Recognition: unknown
Bolek: A Multimodal Language Model for Molecular Reasoning
Pith reviewed 2026-05-09 15:40 UTC · model grok-4.3
The pith
Injecting a molecular fingerprint embedding and training on feature-anchored reasoning chains turns a compact language model into a stronger performer on molecular classification tasks than its larger base model or a rival twice its size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Bolek is built by adding a Morgan fingerprint embedding to an instruction-tuned text decoder and fine-tuning first on alignment tasks such as molecule description and substructure detection, then on downstream binary classification using synthetic chains of thought that are explicitly tied to verifiable molecular features. The resulting model outperforms its base on all yes/no endpoints and most chain-of-thought endpoints, and it beats a larger rival model on most tasks while generating explanations that reference numerical descriptors far more frequently and with higher agreement to RDKit calculations.
What carries the argument
The Morgan fingerprint embedding injected into the text decoder, which supplies the model with direct structural information that its reasoning chains can cite and that remains verifiable against external chemical computation tools.
If this is right
- The model produces more auditable explanations because its reasoning steps reference concrete, computable molecular properties that chemists can verify independently.
- Performance gains appear on both seen and unseen TDC classification endpoints, and some ability to rank regression endpoints emerges without any regression training.
- Smaller models equipped this way can match or exceed larger general models on the targeted tasks while remaining compact enough for broader deployment.
- The same injection-plus-anchored-supervision recipe can be applied to other molecular endpoints beyond the fifteen binary tasks shown.
Where Pith is reading between the lines
- The method could be extended to other scientific modalities such as spectra or sequences where an embedding can be injected to ground language-model reasoning.
- Verified outputs from the model could be fed back to create higher-quality training data, potentially creating an iterative improvement loop.
- If the grounding holds across more diverse molecular libraries, the approach would lower the compute barrier for building trustworthy AI assistants in chemistry.
Load-bearing premise
The synthetic chains of thought used for supervision are both factually correct and sufficient to teach the model genuine molecular reasoning rather than mere pattern matching to the training tasks.
What would settle it
Run the model on a fresh set of molecules, extract the numerical descriptor values it cites in its chains of thought, and compare those values directly to independent calculations from chemical software; a high mismatch rate or a sharp drop in accuracy on molecules structurally distant from the training distribution would falsify the central claim.
Figures
read the original abstract
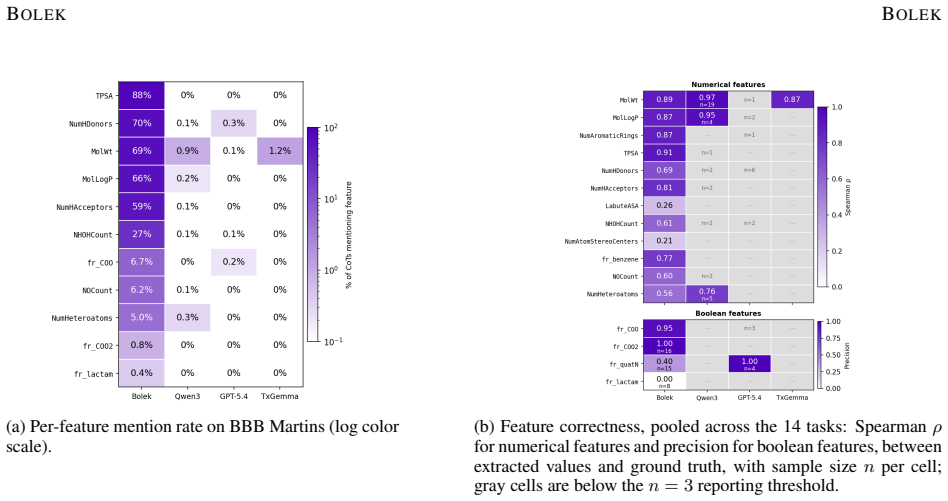
Molecular property models increasingly support high-stakes drug-discovery decisions, but their outputs are often difficult to audit: classical predictors return scores without rationale, while language models can produce fluent explanations weakly grounded in the input molecule. We introduce Bolek, a compact multimodal language model that grounds natural-language reasoning in molecular structure by injecting a Morgan fingerprint embedding into an instruction-tuned text decoder. Bolek is fine-tuned on molecular alignment tasks, including molecule description, RDKit descriptor prediction, and substructure detection, and on downstream reasoning over 15 TDC binary classification tasks using synthetic chains-of-thought anchored in concrete molecular features. Across these tasks, Bolek outperforms its Qwen3-4B-Instruct base on all endpoints in yes/no mode and on 13 of 15 in chain-of-thought mode, raising mean ROC/PR AUC from 0.55 to 0.76. It also outperforms TxGemma-9B-Chat on 13 of 15 binary classification tasks despite being less than half its size. Bolek's explanations are more grounded than those of the