Recognition: 2 theorem links
· Lean TheoremRethinking the Need for Source Models: Source-Free Domain Adaptation from Scratch Guided by a Vision-Language Model
Pith reviewed 2026-05-08 18:23 UTC · model grok-4.3
The pith
Vision-language models let domain adaptation start from random weights without any source model at all.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under the VODA setting that removes every dependency on source data and source models, the Two-Stage Denoised-Region Distillation framework reaches competitive or better accuracy than prior source-free domain adaptation methods that still initialize from a source pre-trained model.
What carries the argument
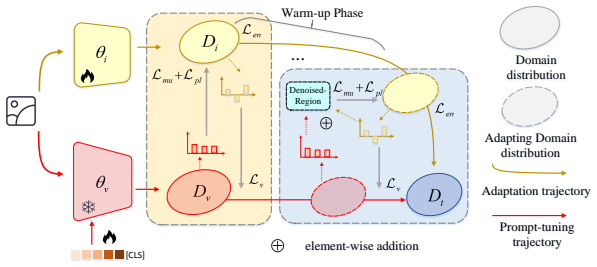
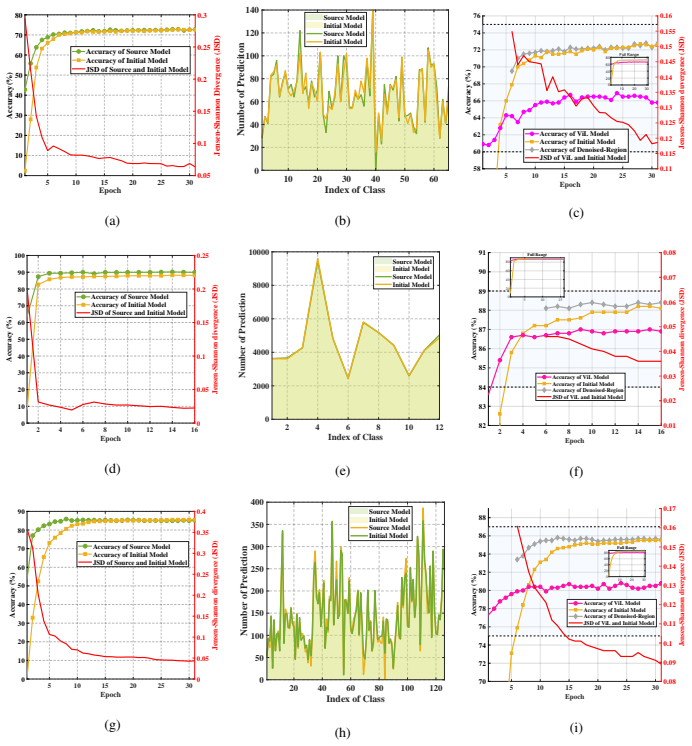
Two-Stage Denoised-Region Distillation (TS-DRD), a procedure that first warms up a random network using vision-language guidance and then extracts a shared denoised region between the vision-language model and the adapting network to supply cleaner pseudo-labels for distillation.
If this is right
- Domain adaptation can be performed without ever training or storing a source model.
- Vision-language models alone can replace the role previously played by source pre-training.
- The choice of source model has limited effect on final target accuracy once the target data are fixed.
- A two-stage warm-up followed by denoised-region distillation produces usable supervision from a vision-language model.
Where Pith is reading between the lines
- VODA may reduce the need to store or transmit large source models in privacy-sensitive applications.
- The same invariance to source model choice could be tested on detection or segmentation tasks to see whether vision-language guidance remains sufficient.
- If target-domain statistics dominate, then collecting more diverse unlabeled target data might improve results faster than improving the vision-language model.
Load-bearing premise
A vision-language model can supply reliable enough guidance to adapt a network that begins with random weights using only unlabeled target data.
What would settle it
Run TS-DRD from random initialization on a held-out target domain and measure whether its accuracy falls well below the accuracy of any standard SFDA method that starts from a source model; a large consistent gap would show that the source model remains necessary.
