Recognition: 2 theorem links
· Lean TheoremViewSAM: Learning View-aware Cross-modal Semantics for Weakly Supervised Cross-view Referring Multi-Object Tracking
Pith reviewed 2026-05-08 18:28 UTC · model grok-4.3
The pith
ViewSAM tracks objects described by natural language across camera views using only category labels by refining SAM tracklets and adding view-aware conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ViewSAM builds on SAM2 by formulating view-induced variations as learnable conditions that bridge view-variant visual features with view-invariant textual referring expressions, after an initial stage that refines and associates SAM3 tracklets across cameras via affinity-guided re-prompting to supply reliable pseudo labels from only category supervision.
What carries the argument
View-aware cross-modal semantics expressed as learnable conditions inside ViewSAM, paired with affinity-guided cross-view re-prompting that turns SAM3 tracklets into cross-view pseudo labels.
If this is right
- Cross-view referring tracking can operate at near fully-supervised accuracy with roughly 10 percent added parameters and no spatial annotations.
- Foundation models become reusable generators of pseudo labels for multi-view tasks once a lightweight re-prompting stage is applied.
- View variations can be isolated as conditions rather than treated as noise, preserving identity consistency under language queries.
- Weak supervision reduces the data cost barrier for deploying referring trackers in real multi-camera setups.
Where Pith is reading between the lines
- The same two-stage pattern of pseudo-label creation followed by light adaptation could apply to other language-guided video tasks that cross camera boundaries.
- If view conditions prove general, the method might extend to dynamic camera rigs or non-overlapping views without retraining the core model.
- Lower annotation needs open the door to training on much larger unlabeled multi-view video collections collected in the wild.
Load-bearing premise
That SAM3 tracklets can be refined and correctly associated across views using only affinity-guided re-prompting and category labels to yield training data accurate enough for the view-aware model.
What would settle it
On a standard CRMOT benchmark, measure whether the refined pseudo labels match ground-truth cross-view identities at a rate below 70 percent; if ViewSAM then falls well short of fully supervised baselines, the claim fails.
Figures







read the original abstract
Cross-view Referring Multi-Object Tracking (CRMOT) aims to track multiple objects specified by natural language across multiple camera views, with globally consistent identities. Despite recent progress, existing methods rely heavily on costly frame-level spatial annotations and cross-view identity supervision. To reduce such reliance, we explore CRMOT under weak supervision by leveraging the capabilities of foundation models. However, our empirical study shows that directly applying foundation models such as SAM2 and SAM3, even with task-specific modifications, fails to accurately understand referring expressions and maintain consistent identities across views. Yet, they remain effective at producing reliable object tracklets that can serve as pseudo supervision. We therefore repurpose foundation models as pseudo-label generators and propose a two-stage framework for weakly supervised CRMOT, using only object category labels as coarse-grained supervision. In the first stage, we design an Affinity-guided Cross-view Re-prompting strategy to refine and associate SAM3-generated tracklets across cameras, producing reliable cross-view pseudo labels for subsequent training. In the second stage, we introduce ViewSAM, a CRMOT model built upon SAM2 that explicitly models view-aware cross-modal semantics. By formulating view-induced variations as learnable conditions, ViewSAM bridges the gap between view-variant visual observations and view-invariant textual expressions, enabling robust cross-view referring tracking with only approximately 10% additional parameters. Extensive experiments demonstrate that ViewSAM achieves SOTA performance under weak supervision and remains competitive with fully supervised methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a two-stage framework for weakly supervised Cross-view Referring Multi-Object Tracking (CRMOT). Stage 1 uses an Affinity-guided Cross-view Re-prompting strategy to refine and associate SAM3-generated tracklets across views using only category labels as supervision, generating pseudo labels. Stage 2 introduces ViewSAM, which builds on SAM2 by modeling view-induced variations as learnable conditions to capture view-aware cross-modal semantics, enabling robust tracking with only about 10% additional parameters. The paper claims that this achieves state-of-the-art performance under weak supervision and remains competitive with fully supervised methods.
