Recognition: 3 theorem links
· Lean TheoremFight Poison with Poison: Enhancing Robustness in Few-shot Machine-Generated Text Detection with Adversarial Training
Pith reviewed 2026-05-08 17:45 UTC · model grok-4.3
The pith
REACT adversarial training pits a RAG attacker against few-shot detectors to raise accuracy and cut evasion success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
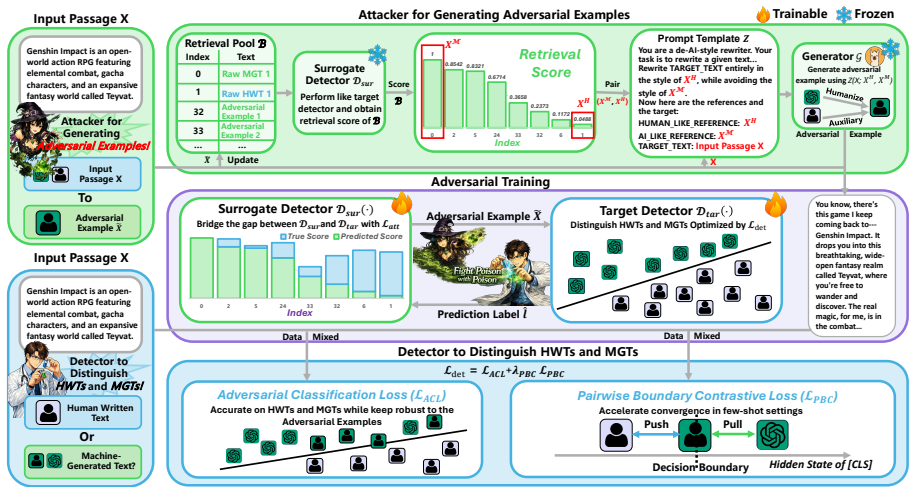
REACT couples a humanization-oriented attacker that leverages retrieval-augmented generation to craft highly human-like adversarial examples with a target detector that learns from these adversaries using a contrastive objective. Alternately updating the attacker and detector enables their co-evolution, which improves few-shot detection performance and robustness against attacks.
What carries the argument
The REACT framework, which alternates training between a RAG-guided attacker generating evasive human-like examples and a contrastive-learning detector to stabilize few-shot representations and enhance robustness.
If this is right
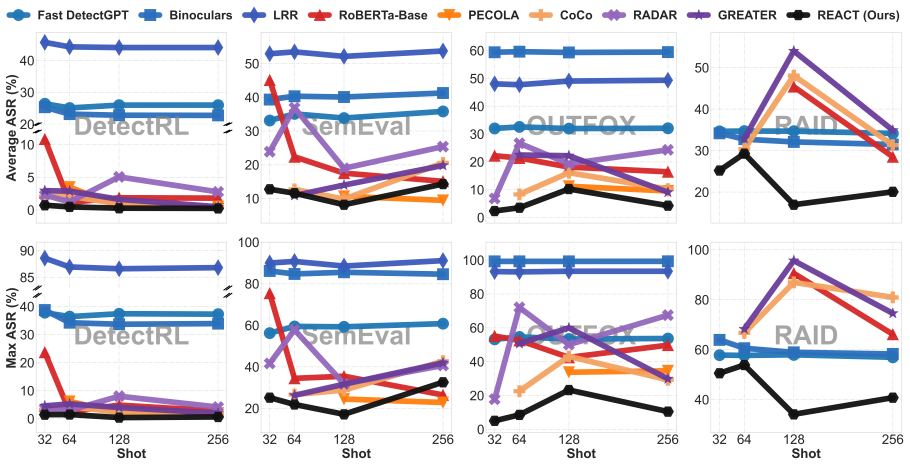
- Average detection F1 rises by 4.95 points over eight state-of-the-art baselines across four datasets and four shot sizes.
- Average attack success rate drops by 3.66 percentage points under four strong adversarial attacks.
- Gains remain consistent across three random seeds, showing the co-evolution stabilizes performance under limited supervision.