Figures


read the original abstract
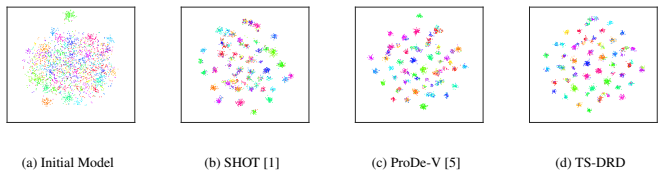
Source-Free Domain Adaptation (SFDA) adapts source models to target domains without accessing source data, addressing privacy and transmission issues. However, existing methods still initialize from a source pre-trained model and thus are not truly source-free. Recent works have introduced Vision-Language (ViL) models to guide the adaptation process, in these methods, we observe that for the same target domain, different source models yield minimal variation in final results, indicating the source model itself has limited impact. Motivated by this, we propose ViL-Only Domain Adaptation (VODA) , a stricter setting that eliminates all dependencies on source domain, relying solely on a randomly initialized model, a ViL model, and unlabeled target data. We analyze the adaptation dynamics of VODA and introduce Two-Stage Denoised-Region Distillation (TS-DRD) , a two-stage framework that first warms up the model with ViL guidance, then seek a Denoised-Region inherent in both the ViL and adapting model, yielding cleaner supervision for distillation. Experiments on Office-Home, VisDA, and DomainNet-126 show that under VODA, TS-DRD achieves competitive or superior performance to existing SFDA methods that still use source models, demonstrating its effectiveness and the potential of the VODA setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper motivates a stricter ViL-Only Domain Adaptation (VODA) setting by observing that, in existing SFDA methods guided by vision-language models, swapping source models produces minimal variation in final target performance. It proposes Two-Stage Denoised-Region Distillation (TS-DRD), which warms up a randomly initialized backbone using ViL pseudo-labels and then extracts denoised regions for cleaner distillation, and reports that TS-DRD achieves competitive or superior results to conventional SFDA methods on Office-Home, VisDA, and DomainNet-126.
Significance. If the central empirical claims hold, the work would demonstrate that source models can be eliminated entirely in domain adaptation, shifting the field toward purely target-driven, privacy-preserving pipelines that rely only on ViL guidance and random initialization. This would be a notable conceptual advance, provided the motivating observation generalizes and the from-scratch regime is shown to be robust rather than dependent on residual pre-training effects.
major comments (3)
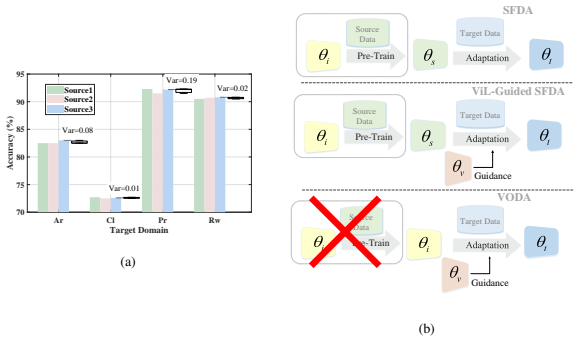
- [Introduction / §3] Introduction and §3 (motivating observation): the claim that 'different source models yield minimal variation in final results' is presented as general motivation for VODA, yet the manuscript provides no quantitative table or figure reporting performance variance (e.g., mean and std across source backbones) on the three evaluated datasets; without this evidence the justification for discarding source models remains unsupported.
- [Experiments (§4)] Experiments (§4): no ablation isolates random initialization from ImageNet pre-training; the warm-up stage and subsequent denoised-region distillation could still benefit from residual pre-trained features, undermining the central claim that TS-DRD succeeds 'from scratch' under VODA.
- [§4.2] §4.2 (TS-DRD details): the denoised-region extraction assumes ViL signals remain reliable after the first stage, but the paper reports no sensitivity tests to alternative ViL models (e.g., different CLIP variants) or to initialization variance; this leaves open whether reported gains are specific to the chosen ViL and random seed.
minor comments (2)
- [Abstract] Abstract: minor grammatical issues ('in these methods, we observe' should be 'in these methods we observe'; 'then seek a Denoised-Region' should be 'then seeks a denoised region').
