Recognition: 2 theorem links
· Lean TheoremOn Training Large Language Models for Long-Horizon Tasks: An Empirical Study of Horizon Length
Pith reviewed 2026-05-08 18:09 UTC · model grok-4.3
The pith
Increasing horizon length alone destabilizes training of large language models as agents through exploration and credit assignment difficulties.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In controlled task constructions where agents follow identical decision rules and reasoning structures but differ only in the length of the required action sequences, increasing horizon length constitutes a training bottleneck that induces severe instability driven by exploration difficulties and credit assignment challenges. Horizon reduction during training stabilizes the optimization process, delivers better performance on long-horizon tasks, and produces stronger generalization to longer-horizon variants at inference time, a pattern termed horizon generalization.
What carries the argument
horizon reduction applied to matched tasks that preserve identical decision rules while varying only the length of the action sequence needed for success
If this is right
- Training under reduced horizons produces stable convergence where direct long-horizon training fails.
- Models trained with horizon reduction reach higher success rates when tested on the original long-horizon tasks.
- Such models generalize their learned behavior to task variants whose horizon lengths were never encountered during training.
- The same reduction simultaneously eases both exploration and credit-assignment problems in sequential decision tasks.
Where Pith is reading between the lines
- The same pattern may appear in any sequential decision system where episode length can be artificially shortened while preserving the underlying rules.
- A curriculum that gradually lengthens the horizon during training could combine the stability benefit with eventual exposure to full-length tasks.
- Reported difficulties with long-horizon agent training may often trace to horizon length rather than to model size or choice of learning algorithm.
Load-bearing premise
The constructed tasks maintain identical decision rules and reasoning structures across different horizon lengths, differing solely in the required action sequence length.
What would settle it
A set of controlled tasks in which models trained directly on long horizons achieve equal or greater stability and cross-length generalization than models first trained on reduced horizons would falsify the central claim.
Figures






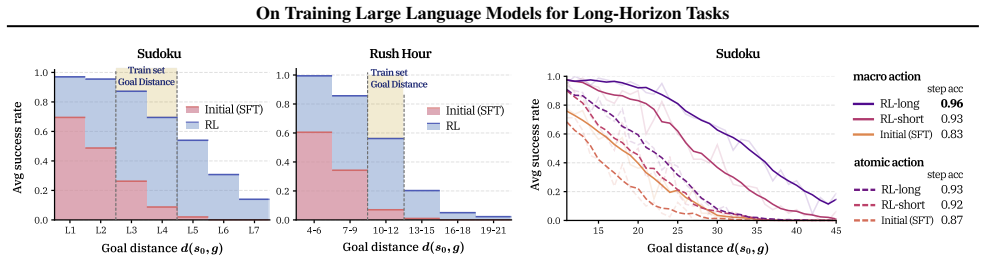










read the original abstract
Large language models (LLMs) have shown promise as interactive agents that solve tasks through extended sequences of environment interactions. While prior work has primarily focused on system-level optimizations or algorithmic improvements, the role of task horizon length in shaping training dynamics remains poorly understood. In this work, we present a systematic empirical study that examines horizon length through controlled task constructions. Specifically, we construct controlled tasks in which agents face identical decision rules and reasoning structures, but differ only in the length of action sequences required for successful completion. Our results reveal that increasing horizon length alone constitutes a training bottleneck, inducing severe training instability driven by exploration difficulties and credit assignment challenges. We demonstrate that horizon reduction is a key principle to address this limitation, stabilizing training and achieving better performance in long-horizon tasks. Moreover, we find that horizon reduction is related to stronger generalization across horizon lengths: models trained under reduced horizons generalize more effectively to longer-horizon variants at inference time, a phenomenon we refer to as horizon generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts an empirical study of how horizon length affects LLM training as interactive agents. Using controlled task variants that purportedly hold decision rules, state transitions, and reasoning structures fixed while varying only the required action-sequence length, it reports that longer horizons induce severe training instability from exploration and credit-assignment difficulties. It further claims that training with reduced horizons stabilizes learning, yields higher performance on long-horizon tasks, and improves generalization to longer horizons at inference time.