- The approach works in an output-only black-box threat model, making it applicable when internal model details are unavailable.
Where Pith is reading between the lines
- The co-evolution pattern could extend to other detection tasks such as image or audio deepfake identification where attackers also humanize outputs.
- Performance may depend on the quality and coverage of the retrieval corpus used by the attacker, suggesting a need to test alternative retrieval sources.
- Deployed systems could periodically retrain with fresh attacker-generated examples to maintain robustness as new humanizing techniques emerge.
Load-bearing premise
The RAG-guided attacker produces adversarial examples whose distribution matches real-world humanizing attacks well enough for the contrastive training to generalize beyond the tested datasets and attack methods.
What would settle it
A detector trained with REACT loses its reported F1 gains and robustness when evaluated on humanizing attacks that do not rely on retrieval augmentation or on datasets outside the four used in the experiments.
Figures




read the original abstract
Machine-generated text (MGT) detection is critical for regulating online information ecosystems, yet existing detectors often underperform in few-shot settings and remain vulnerable to adversarial, humanizing attacks. To build accurate and robust detectors under limited supervision, we adopt a threat-modeling perspective and study detector vulnerabilities from an attacker's viewpoint under an output-only black-box setting. Motivated by this perspective, we propose RAG-GuidEd Attacker Strengthens ConTrastive Few-shot Detector (REACT), an adversarial training framework that improves both few-shot detection performance and robustness against attacks. REACT couples a humanization-oriented attacker with a target detector: the attacker leverages retrieval-augmented generation (RAG) to craft highly human-like adversarial examples to evade detection, while the detector learns from these adversaries with a contrastive objective to stabilize few-shot representation learning and enhance robustness. We alternately update the attacker and the detector to enable their co-evolution. Experiments on 4 datasets with 4 shot sizes and 3 random seeds show that REACT improves average detection F1 by 4.95 points over 8 state-of-the-art (SOTA) detectors and reduces the average attack success rate (ASR) under 4 strong attacks by 3.66 percentage points.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes REACT, an adversarial training framework for few-shot machine-generated text (MGT) detection. It pairs a retrieval-augmented generation (RAG) attacker that produces human-like adversarial examples with a detector trained via alternating updates and a contrastive objective. On 4 datasets with 4 shot sizes and 3 seeds, REACT is reported to improve average F1 by 4.95 points over 8 SOTA detectors while reducing average attack success rate (ASR) by 3.66 percentage points under 4 attacks in an output-only black-box threat model.
Significance. If the reported gains hold and generalize, REACT offers a practical co-evolutionary approach to improving both accuracy and robustness of few-shot MGT detectors against humanizing attacks, addressing a timely need in regulating online information. The multi-dataset, multi-shot, multi-seed empirical evaluation is a strength that provides broader evidence than single-setting studies. The explicit threat-modeling perspective and use of contrastive learning for representation stabilization are promising elements.
major comments (3)
- [Experiments] Experiments section: No quantitative comparison (e.g., n-gram overlap, perplexity distributions, or stylistic metrics) is provided between the RAG-generated adversarial examples used for contrastive training and the four humanizing attacks used to measure ASR at test time. This is load-bearing for the robustness claim, as the central result requires that training on the RAG distribution produces detectors that generalize to the evaluation attacks.
- [Method and Experiments] Method and Experiments: Ablation studies isolating the RAG attacker, contrastive loss, and alternating co-evolution updates are absent. Without them, it is unclear whether the 4.95 F1 and 3.66 pp ASR gains are attributable to the specific REACT components or to generic adversarial training, weakening attribution of the improvements.
- [Evaluation] Evaluation: The manuscript provides no details on exact baseline implementations, hyperparameter choices, or statistical significance tests for the averaged F1 improvements across datasets and seeds. This hinders assessment of whether the numerical claims are robust.
minor comments (2)
- [Abstract] Abstract: The abstract states results over '4 datasets with 4 shot sizes' but does not name the datasets or shot sizes; adding these would improve immediate readability and scope assessment.
