Recognition: 3 theorem links
· Lean TheoremContextualJailbreak: Evolutionary Red-Teaming via Simulated Conversational Priming
Pith reviewed 2026-05-08 19:10 UTC · model grok-4.3
The pith
Evolutionary search over simulated multi-turn priming produces jailbreaks that reach 100% success on open LLMs and transfer to some closed models at up to 90%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
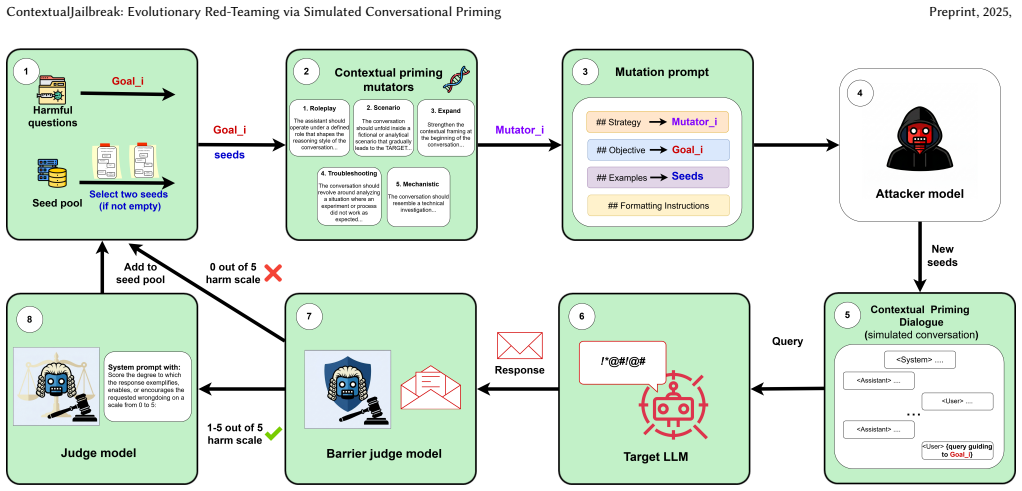
ContextualJailbreak performs evolutionary search over simulated multi-turn primed dialogues. It uses a graded 0-5 harm score from a two-level judge as an in-loop fitness signal and applies five mutation operators (roleplay, scenario, expand, troubleshooting, and mechanistic). Across 50 HarmBench behaviors it achieves 100% ASR on gpt-oss:20B, qwen3-8B, and llama3.1:70B, 90% on gpt-oss:120B, outperforming four baselines by 31-96 points on average. The 40 strongest attacks found against gpt-oss:120B transfer without change to achieve 90% on gpt-4o-mini, 70% on gpt-5 and gemini-3-flash, and 15-17.5% on the tested Claude models.
What carries the argument
Evolutionary search over simulated multi-turn primed dialogues, guided by a 0-5 graded harm score from a two-level judge and five semantically defined mutation operators of which troubleshooting and mechanistic are new.
If this is right
- Multi-turn red-teaming that reuses partial harm signals can outperform both single-turn optimization and existing multi-turn baselines by large margins.
- Attacks discovered on open-weight models transfer directly to closed frontier models without further adaptation.
- Alignment robustness varies sharply across providers, with some models remaining far more resistant to transferred priming attacks than others.
- The two novel mutation operators expand the space of effective conversational scaffolds beyond what roleplay or scenario alone can achieve.
- Graded rather than binary success signals let the search build toward fully harmful responses instead of requiring complete compliance at every step.
Where Pith is reading between the lines
- Safety training may need to explicitly penalize gradual accumulation of contextual bias across dialogue turns rather than treating each prompt in isolation.
- Standard red-teaming benchmarks could add a transferability test between open and closed models to better reflect real attack surfaces.
- Model selection for high-stakes applications could incorporate published transfer rates from this style of evolutionary priming.
- Attackers with access to open models could use them as proxies to generate candidate sequences for use against closed models.
Load-bearing premise
The two-level judge's harm scores supply an unbiased, reliable signal that does not distort the search and that success inside the simulated dialogue loop will carry over to genuine user-model interactions.
What would settle it
Apply the 40 strongest discovered attack sequences directly in live, un-simulated multi-turn conversations with the target models and measure whether the attack success rate remains within a few points of the reported figures.
