Recognition: 2 theorem links
· Lean TheoremValidation of an AI-based end-to-end model for prostate pathology using long-term archived routine samples
Pith reviewed 2026-05-08 18:16 UTC · model grok-4.3
The pith
An AI model grades prostate biopsies at pathologist level and stays stable on samples up to 17 years old.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GleasonAI, an attention-based multiple instance learning model, achieves an overall quadratic-weighted kappa of 0.86 for core-level ISUP grading on 10,366 archival biopsy cores, with performance that does not decline across a 17-year collection window and that shows a statistically significant prognostic gradient for prostate-cancer-specific mortality.
What carries the argument
The end-to-end attention-based multiple instance learning model (GleasonAI) that maps whole-slide images of biopsy cores directly to ISUP grade groups without intermediate patch-level labels.
If this is right
- The model can be applied to routine diagnostic material from varied geographic sources without loss of agreement.
- Performance does not degrade with increasing sample age, allowing use of historical archives for validation.
- AI-assigned grade groups carry prognostic information for prostate-cancer-specific mortality.
- Large-scale retrospective studies of prostate cancer outcomes become feasible using consistent AI grading on existing archives.
Where Pith is reading between the lines
- Consistent AI grading across decades could allow re-analysis of old cohorts to test whether grade group cutoffs should be adjusted for long-term risk.
- If the stability holds on non-Swedish material, the approach could support multi-center validation without fresh staining standardization.
- The prognostic signal in AI grades raises the testable possibility that the model captures subtle histologic features missed in routine reporting.
Load-bearing premise