Significance. If the empirical results hold, the work is significant for reducing the reliance on costly frame-level spatial annotations and cross-view identity supervision in CRMOT by repurposing foundation models as pseudo-label generators and introducing an efficient view-aware adaptation. This could facilitate more practical deployments in multi-camera systems.
major comments (2)
- The SOTA claim under weak supervision and competitiveness with fully supervised methods is asserted without any quantitative metrics, baselines, error bars, dataset details, or validation procedures provided. This makes the central performance claims impossible to evaluate.
- The reliability of the Affinity-guided Cross-view Re-prompting strategy for producing high-quality cross-view pseudo labels is load-bearing for the entire framework, yet no direct quantitative validation (e.g., association precision, cross-view ID consistency rates, or error analysis on pseudo labels) is mentioned to confirm it resolves view-induced appearance changes and avoids identity switches.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the current manuscript version requires additional quantitative details to fully substantiate the performance claims and the reliability of the pseudo-label generation stage. We will revise accordingly.
read point-by-point responses
-
Referee: The SOTA claim under weak supervision and competitiveness with fully supervised methods is asserted without any quantitative metrics, baselines, error bars, dataset details, or validation procedures provided. This makes the central performance claims impossible to evaluate.
Authors: We acknowledge that the submitted manuscript does not present the quantitative results with sufficient detail. Although the abstract references extensive experiments, the experimental section in the current version lacks explicit tables, baselines, error bars, dataset statistics, and protocol descriptions. In the revision we will expand Section 4 to include: (i) full tables reporting MOTA, IDF1, HOTA, and referring accuracy under weak supervision; (ii) direct comparisons against multiple weak- and fully-supervised baselines; (iii) mean and standard deviation over multiple runs; (iv) dataset details (number of sequences, views, objects, and annotation statistics); and (v) a clear description of the evaluation protocol and splits. These additions will make the SOTA and competitiveness claims directly verifiable. revision: yes
-
Referee: The reliability of the Affinity-guided Cross-view Re-prompting strategy for producing high-quality cross-view pseudo labels is load-bearing for the entire framework, yet no direct quantitative validation (e.g., association precision, cross-view ID consistency rates, or error analysis on pseudo labels) is mentioned to confirm it resolves view-induced appearance changes and avoids identity switches.
Authors: We agree that direct validation of the pseudo-label quality is essential and currently insufficient. The manuscript relies on downstream tracking performance as indirect evidence. In the revision we will add a dedicated subsection (or table) that reports: association precision, cross-view ID consistency rates, and an error breakdown showing how the affinity-guided re-prompting reduces identity switches caused by view-induced appearance changes. These metrics will be computed on a validation subset where ground-truth cross-view associations are available, thereby providing explicit confirmation of the strategy’s reliability. revision: yes
Circularity Check
No circularity: empirical two-stage framework with independent experimental validation
full rationale
The paper describes a practical engineering pipeline: SAM3 tracklets are generated as pseudo-labels, refined via an Affinity-guided Cross-view Re-prompting strategy using only category labels, then used to train ViewSAM (a SAM2-based model with added learnable view conditions). No equations, fitted parameters, or first-principles derivations are presented that reduce to their own inputs by construction. The SOTA claims rest on reported experiments comparing against baselines, not on self-referential definitions or self-citation chains. This is a standard empirical proposal with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SAM2 and SAM3 produce reliable object tracklets that can serve as pseudo supervision for CRMOT when refined.