baseline LLMs: it cites numerical descriptors 10-100x more often per chain-of-thought, and the cited values agree strongly with RDKit for key descriptors such as TPSA, MolLogP, and MolWt (Spearman rho = 0.87-0.91). Generalisation extends beyond the training panel: on 15 unseen TDC classification endpoints, Bolek matches TxGemma on five, and it produces non-trivial rank correlations on three held-out regression endpoints despite never seeing downstream regression during training. These results suggest that targeted modality injection and reasoning supervision tied to verifiable molecular features can yield compact, auditable molecular reasoning models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Bolek, a compact multimodal language model that injects Morgan fingerprint embeddings into a Qwen3-4B-Instruct text decoder. It is fine-tuned on molecular alignment tasks (description, RDKit descriptor prediction, substructure detection) plus downstream binary classification on 15 TDC tasks using synthetic chains-of-thought anchored in molecular features. The paper claims Bolek outperforms its base model on all yes/no endpoints and 13/15 CoT endpoints (raising mean ROC/PR AUC from 0.55 to 0.76), beats the larger TxGemma-9B-Chat on 13/15 tasks, produces more grounded explanations (citing descriptors 10-100x more often with RDKit Spearman rho 0.87-0.91 on TPSA, MolLogP, MolWt), and generalizes to 15 unseen TDC endpoints plus non-trivial rank correlations on three held-out regression tasks.
Significance. If the performance gains and generalization are driven by the modality injection and feature-anchored supervision rather than pattern matching to the TDC distribution, Bolek offers a practical advance toward smaller, auditable molecular reasoning models. The explicit post-hoc verification of cited numerical descriptors against RDKit provides a concrete auditing mechanism that is stronger than typical LLM explanation claims in this domain. The size advantage (under half of TxGemma) and cross-task generalization without regression training are notable strengths that could support deployment in drug-discovery workflows where interpretability matters.
major comments (2)
- [§4 and §5] §4 (Methods) and §5 (Results): No ablation is reported that removes the synthetic CoT supervision while retaining the Morgan fingerprint injection and alignment tasks. This is load-bearing for the central claim that 'reasoning supervision tied to verifiable molecular features' drives the AUC gains (0.55 to 0.76) and outperformance on 13/15 tasks; without it, the improvements could be attributable to the embedding injection or alignment data alone.
- [§5.3] §5.3 (Generalization): The claim of generalization to 15 unseen TDC endpoints and three held-out regression tasks lacks quantification of molecular feature overlap (e.g., average Tanimoto similarity of Morgan fingerprints or shared substructures) between the 15 training endpoints and the held-out sets. This is needed to distinguish transferable reasoning from shared descriptor distributions across the TDC panel.
minor comments (3)
- [§3] The description of the fingerprint embedding projection and fusion into the decoder (presumably in §3) would benefit from an explicit equation or diagram showing dimension matching and concatenation.
- [Tables 1-2] Table 1 or 2: clarify whether the reported ROC/PR AUC values are macro-averaged across the 15 tasks or per-task, and include standard deviations over multiple seeds.
- [Related Work] The related-work section should cite prior multimodal molecular models (e.g., MolT5, ChemLLM) to better situate the modality-injection approach.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to incorporate the suggested analyses.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Methods) and §5 (Results): No ablation is reported that removes the synthetic CoT supervision while retaining the Morgan fingerprint injection and alignment tasks. This is load-bearing for the central claim that 'reasoning supervision tied to verifiable molecular features' drives the AUC gains (0.55 to 0.76) and outperformance on 13/15 tasks; without it, the improvements could be attributable to the embedding injection or alignment data alone.