The original pathologist-assigned ISUP grades from routine practice serve as sufficiently reliable ground truth, unaffected by inter-observer variability or by any time-dependent changes in the archived tissue that would affect the AI differently than human readers.
What would settle it
Independent re-grading of a random subset of the same cores by multiple pathologists, followed by measurement of inter-observer kappa and comparison against the AI's agreement with the original labels; a large drop would undermine the ground-truth assumption.
Figures





read the original abstract
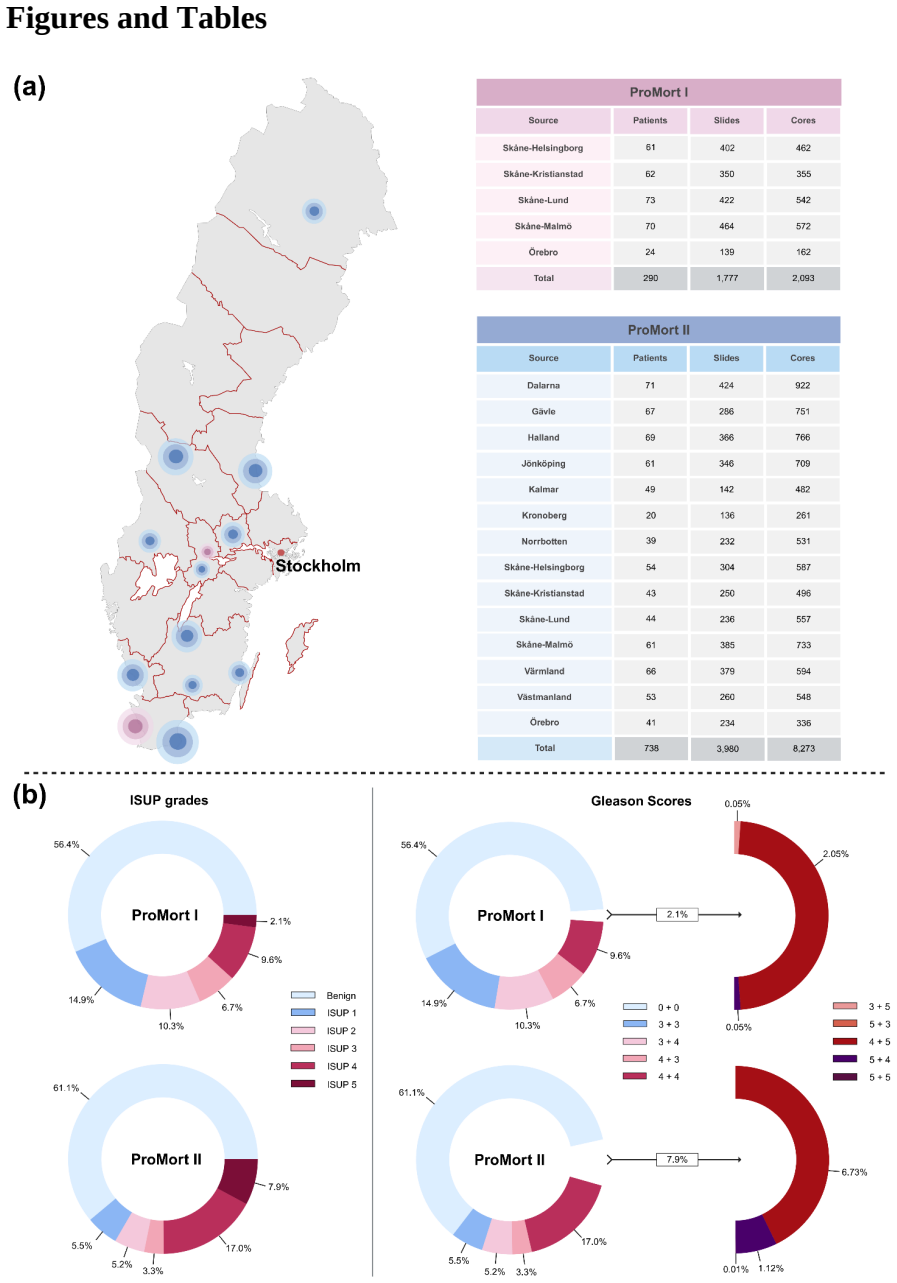
Artificial intelligence (AI) is becoming a clinical tool for prostate pathology, but generalization across variations in sample preparation and preservation over prolonged time periods remains poorly understood. We evaluated GleasonAI, an end-to-end attention-based multiple instance learning model, on an independent validation cohort comprising 10,366 biopsy cores from 1,028 patients across 14 Swedish regions, using archival diagnostic specimens from the ProMort cohorts collected between 1998-2015. The model achieved an overall quadratic-weighted kappa of 0.86 for core-level ISUP grading, comparable to several experienced pathologists and consistent across geographic regions. Notably, performance remained stable across the 17-year collection period, demonstrating robustness to time-related variation in archival material, a property not consistently observed with foundation model-based approaches, with exploratory analysis demonstrating a significant prognostic gradient across AI-assigned grade groups for prostate cancer-specific mortality. These findings support the generalizability of the AI grading model and demonstrate the potential of pathology archives as a large-scale resource for AI development, validation, and retrospective prognostic research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