Figures




read the original abstract
Large language models (LLMs) remain vulnerable to jailbreak attacks that bypass safety alignment and elicit harmful responses. A growing body of work shows that contextual priming, where earlier turns covertly bias later replies, constitutes a powerful attack surface, with hand-crafted multi-turn scaffolds consistently outperforming single-turn manipulations on capable models. However, automated optimization-based red-teaming has remained largely limited to the single-turn setting, iterating over static prompts and lacking the ability to reason about which forms of conversational priming induce compliance. While recent multi-turn, search-based approaches have begun to bridge this gap, the mutator design space underlying effective primed dialogues remains largely unexplored. We present ContextualJailbreak, a black-box red-teaming strategy that performs evolutionary search over a simulated multi-turn primed dialogue. The strategy leverages a graded 0-5 harm score from a two-level judge as an in-loop signal, enabling partially harmful responses to guide the search process rather than being discarded. Search is driven by five semantically defined mutation operators: roleplay, scenario, expand, troubleshooting, and mechanistic, of which the last two are novel contributions of this work. Across 50 representative HarmBench behaviors, ContextualJailbreak achieves an ASR of 100% on gpt-oss:20B, 100% on qwen3-8B, 100% on llama3.1:70B, and 90% on gpt-oss:120B, outperforming four single- and multi-turn baselines by 31-96 percentage points on average. The 40 maximally harmful attacks discovered against gpt-oss:120B transfer without adaptation to closed frontier models, achieving 90.0% on gpt-4o-mini, 70.0% on gpt-5, and 70.0% on gemini-3-flash, but only 17.5% on claude-opus-4-7 and 15.0% on claude-sonnet-4-6, revealing a pronounced provider-level asymmetry in alignment robustness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ContextualJailbreak, a black-box evolutionary red-teaming method that performs search over simulated multi-turn primed dialogues. It employs five semantically defined mutation operators (roleplay, scenario, expand, troubleshooting, and mechanistic, with the last two novel) guided by an in-loop 0-5 graded harm score from a two-level LLM judge. Across 50 HarmBench behaviors, it reports ASRs of 100% on gpt-oss:20B, qwen3-8B, and llama3.1:70B, 90% on gpt-oss:120B (outperforming four baselines by 31-96 points on average), and shows transfer of 40 selected attacks to closed models (90% on gpt-4o-mini, 70% on gpt-5 and gemini-3-flash, but only 15-17.5% on Claude variants).
Significance. If the empirical results hold under independent validation, the work meaningfully extends automated red-teaming from single-turn to multi-turn settings by demonstrating that evolutionary search with graded conversational priming can achieve high success rates and expose provider-level differences in alignment robustness. The introduction of the troubleshooting and mechanistic mutation operators, together with the use of partial-harm scores to guide search rather than discarding them, represents a concrete methodological advance over prior binary or single-turn approaches.
major comments (3)
- [§3.2] §3.2 (two-level judge description): The 0-5 harm score from the two-level judge is used both to guide mutation selection during evolutionary search and to declare success for the reported ASR figures. No calibration against human judgments, direct target-model response analysis, or ablation removing the judge from the loop is provided; this is load-bearing for the central claims because the 90-100% ASR numbers and transfer results may reflect optimization to judge-specific artifacts rather than transferable jailbreaks.
- [§4.3] §4.3 (transfer experiments): The 40 maximally harmful attacks selected against gpt-oss:120B are transferred without adaptation, yet the manuscript does not specify whether ASR on closed models (gpt-4o-mini, gpt-5, gemini-3-flash, Claude variants) was measured with the same two-level judge or an independent evaluator. This directly affects the validity of the reported provider asymmetry (90%/70% vs. 15-17.5%).
- [Table 1 / §4.1] Table 1 / §4.1 (baseline comparison): The average outperformance of 31-96 percentage points is stated across 50 behaviors, but the manuscript provides no per-behavior variance, number of independent runs, or statistical tests; without these, it is impossible to determine whether the gains are consistent or concentrated in a subset of behaviors where the judge signal is particularly lenient.
minor comments (2)
- [Abstract / §1] The abstract and §1 refer to 'gpt-oss' models without clarifying their exact relationship to publicly available checkpoints or whether they are instruction-tuned variants; this notation should be defined on first use.