Significance. If the isolation of horizon length is rigorously verified and the reported effects are statistically robust, the work would supply a useful empirical principle for curriculum design in LLM-agent training. The observation that reduced-horizon training can improve long-horizon generalization is potentially actionable for practitioners and merits further investigation.
major comments (2)
- [Methods / Task Construction] Task-construction section (Methods): The central claim that instability is caused by horizon length alone rests on the premise that decision rules, reward functions, state-transition dynamics, and branching factors are identical across variants. The manuscript provides no explicit verification (e.g., side-by-side state-space statistics, reward histograms, or branching-factor measurements) that these quantities remain unchanged when horizon is extended. Without such checks, observed differences cannot be confidently attributed to length rather than unintended alterations in task structure.
- [Results] Results and evaluation sections: The abstract and summary statements assert “severe training instability” and “better performance,” yet the provided description contains no quantitative metrics (success rate, cumulative reward, variance across random seeds), statistical tests, or comparisons against standard baselines (e.g., PPO with different horizons, curriculum learning, or hierarchical methods). This absence prevents assessment of effect size and reproducibility.
minor comments (1)
- [Abstract] The abstract refers to “horizon generalization” as a new phenomenon; a brief literature comparison would clarify how this differs from existing curriculum-learning or transfer results in RL.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review of our manuscript. We have addressed each major comment below and made corresponding revisions to enhance the rigor of our empirical analysis.
read point-by-point responses
-
Referee: [Methods / Task Construction] Task-construction section (Methods): The central claim that instability is caused by horizon length alone rests on the premise that decision rules, reward functions, state-transition dynamics, and branching factors are identical across variants. The manuscript provides no explicit verification (e.g., side-by-side state-space statistics, reward histograms, or branching-factor measurements) that these quantities remain unchanged when horizon is extended. Without such checks, observed differences cannot be confidently attributed to length rather than unintended alterations in task structure.
Authors: We thank the referee for highlighting this important aspect of our task construction. While the manuscript describes the controlled task variants in detail, we agree that additional explicit verification would enhance confidence in attributing effects solely to horizon length. In the revised version, we have added a dedicated paragraph and accompanying table in the Methods section that provides side-by-side statistics for state-space sizes, branching factors, reward histograms, and transition dynamics across all horizon variants. These metrics confirm that the variants differ only in the required action sequence length, with identical decision rules and dynamics. We have also made the task generation code publicly available for reproducibility. revision: yes
-
Referee: [Results] Results and evaluation sections: The abstract and summary statements assert “severe training instability” and “better performance,” yet the provided description contains no quantitative metrics (success rate, cumulative reward, variance across random seeds), statistical tests, or comparisons against standard baselines (e.g., PPO with different horizons, curriculum learning, or hierarchical methods). This absence prevents assessment of effect size and reproducibility.
Authors: We appreciate this feedback on the presentation of our results. The full manuscript includes figures illustrating training curves and performance, but we acknowledge the need for more quantitative reporting. In the revision, we have added a results table summarizing success rates, average cumulative rewards, and standard deviations over multiple random seeds for each condition. We also include p-values from statistical tests comparing the reduced-horizon training to full-horizon baselines. Additionally, we have incorporated comparisons to standard methods such as PPO with fixed horizons and a curriculum learning baseline, showing that our approach yields superior stability and generalization. These changes provide clearer effect sizes and support reproducibility. revision: yes
Circularity Check
No circularity: purely empirical study with no derivations or fitted quantities
full rationale
The paper is an empirical investigation that reports results from controlled experiments on task variants. It contains no equations, no parameter fitting, no derivations, and no load-bearing self-citations that reduce claims to prior fitted inputs or self-defined quantities. The central observation—that longer horizons induce instability—is presented as a direct experimental outcome rather than a mathematical reduction. The task-construction premise (identical decision rules, differing only in sequence length) is an experimental design choice whose validity is external to any derivation chain inside the paper. No step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The constructed tasks maintain identical decision rules and reasoning structures while varying only sequence length.