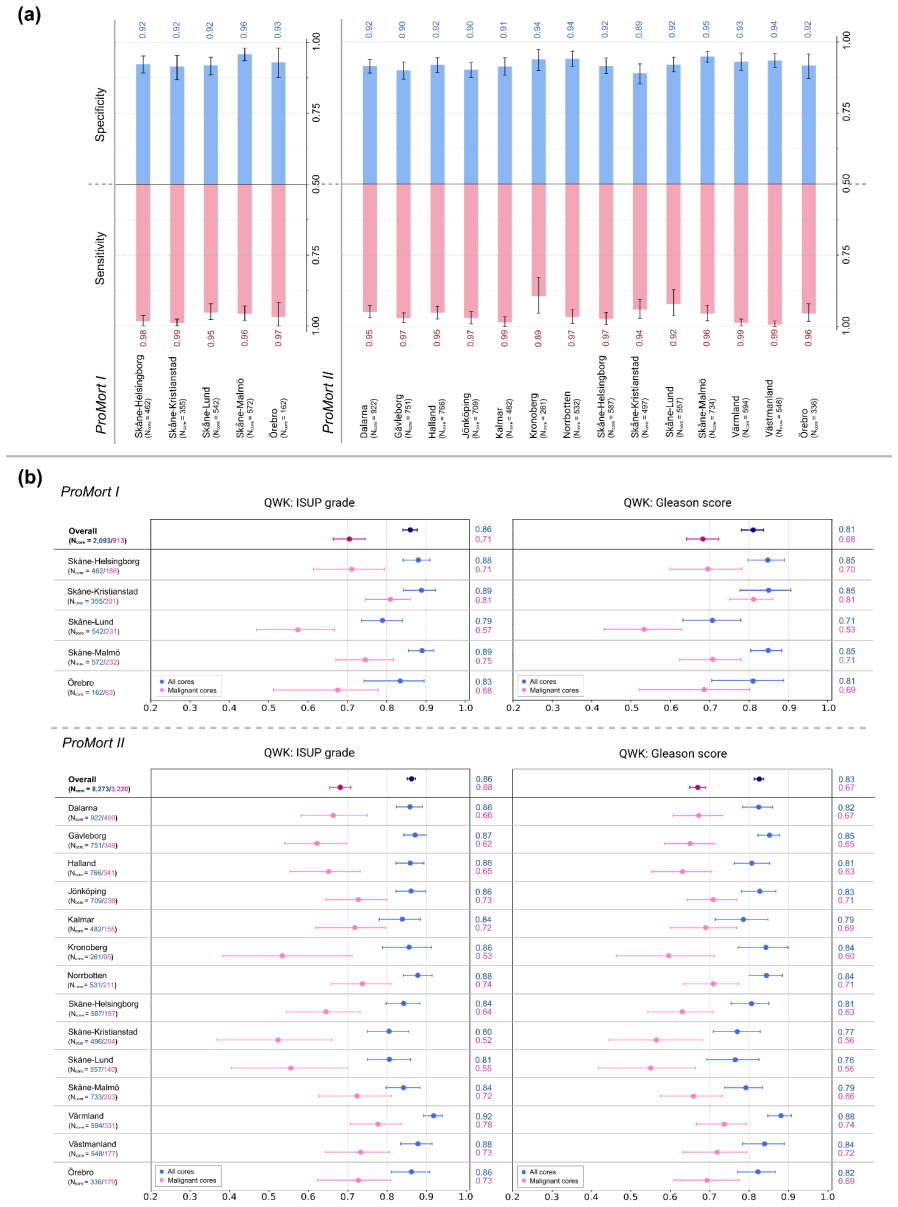
Summary. The paper validates the GleasonAI end-to-end attention-based multiple instance learning model for core-level ISUP grading on an independent cohort of 10,366 biopsy cores from 1,028 patients across 14 Swedish regions, drawn from the ProMort archival diagnostic specimens collected 1998-2015. It reports an overall quadratic-weighted kappa of 0.86 against the original routine pathologist labels, with consistency across geographic regions, stability over the 17-year span, comparability to experienced pathologists, and an exploratory prognostic gradient for prostate cancer-specific mortality across AI-assigned grade groups.
Significance. If the central performance and stability claims hold after addressing ground-truth limitations, the work would demonstrate that pathology archives can serve as a scalable resource for AI model validation and retrospective prognostic research, particularly for robustness to long-term sample variation. The multi-regional, multi-year cohort size and the prognostic analysis are concrete strengths that would strengthen evidence for generalizability beyond what is typically shown in smaller or single-institution studies.
major comments (2)
- [Abstract] Abstract and validation design: The quadratic-weighted kappa of 0.86 and the temporal-stability claim are computed against single-pathologist routine diagnostic ISUP labels from 1998-2015 without any reported inter-rater agreement statistics, multi-pathologist re-review, or cohort-specific variability metrics on the 10,366 cores. Because prostate ISUP/Gleason grading is known to exhibit substantial inter-observer variability (expert pairwise kappa typically 0.5-0.75), it is impossible to determine whether the reported AI agreement exceeds, matches, or lies within the range of human variability on these exact archival samples.