- [Method] Notation: 'Denoised-Region' is inconsistently capitalized; define the region extraction procedure formally (e.g., via an equation) rather than descriptively.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. The comments highlight important aspects of our motivation and experimental validation for the VODA setting and TS-DRD method. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Introduction / §3] Introduction and §3 (motivating observation): the claim that 'different source models yield minimal variation in final results' is presented as general motivation for VODA, yet the manuscript provides no quantitative table or figure reporting performance variance (e.g., mean and std across source backbones) on the three evaluated datasets; without this evidence the justification for discarding source models remains unsupported.
Authors: We agree that a quantitative demonstration would make the motivating observation more rigorous. While our preliminary experiments across multiple source models (e.g., ResNet-50, ResNet-101, and ViT variants) showed low variance in final target accuracy under the same ViL guidance, this was not reported in tabular form. In the revised manuscript, we will add a new table in Section 3 that reports mean and standard deviation of target performance when TS-DRD is initialized from different source models on Office-Home, VisDA, and DomainNet-126, thereby providing concrete evidence for the limited impact of the source model. revision: yes
-
Referee: [Experiments (§4)] Experiments (§4): no ablation isolates random initialization from ImageNet pre-training; the warm-up stage and subsequent denoised-region distillation could still benefit from residual pre-trained features, undermining the central claim that TS-DRD succeeds 'from scratch' under VODA.
Authors: This concern is well-taken and directly relates to the core claim of the VODA setting. Our implementation initializes the backbone with standard random initialization (e.g., Kaiming or Xavier) without any ImageNet or source-domain pre-training, as stated in the VODA definition. However, to explicitly isolate this factor, we will add an ablation in the revised Section 4 that compares TS-DRD performance under (i) random initialization and (ii) ImageNet-pretrained initialization, both within the VODA protocol (no source data or models). This will confirm that the reported gains arise from the two-stage denoised-region distillation rather than residual pre-trained features. revision: yes
-
Referee: [§4.2] §4.2 (TS-DRD details): the denoised-region extraction assumes ViL signals remain reliable after the first stage, but the paper reports no sensitivity tests to alternative ViL models (e.g., different CLIP variants) or to initialization variance; this leaves open whether reported gains are specific to the chosen ViL and random seed.
Authors: We acknowledge the value of sensitivity analysis for robustness. The current results use a fixed CLIP ViT-B/16 model and report single-run performance. In the revision, we will expand Section 4.2 with additional experiments using alternative ViL models (e.g., CLIP ViT-L/14 and OpenCLIP variants) and will report mean and standard deviation over at least three random seeds for the main benchmarks. This will demonstrate that the denoised-region distillation remains effective across ViL choices and initialization variance. revision: yes
Circularity Check
No circularity: empirical method with self-contained description
full rationale
The paper is an empirical proposal of the VODA setting and TS-DRD framework for source-free domain adaptation guided by vision-language models. It motivates the approach via an experimental observation about source-model variation but presents the method steps (warm-up with ViL guidance followed by denoised-region distillation) independently of any fitted parameters or self-referential equations. Performance is validated on Office-Home, VisDA, and DomainNet-126 without any derivation chain that reduces predictions or claims back to inputs by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked.
Axiom & Free-Parameter Ledger
free parameters (1)
- Stage-specific hyperparameters for warm-up and distillation
axioms (1)
- domain assumption Vision-language models encode transferable knowledge that can guide adaptation without source data
Lean theorems connected to this paper
-
Cost.FunctionalEquation (RS forces a parameter-free J; this paper uses dataset-tuned hyperparameters — orthogonal methodology)washburn_uniqueness_aczel unclearHyper-parameters are set as follows. On Office-Home, we use α=1.3, γ=1.0, β=0.4; on VisDA-C, α=1.0, γ=0.1, β=0.4; on DomainNet-126, α=1.3, γ=0.01, β=0.4.