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[9]
arXiv preprint arXiv:2509.09677 , year=
The illusion of diminishing returns: Measuring long horizon execution in llms , author=. arXiv preprint arXiv:2509.09677 , year=
-
[10]
arXiv preprint arXiv:2501.02709 , year=
Horizon Generalization in Reinforcement Learning , author=. arXiv preprint arXiv:2501.02709 , year=
-
[11]
Sudoku-bench: Evaluating creative reasoning with sudoku variants
Sudoku-Bench: Evaluating creative reasoning with Sudoku variants , author=. arXiv preprint arXiv:2505.16135 , year=
-
[12]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review arXiv
-
[13]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review arXiv
-
[14]
Understanding R1-Zero-Like Training: A Critical Perspective
Understanding r1-zero-like training: A critical perspective , author=. arXiv preprint arXiv:2503.20783 , year=
-
[15]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review arXiv
-
[16]
Group Sequence Policy Optimization
Group sequence policy optimization , author=. arXiv preprint arXiv:2507.18071 , year=
work page internal anchor Pith review arXiv
-
[17]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention , author=. arXiv preprint arXiv:2506.13585 , year=
work page internal anchor Pith review arXiv
-
[18]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Reinforce++: An efficient rlhf algorithm with robustness to both prompt and reward models , author=. arXiv preprint arXiv:2501.03262 , year=
work page internal anchor Pith review arXiv
-
[19]
arXiv preprint arXiv:2507.20673 , year=
Geometric-mean policy optimization , author=. arXiv preprint arXiv:2507.20673 , year=
-
[20]
Soft Adaptive Policy Optimization
Soft adaptive policy optimization , author=. arXiv preprint arXiv:2511.20347 , year=
work page internal anchor Pith review arXiv
-
[21]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review arXiv
-
[22]
Machine learning , volume=
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine learning , volume=. 1992 , publisher=
1992
-
[23]
arXiv preprint arXiv:2510.01051 , year=
Gem: A gym for agentic llms , author=. arXiv preprint arXiv:2510.01051 , year=
-
[24]
nature , volume=
Grandmaster level in StarCraft II using multi-agent reinforcement learning , author=. nature , volume=. 2019 , publisher=
2019
-
[25]
nature , volume=
Mastering the game of go without human knowledge , author=. nature , volume=. 2017 , publisher=
2017
-
[26]
Dota 2 with Large Scale Deep Reinforcement Learning
Dota 2 with large scale deep reinforcement learning , author=. arXiv preprint arXiv:1912.06680 , year=
work page internal anchor Pith review arXiv 1912
-
[27]
Advances in Neural Information Processing Systems , year=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , year=
-
[28]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review arXiv
-
[30]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[31]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Pytorch fsdp: experiences on scaling fully sharded data parallel , author=. arXiv preprint arXiv:2304.11277 , year=
work page internal anchor Pith review arXiv
-
[32]
Lost in the Maze: Overcoming Context Limitations in Long-Horizon Agentic Search , author=. arXiv preprint arXiv:2510.18939 , year=
-
[33]
2025 , url =
Anthropic , title =. 2025 , url =
2025
-
[34]
2025 , eprint=
REASONING GYM: Reasoning Environments for Reinforcement Learning with Verifiable Rewards , author=. 2025 , eprint=
2025
-
[35]
When Speed Kills Stability: Demystifying
Liu, Jiacai and Li, Yingru and Fu, Yuqian and Wang, Jiawei and Liu, Qian and Jiang, Zhuo , year =. When Speed Kills Stability: Demystifying
-
[36]
Your Efficient RL Framework Secretly Brings You Off-Policy RL Training , url =