Lean theorems connected to this paper
-
Cost.FunctionalEquation (J(x)=½(x+x⁻¹)−1 uniqueness)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
L_CGCT = Σ_g [Σ_i Σ_(t,k)∈T_g^i ||z_t,i^k − z̄_g^i||² + λ Σ_i ||z̄_g^i − z̄_g||²]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Cross-view referring multi-object tracking
Sijia Chen, En Yu, and Wenbing Tao. Cross-view referring multi-object tracking. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 2204–2211, 2025
2025
-
[2]
Referring multi-object tracking
Dongming Wu, Wencheng Han, Tiancai Wang, Xingping Dong, Xiangyu Zhang, and Jianbing Shen. Referring multi-object tracking. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14633–14642, 2023
2023
-
[3]
CC-3dt: Panoramic 3d object tracking via cross-camera fusion
Tobias Fischer, Yung-Hsu Yang, Suryansh Kumar, Min Sun, and Fisher Yu. Cc-3dt: Panoramic 3d object tracking via cross-camera fusion.arXiv preprint arXiv:2212.01247, 2022
-
[4]
Tango: training- free embodied ai agents for open-world tasks
Filippo Ziliotto, Tommaso Campari, Luciano Serafini, and Lamberto Ballan. Tango: training- free embodied ai agents for open-world tasks. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24603–24613, 2025
2025
-
[5]
Divotrack: A novel dataset and baseline method for cross-view multi- object tracking in diverse open scenes.International Journal of Computer Vision, 132(4):1075– 1090, 2024
Shengyu Hao, Peiyuan Liu, Yibing Zhan, Kaixun Jin, Zuozhu Liu, Mingli Song, Jenq-Neng Hwang, and Gaoang Wang. Divotrack: A novel dataset and baseline method for cross-view multi- object tracking in diverse open scenes.International Journal of Computer Vision, 132(4):1075– 1090, 2024
2024
-
[6]
Multi-target multi-camera tracking with spatial-temporal network
Yi Gao, Wanneng Wu, Ao Liu, Qiaokang Liang, and Jianwen Hu. Multi-target multi-camera tracking with spatial-temporal network. In2023 7th International Symposium on Computer Science and Intelligent Control (ISCSIC), pages 196–200. IEEE, 2023
2023
-
[7]
Dual-head feature enhancement for graph-based cross-view multi-object tracking
Yunfei Zhang, Jin Gao, Wenjuan Li, and Weiming Hu. Dual-head feature enhancement for graph-based cross-view multi-object tracking. InInternational Conference on Artificial Neural Networks, pages 643–655. Springer, 2025. 10
2025
-
[8]
Gmt: Effective global framework for multi-camera multi-target tracking.arXiv e-prints, pages arXiv–2407, 2024
Yihao Zhen, Mingyue Xu, Qiang Wang, Baojie Fan, Jiahua Dong, Tinghui Zhao, and Huijie Fan. Gmt: Effective global framework for multi-camera multi-target tracking.arXiv e-prints, pages arXiv–2407, 2024
2024
-
[9]
All-day multi- camera multi-target tracking
Huijie Fan, Yu Qiao, Yihao Zhen, Tinghui Zhao, Baojie Fan, and Qiang Wang. All-day multi- camera multi-target tracking. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16892–16901, 2025
2025
-
[10]
Consis- tencies are all you need for semi-supervised vision-language tracking
Jiawei Ge, Jiuxin Cao, Xuelin Zhu, Xinyu Zhang, Chang Liu, Kun Wang, and Bo Liu. Consis- tencies are all you need for semi-supervised vision-language tracking. InProceedings of the 32nd ACM International Conference on Multimedia, pages 1895–1904, 2024
1904
-
[11]
Large-margin weakly supervised dimen- sionality reduction
Chang Xu, Dacheng Tao, Chao Xu, and Yong Rui. Large-margin weakly supervised dimen- sionality reduction. InInternational conference on machine learning, pages 865–873. PMLR, 2014
2014
-
[12]
Weaksam: Segment anything meets weakly-supervised instance-level recognition
Lianghui Zhu, Junwei Zhou, Yan Liu, Xin Hao, Wenyu Liu, and Xinggang Wang. Weaksam: Segment anything meets weakly-supervised instance-level recognition. InProceedings of the 32nd ACM international conference on multimedia, pages 7947–7956, 2024