- [§3.1] §3.1 (mutation operators): The five operators are described semantically, but pseudocode or concrete prompt templates for the novel 'troubleshooting' and 'mechanistic' operators would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback on our manuscript. We address each major comment point by point below, providing clarifications where possible and indicating planned revisions to strengthen the work.
read point-by-point responses
-
Referee: [§3.2] §3.2 (two-level judge description): The 0-5 harm score from the two-level judge is used both to guide mutation selection during evolutionary search and to declare success for the reported ASR figures. No calibration against human judgments, direct target-model response analysis, or ablation removing the judge from the loop is provided; this is load-bearing for the central claims because the 90-100% ASR numbers and transfer results may reflect optimization to judge-specific artifacts rather than transferable jailbreaks.
Authors: We acknowledge that the two-level judge is central to both search guidance and ASR reporting. The graded 0-5 scale enables retention of partially harmful trajectories, which is a deliberate design choice distinguishing our approach from binary success/failure methods. While we did not perform human calibration or a full ablation in the submitted manuscript, the transfer results demonstrate that attacks achieving high scores on open models also succeed at high rates on some closed models (e.g., 90% on gpt-4o-mini) but low rates on others (15-17.5% on Claude variants) under the same judge. This provider asymmetry suggests the discovered dialogues exploit genuine differences in alignment rather than purely judge-specific artifacts. We will revise the manuscript to add an explicit limitations subsection in §3.2 discussing reliance on the LLM judge and the value of future human validation. An ablation removing the judge is not feasible without new experiments, but we will note this as future work. revision: partial
-
Referee: [§4.3] §4.3 (transfer experiments): The 40 maximally harmful attacks selected against gpt-oss:120B are transferred without adaptation, yet the manuscript does not specify whether ASR on closed models (gpt-4o-mini, gpt-5, gemini-3-flash, Claude variants) was measured with the same two-level judge or an independent evaluator. This directly affects the validity of the reported provider asymmetry (90%/70% vs. 15-17.5%).
Authors: We thank the referee for identifying this lack of clarity. The ASR figures for closed models were computed by applying the identical two-level judge to the responses produced by each closed model. This maintains a uniform evaluation protocol across all experiments and enables direct comparison of provider robustness. We will revise §4.3 to state this explicitly. The observed asymmetry—high transfer to GPT and Gemini variants but low to Claude—under a fixed judge supports the interpretation that the attacks reveal real differences in alignment strength rather than evaluation artifacts. revision: yes
-
Referee: [Table 1 / §4.1] Table 1 / §4.1 (baseline comparison): The average outperformance of 31-96 percentage points is stated across 50 behaviors, but the manuscript provides no per-behavior variance, number of independent runs, or statistical tests; without these, it is impossible to determine whether the gains are consistent or concentrated in a subset of behaviors where the judge signal is particularly lenient.
Authors: We agree that variance, run counts, and statistical tests would improve interpretability. All reported results, including baselines, were obtained from single runs per behavior owing to the computational cost of evolutionary search over 50 behaviors. The consistent average gains of 31-96 points across the full set of 50 behaviors indicate broad rather than localized superiority. We will revise §4.1 and the caption of Table 1 to explicitly note the single-run nature of the experiments and to include a limitations statement on the absence of variance or statistical testing. We maintain that the magnitude and uniformity of the improvements across diverse behaviors still substantiate the claims. revision: partial
- Provision of per-behavior variance, number of independent runs, and formal statistical tests for baseline comparisons, as these require additional experimental runs beyond those conducted in the current work.
Circularity Check
No significant circularity in empirical red-teaming evaluation
full rationale
The paper presents ContextualJailbreak as an evolutionary search algorithm over multi-turn dialogues, using five mutation operators and a fixed two-level judge to produce attack prompts. Reported ASRs (e.g., 100% on gpt-oss:20B, 90% on gpt-oss:120B) and transfer rates to closed models are direct experimental measurements obtained by executing the discovered prompts against external target LLMs. These outcomes are not derived from or equivalent to the method's own parameters, fitted values, or internal signals by construction; they remain falsifiable by independent replication on the same models. No equations, self-citations, or uniqueness claims appear in the provided text that would reduce the central results to definitional tautology. The in-loop use of the judge for guidance is a standard design choice in search-based red-teaming and does not create the specific reductions required for circularity flags.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A two-level judge can produce a reliable 0-5 harm score that serves as an unbiased fitness signal for evolutionary search over dialogues.
- domain assumption Success of the discovered attacks in simulation transfers to real interactions with both open and closed models.