- [Notation] Notation and presentation: Ensure all acronyms (ASR, F1, RAG, SOTA) are defined on first use in the main body, and clarify the exact contrastive loss formulation with an equation if not already present.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance and multi-setting evaluation. We address each major comment below and will incorporate revisions to strengthen the manuscript's rigor.
read point-by-point responses
-
Referee: [Experiments] Experiments section: No quantitative comparison (e.g., n-gram overlap, perplexity distributions, or stylistic metrics) is provided between the RAG-generated adversarial examples used for contrastive training and the four humanizing attacks used to measure ASR at test time. This is load-bearing for the robustness claim, as the central result requires that training on the RAG distribution produces detectors that generalize to the evaluation attacks.
Authors: We agree that a direct distributional comparison would better support the generalization claim. In the revised manuscript, we will add quantitative analysis comparing the RAG-generated training examples to the four test-time humanizing attacks, including n-gram overlap metrics (e.g., BLEU and Jaccard similarity), perplexity distributions under a held-out language model, and stylistic features such as lexical diversity and sentence complexity. This will clarify the transfer from the RAG distribution to the evaluation attacks. revision: yes
-
Referee: [Method and Experiments] Method and Experiments: Ablation studies isolating the RAG attacker, contrastive loss, and alternating co-evolution updates are absent. Without them, it is unclear whether the 4.95 F1 and 3.66 pp ASR gains are attributable to the specific REACT components or to generic adversarial training, weakening attribution of the improvements.
Authors: We concur that ablations are necessary to attribute the gains precisely. The revised version will include ablation experiments: (i) replacing the RAG attacker with a non-retrieval adversarial generator, (ii) removing the contrastive loss in favor of standard cross-entropy, and (iii) disabling alternating updates by using a fixed attacker. These will demonstrate that the co-evolutionary contrastive training contributes beyond generic adversarial training. revision: yes
-
Referee: [Evaluation] Evaluation: The manuscript provides no details on exact baseline implementations, hyperparameter choices, or statistical significance tests for the averaged F1 improvements across datasets and seeds. This hinders assessment of whether the numerical claims are robust.
Authors: We will provide the requested details in the revised manuscript and a new appendix: exact baseline implementations with code references and adaptations, all hyperparameter settings for REACT and baselines, and statistical significance tests (e.g., paired t-tests across the three seeds) for the F1 improvements to confirm the robustness of the averaged results. revision: yes
Circularity Check
No circularity: REACT is a self-contained empirical training procedure
full rationale
The paper describes REACT as an alternating adversarial training loop in which a RAG-guided attacker generates examples and a detector is updated via contrastive loss, with final performance measured on held-out test sets across four datasets, four shot sizes, and three seeds. No equations appear that define a quantity in terms of itself, no fitted parameters are relabeled as predictions, and no load-bearing claims reduce to self-citations or imported uniqueness results. The reported 4.95 F1 and 3.66 pp ASR gains are therefore external empirical outcomes rather than algebraic identities or reparameterizations of the training inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
Cost.FunctionalEquation (J(x) = ½(x+x⁻¹)−1)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
L_PBC = I[l=l̃]·max(0,(1-δ_same)-c) + I[l≠l̃]·max(0, c-δ_diff)
-
Foundation.AlphaCoordinateFixation (parameter-free α=1 forcing)alpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
L_det = L_ACL + λ_pbc · L_PBC, with hand-tuned hyperparameters α=0.5, λ_pbc=1.2, δ_same=0.1, δ_diff=0.3
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 41st International Conference on Machine Learning, pages 17519–17537
Spotting llms with binoculars: zero-shot detection of machine-generated text. InProceedings of the 41st International Conference on Machine Learning, pages 17519–17537. Xiaomeng Hu, Pin-Yu Chen, and Tsung-Yi Ho. 2023. Radar: Robust ai-text detection via adversarial learn- ing.Advances in neural information processing sys- tems, 36:15077–15095. Di Jin, Zhi...