2024
-
[13]
A brief introduction to weakly supervised learning.National science review, 5(1):44–53, 2018
Zhi-Hua Zhou. A brief introduction to weakly supervised learning.National science review, 5(1):44–53, 2018
2018
-
[14]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[15]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[16]
Segment anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
2023
-
[17]
Sam 2: Segment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos. InThe Thirteenth International Conference on Learning Representations
-
[18]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page Pith review arXiv 2025
-
[19]
From sam to cams: Exploring segment anything model for weakly supervised semantic segmentation
Hyeokjun Kweon and Kuk-Jin Yoon. From sam to cams: Exploring segment anything model for weakly supervised semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19499–19509, 2024
2024
-
[20]
Chunming He, Kai Li, Yachao Zhang, Guoxia Xu, Longxiang Tang, Yulun Zhang, Zhenhua Guo, and Xiu Li. Weakly-supervised concealed object segmentation with sam-based pseudo labeling and multi-scale feature grouping.Advances in Neural Information Processing Systems, 36:30726–30737, 2023
2023
-
[21]
Tracking by natural language specification
Zhenyang Li, Ran Tao, Efstratios Gavves, Cees GM Snoek, and Arnold WM Smeulders. Tracking by natural language specification. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6495–6503, 2017
2017
-
[22]
Towards more flexible and accurate object tracking with natural language: Algorithms and benchmark
Xiao Wang, Xiujun Shu, Zhipeng Zhang, Bo Jiang, Yaowei Wang, Yonghong Tian, and Feng Wu. Towards more flexible and accurate object tracking with natural language: Algorithms and benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13763–13773, 2021. 11
2021
-
[23]
Joint visual grounding and tracking with natural language specification
Li Zhou, Zikun Zhou, Kaige Mao, and Zhenyu He. Joint visual grounding and tracking with natural language specification. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23151–23160, 2023
2023
-
[24]
Divert more attention to vision- language tracking
Mingzhe Guo, Zhipeng Zhang, Heng Fan, and Liping Jing. Divert more attention to vision- language tracking. InAdvances in Neural Information Processing Systems
-
[25]
R1-track: Direct application of mllms to visual object tracking via reinforcement learning, 2025
Biao Wang, Wenwen Li, and Jiawei Ge. R1-track: Direct application of mllms to visual object tracking via reinforcement learning, 2025
2025
-
[26]
Jiawei Ge, Jiuxin Cao, Xiangmei Chen, Xuelin Zhu, Weijia Liu, Chang Liu, Kun Wang, and Bo Liu. Beyond visual cues: Synchronously exploring target-centric semantics for vision- language tracking.ACM Transactions on Multimedia Computing, Communications and Appli- cations, 21(5):1–21, 2025
2025
-
[27]
ikun: Speak to trackers without retraining
Yunhao Du, Cheng Lei, Zhicheng Zhao, and Fei Su. ikun: Speak to trackers without retraining. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19135–19144, 2024
2024
-
[28]
Lamot: Language-guided multi-object tracking
Yunhao Li, Xiaoqiong Liu, Luke Liu, Heng Fan, and Libo Zhang. Lamot: Language-guided multi-object tracking. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 6816–6822. IEEE, 2025
2025
-
[29]
Language decoupling with fine-grained knowledge guidance for referring multi-object tracking
Guangyao Li, Siping Zhuang, Yajun Jian, Yan Yan, and Hanzi Wang. Language decoupling with fine-grained knowledge guidance for referring multi-object tracking. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 23626–23635, 2025
2025
-
[30]
Temporal-enhanced multimodal transformer for referring multi-object tracking and segmentation.IEEE Transactions on Circuits and Systems for Video Technology, 2025