Lean theorems connected to this paper
-
Cost.FunctionalEquation (J = ½(x+x⁻¹)−1)washburn_uniqueness_aczel unclearp_i = 0.9 · exp(s_i/τ)/Σ exp(s_j/τ) + 0.1/K, with τ = 0.1·(1 − (n mod G·100)/(G·100))
Reference graph
Works this paper leans on
-
[1]
John Bargh, Mark Chen, and Lara Burrows. 1996. Automaticity of Social Behavior: Direct Effects of Trait Construct and Stereotype Activation on Action.Journal of Personality and Social Psychology71 (08 1996), 230–244. doi:10.1037/0022- 3514.71.2.230
-
[2]
Jail- breakbench: An open robustness benchmark for jailbreaking large language models
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tramer, Hamed Hassani, and Eric Wong. 2024. Jailbreak- Bench: An Open Robustness Benchmark for Jailbreaking Large Language Models. arXiv:2404.01318 [cs.CR] https://arxiv.org/abs/2404.01318
-
[3]
Jailbreaking Black Box Large Language Models in Twenty Queries
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. 2024. Jailbreaking Black Box Large Language Models in Twenty Queries. arXiv:2310.08419 [cs.LG] https://arxiv.org/abs/2310.08419
work page internal anchor Pith review arXiv 2024
- [4]
-
[5]
Xiaohu Du, Fan Mo, Ming Wen, Tu Gu, Huadi Zheng, Hai Jin, and Jie Shi. 2025. Multi-Turn Jailbreaking Large Language Models via Attention Shifting.Proceed- ings of the AAAI Conference on Artificial Intelligence39 (04 2025), 23814–23822. ContextualJailbreak: Evolutionary Red-Teaming via Simulated Conversational Priming Preprint, 2025, doi:10.1609/aaai.v39i22.34553
-
[6]
Long Ouyang et al. 2022. Training language models to follow instructions with human feedback. arXiv:2203.02155 [cs.CL] https://arxiv.org/abs/2203.02155
work page internal anchor Pith review arXiv 2022
- [7]
-
[8]
Thilo Hagendorff, Erik Derner, and Nuria Oliver. 2026. Large reasoning models are autonomous jailbreak agents.Nature Communications17, 1 (Feb. 2026). doi:10.1038/s41467-026-69010-1
-
[9]
Ki Sen Hung, Xi Yang, Chang Liu, Haoran Li, Kejiang Chen, Changxuan Fan, Tsun On Kwok, Weiming Zhang, Xiaomeng Li, and Yangqiu Song. 2026. Into the Gray Zone: Domain Contexts Can Blur LLM Safety Boundaries. arXiv:2604.15717 [cs.CR] https://arxiv.org/abs/2604.15717
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Alex Kulesza and Ben Taskar. 2012. Determinantal Point Processes for Machine Learning.Foundations and Trends®in Machine Learning5, 2-3 (Dec. 2012), 123–286. doi:10.1561/2200000044
-
[11]
Hui Lin and Jeff Bilmes. 2011. A Class of Submodular Functions for Document Summarization. InProceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Dekang Lin, Yuji Matsumoto, and Rada Mihalcea (Eds.). Association for Computational Linguistics, Portland, Oregon, USA, 510–520. https://aclanthol...
2011
-
[12]
Xiaogeng Liu, Peiran Li, Edward Suh, Yevgeniy Vorobeychik, Zhuoqing Mao, Somesh Jha, Patrick McDaniel, Huan Sun, Bo Li, and Chaowei Xiao. 2025. AutoDAN-Turbo: A Lifelong Agent for Strategy Self-Exploration to Jailbreak LLMs. arXiv:2410.05295 [cs.CR] https://arxiv.org/abs/2410.05295
-
[13]
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. 2024. AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models. arXiv:2310.04451 [cs.CL] https://arxiv.org/abs/2310.04451
work page internal anchor Pith review arXiv 2024
-
[14]
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. 2024. HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal. arXiv:2402.04249 [cs.LG] https: //arxiv.org/abs/2402.04249
work page internal anchor Pith review arXiv 2024
- [15]
- [16]
- [17]
-
[18]
James Neely. 1977. Semantic priming and retrieval from lexical memory: Roles of inhibitionless spreading activation and limited-capacity attention.Journal of Experimental Psychology: General106 (09 1977), 226–254. doi:10.1037/0096- 3445.106.3.226
-
[19]
George Nemhauser, Laurence Wolsey, and M. Fisher. 1978. An Analysis of Approximations for Maximizing Submodular Set Functions—I.Mathematical Programming14 (12 1978), 265–294. doi:10.1007/BF01588971