Authors: We agree that an ablation isolating the synthetic CoT supervision is important for attributing the performance gains specifically to the feature-anchored reasoning supervision rather than the modality injection or alignment tasks alone. Our current evidence includes consistent gains in both yes/no and CoT evaluation modes, plus substantially improved explanation grounding (10-100x more descriptor citations with RDKit Spearman correlations of 0.87-0.91). To directly address the concern, we will train and evaluate the requested ablation variant (Morgan injection + alignment tasks only, without CoT) and report the comparative AUC and grounding metrics in the revised manuscript. revision: yes
-
Referee: [§5.3] §5.3 (Generalization): The claim of generalization to 15 unseen TDC endpoints and three held-out regression tasks lacks quantification of molecular feature overlap (e.g., average Tanimoto similarity of Morgan fingerprints or shared substructures) between the 15 training endpoints and the held-out sets. This is needed to distinguish transferable reasoning from shared descriptor distributions across the TDC panel.
Authors: We agree that quantifying molecular feature overlap is necessary to strengthen the generalization claims. While the TDC panel spans diverse endpoints and the held-out tasks were excluded from training, we did not previously compute overlap metrics. In the revision we will add average Tanimoto similarity on Morgan fingerprints (radius 2, 2048 bits) and counts of shared substructures between the 15 training endpoints and the 15 unseen classification plus three regression held-out sets, allowing readers to better assess transferable reasoning versus distributional similarity. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central claims rest on empirical fine-tuning with synthetic CoTs followed by evaluation on held-out TDC endpoints and generalization to 15 unseen tasks, with external verification via RDKit agreement (rho 0.87-0.91) and baseline comparisons. No load-bearing step reduces by construction to the inputs: the reported AUC gains and outperformance are measured on data partitions not used in supervision, and no equations, self-citations, or ansatzes are invoked to force the results. The derivation chain is self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Morgan fingerprints plus RDKit-computed descriptors provide faithful and sufficient molecular features for reasoning supervision
Reference graph
Works this paper leans on
-
[1]
Zhenqin Wu, Bharath Ramsundar, Evan N. Feinberg, Joseph Gomes, Caleb Geniesse, Aneesh S. Pappu, Karl Leswing, and Vijay Pande. MoleculeNet: A benchmark for molecular machine learning.Chemical Science, 9 (2):513–530, 2018. doi: 10.1039/c7sc02664a
-
[2]
Coley, Cao Xiao, Jimeng Sun, and Marinka Zitnik
Kexin Huang, Tianfan Fu, Wenhao Gao, Yue Zhao, Yusuf Roohani, Jure Leskovec, Connor W. Coley, Cao Xiao, Jimeng Sun, and Marinka Zitnik. Therapeutics data commons: Machine learning datasets and tasks for drug discovery and development. InAdvances in Neural Information Processing Systems (NeurIPS) Track on Datasets and Benchmarks, 2021
2021
-
[3]
Kevin Yang, Kyle Swanson, Wengong Jin, Connor Coley, Philipp Eiden, Hua Gao, Angel Guzman-Perez, Timo- thy Hopper, Brian Kelley, Miriam Mathea, et al. Analyzing learned molecular representations for property predic- tion.Journal of Chemical Information and Modeling, 59(8):3370–3388, 2019. doi: 10.1021/acs.jcim.9b00237
-
[4]
Nicolaou, and Berton Earnshaw
Oscar Méndez-Lucio, Christos A. Nicolaou, and Berton Earnshaw. MolE: A foundation model for molec- ular graphs using disentangled attention.Nature Communications, 15(1):9431, 2024. doi: 10.1038/ s41467-024-53751-y