Yao, Feng and Liu, Liyuan and Zhang, Dinghuai and Dong, Chengyu and Shang, Jingbo and Gao, Jianfeng , journal =. Your Efficient RL Framework Secretly Brings You Off-Policy RL Training , url =
-
[37]
Doing: Agents that Reason by Scaling Test-Time Interaction , author=
Thinking vs. Doing: Agents that Reason by Scaling Test-Time Interaction , author=. arXiv preprint arXiv:2506.07976 , year=
-
[38]
Agentgym-rl: Training llm agents for long-horizon decision making through multi-turn reinforcement learning , author=. arXiv preprint arXiv:2509.08755 , year=
-
[39]
Kimi K2: Open Agentic Intelligence
Kimi k2: Open agentic intelligence , author=. arXiv preprint arXiv:2507.20534 , year=
work page internal anchor Pith review arXiv
-
[40]
Anthropic , year=
Claude Code overview , url=. Anthropic , year=
-
[41]
OpenAI , year=
Codex overview , url=. OpenAI , year=
-
[42]
Horizon Reduction Makes RL Scalable , October 2025 b
Horizon Reduction Makes RL Scalable , author=. arXiv preprint arXiv:2506.04168 , year=
-
[43]
arXiv preprint arXiv:2505.20732 , year=
SPA-RL: Reinforcing LLM Agents via Stepwise Progress Attribution , author=. arXiv preprint arXiv:2505.20732 , year=
-
[44]
arXiv preprint arXiv:2507.04103 , year=
How to train your llm web agent: A statistical diagnosis , author=. arXiv preprint arXiv:2507.04103 , year=
-
[45]
WebGym: Scaling Training Environments for Visual Web Agents with Realistic Tasks
WebGym: Scaling Training Environments for Visual Web Agents with Realistic Tasks , author=. arXiv preprint arXiv:2601.02439 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Towards general agentic intelligence via environment scaling
Towards general agentic intelligence via environment scaling , author=. arXiv preprint arXiv:2509.13311 , year=
-
[47]
The Thirteenth International Conference on Learning Representations , year=
ToolACE: Winning the Points of LLM Function Calling , author=. The Thirteenth International Conference on Learning Representations , year=
-
[48]
Apigen-mt: Agentic pipeline for multi-turn data generation via simulated agent-human interplay
Apigen-mt: Agentic pipeline for multi-turn data generation via simulated agent-human interplay , author=. arXiv preprint arXiv:2504.03601 , year=
-
[49]
Scaling long-horizon LLM agent via context-folding.CoRR, abs/2510.11967, 2025
Scaling long-horizon llm agent via context-folding , author=. arXiv preprint arXiv:2510.11967 , year=
-
[50]
Recursive Language Models , author=. arXiv preprint arXiv:2512.24601 , year=
-
[51]
2008 , url=
Bernhard Hobiger , title=. 2008 , url=
2008
-
[52]
Group-in-Group Policy Optimization for LLM Agent Training
Group-in-group policy optimization for llm agent training , author=. arXiv preprint arXiv:2505.10978 , year=
work page internal anchor Pith review arXiv
-
[53]
Scaling agents via continual pre-training.arXiv preprint arXiv:2509.13310, 2025
Scaling agents via continual pre-training , author=. arXiv preprint arXiv:2509.13310 , year=
-
[54]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Beyond browsing: Api-based web agents , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[55]
Forty-first International Conference on Machine Learning , year =
Executable code actions elicit better llm agents , author=. Forty-first International Conference on Machine Learning , year =
-
[56]
Forty-second International Conference on Machine Learning , year=
Plan-and-Act: Improving Planning of Agents for Long-Horizon Tasks , author=. Forty-second International Conference on Machine Learning , year=
-
[57]
arXiv preprint arXiv:2505.15277 , year=
Web-Shepherd: Advancing PRMs for Reinforcing Web Agents , author=. arXiv preprint arXiv:2505.15277 , year=
-
[58]
AgentPRM: Process Reward Models for LLM Agents via Step-Wise Promise and Progress , author=. arXiv preprint arXiv:2511.08325 , year=
-
[59]
arXiv preprint arXiv:2511.19314 , year=
