceptual validation framework is outlined as future work without load-bearing self-citations or ansatz smuggling. The derivation chain is therefore self-contained against external benchmarks and does not reduce to its own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The six diagnostic categories are clinically meaningful and balanced across languages
- domain assumption Zero-shot LLM outputs can be directly compared to fine-tuned encoder outputs on the same task
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.AlphaCoordinateFixationwashburn_uniqueness_aczel; J_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
˜ℎ_t = ℎ_t + W₂^(ℓ) σ(W₁^(ℓ) ℎ_t + b₁^(ℓ)) + b₂^(ℓ) ... r = 512 is the adapter bottleneck dimension, σ(·) denotes a non-linear activation (ReLU)
-
Cost (RS uses J(x) = ½(x+x⁻¹) − 1, not cross-entropy)Jcost / cost_alpha_one_eq_jcost unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
L = −Σ log p(y_i | x_i) ... cross-entropy classification objective with softmax head
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Moustafa Abdelwanis, Hamdan Khalaf Alarafati, Maram Muhanad Saleh Tammam, and Mecit Can Emre Simsekler. 2024. Exploring the risks of automation bias in healthcare artificial intelligence applications: A Bowtie analysis.Journal of Safety Science and Resilience5, 4 (2024), 460–469
2024
-
[2]
Abirami, N
S. Abirami, N. Krishnammal, R. Suganya, and R. T. Suganya. 2026. NLP Powered Orthopaedics Expert System. InProceedings of the 2026 International Conference on Intelligent and Innovative Technologies in Computing, Electrical and Electronics (IITCEE). IEEE, 1–5
2026
-
[3]
Hugo Araujo, Mohammad Reza Mousavi, and Mahsa Varshosaz. 2023. Testing, validation, and verification of robotic and autonomous systems: a systematic review.ACM Transactions on Software Engineering and Methodology32, 2 (2023), 1–61
2023
-
[4]
Hayden P Baker, Sarthak Aggarwal, Senthooran Kalidoss, Matthew Hess, Rex Haydon, and Jason A Strelzow. 2025. Diagnostic accuracy of ChatGPT-4 in orthopedic oncology: a comparative study with residents.The Knee55 (2025), 153–160
2025
-
[5]
Prashant Baranwal, Ankit Pundir, Sandeep Singh, and Gaurav Saxena. 2025. Embedding-Driven Clustering for Unerring Content Categorization in Low-Resource Hindi Language.ACM Transactions on Asian and Low-Resource Language Information Processing24, 12 (2025), 1–33
2025
-
[6]
Agnese Bonfigli, Luca Bacco, Mario Merone, and Felice Dell’Orletta. 2024. From pre-training to fine-tuning: An in-depth analysis of Large Language Models in the biomedical domain.Artificial Intelligence in Medicine157 (2024), 103003
2024
-
[7]
Qiang Chen, Yu Hu, Xi Peng, Qian Xie, Qiang Jin, Aaron Gilson, and Hua Xu. 2025. Benchmarking Large Language Models for Biomedical Natural Language Processing Applications and Recommendations.Nature Communications16, 1 (2025), 3280
2025
-
[8]
Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng. 2025. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
2025
-
[9]
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, et al. 2020. Unsupervised Cross-lingual Representation Learning at Scale. InACL
2020
-
[10]
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020. Unsupervised cross-lingual representation learning at scale. InProceedings of the 58th annual meeting of the association for computational linguistics. 8440–8451
2020
-
[11]