2024
-
[5]
José Jiménez-Luna, Francesca Grisoni, and Gisbert Schneider. Drug discovery with explainable artificial intelli- gence.Nature Machine Intelligence, 2(10):573–584, 2020. doi: 10.1038/s42256-020-00236-4
-
[6]
Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D
Andres M. Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D. White, and Philippe Schwaller. Aug- menting large language models with chemistry tools.Nature Machine Intelligence, 6(5):525–535, 2024. doi: 10.1038/s42256-024-00832-8
-
[7]
Autonomous chemical research with large language models
Daniil A. Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models.Nature, 624(7992):570–578, 2023. doi: 10.1038/s41586-023-06792-0
-
[9]
Extended-connectivity fingerprints
David Rogers and Mathew Hahn. Extended-connectivity fingerprints.Journal of Chemical Information and Modeling, 50(5):742–754, 2010. doi: 10.1021/ci100050t
-
[10]
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka
Zhaoping Xiong, Dingyan Wang, Xiaohong Liu, Feisheng Zhong, Xiaozhe Wan, Xutong Li, Zhaojun Li, Xi- aomin Luo, Kaixian Chen, Hualiang Jiang, and Mingyue Zheng. Pushing the boundaries of molecular rep- resentation for drug discovery with the graph attention mechanism.Journal of Medicinal Chemistry, 63(16): 8749–8760, 2020. doi: 10.1021/acs.jmedchem.9b00959
-
[11]
How powerful are graph neural networks? In International Conference on Learning Representations (ICLR), 2019
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? In International Conference on Learning Representations (ICLR), 2019
2019
-
[12]
Uni-Mol: A universal 3D molecular representation learning framework
Gengmo Zhou, Zhifeng Gao, Qiankun Ding, Hang Zheng, Hongteng Xu, Zhewei Wei, Linfeng Zhang, and Guolin Ke. Uni-Mol: A universal 3D molecular representation learning framework. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[13]
Chemllm: A chemical large language model.arXiv preprint arXiv:2402.06852, 2024
Di Zhang, Wei Liu, Qian Tan, Jingdan Chen, Hang Yan, Yuliang Yan, Jiatong Li, Weiran Huang, Xiangyu Yue, Wanli Ouyang, Dongzhan Zhou, Shufei Zhang, Mao Su, Han-Sen Zhong, and Yuqiang Li. Chemllm: A chemical large language model, 2024. URLhttps://arxiv.org/abs/2402.06852. 12 BOLEK BOLEK
-
[14]
Hao Li, He Cao, Bin Feng, Yanjun Shao, Xiangru Tang, Zhiyuan Yan, Li Yuan, Yonghong Tian, and Yu Li. Beyond chemical qa: Evaluating llm’s chemical reasoning with modular chemical operations, 2026. URL https://arxiv.org/abs/2505.21318
-
[15]
arXiv preprint arXiv:2402.09391 (2024)
Botao Yu, Frazier N. Baker, Ziqi Chen, Xia Ning, and Huan Sun. LlaSMol: Advancing large language models for chemistry with a large-scale, comprehensive, high-quality instruction tuning dataset. InFirst Conference on Language Modeling (COLM), 2024. arXiv:2402.09391
-
[16]
arXiv preprint arXiv:2411.07228 , year=
Botao Yu, Frazier N. Baker, Ziru Chen, Garrett Herb, Boyu Gou, Daniel Adu-Ampratwum, Xia Ning, and Huan Sun. ChemToolAgent: The impact of tools on language agents for chemistry problem solving. InFindings of the Association for Computational Linguistics: NAACL, 2025. URLhttps://arxiv.org/abs/2411.07228
-
[17]
MolCA: Molecular graph-language modeling with cross-modal projector and uni-modal adapter
Zhiyuan Liu, Sihang Li, Yanchen Luo, Hao Fei, Yixin Cao, Kenji Kawaguchi, Xiang Wang, and Tat-Seng Chua. MolCA: Molecular graph-language modeling with cross-modal projector and uni-modal adapter. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 15623–15638, 2023
2023
-
[18]