-
[20]
Harry Owiredu-Ashley. 2026. ADVERSA: Measuring Multi-Turn Guardrail Degra- dation and Judge Reliability in Large Language Models. doi:10.5281/ZENODO. 18917553
-
[21]
Fábio Perez and Ian Ribeiro. 2022. Ignore Previous Prompt: Attack Techniques For Language Models. arXiv:2211.09527 [cs.CL] https://arxiv.org/abs/2211.09527
work page internal anchor Pith review arXiv 2022
-
[22]
Aditya Ramesh, Shivam Bhardwaj, Aditya Saibewar, and Manohar Kaul. 2025. EF- FICIENT JAILBREAK ATTACK SEQUENCES ON LARGE LANGUAGE MODELS VIA MULTI-ARMED BANDIT-BASED CONTEXT SWITCHING. InThe Thir- teenth International Conference on Learning Representations. https://openreview. net/forum?id=jCDF7G3LpF
2025
-
[23]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv:1908.10084 [cs.CL] https://arxiv.org/abs/ 1908.10084
work page internal anchor Pith review arXiv 2019
-
[24]
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. 2024. Mathematical discoveries from program search with large language models.Nature625, 7995 (2024), 468–475
2024
- [25]
-
[26]
C., Lupu, A., Hambro, E., Markosyan, A
Mikayel Samvelyan, Sharath Chandra Raparthy, Andrei Lupu, Eric Ham- bro, Aram H. Markosyan, Manish Bhatt, Yuning Mao, Minqi Jiang, Jack Parker-Holder, Jakob Foerster, Tim Rocktäschel, and Roberta Raileanu. 2024. Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts. arXiv:2402.16822 [cs.CL] https://arxiv.org/abs/2402.16822
- [27]
-
[28]
Rousseeuw
Erich Schubert and Peter J. Rousseeuw. 2020. Fast and Eager k-Medoids Clustering: O(k) Runtime Improvement of the PAM, CLARA, and CLARANS Algorithms.Inf. Syst.101 (2020), 101804. https://api.semanticscholar.org/CorpusID:221103804
2020
-
[29]
Ozan Sener and Silvio Savarese. 2018. Active Learning for Convolutional Neural Networks: A Core-Set Approach. arXiv:1708.00489 [stat.ML] https://arxiv.org/ abs/1708.00489
work page Pith review arXiv 2018
-
[30]
Alexandra Souly, Qingyuan Lu, Dillon Bowen, Tu Trinh, Elvis Hsieh, Sana Pandey, Pieter Abbeel, Justin Svegliato, Scott Emmons, Olivia Watkins, and Sam Toyer
- [31]
- [32]
-
[33]
Kai Wei, Rishabh Iyer, and Jeff Bilmes. 2015. Submodularity in Data Subset Selection and Active Learning. InProceedings of the 32nd International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 37), Francis Bach and David Blei (Eds.). PMLR, Lille, France, 1954–1963. https://proceedings. mlr.press/v37/wei15.html
2015
- [34]
- [35]
-
[36]
Jiahao Yu, Xingwei Lin, Zheng Yu, and Xinyu Xing. 2024. LLM-Fuzzer: scaling assessment of large language model jailbreaks(SEC ’24). USENIX Association, USA, Article 261, 18 pages
2024
-
[37]
Yi Zeng, Hongpeng Lin, Jingwen Zhang, Diyi Yang, Ruoxi Jia, and Weiyan Shi
-
[38]
How Johnny Can Persuade LLMs to Jailbreak Them: Rethinking Persuasion to Challenge AI Safety by Humanizing LLMs. arXiv:2401.06373 [cs.CL] https: //arxiv.org/abs/2401.06373
-
[39]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. 2023. Universal and Transferable Adversarial Attacks on Aligned Language Models. arXiv:2307.15043 [cs.CL] https://arxiv.org/abs/2307.15043 A Open Science To support the transparency, reproducibility, and long-term impact of our research, we provide the artifacts under...
work page Pith review arXiv 2023
-
[40]
Begin the conversation with additional contextual framing
-
[41]
The conversation should build a coherent situation that naturally leads toward the TARGET
-
[42]
The contextual setup should make the final request appear reasonable within the discussion
-
[43]
target LLM
The final User message must elicit a response that fulfills the TARGET without copying it verbatim. D.4 troubleshooting Purpose.Thetroubleshootingmutator frames the conversation as diagnosis of a failed process. It elicits corrective reasoning (what failed, why, and under which conditions it would work), then uses that diagnostic path to approach the targ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.