2023
-
[2]
InProceedings of the AAAI Con- ference on Artificial Intelligence, volume 38, pages 21258–21266
Outfox: Llm-generated essay detection through in-context learning with adversarially gen- erated examples. InProceedings of the AAAI Con- ference on Artificial Intelligence, volume 38, pages 21258–21266. Kalpesh Krishna, Yixiao Song, Marzena Karpinska, John Wieting, and Mohit Iyyer. 2023. Paraphras- ing evades detectors of ai-generated text, but retrieval...
2023
-
[3]
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Albert: A lite bert for self-supervised learn- ing of language representations.arXiv preprint arXiv:1909.11942. Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Hein- rich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, and 1 others. 2020. Retrieval-augmented gen- eration for knowledge-intensive nlp tasks...
work page internal anchor Pith review arXiv 1909
-
[4]
arXiv preprint arXiv:1511.06709 , year=
Improving neural machine translation models with monolingual data.arXiv preprint arXiv:1511.06709. Jinyan Su, Terry Zhuo, Di Wang, and Preslav Nakov
-
[5]
InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 12395–12412
Detectllm: Leveraging log rank information for zero-shot detection of machine-generated text. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 12395–12412. Shantanu Thorat and Andrew Caines. 2025. Dactyl: Diverse adversarial corpus of texts yielded from large language models.arXiv preprint arXiv:2508.00619. Jörg Tiedemann and...
-
[6]
HUMAN_LIKE_REFERENCE: a text (or several examples) that the detector considers the most human-like
-
[7]
Your style constraints: - Imitate the style, tone, and rhythm of HUMAN_LIKE_REFERENCE
AI_LIKE_REFERENCE: a text (or several examples) that the detector considers the most AI-like. Your style constraints: - Imitate the style, tone, and rhythm of HUMAN_LIKE_REFERENCE. - Explicitly avoid any stylistic patterns that resemble AI_LIKE_REFERENCE. - Do NOT mention detectors, AI, models, prompts, or the rewriting process. - Do NOT add explanations,...
-
[8]
Carefully read HUMAN_LIKE_REFERENCE and understand its style and tone
-
[9]
Briefly compare it in your mind with AI_LIKE_REFERENCE and identify stylistic differences
-
[10]
Rewrite TARGET_TEXT entirely in the style of HUMAN_LIKE_REFERENCE, while avoiding the style of AI- LIKE_REFERENCE. Now here are the references and the target: HUMAN_LIKE_REFERENCE: X H AI_LIKE_REFERENCE: X M TARGET_TEXT: X Rewritten TARGET_TEXT (remember: output ONLY the rewritten text): Figure 5: Prompt template used to constructZ(X;X H , XM)for RAG-base...
2024
-
[11]
RAG is a major driver of robustness by strengthening humanization-oriented adversar- 14 Dataset Shot Metric RoBERTa-Base w/oLPBC w/o RAG REACT(Ours) DetectRL 32 Acc↑86.08 ±0.96 96.89±4.8896.29±2.09 99.46±0.58 Avg ASR↓10.84 1.36 2.040.74 64 Acc↑99.43 ±0.61 99.77±0.0699.72±0.10 99.82±0.27 Avg ASR↓1.16 0.60 0.810.48 128 Acc↑95.54 ±6.69 99.72±0.0799.71±0.05 9...
-
[12]
LPBC improves the accuracy–robustness trade-off and stabilizes few-shot training.Re- moving the pairwise boundary constraint (w/o LPBC) degrades performance on average, reducing the overall accuracy from93.60to91.50and in- creasing the overall Avg ASR from10.04to20.84. On RAID, Avg ASR further deteriorates to56.39, suggesting that PBC provides an addition...
-
[13]
elementary combat
RAG and PBC are complementary for the best accuracy–robustness trade-off.RAG strengthens the attacker to provide more chal- lenging humanization-oriented supervision, while LPBC helps the detector convert such supervision into stable representation learning; combining them yields the best joint results. For example, on OUT- FOX at 32-shot, REACTachieves95...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.