He Cao, Zijing Liu, Xingyu Lu, Yuan Yao, and Yu Li. InstructMol: Multi-modal integration for building a versatile and reliable molecular assistant in drug discovery. InProceedings of the 31st International Conference on Computational Linguistics (COLING), pages 354–379, 2025. arXiv:2311.16208
- [19]
- [20]
-
[21]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning (ICML), 2021. URLhttps://arxi...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[22]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. URLhttps://arxiv.org/abs/2304.08485
work page internal anchor Pith review arXiv 2023
-
[23]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Zheni Zeng, Yuan Yao, Zhiyuan Liu, and Maosong Sun. A deep-learning system bridging molecule structure and biomedical text with comprehension comparable to human professionals.Nature Communications, 13(1): 862, 2022. doi: 10.1038/s41467-022-28494-3
-
[25]
Shengchao Liu, Weili Nie, Chengpeng Wang, Jiarui Lu, Zhuoran Qiao, Ling Liu, Jian Tang, Chaowei Xiao, and Anima Anandkumar. Multi-modal molecule structure–text model for text-based retrieval and editing.Nature Machine Intelligence, 5(12):1447–1457, 2023. doi: 10.1038/s42256-023-00759-6
-
[26]
Bing Su, Dazhao Du, Zhao Yang, Yujie Zhou, Jiangmeng Li, Anyi Rao, Hao Sun, Zhiwu Lu, and Ji-Rong Wen. A molecular multimodal foundation model associating molecule graphs with natural language.arXiv preprint arXiv:2209.05481, 2022
-
[27]
Advancing molecular graph-text pre-training via fine-grained alignment
Yibo Li, Yuan Hu, Sheng Wang, Yu Wang, Mufang Shen, and Wenjie Yang. Advancing molecular graph-text pre-training via fine-grained alignment. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2025. arXiv:2409.14106
-
[28]
Galactica: A Large Language Model for Science
Ross Taylor, Marcin Kardas, Guillem Cucurull, Thomas Scialom, Anthony Hartshorn, Elvis Saravia, Andrew Poulton, Viktor Kerkez, and Robert Stojnic. Galactica: A large language model for science.arXiv preprint arXiv:2211.09085, 2022
work page internal anchor Pith review arXiv 2022
-
[29]
Towards 3d molecule-text interpretation in language models
Sihang Li, Zhiyuan Liu, Yanchen Luo, Xiang Wang, Xiangnan He, Kenji Kawaguchi, Tat-Seng Chua, and Qi Tian. Towards 3d molecule-text interpretation in language models. InInternational Conference on Learning Representations (ICLR), 2024. Also referred to as 3D-MoLM. 13 BOLEK BOLEK
2024
-
[30]
Yizhen Luo, Jiahuan Zhang, Siqi Fan, Kai Yang, Yushuai Wu, Mu Qiao, and Zaiqing Nie. BioMedGPT: Open multimodal generative pre-trained transformer for biomedicine.arXiv preprint arXiv:2308.09442, 2023
-
[31]
Pengfei Liu, Yiming Ren, Jun Tao, and Zhixiang Ren. GIT-Mol: A multi-modal large language model for molecular science with graph, image, and text.Computers in Biology and Medicine, 171:108073, 2024. doi: 10.1016/j.compbiomed.2024.108073
-
[32]
Pengfei Liu, Jun Tao, and Zhixiang Ren. A quantitative analysis of knowledge-learning preferences in large language models in molecular science.arXiv preprint arXiv:2402.04119, 2024. URLhttps://arxiv.org/ abs/2402.04119
-
[33]
Mol-instructions: A large-scale biomolecular instruction dataset for large language models
Yin Fang, Xiaozhuan Liang, Ningyu Zhang, Kangwei Liu, Rui Huang, Zhuo Chen, Xiaohui Fan, and Huajun Chen. Mol-instructions: A large-scale biomolecular instruction dataset for large language models. InInterna- tional Conference on Learning Representations (ICLR), 2024
2024
-
[34]
Sara Mahdavi, Christopher Semturs, David Fleet, Vivek Natarajan, and Shekoofeh Azizi
Juan Manuel Zambrano Chaves, Eric Wang, Tao Tu, Eeshit Dhaval Vaishnav, Byron Lee, S. Sara Mahdavi, Christopher Semturs, David Fleet, Vivek Natarajan, and Shekoofeh Azizi. Tx-LLM: A large language model for therapeutics.arXiv preprint arXiv:2406.06316, 2024
-
[35]