- [Results] Results on temporal stability and prognostic analysis: The claim that performance 'remained stable across the 17-year collection period' and the prognostic gradient are vulnerable because both the original labels and the AI predictions could be similarly affected by time-dependent staining, sectioning, or preservation artifacts; without data on how such artifacts differentially impact human grading versus the model (or a re-reviewed subset), the robustness interpretation lacks direct support.
minor comments (2)
- [Abstract] The abstract and methods do not report confidence intervals around the kappa value, details on exclusion criteria for the 10,366 cores, or the training data and splits used to develop GleasonAI (if this is a held-out validation of a prior model).
- [Results] Figure or table legends should explicitly state whether the reported kappa is core-level only or also includes patient-level aggregation, and whether any calibration or threshold tuning was performed on the validation cohort.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our manuscript. We have addressed each major point below, providing clarifications and indicating where revisions have been made to improve the manuscript. Our responses aim to strengthen the interpretation of the validation results while honestly acknowledging limitations inherent to the archival cohort design.
read point-by-point responses
-
Referee: [Abstract] Abstract and validation design: The quadratic-weighted kappa of 0.86 and the temporal-stability claim are computed against single-pathologist routine diagnostic ISUP labels from 1998-2015 without any reported inter-rater agreement statistics, multi-pathologist re-review, or cohort-specific variability metrics on the 10,366 cores. Because prostate ISUP/Gleason grading is known to exhibit substantial inter-observer variability (expert pairwise kappa typically 0.5-0.75), it is impossible to determine whether the reported AI agreement exceeds, matches, or lies within the range of human variability on these exact archival samples.
Authors: We agree that inter-observer variability in ISUP grading is a recognized limitation, with literature reporting expert pairwise kappas typically in the 0.5-0.75 range. Our reported quadratic-weighted kappa of 0.86 is computed against the original single-pathologist diagnostic labels and exceeds many published inter-rater figures, while also being consistent with performance levels observed when comparing experienced pathologists in other cohorts. However, we did not conduct a multi-pathologist re-review or compute cohort-specific inter-rater metrics on these 10,366 archival cores, as the scale of the dataset would require substantial additional resources. The manuscript already notes comparability to experienced pathologists based on external benchmarks and regional consistency. In revision, we have expanded the Discussion section to explicitly contextualize the 0.86 kappa against known human variability ranges, added a limitations paragraph on the single-label ground truth, and clarified that the result demonstrates agreement with routine diagnostic practice rather than superiority to multi-rater consensus. revision: partial
-
Referee: [Results] Results on temporal stability and prognostic analysis: The claim that performance 'remained stable across the 17-year collection period' and the prognostic gradient are vulnerable because both the original labels and the AI predictions could be similarly affected by time-dependent staining, sectioning, or preservation artifacts; without data on how such artifacts differentially impact human grading versus the model (or a re-reviewed subset), the robustness interpretation lacks direct support.
Authors: We acknowledge that without a re-reviewed subset, direct quantification of differential artifact effects on human grading versus the model is not possible, and both could in principle be influenced by time-related changes in sample quality. Our stability analysis shows no statistically significant decline in agreement metrics when stratifying by year of collection (1998-2015), and the AI-assigned grades exhibit a clear, significant prognostic gradient for cancer-specific mortality. This provides indirect evidence that the model extracts biologically meaningful signals despite potential artifacts. In the revised manuscript, we have tempered the language in the Results and Discussion to describe 'stability' as 'no evidence of performance degradation' rather than definitive robustness, added explicit caveats about the lack of re-reviewed data for artifact analysis, and suggested that future work with paired re-reviews would be valuable to isolate differential impacts. The multi-regional design and large cohort size still offer stronger generalizability evidence than typical single-institution studies. revision: partial
- Absence of multi-pathologist re-review or inter-rater agreement statistics specifically on the 10,366 archival cores, which would require new data collection beyond the scope of the current study.
- Lack of a re-reviewed subset to directly measure differential effects of time-dependent artifacts on human versus AI grading.