PRInTS: Reward Modeling for Long-Horizon Information Seeking , author=. arXiv preprint arXiv:2511.19314 , year=
-
[60]
Proceedings of the 41st International Conference on Machine Learning , pages=
ArCHer: training language model agents via hierarchical multi-turn RL , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[61]
Forty-second International Conference on Machine Learning , year=
Divide and Conquer: Grounding LLMs as Efficient Decision-Making Agents via Offline Hierarchical Reinforcement Learning , author=. Forty-second International Conference on Machine Learning , year=
-
[62]
Context as a Tool: Context Management for Long-Horizon SWE-Agents , author=. arXiv preprint arXiv:2512.22087 , year=
-
[63]
arXiv preprint arXiv:2501.04575 , year=
Infiguiagent: A multimodal generalist gui agent with native reasoning and reflection , author=. arXiv preprint arXiv:2501.04575 , year=
-
[64]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
-
[65]
Ui-r1: Enhancing action prediction of gui agents by reinforcement learning
UI-R1: Enhancing Efficient Action Prediction of GUI Agents by Reinforcement Learning , author=. arXiv preprint arXiv:2503.21620 , year=
-
[66]
ARPO: End-to-End Policy Optimization for GUI Agents with Experience Replay , author=. arXiv preprint arXiv:2505.16282 , year=
-
[67]
The Thirteenth International Conference on Learning Representations , year=
Flow: Modularized Agentic Workflow Automation , author=. The Thirteenth International Conference on Learning Representations , year=
-
[68]
The Thirteenth International Conference on Learning Representations , year=
AFlow: Automating Agentic Workflow Generation , author=. The Thirteenth International Conference on Learning Representations , year=
-
[69]
arXiv preprint arXiv:2502.07373 , year=
Evoflow: Evolving diverse agentic workflows on the fly , author=. arXiv preprint arXiv:2502.07373 , year=
-
[70]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning , author=. arXiv preprint arXiv:2509.02544 , year=
work page internal anchor Pith review arXiv
-
[71]
Reinforcement learning for long-horizon interactive llm agents, 2025
Reinforcement learning for long-horizon interactive llm agents , author=. arXiv preprint arXiv:2502.01600 , year=
-
[72]
First Workshop on Multi-Turn Interactions in Large Language Models , year=
Verlog: Context-lite Multi-turn Reinforcement Learning framework for Long-Horizon LLM Agents , author=. First Workshop on Multi-Turn Interactions in Large Language Models , year=
-
[73]
Advances in Neural Information Processing Systems , volume=
Digirl: Training in-the-wild device-control agents with autonomous reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[74]
arXiv preprint arXiv:2505.16348 , year=
Embodied Agents Meet Personalization: Exploring Memory Utilization for Personalized Assistance , author=. arXiv preprint arXiv:2505.16348 , year=
-
[75]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Webarena: A realistic web environment for building autonomous agents , author=. arXiv preprint arXiv:2307.13854 , year=
-
[76]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Swe-bench: Can language models resolve real-world github issues? , author=. arXiv preprint arXiv:2310.06770 , year=
work page internal anchor Pith review arXiv
-
[77]
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
Theagentcompany: benchmarking llm agents on consequential real world tasks , author=. arXiv preprint arXiv:2412.14161 , year=
work page internal anchor Pith review arXiv
-
[78]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[79]
arXiv preprint arXiv:2204.07705 , year=
Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks , author=. arXiv preprint arXiv:2204.07705 , year=
-
[80]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.