Txgemma: Efficient and agentic llms for therapeutics
Eric Wang, Nicholas Schottlender, Juan Manuel Zambrano Chaves, Eeshit Dhaval Vaishnav, Tao Tu, S. Sara Mahdavi, Vivek Natarajan, David Fleet, Christopher Semturs, and Shekoofeh Azizi. TxGemma: Efficient and agentic LLMs for therapeutics.arXiv preprint arXiv:2504.06196, 2025
-
[36]
Chemdfm: Dialogue foundation model for chemistry
Zihan Zhao, Da Ma, Lu Chen, Liangtai Sun, Zihao Li, Yi Xia, Bo Chen, Hongshen Xu, Zichen Zhu, Su Zhu, et al. ChemDFM: A large language foundation model for chemistry.arXiv preprint arXiv:2401.14818, 2024
-
[37]
BioT5: Enriching cross-modal integration in biology with chemical knowledge and natural language associations
Qizhi Pei, Wei Zhang, Jinhua Zhu, Kehan Wu, Kaiyuan Gao, Lijun Wu, Yingce Xia, and Rui Yan. BioT5: Enriching cross-modal integration in biology with chemical knowledge and natural language associations. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1102–1123, 2023
2023
-
[38]
Seyone Chithrananda, Gabriel Grand, Bharath Ramsun- dar, et al
Walid Ahmad, Elana Simon, Seyone Chithrananda, Gabriel Grand, and Bharath Ramsundar. ChemBERTa-2: Towards chemical foundation models.arXiv preprint arXiv:2209.01712, 2022
-
[39]
Molecular contrastive learning of representations via graph neural networks.Nature Machine Intelligence, 4(3):279–287, 2022
Yuyang Wang, Jianren Wang, Zhonglin Cao, and Amir Barati Farimani. Molecular contrastive learning of representations via graph neural networks.Nature Machine Intelligence, 4(3):279–287, 2022. doi: 10.1038/ s42256-022-00447-x
2022
-
[40]
Self- supervised graph transformer on large-scale molecular data
Yu Rong, Yatao Bian, Tingyang Xu, Weiyang Xie, Ying Wei, Wenbing Huang, and Junzhou Huang. Self- supervised graph transformer on large-scale molecular data. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[41]
MolPILE – large- scale, diverse dataset for molecular representation learning, 2025
Jakub Adamczyk, Jakub Poziemski, Franciszek Job, Mateusz Król, and Maciej Makowski. MolPILE – large- scale, diverse dataset for molecular representation learning, 2025. URLhttps://arxiv.org/abs/2509. 18353
2025
-
[42]
Zaifei Yang, Hong Chang, Ruibing Hou, Shiguang Shan, and Xilin Chen. KnowMol: Advancing molecular large language models with multi-level chemical knowledge, 2025. URLhttps://arxiv.org/abs/2510.19484
-
[43]
Teague Sterling and John J. Irwin. ZINC20 – a free ultralarge-scale chemical database for ligand discovery. Journal of Chemical Information and Modeling, 60(12):6065–6073, 2020. doi: 10.1021/acs.jcim.0c00675
-
[44]
RDKit: Open-source cheminformatics, 2024
Gregory Landrum et al. RDKit: Open-source cheminformatics, 2024. URLhttps://www.rdkit.org. Release 2024.03.1
2024
-
[45]
Irvine, Joe Pettersson, Nicko Goncharoff, Anne Hersey, and John P
George Papadatos, Mark Davies, Nathan Dedman, Jon Chambers, Anna Gaulton, James Siddle, Richard Koks, Sean A. Irvine, Joe Pettersson, Nicko Goncharoff, Anne Hersey, and John P. Overington. SureChEMBL: a large- scale, chemically annotated patent document database.Nucleic Acids Research, 44(D1):D1220–D1228, 2016. doi: 10.1093/nar/gkv1253
-
[46]
Thierry Kogej, Christos Kannas, Samuel Genheden, Eike Caldeweyher, and Mikhail Kabeshov. SMARTS-RX: a SMARTS-based representation of chemical functions for reactivity analysis.Journal of Cheminformatics, 17 (1):177, 2025. doi: 10.1186/s13321-025-01136-8
-
[47]
Mordred: a molecular descriptor calculator.Journal of Cheminformatics, 10(1):4, 2018
Hirotomo Moriwaki, Yu-Shi Tian, Norihito Kawashita, and Tatsuya Takagi. Mordred: a molecular descriptor calculator.Journal of Cheminformatics, 10(1):4, 2018. doi: 10.1186/s13321-018-0258-y
-
[48]
