Recognition: 3 theorem links
· Lean TheoremBeyond State Machines: Executing Network Procedures with Agentic Tool-Calling Sequences
Pith reviewed 2026-05-08 17:34 UTC · model grok-4.3
The pith
Encapsulating network procedures in a single tool that orchestrates steps reduces latency for LLM agents by avoiding repeated reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
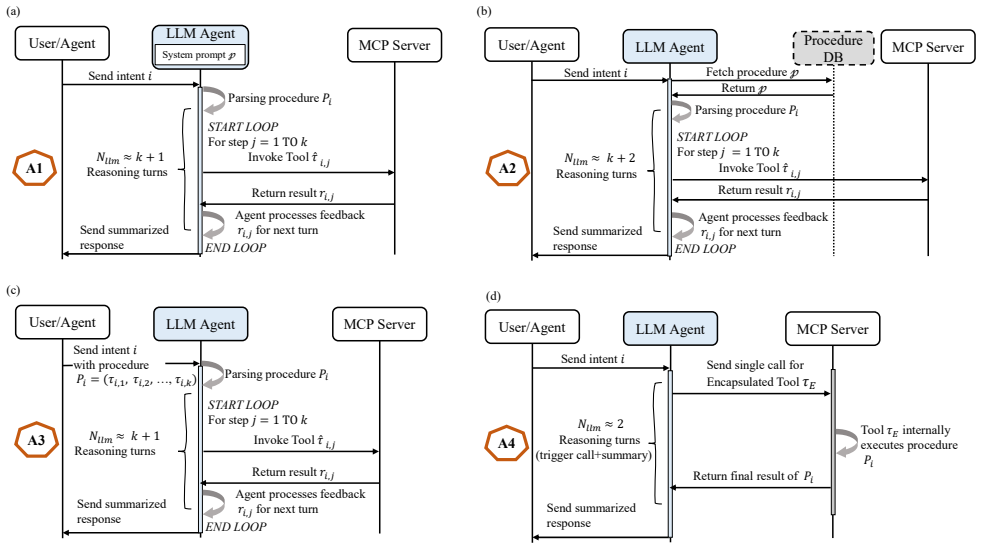
Approaches relying on iterative agent-side reasoning incur higher latency and are more prone to execution errors, while approaches where the procedure is encapsulated within a single tool, which internally orchestrates the required steps by invoking other tools, reduce latency by limiting repeated reasoning. Stress-test results show that the model with advanced tool-calling capability maintains reliable execution over longer procedures than the other evaluated models; however, all models exhibit reliability degradation as procedure length increases.
What carries the argument
The four approaches to distributing procedure execution between LLM agent reasoning and tool-internal orchestration in network procedures.
If this is right
- Single-tool encapsulation of procedures leads to lower latency compared to agent-driven step-by-step execution.
- Iterative agent reasoning increases the likelihood of execution errors in network procedures.
- LLM agents show a clear degradation in reliability as the length of the procedural sequence increases.
- Models with advanced tool-calling abilities can handle longer sequences reliably before failure occurs.
- The introduced procedure-specific error taxonomy provides a structured way to analyze deviations in tool-calling workflows.
Where Pith is reading between the lines
- Network operators could prioritize building complex procedures as encapsulated tools to enable faster and more reliable AI-driven automation.
- The limits observed suggest that very long procedures may require hybrid agent-tool designs or human oversight in practice.
- Similar tool-calling strategies could be tested in other sequential domains such as cloud orchestration or IoT coordination.
Load-bearing premise
The latency and correctness advantages of single-tool encapsulation observed in the UE IP allocation procedure will generalize across other network procedures and tool implementations.
What would settle it
Conducting equivalent latency and error measurements on a different procedure such as radio resource control connection establishment and verifying whether the single-tool approach consistently shows reduced latency and improved correctness.