Warren Del-Pinto, George Demetriou, Meghna Jani, Rikesh Patel, Leanne Gray, Alex Bulcock, Niels Peek, Andrew S Kanter, William G Dixon, and Goran Nenadic. 2025. Exploring the consistency, quality and challenges in manual and automated coding of free-text diagnoses from hospital outpatient letters.Plos one20, 8 (2025), e0328108
2025
-
[12]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. InNAACL-HLT
2019
-
[13]
Shangheng Du, Jiabao Zhao, Jinxin Shi, Zhentao Xie, Xin Jiang, Yanhong Bai, and Liang He. 2026. A survey on the optimization of large language model-based agents.Comput. Surveys58, 9 (2026), 1–37
2026
-
[14]
Niles, Ken Pathak, and Steven Sloan
Md Meftahul Ferdaus, Mahdi Abdelguerfi, Elias Loup, Kendall N. Niles, Ken Pathak, and Steven Sloan. 2026. Towards trustworthy AI: a review of ethical and robust large language models.Comput. Surveys58, 7 (2026), 1–43. Manuscript submitted to ACM 30 Ali et al
2026
-
[15]
Gaber, M
F. Gaber, M. Shaik, F. Allega, A. J. Bilecz, F. Busch, K. Goon, and A. Akalin. 2025. Evaluating large language model workflows in clinical decision support for triage and referral and diagnosis.npj Digital Medicine8, 1 (2025), 263
2025
-
[16]
Shang Gao, Mohammed Alawad, M Todd Young, John Gounley, Noah Schaefferkoetter, Hong Jun Yoon, Xiao-Cheng Wu, Eric B Durbin, Jennifer Doherty, Antoinette Stroup, et al. 2021. Limitations of transformers on clinical text classification.IEEE journal of biomedical and health informatics 25, 9 (2021), 3596–3607
2021
-
[17]
Edgar Garcia-Lopez, Jamieson O’Marr, Rachel Gottlieb, Katherine Rebecca Miclau, and Nirav Pandya. 2025. Language Barriers in the Delivery of Musculoskeletal Care and Future Directions.Current Reviews in Musculoskeletal Medicine(2025), 1–9
2025
-
[18]
Pengcheng He, Jianfeng Gao, Weizhu Chen, and Jason Wang. 2021. mDeBERTa: Efficient Multilingual Pre-trained Model for Low-Resource Languages. InFindings of EMNLP
2021
-
[19]
Koki Horiguchi, Tomoyuki Kajiwara, Takashi Ninomiya, Shoko Wakamiya, and Eiji Aramaki. 2025. MultiMSD: A corpus for multilingual medical text simplification from online medical references. InFindings of the Association for Computational Linguistics: ACL 2025. 9248–9258
2025
-
[20]
Dipika Jain. 2025. Multilingual and Cross-Linguistic Challenges in NLP. InTransformative Natural Language Processing: Bridging Ambiguity in Healthcare, Legal, and Financial Applications. Springer, 157–177
2025
-
[21]
Shaoxiong Ji, Xiaobo Li, Wei Sun, Hang Dong, Ara Taalas, Yijia Zhang, Honghan Wu, Esa Pitkänen, and Pekka Marttinen. 2024. A Unified Review of Deep Learning for Automated Medical Coding.Comput. Surveys56, 12 (2024), 1–41
2024
-
[22]
Kyungjin Kim, Jinju Kim, Haeji Jung, David R Mortensen, and Jongmo Seo. 2025. Domain-Specific Multilingual Strategies for Medical NLP: A Cross-Lingual Analysis of Orthographic and Phonemic Representations. In2025 47th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE, 1–6
2025
-
[23]
Young-Tak Kim, Hyunji Kim, Manisha Bahl, Michael H Lev, Ramon Gilberto González, Michael S Gee, and Synho Do. 2026. Defining operational safety in clinical artificial intelligence systems.npj Digital Medicine(2026)
2026
-
[24]
Dani Kiyasseh, Tingting Zhu, and David Clifton. 2020. The promise of clinical decision support systems targetting low-resource settings.IEEE Reviews in Biomedical Engineering15 (2020), 354–371
2020
-
[25]
Bo Li. 2024. A Study of DistilBERT-Based Answer Extraction Machine Reading Comprehension Algorithm. InProceedings of the 2024 3rd International Conference on Cyber Security, Artificial Intelligence and Digital Economy. 261–268