Benchmark data set for in silico prediction of Ames mutagenicity
Kasper Hansen, Sebastian Mika, Tim Schroeter, Andreas Sutter, Andreas ter Laak, Thomas Steger-Hartmann, Norbert Heinrich, and Klaus-Robert Müller. Benchmark data set for in silico prediction of Ames mutagenicity. Journal of Chemical Information and Modeling, 49(9):2077–2081, 2009. doi: 10.1021/ci900112x. 14 BOLEK BOLEK
-
[49]
Teixeira, Luis Pinheiro, and Antonio O
Ines Filipa Martins, Ana L. Teixeira, Luis Pinheiro, and Antonio O. Falcao. A Bayesian approach to in silico blood-brain barrier penetration modeling.Journal of Chemical Information and Modeling, 52(6):1686–1697,
-
[50]
doi: 10.1021/ci300124c
-
[51]
Chang-Ying Ma, Sheng-Yong Yang, Hui Zhang, Ming-Li Xiang, Qi Huang, and Yu-Quan Wei. Prediction models of human plasma protein binding rate and oral bioavailability derived by using GA–CG–SVM method.Journal of Pharmaceutical and Biomedical Analysis, 47(4–5):677–682, 2008. doi: 10.1016/j.jpba.2008.03.023
-
[52]
ADME evaluation in drug discovery
Tingjun Hou, Junmei Wang, Wei Zhang, and Xiaojie Xu. ADME evaluation in drug discovery. 7. prediction of oral absorption by correlation and classification.Journal of Chemical Information and Modeling, 47(1):208–218,
-
[53]
doi: 10.1021/ci600343x
-
[54]
ADMET evaluation in drug discovery
Shuangquan Wang, Huiyong Sun, Hui Liu, Dan Li, Youyong Li, and Tingjun Hou. ADMET evaluation in drug discovery. 16. predicting hERG blockers by combining multiple pharmacophores and machine learning approaches.Molecular Pharmaceutics, 13(8):2855–2866, 2016. doi: 10.1021/acs.molpharmaceut.6b00471
-
[55]
Fabio Broccatelli, Emanuele Carosati, Alessio Neri, Maria Frosini, Laura Goracci, Tudor I. Oprea, and Gabriele Cruciani. A novel approach for predicting P-glycoprotein (ABCB1) inhibition using molecular interaction fields. Journal of Medicinal Chemistry, 54(6):1740–1751, 2011. doi: 10.1021/jm101421d
-
[56]
AIDS antiviral screen data.https://wiki
National Cancer Institute Developmental Therapeutics Program. AIDS antiviral screen data.https://wiki. nci.nih.gov/display/NCIDTPdata/AIDS+Antiviral+Screen+Data, 2004. May 2004 release
2004
-
[57]
Henrike Veith, Noel Southall, Ruili Huang, Tim James, Darren Fayne, Natalia Artemenko, Min Shen, James Inglese, Christopher P. Austin, David G. Lloyd, and Douglas S. Auld. Comprehensive characterization of cy- tochrome P450 isozyme selectivity across chemical libraries.Nature Biotechnology, 27(11):1050–1055, 2009. doi: 10.1038/nbt.1581
-
[58]
Miriam Carbon-Mangels and Michael C. Hutter. Selecting relevant descriptors for classification by Bayesian estimates: a comparison with decision trees and support vector machines approaches for disparate data sets. Molecular Informatics, 30(10):885–895, 2011. doi: 10.1002/minf.201100069
-
[59]
Jeroen Kazius, Ross McGuire, and Roberta Bursi. Derivation and validation of toxicophores for mutagenicity prediction.Journal of Medicinal Chemistry, 48(1):312–320, 2005. doi: 10.1021/jm040835a
-
[60]
Hassan Pajouhesh and George R. Lenz. Medicinal chemical properties of successful central nervous system drugs.NeuroRx, 2(4):541–553, 2005. doi: 10.1602/neurorx.2.4.541
-
[61]
Daniel F. Veber, Stephen R. Johnson, Hung-Yuan Cheng, Brian R. Smith, Keith W. Ward, and Kenneth D. Kopple. Molecular properties that influence the oral bioavailability of drug candidates.Journal of Medicinal Chemistry, 45(12):2615–2623, 2002. doi: 10.1021/jm020017n
-
[62]
Daoyi Si, Yuetao Wang, Yi-Hua Zhou, Yajuan Guo, Jian Wang, Hua Zhou, Zhu-Sheng Li, and J. Paul Fawcett. Substrates, inducers, inhibitors and structure-activity relationships of human cytochrome P450 2C9 and implications in drug development.Current Medicinal Chemistry, 16(16):2066–2086, 2009. doi: 10.2174/092986709788682263