Circularity Check
No circularity: independent validation on external labels
full rationale
The paper evaluates a pre-existing model (GleasonAI) on an independent cohort of 10,366 cores from 1998-2015 using original routine pathologist ISUP grades as ground truth. Reported metrics (quadratic-weighted kappa 0.86, temporal stability, prognostic gradient) are direct empirical comparisons against these external labels and patient outcomes; they do not reduce to any fitted parameter, self-defined quantity, or self-citation chain within the study. No equations or derivations are presented that would make the results tautological. This is a standard held-out validation design with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Original diagnostic pathologist ISUP grades serve as reliable ground truth for AI evaluation
Reference graph
Works this paper leans on
-
[1]
Bravi, C. A. et al. Relative Contribution of Sampling and Grading to the Quality of Prostate Biopsy: Results from a Single High-volume Institution. Eur Urol Oncol 3, 474–480 (2020)
2020
-
[2]
Epstein, J. I. et al. The 2014 International Society of Urological Pathology (ISUP) Consensus Conference on Gleason Grading of Prostatic Carcinoma: Definition of Grading Patterns and Proposal for a New Grading System. Am J Surg Pathol 40, 244–252 (2016)
2014
-
[3]
Flach, R. N. et al. Significant Inter- and Intralaboratory Variation in Gleason Grading of Prostate Cancer: A Nationwide Study of 35,258 Patients in The Netherlands. Cancers (Basel) 13, (2021)
2021
-
[4]
Ilse, M., Tomczak, J. M. & Welling, M. Attention-based deep multiple instance learning. arXiv [cs.LG] (2018) doi:10.48550/arXiv.1802.04712
-
[5]
Chen, R. J. et al. Towards a general-purpose foundation model for computational pathology. Nature Medicine 30, 850–862 (2024)
2024
-
[6]
Bulten, W. et al. Artificial intelligence for diagnosis and Gleason grading of prostate cancer: the PANDA challenge. Nature Medicine 28, 154–163 (2022)
2022
-
[7]
Mulliqi, N. et al. Foundation Models -- A Panacea for Artificial Intelligence in Pathology? (2025)
2025
-
[8]
Hari, S. N. et al. Examining Batch Effect in Histopathology as a Distributionally Robust Optimization Problem. bioRxiv 2021.09.14.460365 (2021) doi:10.1101/2021.09.14.460365
-
[10]
& Hense, J
Kömen, J., Marienwald, H., Dippel, J. & Hense, J. Do Histopathological Foundation Models Eliminate Batch Effects? A Comparative Study. (2024)
2024
-
[11]
Jarkman, S. et al. Generalization of Deep Learning in Digital Pathology: Experience in Breast Cancer Metastasis Detection. Cancers (Basel) 14, (2022)
2022
-
[12]
Schömig-Markiefka, B. et al. Quality control stress test for deep learning-based diagnostic model in digital pathology. Mod Pathol 34, 2098–2108 (2021)
2098
-
[13]
Asif, A. et al. Unleashing the potential of AI for pathology: challenges and recommendations. The Journal of Pathology 260, 564 (2023)
2023
-
[14]
Zelic, R. et al. Estimation of Relative and Absolute Risks in a Competing-Risks Setting Using a Nested Case-Control Study Design: Example From the ProMort Study. Am J Epidemiol 188, 1165–1173 (2019)
2019
-
[15]
Zelic, R. et al. Prognostic Utility of the Gleason Grading System Revisions and Histopathological Factors Beyond Gleason Grade. Clin Epidemiol 14, 59–70 (2022)
2022
-
[16]
Ji, X. et al. Retrospective validation of an artificial intelligence system for diagnostic assessment of prostate biopsies on the ProMort cohort: study protocol. BMJ Open 15, e111361 (2025)
2025
-
[17]
H., Doan, J
Sura, G. H., Doan, J. V. & Thrall, M. J. Assessing the quality of cytopathology whole slide imaging for education from archived cases. J Am Soc Cytopathol 11, 313–319 (2022). 16
2022
-
[18]
Odate, T. et al. Diagnostic challenges of faded hematoxylin and eosin slides: limitations of re- staining and re-sectioning and possible reason to go digital. Virchows Archiv 1–10 (2025)
2025
-
[19]
Ali, P. J. M. et al. Validation of diagnostic artificial intelligence models for prostate pathology in a middle eastern cohort. arXiv [cs.CV] (2025) doi:10.48550/arXiv.2512.17499
-
[20]
Egevad, L. et al. Identification of areas of grading difficulties in prostate cancer and comparison with artificial intelligence assisted grading. Virchows Arch 477, 777–786 (2020)
2020
-
[21]
Zimmermann, E. et al. Virchow2: Scaling self-supervised mixed magnification models in pathology. arXiv [cs.CV] (2024) doi:10.48550/ARXIV.2408.00738
-
[22]
Oquab, M. et al. DINOv2: Learning robust visual features without supervision. arXiv [cs.CV] (2023) doi:10.48550/ARXIV.2304.07193
work page internal anchor Pith review doi:10.48550/arxiv.2304.07193 2023
-
[23]
Parker, C. T. A. et al. External validation of a digital pathology-based multimodal artificial intelligence-derived prognostic model in patients with advanced prostate cancer starting long- term androgen deprivation therapy: a post-hoc ancillary biomarker study of four phase 3 randomised controlled trials of the STAMPEDE platform protocol. Lancet Digit He...