2024
-
[26]
Chen Ling, Xujiang Zhao, Jiaying Lu, Chengyuan Deng, Can Zheng, Junxiang Wang, Tanmoy Chowdhury, Yun Li, Hejie Cui, Xuchao Zhang, et al
-
[27]
Surveys58, 3 (2025), 1–39
Domain specialization as the key to make large language models disruptive: A comprehensive survey.Comput. Surveys58, 3 (2025), 1–39
2025
-
[28]
Xinyang Liu, Ji Wang, Xiaoyang Yuan, Jing Sun, Guangyi Dong, Peng Di, and Dong Wang. 2023. Prompting Frameworks for Large Language Models: A Survey.Comput. Surveys(2023)
2023
-
[29]
Yang Liu, Jie Yu, Haoran Sun, Lei Shi, Guang Deng, Yong Chen, and Yang Liu. 2024. Efficient Detection of Toxic Prompts in Large Language Models. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (ASE ’24). Association for Computing Machinery, 455–467
2024
-
[30]
Durga Satish Matta and Saruladha Krishnamurthy. 2026. Enhancing sentiment analysis performance: a multilingual approach with advanced text processing and hybrid deep learning techniques with improved dung beetle optimization algorithm.Knowledge and Information Systems68, 1 (2026), 66
2026
-
[31]
Mark A Musen, Blackford Middleton, and Robert A Greenes. 2021. Clinical decision-support systems. InBiomedical informatics: computer applications in health care and biomedicine. Springer, 795–840
2021
-
[32]
Muhammad Kashif Nazir, CM Nadeem Faisal, Muhammad Asif Habib, and Haseeb Ahmad. 2025. Leveraging multilingual transformer for multiclass sentiment analysis in code-mixed data of low-resource languages.IEEE Access(2025)
2025
-
[33]
Lin Ning, Luyang Liu, Jiaxing Wu, Neo Wu, Devora Berlowitz, Sushant Prakash, Bradley Green, Shawn O’Banion, and Jun Xie. 2025. User-llm: Efficient llm contextualization with user embeddings. InCompanion Proceedings of the ACM on Web Conference 2025. 1219–1223
2025
-
[34]
Riccardo Nogaroli. 2025. Ethical and Legal Aspects of Artificial Intelligence (AI) in Medical Service Contracts. InMedical Liability and Artificial Intelligence. Springer
2025
-
[35]
Nikolaos Pangakis and Sebastian Wolken. 2024. Knowledge Distillation in Automated Annotation: Supervised Text Classification with LLM- Generated Training Labels. InProceedings of the Sixth Workshop on Natural Language Processing and Computational Social Science (NLP+CSS 2024), Dallas Card, Anjalie Field, Dirk Hovy, and Katherine Keith (Eds.). Association ...
- [36]
-
[37]
Yu Qiao, Phuong-Nam Tran, Ji Su Yoon, Loc X Nguyen, Eui-Nam Huh, Dusit Niyato, and Choong Seon Hong. 2025. Deepseek-inspired exploration of rl-based llms and synergy with wireless networks: A survey.Comput. Surveys58, 7 (2025), 1–37
2025
-
[38]
Pengcheng Qiu, Chaoyi Wu, Xiaoman Zhang, Weixiong Lin, Haicheng Wang, Ya Zhang, Yanfeng Wang, and Weidi Xie. 2024. Towards building multilingual language model for medicine.Nature Communications15, 1 (2024), 8384
2024
-
[39]
Lisa Raithel, Johann Frei, Philippe Thomas, Roland Roller, Pierre Zweigenbaum, Sebastian Möller, and Frank Kramer. 2025. Cross-& multi-lingual medication detection: a transformer-based analysis.BMC Medical Informatics and Decision Making25, 1 (2025), 359
2025
-
[40]
Rohit Singh Raja. 2025. A multi-level NLP framework for medical concept mapping in healthcare AI systems. In2025 IEEE 4th International Conference on AI in Cybersecurity (ICAIC). IEEE, 1–3. Manuscript submitted to ACM Reliability-Oriented Multilingual Orthopedic Diagnosis: A Domain-Adaptive Modeling and a Conceptual Validation Framework 31
2025
-
[41]
Tizabi, Michael Baumgartner, Maximilian Eisenmann, et al