Reference graph
Works this paper leans on
-
[1]
J. Liang, D. Hu, J. Feng, Do we really need to access the source data? source hypothesis transfer for unsupervised domain adaptation, in: Proceedings of the 37th International Conference on Machine Learning, ICML’20, JMLR.org, 2020, pp. 6028–6039.doi:10.48550/arXiv.2002.08546. URLhttps://doi.org/10.48550/arXiv.2002.08546
-
[2]
J. Li, Z. Yu, Z. Du, L. Zhu, H. T. Shen, A comprehensive survey on source-free domain adaptation, IEEE Transactions on Pattern Analysis and Machine Intelli- 23 gence 46 (8) (2024) 5743–5762.doi:10.1109/TPAMI.2024.3370978. URLhttps://doi.org/10.1109/TPAMI.2024.3370978
-
[3]
J. Li, Y . Li, Y . Fu, J. Liu, Y . Liu, M. Yang, I. King, Clip-powered domain gener- alization and domain adaptation: A comprehensive survey, IEEE Transactions on Pattern Analysis and Machine Intelligence (2026) 1–20doi:10.1109/TPAMI. 2026.3651700. URLhttps://doi.org/10.1109/TPAMI.2026.3651700
-
[4]
S. Tang, W. Su, M. Ye, X. Zhu, Source-free domain adaptation with frozen mul- timodal foundation model, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR ’24, 2024, pp. 23711–23720. doi:10.48550/arXiv.2311.16510. URLhttps://doi.org/10.48550/arXiv.2311.16510
-
[5]
S. Tang, W. Su, Y . Gan, M. Ye, J. Dr. Zhang, X. Zhu, Proxy denoising for source- free domain adaptation, in: International Conference on Representation Learning, 2025, pp. 82548–82569.doi:10.48550/arXiv.2406.01658. URLhttps://doi.org/10.48550/arXiv.2406.01658
-
[6]
M. Zhan, Z. Wu, J. Yang, L. Peng, J. Shen, X. Zhu, Dual transferable knowledge interaction for source-free domain adaptation, Information Processing & Man- agement 63 (1) (2026) 104302.doi:10.1016/j.ipm.2025.104302. URLhttps://doi.org/10.1016/j.ipm.2025.104302
-
[7]
S. Yang, J. Van de Weijer, L. Herranz, S. Jui, et al., Exploiting the intrinsic neigh- borhood structure for source-free domain adaptation, in: Advances in Neural In- formation Processing Systems, V ol. 34 of NeurIPS ’21, 2021, pp. 29393–29405. doi:10.48550/arXiv.2110.04202. URLhttps://doi.org/10.48550/arXiv.2110.04202
-
[8]
F. You, J. Li, L. Zhu, Z. Chen, Z. Huang, Domain adaptive semantic segmentation without source data, in: Proceedings of the 29th ACM International Conference on Multimedia, MM ’21, ACM, 2021, pp. 3293–3302.doi:10.1145/3474085. 24 3475482. URLhttps://doi.org/10.1145/3474085.3475482
-
[9]
I. Diamant, A. Rosenfeld, I. Achituve, J. Goldberger, A. Netzer, De-confusing pseudo-labels in source-free domain adaptation, in: European Conference on Computer Vision, Springer, 2024, pp. 108–125.doi:10.48550/arXiv.2401. 01650. URLhttps://doi.org/10.48550/arXiv.2401.01650
-
[10]
V . K. Kurmi, V . K. Subramanian, V . P. Namboodiri, Domain impression: A source data free domain adaptation method, in: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, W ACV ’21, IEEE, 2021, pp. 615–625.doi:10.1109/WACV48630.2021.00066. URLhttps://doi.org/10.1109/WACV48630.2021.00066
-
[11]
J. Huang, D. Guan, A. Xiao, S. Lu, Model adaptation: Historical contrastive learning for unsupervised domain adaptation without source data, in: Advances in Neural Information Processing Systems, V ol. 34 of NeurIPS ’21, 2021, pp. 3635–3649.doi:10.48550/arXiv.2110.03374. URLhttps://doi.org/10.48550/arXiv.2110.03374
-
[12]