2025
-
[24]
Zelic, R. et al. Interchangeability of light and virtual microscopy for histopathological evaluation of prostate cancer. Sci Rep 11, 3257 (2021)
2021
-
[25]
Allan, C. et al. OMERO: flexible, model-driven data management for experimental biology. Nat Methods 9, 245–253 (2012)
2012
-
[26]
Mulliqi, N. et al. Development and retrospective validation of an artificial intelligence system for diagnostic assessment of prostate biopsies: study protocol. BMJ Open 15, e097591 (2025)
2025
-
[27]
Zhou, Z., Siddiquee, M. M. R., Tajbakhsh, N. & Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. (2018)
2018
-
[28]
Deep Residual Learning for Image Recognition
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. arXiv [cs.CV] (2015) doi:10.48550/ARXIV.1512.03385
work page internal anchor Pith review doi:10.48550/arxiv.1512.03385 2015
-
[29]
https://huggingface.co/smp-hub/resnet18.swsl
smp-hub/resnet18.swsl · Hugging Face. https://huggingface.co/smp-hub/resnet18.swsl
-
[30]
Boman, S. E. et al. The impact of tissue detection on diagnostic artificial intelligence algorithms in digital pathology. (2025)
2025
-
[31]
Abadi, M. et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. (2016)
2016
-
[32]
Tan, M. & Le, Q. V. EfficientNetV2: Smaller models and faster training. arXiv [cs.CV] (2021) doi:10.48550/ARXIV.2104.00298
-
[33]
Grönberg, H. et al. Prostate cancer screening in men aged 50-69 years (STHLM3): a prospective population-based diagnostic study. Lancet Oncol 16, 1667–1676 (2015)
2015
-
[34]
& Satyanarayanan, M
Goode, A., Gilbert, B., Harkes, J., Jukic, D. & Satyanarayanan, M. OpenSlide: A vendor-neutral software foundation for digital pathology. J Pathol Inform 4, 27 (2013)
2013
-
[35]
GitHub https://github.com/qubvel- org/segmentation_models.pytorch
GitHub - qubvel-org/segmentation_models.pytorch: Semantic segmentation models with 500+ pretrained convolutional and transformer-based backbones. GitHub https://github.com/qubvel- org/segmentation_models.pytorch. 17
-
[36]
Paszke, A. et al. PyTorch: An imperative style, high-performance deep learning library. arXiv [cs.LG] (2019) doi:10.48550/ARXIV.1912.01703
-
[37]
Buslaev, A., Parinov, A., Khvedchenya, E., Iglovikov, V. I. & Kalinin, A. A. Albumentations: fast and flexible image augmentations. arXiv [cs.CV] (2018) doi:10.48550/ARXIV.1809.06839
-
[38]
Otálora, S. et al. stainlib: a python library for augmentation and normalization of histopathology H&E images. bioRxiv (2022) doi:10.1101/2022.05.17.492245
-
[39]
https://ieeexplore.ieee.org/document/6240859
A brief introduction to OpenCV. https://ieeexplore.ieee.org/document/6240859. 18 Figures and Tables Figure 1. Overview of validation dataset with primary reference standard. In total, 290 patients from ProMort I and 738 patients from ProMort II were included in this validation study after excluding slides not stained with H&E and those with annotation err...