Annika Reinke, Mohammad D. Tizabi, Michael Baumgartner, Maximilian Eisenmann, et al. 2024. Understanding metric-related pitfalls in image analysis validation.Nature(2024)
2024
-
[42]
Jenifer Shanmugasundaram and Ratnavel Rajalakshmi. 2024. Multilingual Claim Span Identification With DaBERTa. InInternational Conference on Speech and Language Technologies for Low-resource Languages. Springer, 512–522
2024
-
[43]
Telmo Silva Filho, Hao Song, Miquel Perello-Nieto, Raul Santos-Rodriguez, Meelis Kull, and Peter Flach. 2023. Classifier calibration: a survey on how to assess and improve predicted class probabilities.Machine Learning112, 9 (2023), 3211–3260
2023
-
[44]
Adir Solomon, Maxim Glebov, and Teddy Lazebnik. 2025. Explainable Surgical Procedures Recommender System Leveraging Large Language Models.ACM Transactions on Recommender Systems(2025)
2025
-
[45]
Sauhard Soni and S Lalitha. 2025. Effective Multilingual and Mixed-lingual DSR System for Healthcare Application in Indian Languages.Procedia Computer Science258 (2025), 1219–1231
2025
-
[46]
Hiren Thakkar and A Manimaran. 2023. Comprehensive examination of instruction-based language models: A comparative analysis of mistral-7b and llama-2-7b. In2023 International Conference on Emerging Research in Computational Science (ICERCS). IEEE, 1–6
2023
-
[47]
Jeffrey Thompson, Jinxiang Hu, Dinesh Pal Mudaranthakam, David Streeter, Lisa Neums, Michele Park, Devin C Koestler, Byron Gajewski, Roy Jensen, and Matthew S Mayo. 2019. Relevant word order vectorization for improved natural language processing in electronic health records. Scientific reports9, 1 (2019), 9253
2019
-
[48]
Fabián Villena, Felipe Bravo-Marquez, and Jocelyn Dunstan. 2025. NLP modeling recommendations for restricted data availability in clinical settings. BMC Medical Informatics and Decision Making25, 1 (2025), 116
2025
-
[49]
Xintong Wu, Yu Huang, and Qing He. 2025. A large language model improves clinicians’ diagnostic performance in complex critical illness cases. Critical Care29, 1 (2025), 230
2025
-
[50]
Rui Yang, Zhe Zhang, Wenqing Zheng, and Jeffrey Xu Yu. 2023. Fast Continuous Subgraph Matching over Streaming Graphs via Backtracking Reduction.Proceedings of the ACM on Management of Data1, 1 (2023). doi:10.1145/3588695
-
[51]
Junjie Zhang, Ruobing Xie, Yupeng Hou, Xin Zhao, Leyu Lin, and Ji-Rong Wen. 2025. Recommendation as instruction following: A large language model empowered recommendation approach.ACM Transactions on Information Systems43, 5 (2025), 1–37
2025
-
[52]
Qian Zhang, Chen Zhou, Gregory Go, Bo Zeng, Haotian Shi, Zhen Xu, and Yu Jiang. 2024. Imperceptible Content Poisoning in LLM-Powered Applications. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (ASE ’24). Association for Computing Machinery, New York, NY, USA, 242–254. doi:10.1145/3691620.3695001
-
[53]
R. Zhou, H. Huang, G. Zhang, H. Zhou, and J. Bian. 2025. Crash-based safety testing of autonomous vehicles: Insights from generating safety-critical scenarios based on in-depth crash data.IEEE Transactions on Intelligent Transportation Systems(2025)
2025
-
[54]
Ke Zou, Yang Bai, Bo Liu, Yidi Chen, Zhihao Chen, Yang Zhou, Xuedong Yuan, Meng Wang, Xiaojing Shen, Xiaochun Cao, et al. 2025. Uncertainty- aware medical diagnostic phrase identification and grounding.IEEE Transactions on Pattern Analysis and Machine Intelligence(2025). Manuscript submitted to ACM
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.