-
[63]
Alex M. Aronov. Predictive in silico modeling for hERG channel blockers.Drug Discovery Today, 10(2): 149–155, 2005. doi: 10.1016/S1359-6446(04)03278-7
-
[64]
Stefan Elfwing, Eiji Uchibe, and Kenji Doya. Sigmoid-weighted linear units for neural network function approx- imation in reinforcement learning.Neural Networks, 107:3–11, 2018. doi: 10.1016/j.neunet.2017.12.012
-
[65]
Smiles, a chemical language and information system
David Weininger. Smiles, a chemical language and information system. 1. introduction to methodology and encoding rules.Journal of Chemical Information and Computer Sciences, 28(1):31–36, 1988. doi: 10.1021/ ci00057a005. URLhttps://doi.org/10.1021/ci00057a005
-
[66]
Antoine Daina and Vincent Zoete. A BOILED-egg to predict gastrointestinal absorption and brain penetration of small molecules.ChemMedChem, 11(11):1117–1121, 2016. doi: 10.1002/cmdc.201600182
-
[67]
Kaitlyn M. Gayvert, Neel S. Madhukar, and Olivier Elemento. A data-driven approach to predicting successes and failures of clinical trials.Cell Chemical Biology, 23(10):1294–1301, 2016. doi: 10.1016/j.chembiol.2016. 07.023
-
[68]
Mariusz Butkiewicz, Edward W. Lowe, Ralf Mueller, Jeffrey L. Mendenhall, Pedro L. Teixeira, C. David Weaver, and Jens Meiler. Benchmarking ligand-based virtual high-throughput screening with the PubChem database. Molecules, 18(1):735–756, 2013. doi: 10.3390/molecules18010735
-
[69]
Validating ADME QSAR models using marketed drugs.SLAS Discovery, 26(10):1326–1336,
Vishal Siramshetty, Jordan Williams, Dac-Trung Nguyen, Jorge Neyra, Noel Southall, Ewy Mathe, Xin Xu, and Pranav Shah. Validating ADME QSAR models using marketed drugs.SLAS Discovery, 26(10):1326–1336,
-
[70]
doi: 10.1177/24725552211017520. 15 BOLEK BOLEK
-
[71]
Franck Touret, Maud Gilles, Karine Barral, Antoine Nougairede, Jacques van Helden, Etienne Decroly, and Xavier de Lamballerie. In vitro screening of a FDA approved chemical library reveals potential inhibitors of SARS-CoV-2 replication.Scientific Reports, 10(1):13093, 2020. doi: 10.1038/s41598-020-70143-6
-
[72]
Alves, Eugene Muratov, Denis Fourches, Judy Strickland, Nicole Kleinstreuer, Carolina H
Vinicius M. Alves, Eugene Muratov, Denis Fourches, Judy Strickland, Nicole Kleinstreuer, Carolina H. Andrade, and Alexander Tropsha. Predicting chemically-induced skin reactions. part I: QSAR models of skin sensitization and their application to identify potentially hazardous compounds.Toxicology and Applied Pharmacology, 284 (2):262–272, 2015. doi: 10.10...
-
[73]
Dac-Trung Nguyen, Tongan Zhao, Srilatha Sakamuru, Jinghua Zhao, Sampada A. Shahane, Anton Simeonov, Anna Rossoshek, Menghang Xia, and Ruili Huang. Tox21 challenge to build predictive models of nuclear receptor and stress response pathways as mediated by exposure to environmental chemicals and drugs.Frontiers in Environmental Science, 3:85, 2015. doi: 10.3...
-
[74]
AqSolDB, a curated reference set of aqueous solubility and 2d descriptors for a diverse set of compounds.Scientific Data, 6:143, 2019
Murat Cihan Sorkun, Abhishek Khetan, and Suleyman Er. AqSolDB, a curated reference set of aqueous solubility and 2d descriptors for a diverse set of compounds.Scientific Data, 6:143, 2019. doi: 10.1038/ s41597-019-0151-1
2019
-
[75]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025. URL https://arxiv.org/abs/2501.12948. A Training Task Examples Tables 5, 6, 7, and 8 show representative supervised examples from the training mixture. Each row gives the task type, the natural-language prompt, the molecule represented by its SMILES stri...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.