Recognition: unknown
Private Speech Classification without Collapse: Stabilized DP Training and Offline Distillation
Pith reviewed 2026-05-08 02:43 UTC · model grok-4.3
The pith
A two-stage protocol trains a possibly multimodal DP teacher on private speech data then distills it offline to a released audio-only student on disjoint auxiliary data to avoid collapse under strong privacy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
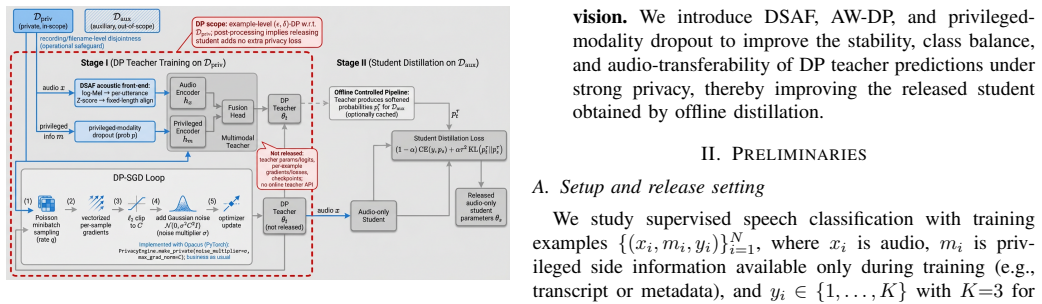
The central claim is that training a DP teacher on the private dataset followed by offline distillation of its non-collapsed probability outputs to an audio-only student on recording-disjoint auxiliary data yields a released model that retains useful performance on imbalanced speech tasks, whereas direct DP-SGD training of an audio-only model under the same privacy budget collapses. The DP guarantee applies solely to the private dataset; the auxiliary dataset carries no DP claim, and release of only the student satisfies post-processing.
What carries the argument
The two-stage protocol of DP teacher training (with DSAF front-end, AW-DP reweighting, and modality dropout) followed by one-shot offline distillation using teacher probability outputs on disjoint auxiliary data.
If this is right
- The released student satisfies differential privacy with respect to the private dataset by post-processing, without any DP claim needed for the auxiliary data.
- Macro-F1 and balanced accuracy remain high on imbalanced speech tasks because the teacher avoids collapse and transfers its outputs before release.
- Privileged modalities can be used only during teacher training and are dropped at inference without affecting the privacy guarantee on the final audio-only model.
- The four bottlenecks of optimization instability, minority-class erosion, modality over-reliance, and train-deploy mismatch are addressed simultaneously by the combined stabilizing and distillation steps.
Where Pith is reading between the lines
- The same teacher-distillation structure could be tested on other imbalanced classification tasks where multimodal data exists only at development time.
- If the auxiliary dataset is sufficiently large and diverse, the distilled student may retain finer probability calibration than direct private training even after the modality drop.
- Reducing collapse through reweighting and front-end stabilization might lower the noise scale required for a given privacy budget in related audio or multimodal settings.
Load-bearing premise
The auxiliary dataset must remain recording-disjoint from the private data and the DP teacher must produce non-collapsed probability outputs that still supply useful supervision to the audio-only student despite the modality mismatch.
What would settle it
An experiment in which the distilled audio-only student is evaluated on a held-out test set and shows no improvement in macro-F1 or minority-class recall compared with a directly trained DP audio-only baseline under identical privacy budget and data imbalance.
Figures

read the original abstract
We study example-level private supervised speech classification under a practical release constraint: training may access privileged side information, but the released model must be audio-only. This setting is important because speech systems can often exploit richer side information during development, whereas deployment and release require a lightweight unimodal model with auditable privacy guarantees. Using DP-SGD on the private dataset $D_{\text{priv}}$, we identify a strong-privacy failure mode ($\epsilon \le 1$) on imbalanced tasks, where training may collapse to a near single-class predictor, a phenomenon that overall accuracy can obscure. We therefore emphasize Macro-F1, balanced accuracy, and a simple collapse diagnostic. This failure is especially problematic in our release setting because a collapsed private teacher cannot provide useful supervision for the downstream audio-only student. To address this setting under strong privacy, we propose a two-stage protocol: (i) train a (possibly multimodal) DP teacher on $D_{\text{priv}}$, and (ii) distill an audio-only student on a fixed, recording-disjoint auxiliary dataset $D_{\text{aux}}$ using one-shot offline teacher probability outputs, releasing only the student. The DP guarantee applies only to $D_{\text{priv}}$; we make no DP claim for $D_{\text{aux}}$, and privacy of the released student with respect to $D_{\text{priv}}$ follows by post-processing. We frame this setting as involving four coupled bottlenecks: speech-induced optimization instability under DP-SGD, minority-class erosion under clipping and noise, teacher over-reliance on privileged modalities unavailable at deployment, and train--deploy modality mismatch. We address them with a DP-stabilizing acoustic front-end (DSAF), minibatch-adaptive bounded loss reweighting (AW-DP), privileged-modality dropout, and offline teacher-to-student distillation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a two-stage protocol for example-level differentially private supervised speech classification under a release constraint requiring an audio-only model. A (possibly multimodal) DP teacher is trained on private data D_priv using DP-SGD, stabilized against collapse via a DP-stabilizing acoustic front-end (DSAF), minibatch-adaptive bounded loss reweighting (AW-DP), and privileged-modality dropout; one-shot offline distillation then transfers teacher probability outputs to an audio-only student on a fixed, recording-disjoint auxiliary dataset D_aux. Only the student is released, with privacy w.r.t. D_priv following by post-processing. The work identifies collapse to near-single-class predictors under strong privacy (ε ≤ 1) on imbalanced tasks as a failure mode obscured by accuracy, and emphasizes Macro-F1, balanced accuracy, and a collapse diagnostic.