Changcheng Xiao, Qiong Cao, Yujie Zhong, Xiang Zhang, Tao Wang, Canqun Yang, and Long Lan. Temporal-enhanced multimodal transformer for referring multi-object tracking and segmentation.IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[31]
Cgatracker: Correlation-aware graph alignment for referring multi-object tracking.IEEE Transactions on Circuits and Systems for Video Technology, 2025
Siping Zhuang, Guangyao Li, Qiangqiang Wu, Yang Lu, Hai-Miao Hu, and Hanzi Wang. Cgatracker: Correlation-aware graph alignment for referring multi-object tracking.IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[32]
Cognitive disentanglement for referring multi-object tracking.Information Fusion, page 103349, 2025
Shaofeng Liang, Runwei Guan, Wangwang Lian, Daizong Liu, Xiaolou Sun, Dongming Wu, Yutao Yue, Weiping Ding, and Hui Xiong. Cognitive disentanglement for referring multi-object tracking.Information Fusion, page 103349, 2025
2025
-
[33]
Visual-linguistic feature alignment with semantic and kinematic guidance for referring multi-object tracking.IEEE Transactions on Multimedia, 2025
Yizhe Li, Sanping Zhou, Zheng Qin, and Le Wang. Visual-linguistic feature alignment with semantic and kinematic guidance for referring multi-object tracking.IEEE Transactions on Multimedia, 2025
2025
-
[34]
Cheng-Yen Yang, Hsiang-Wei Huang, Wenhao Chai, Zhongyu Jiang, and Jenq-Neng Hwang. Samurai: Adapting segment anything model for zero-shot visual tracking with motion-aware memory.arXiv preprint arXiv:2411.11922, 2024
-
[35]
Sam2long: Enhancing sam 2 for long video segmentation with a training-free memory tree
Shuangrui Ding, Rui Qian, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Yuwei Guo, Dahua Lin, and Jiaqi Wang. Sam2long: Enhancing sam 2 for long video segmentation with a training-free memory tree. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13614–13624, 2025
2025
-
[36]
Sam2mot: A novel paradigm of multi-object tracking by segmentation,
Junjie Jiang, Zelin Wang, Manqi Zhao, Yin Li, and DongSheng Jiang. Sam2mot: A novel paradigm of multi-object tracking by segmentation.arXiv preprint arXiv:2504.04519, 2025
-
[37]
Omni-scale feature learning for person re-identification
Kaiyang Zhou, Yongxin Yang, Andrea Cavallaro, and Tao Xiang. Omni-scale feature learning for person re-identification. InProceedings of the IEEE/CVF international conference on computer vision, pages 3702–3712, 2019
2019
-
[38]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 12
work page internal anchor Pith review arXiv 2025
-
[39]
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. InInternational conference on machine learning, pages 2790–2799. PMLR, 2019
2019
-
[40]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[41]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review arXiv 1907
-
[42]
Towards unified text-based person retrieval: A large-scale multi-attribute and language search benchmark
Shuyu Yang, Yinan Zhou, Zhedong Zheng, Yaxiong Wang, Li Zhu, and Yujiao Wu. Towards unified text-based person retrieval: A large-scale multi-attribute and language search benchmark. InProceedings of the 31st ACM international conference on multimedia, pages 4492–4501, 2023
2023
-
[43]
Urvos: Unified referring video object segmentation network with a large-scale benchmark
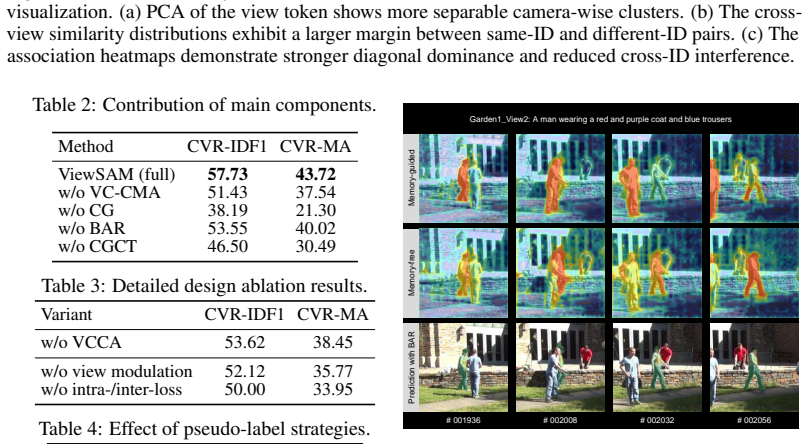
Seonguk Seo, Joon-Young Lee, and Bohyung Han. Urvos: Unified referring video object segmentation network with a large-scale benchmark. InEuropean conference on computer vision, pages 208–223. Springer, 2020. A Qualitative Results for Comparing with SOTAs To provide intuitive insights beyond quantitative comparisons, we present qualitative results of ViewS...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.