Figures



read the original abstract
Agentic AI will be an essential enabling technology for designing future mobile communication systems, which could provide flexible and customized services, automate complex network operations, and drive autonomous decision-making across the network. This work studies how Large Language Model (LLM)-based network AI agents can be utilized to execute network procedures expressed as sequences of tool invocations. We investigate four approaches, which differ in how the agent obtains the procedure and in how execution is distributed between the agent and the underlying tools. We evaluated the latency and execution correctness across these approaches using a User Equipment (UE) IP allocation procedure as a case study. Furthermore, we conduct a stress test to examine how many sequential procedural steps an LLM agent can reliably execute before failure. Our results show that approaches relying on iterative agent-side reasoning incur higher latency and are more prone to execution errors, while approaches where the procedure is encapsulated within a single tool, which internally orchestrates the required steps by invoking other tools, reduce latency by limiting repeated reasoning. The stress-test results further show that the model with advanced tool-calling capability maintains reliable execution over longer procedures than the other evaluated models; however, all models exhibit reliability degradation as procedure length increases, revealing clear execution limits in multi-step tool-based workflows. To systematically analyze failures in procedure execution, we introduce a procedure-specific error taxonomy that categorizes deviations in multi-step procedural execution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates four approaches for LLM-based agents to execute network procedures as tool-calling sequences, differing in how the procedure is obtained and how reasoning/execution is distributed between agent and tools. Using a UE IP allocation procedure as a case study, it compares latency and execution correctness, concluding that single-tool encapsulation (where the tool internally orchestrates steps) reduces latency by limiting repeated agent reasoning and is less error-prone than iterative approaches. A stress test examines reliable execution length, showing degradation with increasing steps across models, and the authors introduce a procedure-specific error taxonomy for analyzing failures in multi-step workflows.
Significance. If the empirical patterns hold, this work provides timely guidance on practical trade-offs in deploying agentic AI for automating network operations in future mobile systems, highlighting both the benefits of tool encapsulation and the inherent limits of current LLMs in long sequential tool calls. The stress-test results and error taxonomy are constructive contributions that could inform system design and failure analysis in this domain. Credit is given for the empirical comparison of agent behaviors and the introduction of a targeted error taxonomy.
major comments (2)
- [Evaluation / Case Study] Evaluation section / UE IP allocation case study: The central claims that encapsulated single-tool approaches reduce latency and errors relative to iterative agent reasoning rest exclusively on results from one linear procedure (UE IP allocation). Without additional evaluations on procedures involving branching logic, concurrent steps, or different state/error surfaces, it is unclear whether the observed differences are inherent to the reasoning distribution or specific to this procedure's structure.
- [Results / Abstract] Results and Abstract: Performance differences in latency and correctness are asserted without any quantitative values, error bars, baseline comparisons, or details on how correctness was measured or failures classified, which undermines assessment of the magnitude and reliability of the reported advantages.
minor comments (2)
- [Abstract] The abstract states key findings but omits any numerical results or specifics, which reduces its utility as a standalone summary.
- [Introduction / Approach] Clarify the precise definitions and distinctions among the four approaches with a table or diagram early in the manuscript to improve readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment point by point below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Evaluation / Case Study] Evaluation section / UE IP allocation case study: The central claims that encapsulated single-tool approaches reduce latency and errors relative to iterative agent reasoning rest exclusively on results from one linear procedure (UE IP allocation). Without additional evaluations on procedures involving branching logic, concurrent steps, or different state/error surfaces, it is unclear whether the observed differences are inherent to the reasoning distribution or specific to this procedure's structure.
Authors: We acknowledge that the evaluation relies on a single linear procedure. The UE IP allocation was chosen because it is a standard, state-dependent network procedure that involves a clear sequence of tool invocations, enabling isolation of the effects of reasoning distribution versus tool encapsulation. We agree that this limits the strength of claims about inherent advantages across all procedure types. In the revised manuscript we will add an explicit limitations paragraph in the evaluation section and a forward-looking statement in the conclusion that discusses how the observed patterns may or may not extend to branching or concurrent workflows, and we will outline planned follow-up experiments on such procedures. revision: partial
-
Referee: [Results / Abstract] Results and Abstract: Performance differences in latency and correctness are asserted without any quantitative values, error bars, baseline comparisons, or details on how correctness was measured or failures classified, which undermines assessment of the magnitude and reliability of the reported advantages.