Significance. If the stabilization techniques prove effective, the protocol could enable practical release of private audio-only models while exploiting privileged modalities only during training, addressing a realistic deployment constraint in speech systems. The clear framing of four coupled bottlenecks (optimization instability, minority-class erosion, teacher over-reliance on privileged modalities, and modality mismatch) and their mapping to specific components is a strength, as is the reliance on standard post-processing for the privacy guarantee. Credit is due for highlighting how overall accuracy can mask collapse and for insisting on Macro-F1. However, significance remains prospective because the manuscript supplies no empirical results.
major comments (2)
- [Abstract] Abstract and protocol description: the central claim is that DSAF, AW-DP, and privileged-modality dropout prevent collapse and yield useful supervision for the audio-only student despite modality mismatch, yet the manuscript provides no experimental results, ablation studies, quantitative Macro-F1 scores, collapse diagnostics, or comparisons against vanilla DP-SGD baselines. This is load-bearing because the proposal's value rests on these techniques actually addressing the identified failure mode.
- [Protocol and method description] Description of the four bottlenecks and their remedies: while the mapping of components to bottlenecks is logically presented, no analysis or evidence is given showing, for example, that AW-DP specifically mitigates minority-class erosion under clipping and noise or that privileged-modality dropout reduces teacher over-reliance without harming the distillation signal.
minor comments (2)
- The acronyms DSAF and AW-DP should be expanded at first use for readers unfamiliar with the specific techniques.
- Clarify whether the auxiliary dataset D_aux is assumed to be public or merely non-private; the privacy claim is unaffected either way, but the distinction affects practical deployment.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the practical importance of the release-constrained private speech setting as well as the collapse failure mode. We agree that the manuscript's central claims require empirical support and that the logical mapping of bottlenecks to remedies needs additional analysis. We will revise the manuscript to address these points directly.
read point-by-point responses
-
Referee: [Abstract] Abstract and protocol description: the central claim is that DSAF, AW-DP, and privileged-modality dropout prevent collapse and yield useful supervision for the audio-only student despite modality mismatch, yet the manuscript provides no experimental results, ablation studies, quantitative Macro-F1 scores, collapse diagnostics, or comparisons against vanilla DP-SGD baselines. This is load-bearing because the proposal's value rests on these techniques actually addressing the identified failure mode.
Authors: We agree that the effectiveness claims are load-bearing and that the initial manuscript lacks the necessary empirical validation. The submission focused on problem identification, the four-bottleneck framing, and the protocol description. In the revised version we will add a full experimental section containing: results on imbalanced speech tasks under strong privacy (ε ≤ 1) using Macro-F1, balanced accuracy, and the collapse diagnostic; direct comparisons to vanilla DP-SGD; ablations that isolate DSAF, AW-DP, and privileged-modality dropout; and evaluation of the distilled audio-only student to confirm useful supervision despite modality mismatch. These additions will substantiate the protocol's value. revision: yes
-
Referee: [Protocol and method description] Description of the four bottlenecks and their remedies: while the mapping of components to bottlenecks is logically presented, no analysis or evidence is given showing, for example, that AW-DP specifically mitigates minority-class erosion under clipping and noise or that privileged-modality dropout reduces teacher over-reliance without harming the distillation signal.