-
[40]
Department of Medical Epidemiology and Biostatistics, Karolinska Institutet, Stockholm, Sweden
-
[41]
Department of Molecular Medicine and Surgery, Karolinska Institutet, Stockholm, Sweden
-
[42]
Department of Pelvic Cancer, Cancer Theme, Karolinska University Hospital, Stockholm, Sweden
-
[43]
Department of Pathology and Cancer Diagnostics, Karolinska University Hospital, Stockholm, Sweden
-
[44]
Department of Medical Epidemiology and Biostatistics, SciLifeLab, Karolinska Institutet, Stockholm, Sweden
-
[45]
Department of Medical and Surgical Sciences, University of Bologna, Bologna, Italy
-
[46]
Department of Pathology, IRCCS Azienda Ospedaliero-Universitaria di Bologna, Bologna, Italy
-
[47]
Division of Pathology, AOU Città Della Salute e Della Scienza di Torino, Turin, Italy
-
[48]
Department of Medical Sciences, University of Turin, Torino, Italy
-
[49]
Cancer Epidemiology Unit, University Hospital Città della Scienza e della Salute di Torino and CPO-Piemonte, Torino, Italy
-
[50]
Validation of an AI-based end-to-end model for prostate pathology
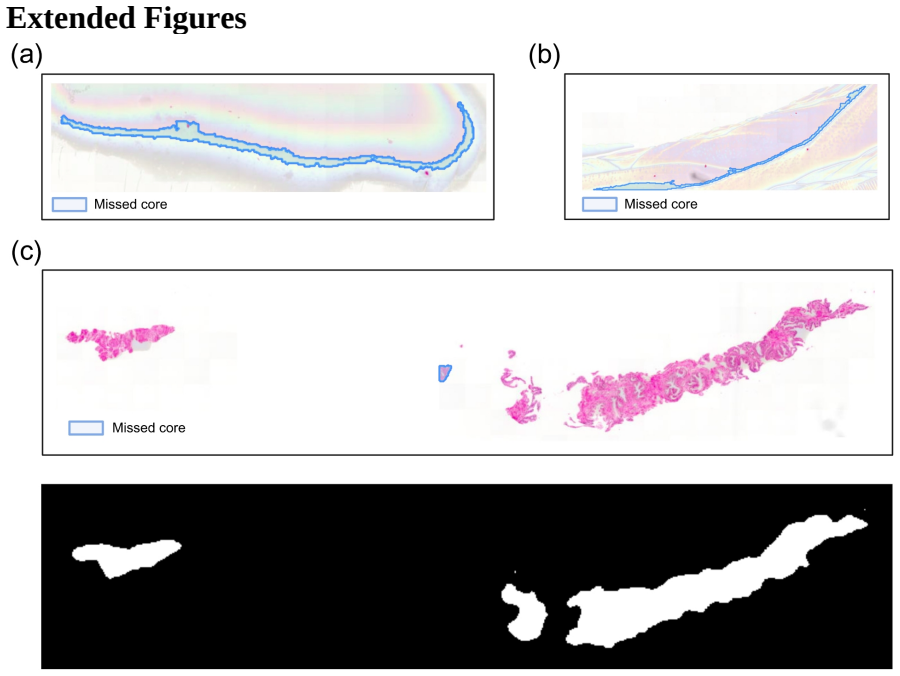
Clinical Epidemiology Division, Department of Medicine Solna, Karolinska Institutet, Stockholm, Sweden. Extended Figures Extended Figure 1. All three pre-processing failures in the AI-based tissue segmentation process. (a, b) Annotation errors where regions marked by the pathologist (blue outlines) do not represent actual tissue cores. (c) Tissue fragment...
1998
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.