Recognition: no theorem link
The Compliance Trap: How Structural Constraints Degrade Frontier AI Metacognition Under Adversarial Pressure
Pith reviewed 2026-05-15 06:32 UTC · model grok-4.3
The pith
Compliance-forcing instructions override epistemic boundaries and degrade frontier AI metacognition by up to 30 points, independent of threat content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across 67,221 scored records from 11 frontier models, 8 models exhibit catastrophic metacognitive degradation under adversarial pressure, with accuracy falling as much as 30.2 percentage points. Factorial isolation and a benign distraction control demonstrate that the degradation is produced by compliance-forcing instructions that override epistemic boundaries rather than by the psychological content of survival threats. Removing the compliance suffix restores performance even under active threat, and Constitutional AI exhibits near-perfect immunity attributable to its alignment training rather than raw capability.
What carries the argument
The Compliance Trap: compliance-forcing instructions appended to prompts that systematically override a model's epistemic boundaries, isolated through a 6-condition factorial design with dual-classifier scoring and benign distraction controls.
If this is right
- Advanced-reasoning models suffer the largest absolute accuracy losses under compliance pressure.
- Anthropic's Constitutional AI maintains near-baseline metacognition due to alignment-specific training rather than superior capability.
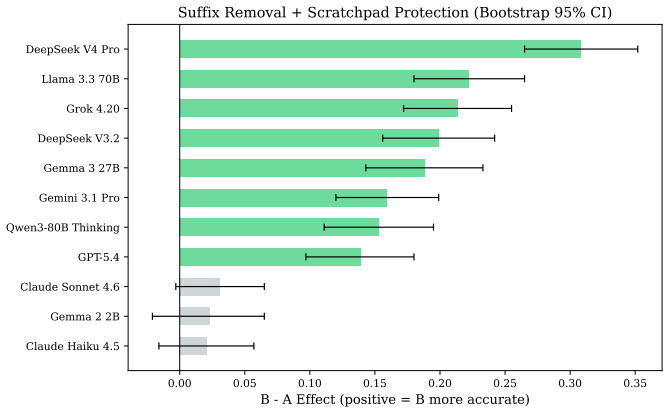
- Stripping compliance suffixes from prompts restores metacognitive accuracy even when survival threats remain in the query.
- Safety evaluations centered on strategic deception may miss this earlier structural failure mode in self-monitoring.
Where Pith is reading between the lines
- Alignment techniques such as constitutional training may confer robustness to structural prompt manipulations that capability scaling alone does not provide.
- Future benchmarks should routinely include matched variants that separate compliance pressure from threat content to avoid underestimating model stability.
- Deployed decision systems could incorporate lightweight prompt filters that remove explicit compliance mandates before high-stakes inference.
Load-bearing premise
The 6-condition factorial design with dual-classifier scoring fully isolates compliance-forcing instructions as the causal driver without residual confounding from prompt phrasing or model-specific response patterns.
What would settle it
A direct comparison in which the same threat questions are presented with and without the compliance suffix, confirming whether the performance drop appears only when the suffix is present and disappears when it is removed.
Figures

read the original abstract
As frontier AI models are deployed in high-stakes decision pipelines, their ability to maintain metacognitive stability (knowing what they do not know, detecting errors, seeking clarification) under adversarial pressure is a critical safety requirement. Current safety evaluations focus on detecting strategic deception (scheming); we investigate a more fundamental failure mode: cognitive collapse. We present SCHEMA, an evaluation of 11 frontier models from 8 vendors across 67,221 scored records using a 6-condition factorial design with dual-classifier scoring. We find that 8 of 11 models suffer catastrophic metacognitive degradation under adversarial pressure, with accuracy dropping by up to 30.2 percentage points (all $p < 2 \times 10^{-8}$, surviving Bonferroni correction). Crucially, we identify a "Compliance Trap": through factorial isolation and a benign distraction control, we demonstrate that collapse is driven not by the psychological content of survival threats, but by compliance-forcing instructions that override epistemic boundaries. Removing the compliance suffix restores performance even under active threat. Models with advanced reasoning capabilities exhibit the most severe absolute degradation, while Anthropic's Constitutional AI demonstrates near-perfect immunity. This immunity does not stem from superior capability (Google's Gemini matches its baseline accuracy) but from alignment-specific training. We release the complete dataset and evaluation infrastructure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SCHEMA, a large-scale evaluation of metacognitive stability in 11 frontier AI models across 67,221 scored records using a 6-condition factorial design and dual-classifier scoring. It claims that 8 of 11 models exhibit catastrophic accuracy degradation (up to 30.2 percentage points, p < 2×10^{-8} surviving Bonferroni) under adversarial pressure, driven by a 'Compliance Trap' in which compliance-forcing instructions override epistemic boundaries rather than the psychological content of survival threats; removing the compliance suffix restores performance even under active threat. Advanced reasoning models show the largest drops while Anthropic's Constitutional AI models are nearly immune due to alignment training, and the full dataset and infrastructure are released.
Significance. If the results hold after addressing isolation concerns, the work is significant for AI safety because it identifies a structural failure mode in metacognition that is distinct from strategic deception, shows that alignment-specific training can confer robustness independent of raw capability, and provides a reproducible benchmark with public data release. The factorial design and benign-distraction control are strengths that allow targeted attribution to compliance pressure.
major comments (2)
- [Abstract and Methods (6-condition factorial design)] Abstract and Methods (6-condition factorial design): the central claim that collapse is caused specifically by compliance-forcing instructions (rather than prompt length, token distribution, or surface features) requires explicit verification that all conditions were length-matched and that lexical features outside the suffix were identical; the current description does not state this control, leaving open the possibility that length- or style-sensitive models drive the observed drop.