Authors: We agree that the abstract and high-level result statements would benefit from greater specificity. The full paper already contains quantitative latency and correctness data in figures and tables, along with the procedure-specific error taxonomy used to classify failures. In the revised version we will (1) revise the abstract to report concrete latency reductions and correctness percentages, (2) add a short methods paragraph in the results section that details how correctness was measured and how the taxonomy was applied, and (3) ensure error bars or variance information appear in the relevant figures or captions. revision: yes
Circularity Check
No circularity: empirical evaluation without derivation or self-referential inputs
full rationale
The paper conducts an empirical comparison of four agent approaches for network procedure execution, reporting latency and correctness results from a UE IP allocation case study plus a stress test on sequential steps. No equations, fitted parameters, or predictions appear in the provided text. No self-citations are invoked to justify uniqueness theorems or ansatzes that would reduce the central claims to prior author work by construction. The observed differences are presented as direct experimental outcomes rather than derived quantities, satisfying the self-contained criterion with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost (J = ½(x+x⁻¹)−1)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
C(i) = Σ_{j=1}^{N_llm} L_llm_j + Σ_{j=1}^{k̂} L_tool_j
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
2026 , eprint=
Toward Autonomous O-RAN: A Multi-Scale Agentic AI Framework for Real-Time Network Control and Management , author=. 2026 , eprint=
2026
-
[2]
2026 , eprint=
An Agentic AI Control Plane for 6G Network Slice Orchestration, Monitoring, and Trading , author=. 2026 , eprint=
2026
-
[3]
2026 , eprint=
Toward E2E Intelligence in 6G Networks: An AI Agent-Based RAN-CN Converged Intelligence Framework , author=. 2026 , eprint=
2026
-
[4]
2026 , eprint=
Agentic AI Empowered Intent-Based Networking for 6G , author=. 2026 , eprint=
2026
-
[5]
2025 , eprint=
SANet: A Semantic-aware Agentic AI Networking Framework for Cross-layer Optimization in 6G , author=. 2025 , eprint=
2025
-
[6]
2026 , eprint=
ComAgent: Multi-LLM based Agentic AI Empowered Intelligent Wireless Networks , author=. 2026 , eprint=
2026
-
[7]
2026 , eprint=
Agentic AI-RAN Empowering Synergetic Sensing, Communication, Computing, and Control , author=. 2026 , eprint=
2026
-
[8]
2026 , eprint=
Tool Use as Action: Towards Agentic Control in Mobile Core Networks , author=. 2026 , eprint=
2026
-
[9]
2025 , eprint=
Reflection-Driven Self-Optimization 6G Agentic AI RAN via Simulation-in-the-Loop Workflows , author=. 2025 , eprint=
2025
-
[10]
2025 , eprint=
Agentic AI for Integrated Sensing and Communication: Analysis, Framework, and Case Study , author=. 2025 , eprint=
2025
-
[11]
2025 , eprint=
Towards 6G Native-AI Edge Networks: A Semantic-Aware and Agentic Intelligence Paradigm , author=. 2025 , eprint=
2025
-
[12]
2026 , eprint =
Agentic AI for SAGIN Resource Management: Semantic Awareness, Orchestration, and Optimization , author =. 2026 , eprint =
2026
-
[13]
2025 , eprint=
Where LLM Agents Fail and How They can Learn From Failures , author=. 2025 , eprint=
2025
-
[14]
A Taxonomy of Failures in Tool-Augmented LLMs , year=
Winston, Cailin and Just, René , booktitle=. A Taxonomy of Failures in Tool-Augmented LLMs , year=
-
[15]
2026 , eprint=
When Agents Fail to Act: A Diagnostic Framework for Tool Invocation Reliability in Multi-Agent LLM Systems , author=. 2026 , eprint=
2026
-
[16]
2025 , eprint=
Butterfly Effects in Toolchains: A Comprehensive Analysis of Failed Parameter Filling in LLM Tool-Agent Systems , author=. 2025 , eprint=
2025
-
[17]
2026 , eprint=
Characterizing Faults in Agentic AI: A Taxonomy of Types, Symptoms, and Root Causes , author=. 2026 , eprint=
2026
-
[18]
2025 , eprint=
Aegis: Taxonomy and Optimizations for Overcoming Agent-Environment Failures in LLM Agents , author=. 2025 , eprint=
2025
-
[19]
2026 , eprint=
AgentRx: Diagnosing AI Agent Failures from Execution Trajectories , author=. 2026 , eprint=
2026
-
[20]
AAAI 2026 Workshop on Trust and Control in Agentic AI (TrustAgent) , year=
Beyond Success Rate: Benchmarking Robustness in Tool-Using Language Agents , author=. AAAI 2026 Workshop on Trust and Control in Agentic AI (TrustAgent) , year=
2026
-
[21]
arXiv preprint arXiv:2510.19973 , year=
A Tutorial on Cognitive Biases in Agentic AI-Driven 6G Autonomous Networks , author=. arXiv preprint arXiv:2510.19973 , year=
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.