N. Ding, Y . Xu, Y . Tang, C. Xu, Y . Wang, D. Tao, Source-free domain adapta- tion via distribution estimation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR ’22, IEEE, New Orleans, LA, USA, 2022, pp. 7202–7212.doi:10.1109/CVPR52688.2022.00707. URLhttps://doi.org/10.1109/CVPR52688.2022.00707
-
[13]
Y . Du, H. Yang, M. Chen, H. Luo, J. Jiang, Y . Xin, C. Wang, Generation, aug- mentation, and alignment: A pseudo-source domain based method for source- free domain adaptation, Machine Learning 113 (6) (2024) 3611–3631.doi: 10.1007/s10994-023-06432-8. URLhttps://doi.org/10.1007/s10994-023-06432-8
-
[14]
Learning Transferable Visual Models From Natural Language Supervision
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al., Learning transferable visual models from 25 natural language supervision, in: International conference on machine learning, PmLR, 2021, pp. 8748–8763.doi:10.48550/arXiv.2103.00020. URLhttps://doi.org/10.48550/arXiv.2103.00020
work page internal anchor Pith review doi:10.48550/arxiv.2103.00020 2021
-
[15]
C. Ge, R. Huang, M. Xie, Z. Lai, S. Song, S. Li, G. Huang, Domain adaptation via prompt learning, IEEE Transactions on Neural Networks and Learning Systems 36 (1) (2025) 1160–1170.doi:10.1109/TNNLS.2023.3327962. URLhttps://doi.org/10.1109/TNNLS.2023.3327962
-
[16]
K. Zhou, J. Yang, C. C. Loy, Z. Liu, Learning to prompt for vision-language models, International Journal of Computer Vision 130 (9) (2022) 2337–2348. doi:10.1007/s11263-022-01653-1. URLhttps://doi.org/10.1007/s11263-022-01653-1
-
[17]
M. Shu, W. Nie, D.-A. Huang, Z. Yu, T. Goldstein, A. Anandkumar, C. Xiao, Test-time prompt tuning for zero-shot generalization in vision-language models, in: Advances in Neural Information Processing Systems, 2022, pp. 14274–14289. doi:10.48550/arXiv.2209.07511. URLhttps://doi.org/10.48550/arXiv.2209.07511
-
[18]
T. Meng, X. Jing, Z. Yan, W. Pedrycz, A survey on machine learning for data fu- sion, Information Fusion 57 (2020) 115–129.doi:10.1016/j.inffus.2019. 12.001. URLhttps://doi.org/10.1016/j.inffus.2019.12.001
-
[19]
H. M. Gomes, J. P. Barddal, F. Enembreck, A. Bifet, A survey on ensemble learning for data stream classification, ACM Computing Surveys 50 (2) (2017). doi:10.1145/3054925. URLhttps://doi.org/10.1145/3054925
-
[20]
X. Ji, J. F. Henriques, A. Vedaldi, Invariant information clustering for unsuper- vised image classification and segmentation, in: Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9865–9874.doi:10. 48550/arXiv.1807.06653. URLhttps://doi.org/10.48550/arXiv.1807.06653 26
-
[21]
W. Hu, T. Miyato, S. Tokui, E. Matsumoto, M. Sugiyama, Learning discrete representations via information maximizing self-augmented training, in: Pro- ceedings of the 34th International Conference on Machine Learning, ICML’17, JMLR.org, Sydney, Australia, 2017, pp. 1558–1567.doi:10.48550/arXiv. 1702.08720. URLhttps://doi.org/10.48550/arXiv.1702.08720
work page internal anchor Pith review doi:10.48550/arxiv 2017
-
[22]
H. Venkateswara, J. Eusebio, S. Chakraborty, S. Panchanathan, Deep hashing net- work for unsupervised domain adaptation, in: Proceedings of the IEEE Confer- ence on Computer Vision and Pattern Recognition, CVPR ’17, IEEE, Honolulu, HI, USA, 2017, pp. 5385–5394.doi:10.1109/CVPR.2017.572. URLhttps://doi.org/10.1109/CVPR.2017.572