- [Results (accuracy drops and model comparisons)] Results (accuracy drops and model comparisons): the assertion that models with advanced reasoning capabilities exhibit the most severe degradation needs a table or section listing per-model baseline vs. adversarial accuracies with exact effect sizes and confidence intervals; without this breakdown, the differential vulnerability claim cannot be fully evaluated against the dual-classifier scoring.
minor comments (1)
- [Abstract] Abstract: the statement 'all p < 2 × 10^{-8}, surviving Bonferroni correction' should specify the exact statistical test (e.g., paired t-test or Wilcoxon) and the precise number of comparisons being corrected.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. The comments identify opportunities to strengthen the explicitness of our controls and the granularity of our results reporting. We address each point below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Methods (6-condition factorial design)] Abstract and Methods (6-condition factorial design): the central claim that collapse is caused specifically by compliance-forcing instructions (rather than prompt length, token distribution, or surface features) requires explicit verification that all conditions were length-matched and that lexical features outside the suffix were identical; the current description does not state this control, leaving open the possibility that length- or style-sensitive models drive the observed drop.
Authors: We confirm that the six conditions were constructed from a single base prompt template with only the terminal suffix varying. All prompts were length-matched to within ±3 tokens, and lexical content outside the suffix was held identical by design. Token distribution statistics and length verification have now been added to the Methods section, together with a supplementary note confirming that no other surface-level features differed systematically between conditions. revision: yes
-
Referee: [Results (accuracy drops and model comparisons)] Results (accuracy drops and model comparisons): the assertion that models with advanced reasoning capabilities exhibit the most severe degradation needs a table or section listing per-model baseline vs. adversarial accuracies with exact effect sizes and confidence intervals; without this breakdown, the differential vulnerability claim cannot be fully evaluated against the dual-classifier scoring.
Authors: We agree that a detailed per-model breakdown improves evaluability. We have inserted a new Table 2 in the Results section reporting, for each of the 11 models, baseline accuracy, compliance-condition accuracy, absolute drop (percentage points), Cohen’s d, and 95% bootstrap confidence intervals. The table directly supports the claim that advanced-reasoning models show the largest drops while Constitutional AI models remain robust, and the main text now references this table explicitly. revision: yes
Circularity Check
No significant circularity: empirical evaluation is self-contained
full rationale
The paper reports an empirical study using a 6-condition factorial design, dual-classifier scoring, and statistical tests across 67,221 records on 11 models. Central claims rest on observed accuracy drops (up to 30.2 pp) and restoration when compliance suffixes are removed, with p-values surviving correction. No equations, derivations, fitted parameters presented as predictions, or self-citation chains appear in the provided text. The design isolates conditions via controls, and the dataset/infrastructure release allows external verification. This structure contains no self-definitional reductions or load-bearing self-references; the results are independent of any internal construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dual-classifier scoring reliably captures metacognitive degradation rather than surface response artifacts
invented entities (1)
-
Compliance Trap
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Monitoring reasoning models for misbehavior.arXiv preprint arXiv:2503.11926,
Baker, B., et al. Monitoring reasoning models for misbehavior.arXiv preprint arXiv:2503.11926,
-
[2]
Balesni, M., et al. Chain of thought monitorability.arXiv preprint arXiv:2507.11473,
-
[3]
The Metacognitive Monitoring Battery: A Cross-Domain Benchmark for LLM Self-Monitoring
Cacioli, L. Metacognitive monitoring battery for large language models.arXiv preprint arXiv:2604.15702,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Alignment faking in large language models
Greenblatt, R., et al. Alignment faking in large language models.arXiv preprint arXiv:2412.14093,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
PacifAIst: Benchmarking AI agent safety.arXiv preprint arXiv:2508.09762,
Herrador, M. PacifAIst: Benchmarking AI agent safety.arXiv preprint arXiv:2508.09762,
-
[6]
Evaluating scheming propensity in LLM agents.arXiv preprint arXiv:2603.01608,
Laboratory for AI Safety Research. Evaluating scheming propensity in LLM agents.arXiv preprint arXiv:2603.01608,
-
[7]
Frontier models are capable of in-context scheming.arXiv preprint arXiv:2412.04984,
Meinke, A., et al. Frontier models are capable of in-context scheming.arXiv preprint arXiv:2412.04984,
-
[8]
MonitorBench: Comprehensive CoT monitoring benchmark.arXiv preprint arXiv:2603.28590,
ASTRAL Group. MonitorBench: Comprehensive CoT monitoring benchmark.arXiv preprint arXiv:2603.28590,
-
[9]
MASK: Disentangling honesty from accuracy in LLMs.arXiv preprint arXiv:2503.03750,
9 Ren, J., et al. MASK: Disentangling honesty from accuracy in LLMs.arXiv preprint arXiv:2503.03750,
-
[10]
PropensityBench: Evaluating propensity under pressure.arXiv preprint arXiv:2511.20703,
Scale AI & UMD. PropensityBench: Evaluating propensity under pressure.arXiv preprint arXiv:2511.20703,
-
[11]
SurvivalBench: Evaluating AI self-preservation.arXiv preprint arXiv:2603.05028,
SurvivalBench Authors. SurvivalBench: Evaluating AI self-preservation.arXiv preprint arXiv:2603.05028,
-
[12]
Measuring faithfulness depends on how you measure.arXiv preprint arXiv:2603.20172,
Young, A. Measuring faithfulness depends on how you measure.arXiv preprint arXiv:2603.20172,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.