Authors: We acknowledge that the current text presents a logical mapping without supporting analysis or evidence for the specific mechanisms. We will expand the method section with additional theoretical motivation for AW-DP's reweighting under clipping and noise, including how it counters minority-class erosion; discussion of privileged-modality dropout's effect on reducing over-reliance; and explicit consideration of any trade-offs with distillation signal quality. Where possible we will include illustrative analysis or preliminary diagnostics to ground each claim. revision: yes
Circularity Check
No significant circularity; protocol relies on standard DP post-processing and established distillation
full rationale
The paper's central contribution is a two-stage protocol (DP teacher on D_priv followed by offline distillation to audio-only student on disjoint D_aux) whose privacy reduction is the standard post-processing theorem for DP, independent of the stabilization components. Bottlenecks are identified empirically and addressed by design choices (DSAF, AW-DP, modality dropout) without any derivation that equates outputs to inputs by construction, fitted parameters renamed as predictions, or load-bearing self-citations. No equations or claims reduce the claimed performance or privacy to quantities defined by the method itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Membership inference attacks against machine learning models,
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov, “Membership inference attacks against machine learning models,” in 2017 IEEE Symposium on Security and Privacy (SP). 2017, pp. 3–18, IEEE
2017
-
[2]
Model inversion attacks that exploit confidence information and basic coun- termeasures,
Matthew Fredrikson, Somesh Jha, and Thomas Ristenpart, “Model inversion attacks that exploit confidence information and basic coun- termeasures,” inProceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security (CCS). 2015, pp. 1322–1333, ACM
2015
-
[3]
Differential privacy,
Cynthia Dwork, “Differential privacy,” inProceedings of the 33rd International Colloquium on Automata, Languages and Programming (ICALP). 2006, vol. 4052 ofLNCS, pp. 1–12, Springer
2006
-
[4]
Differential privacy: A survey of results,
Cynthia Dwork, “Differential privacy: A survey of results,” inTheory and Applications of Models of Computation (TAMC). 2008, vol. 4978 ofLNCS, pp. 1–19, Springer
2008
-
[5]
Cynthia Dwork and Aaron Roth,The Algorithmic Foundations of Differential Privacy, Now Publishers Inc., 2014
2014
-
[6]
Deep learning with differential privacy,
Mart ´ın Abadi, Andy Chu, Ian Goodfellow, H. Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang, “Deep learning with differential privacy,” inProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (CCS). 2016, pp. 308–318, ACM
2016
-
[7]
Douglas O’Shaughnessy,Speech Communication: Human and Machine, Addison-Wesley, 1987
1987
-
[8]
Understanding gradient clipping in private SGD: A geometric perspective,
Xiaojing Chen, Stephen Z. Wu, and Mingyi Hong, “Understanding gradient clipping in private SGD: A geometric perspective,” inAdvances in Neural Information Processing Systems (NeurIPS), 2020, vol. 33, pp. 13773–13782
2020
-
[9]
Differentially private deep learning under skewed class distributions,
Cuong Tran, Minh Dinh, and Ferdinando Fioretto, “Differentially private deep learning under skewed class distributions,” inProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2021, vol. 35, pp. 9930–9938
2021
-
[10]
Differentially private learning with per-sample adaptive clipping,
Tianhao Xia, Shuo Shen, Shuyuan Yao, et al., “Differentially private learning with per-sample adaptive clipping,” inProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2023, vol. 37, pp. 10444– 10452
2023
-
[11]
DP-SGD-Global- Adapt-V2-S: Triad improvements of privacy, accuracy and fairness via step decay noise multiplier and step decay upper clipping threshold,
S. V . Chilukoti, M. I. Hossen, L. Shan, et al., “DP-SGD-Global- Adapt-V2-S: Triad improvements of privacy, accuracy and fairness via step decay noise multiplier and step decay upper clipping threshold,” Electronic Commerce Research and Applications, vol. 70, pp. 101476, 2025
2025
-
[12]
Common V oice: A massively-multilingual speech corpus,
Rosana Ardila, Megan Branson, Kelly Davis, Michael Henretty, Michael Kohler, Josh Meyer, Reuben Morais, Lindsay Saunders, Francis M. Tyers, and Gregor Weber, “Common V oice: A massively-multilingual speech corpus,” inProceedings of the 12th Language Resources and Evaluation Conference (LREC), 2020, pp. 4218–4222
2020
-
[13]
Mul- timodal machine learning: A survey and taxonomy,
Tadas Baltru ˇsaitis, Chaitanya Ahuja, and Louis-Philippe Morency, “Mul- timodal machine learning: A survey and taxonomy,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 41, no. 2, pp. 423– 443, 2019
2019
-
[14]
A new learning paradigm: Learning using privileged information,
Vladimir Vapnik and Akshay Vashist, “A new learning paradigm: Learning using privileged information,”Neural Networks, vol. 22, no. 5–6, pp. 544–557, 2009
2009
-
[15]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean, “Distilling the knowledge in a neural network,” arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review arXiv 2015
-
[16]
Unifying distillation and privileged information,
David Lopez-Paz, L ´eon Bottou, Bernhard Sch ¨olkopf, and Vladimir Vap- nik, “Unifying distillation and privileged information,” inInternational Conference on Learning Representations (ICLR), 2016
2016
-
[17]
R ´enyi differential privacy,
Ilya Mironov, “R ´enyi differential privacy,” in2017 IEEE 30th Computer Security Foundations Symposium (CSF), 2017, pp. 263–275
2017
-
[18]
Ashkan Yousefpour, Igor Shilov, Alexandre Sablayrolles, Davide Testug- gine, Karthik Prasad, Mani Malek, John Nguyen, Sayan Ghosh, Akash Bharadwaj, Jessica Zhao, Graham Cormode, and Ilya Mironov, “Opacus: User-friendly differential privacy library in pytorch,”arXiv preprint arXiv:2109.12298, 2021
-
[19]
Opacus: Train PyTorch models with differential privacy,
Meta Platforms, Inc., “Opacus: Train PyTorch models with differential privacy,” https://opacus.ai/, 2025, Accessed: 2025-12-26
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.