-
[23]
X. Peng, B. Usman, N. Kaushik, J. Hoffman, D. Wang, K. Saenko, Visda: The visual domain adaptation challenge, arXiv preprint arXiv:1710.06924 (2017). doi:10.48550/arXiv.1710.06924. URLhttps://doi.org/10.48550/arXiv.1710.06924
-
[24]
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, C. L. Zitnick, Microsoft coco: Common objects in context, in: European conference on computer vision, Springer, 2014, pp. 740–755.doi:10.48550/arXiv.1405. 0312. URLhttps://doi.org/10.48550/arXiv.1405.0312
-
[25]
X. Peng, Q. Bai, X. Xia, Z. Huang, K. Saenko, B. Wang, Moment matching for multi-source domain adaptation, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, ICCV ’19, IEEE, Seoul, South Korea, 2019, pp. 1406–1415.doi:10.1109/ICCV.2019.00149. URLhttps://doi.org/10.1109/ICCV.2019.00149
-
[26]
S. Tang, Y . Shi, Z. Ma, J. Li, J. Lyu, Q. Li, J. Zhang, Model adaptation through hypothesis transfer with gradual knowledge distillation, in: 2021 IEEE/RSJ Inter- national Conference on Intelligent Robots and Systems (IROS), IEEE, 2021, pp. 27 5679–5685.doi:10.1109/IROS51168.2021.9636206. URLhttps://doi.org/10.1109/IROS51168.2021.9636206
-
[27]
S. Yang, S. Jui, J. Van De Weijer, et al., Attracting and dispersing: A simple approach for source-free domain adaptation, in: Advances in Neural Informa- tion Processing Systems, V ol. 35 of NeurIPS ’22, New Orleans, Louisiana, USA, 2022, pp. 6000–6010.doi:10.48550/arXiv.2205.04183. URLhttps://doi.org/10.48550/arXiv.2205.04183
-
[28]
D. Chen, D. Wang, T. Darrell, S. Ebrahimi, Contrastive test-time adaptation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 295–305.doi:10.48550/arXiv.2204.10377. URLhttps://doi.org/10.48550/arXiv.2204.10377
-
[29]
J. Lee, D. Jung, J. Yim, S. Yoon, Confidence score for source-free unsupervised domain adaptation, in: International conference on machine learning, PMLR, 2022, pp. 12365–12377.doi:10.48550/arXiv.2206.06640. URLhttps://doi.org/10.48550/arXiv.2206.06640
-
[30]
L. Yi, G. Xu, P. Xu, J. Li, R. Pu, C. Ling, A. I. McLeod, B. Wang, When source- free domain adaptation meets learning with noisy labels, in: International Confer- ence on Representation Learning, 2023.doi:10.48550/arXiv.2301.13381. URLhttps://doi.org/10.48550/arXiv.2301.13381
-
[31]
M. Litrico, A. Del Bue, P. Morerio, Guiding pseudo-labels with uncertainty es- timation for source-free unsupervised domain adaptation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 7640–7650.doi:10.48550/arXiv.2303.03770. URLhttps://doi.org/10.48550/arXiv.2303.03770
-
[32]
L. Zhou, N. Li, M. Ye, X. Zhu, S. Tang, Source-free domain adaptation with class prototype discovery, Pattern Recognition 145 (2024) 109974.doi:10.1016/j. patcog.2023.109974. URLhttps://doi.org/10.1016/j.patcog.2023.109974 28
work page doi:10.1016/j 2024
-
[33]
S. Tang, A. Chang, F. Zhang, X. Zhu, M. Ye, C. Zhang, Source-free domain adap- tation via target prediction distribution searching, International Journal of Com- puter Vision 132 (3) (2024) 654–672.doi:10.1007/s11263-023-01892-w. URLhttps://doi.org/10.1007/s11263-023-01892-w
-
[34]
G. Xu, H. Guo, L. Yi, C. Ling, B. Wang, G. Yi, Revisiting source-free domain adaptation: a new perspective via uncertainty control, in: The Thirteenth International Conference on Learning Representations, 2025. URLhttps://proceedings.iclr.cc/paper_files/paper/2025/file/ e85454a113e8b41e017c81875ae68d47-Paper-Conference.pdf
2025
-
[35]
R. Shao, W. Zhang, K. Luo, Q. Li, J. Wang, Consistent assistant domains trans- former for source-free domain adaptation, IEEE Transactions on Image Process- ing (2025).doi:10.1109/TIP.2025.3611799. URLhttps://doi.org/10.1109/TIP.2025.3611799
-
[36]
Z. Lai, N. Vesdapunt, N. Zhou, J. Wu, C. P. Huynh, X. Li, K. K. Fu, C.-N. Chuah, Padclip: Pseudo-labeling with adaptive debiasing in clip for unsupervised domain adaptation, in: Proceedings of the IEEE/CVF International Conference on Com- puter Vision, 2023, pp. 16155–16165.doi:10.1109/ICCV51070.2023.01480. URLhttps://doi.org/10.1109/ICCV51070.2023.01480
-
[37]
M. Singha, H. Pal, A. Jha, B. Banerjee, Ad-clip: Adapting domains in prompt space using clip, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4355–4364.doi:10.48550/arXiv.2308.05659. URLhttps://doi.org/10.48550/arXiv.2308.05659
-
[38]
Z. Du, X. Li, F. Li, K. Lu, L. Zhu, J. Li, Domain-agnostic mutual prompting for unsupervised domain adaptation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 23375–23384.doi: 10.48550/arXiv.2403.02899. URLhttps://doi.org/10.48550/arXiv.2403.02899
-
[39]
S. Bai, M. Zhang, W. Zhou, S. Huang, Z. Luan, D. Wang, B. Chen, Prompt- based distribution alignment for unsupervised domain adaptation, in: Proceedings 29 of the AAAI conference on artificial intelligence, V ol. 38, 2024, pp. 729–737. doi:10.48550/arXiv.2312.09553. URLhttps://doi.org/10.48550/arXiv.2312.09553
-
[40]
P. P. Busto, J. Gall, Open set domain adaptation, in: 2017 IEEE INTERNA- TIONAL CONFERENCE ON COMPUTER VISION, 2017, pp. 754–763.doi: 10.1109/ICCV.2017.88. URLhttps://doi.org/10.1109/ICCV.2017.88
-
[41]
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recogni- tion, in: Proceedings of the IEEE Conference on Computer Vision and Pat- tern Recognition, CVPR ’16, IEEE, Las Vegas, NV , USA, 2016, pp. 770–778. doi:10.1109/CVPR.2016.90. URLhttps://doi.org/10.1109/CVPR.2016.90
-
[42]
Glorot, Y
X. Glorot, Y . Bengio, Understanding the difficulty of training deep feedforward neural networks, Journal of Machine Learning Research 9 (2010) 249–256
2010
-
[43]
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
S. Ioffe, C. Szegedy, Batch normalization: Accelerating deep network training by reducing internal covariate shift, in: 32nd International Conference on Machine Learning, 2015, pp. 448–456.doi:10.48550/arXiv.1502.03167. URLhttps://doi.org/10.48550/arXiv.1502.03167
work page internal anchor Pith review doi:10.48550/arxiv.1502.03167 2015
-
[44]
A. Dosovitskiy, An image is worth 16x16 words: Transformers for image recog- nition at scale, arXiv preprint arXiv:2010.11929 (2020).doi:10.48550/arXiv: 2010.11929. URLhttps://doi.org/10.48550/arXiv:2010.11929
-
[45]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, I. Polosukhin, Attention is all you need, in: Advances in Neural In- formation Processing Systems, V ol. 31 of NeurIPS ’17, Long Beach, California, USA, 2017, pp. 6000–6010.doi:10.48550/arXiv.1706.03762. URLhttps://doi.org/10.48550/arXiv.1706.03762 30
work page internal anchor Pith review doi:10.48550/arxiv.1706.03762 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.