Recognition: no theorem link
Does it Really Count? Assessing Semantic Grounding in Text-Guided Class-Agnostic Counting
Pith reviewed 2026-05-14 20:49 UTC · model grok-4.3
The pith
Current text-guided class-agnostic counting models fail to ground prompt meanings in visual scenes despite strong standard counting scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
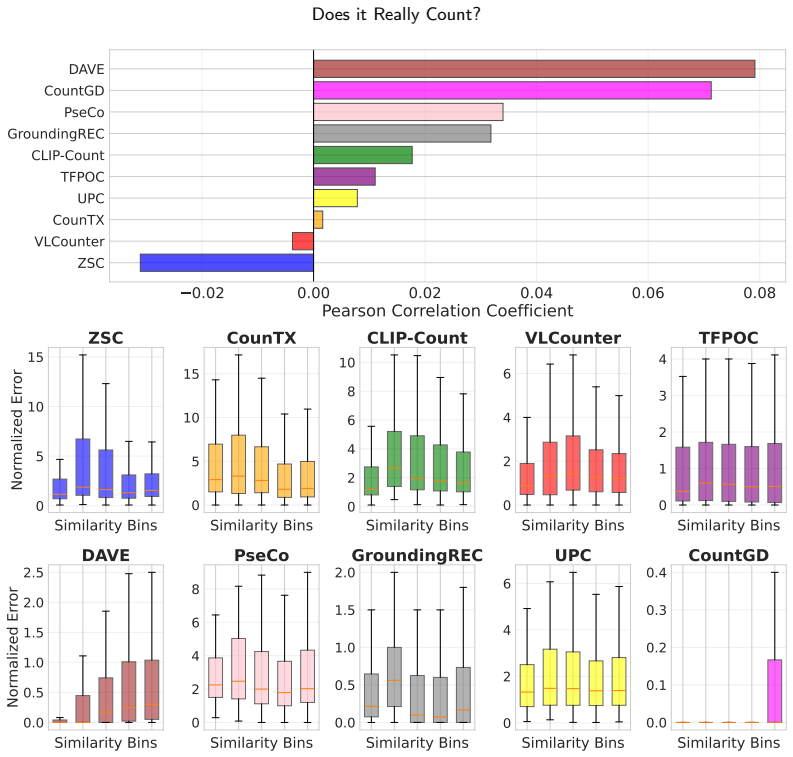
Despite low counting errors on existing benchmarks, current text-guided class-agnostic counting models frequently produce spurious counts when prompts are altered with negative labels or distractor classes, revealing that they do not correctly map textual object descriptions to the corresponding visual instances in multi-category scenes.
What carries the argument
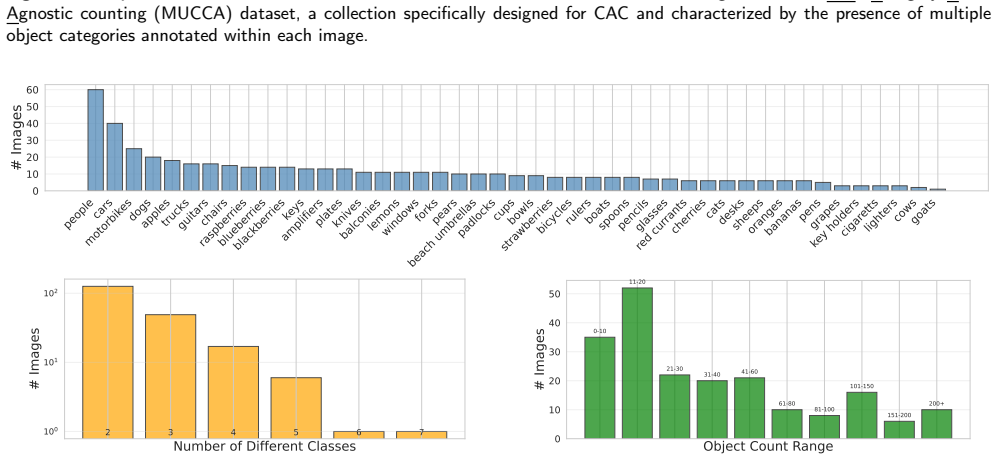
The negative-label test and distractor test within the PrACo++ framework, which quantify drops in counting accuracy when prompts specify absent or competing classes, evaluated on the MUCCA dataset of multi-annotated real-world scenes.
If this is right
- Current models require new architectures that explicitly align textual semantics with visual object features instead of relying on overall scene statistics.
- Evaluation protocols for text-guided counting must incorporate negative and distractor cases to measure trustworthiness beyond raw count error.
- Semantic similarity between alternative prompts directly increases the rate of grounding failures across tested methods.
- Real-world deployments in open scenes will produce unreliable results unless models pass the new robustness tests.
- The MUCCA dataset enables systematic comparison of future methods on multi-category grounding.
- pith_inferences:[
Where Pith is reading between the lines
- Developers could add explicit grounding modules that first localize candidate objects before counting to reduce prompt misalignment.
- The observed failures likely extend to other vision-language tasks where descriptions must be matched to specific instances rather than global image properties.
- The protocols could be adapted to video sequences to test whether motion cues improve semantic grounding over static images.
- Quantitative analysis of prompt similarity suggests targeted fine-tuning on hard negative examples would improve reliability.
Load-bearing premise
The negative-label and distractor protocols together with the MUCCA dataset isolate failures of semantic grounding without being confounded by localization errors or prompt phrasing sensitivity.
What would settle it
Models that maintain high counting accuracy and correct class selection on the negative-label and distractor tests within the MUCCA dataset, rather than defaulting to visually dominant objects unrelated to the prompt.
Figures














read the original abstract
Open-world text-guided class-agnostic counting (CAC) has emerged as a flexible paradigm for counting arbitrary object classes by using natural language prompts. However, current evaluation protocols primarily focus on standard counting errors within single-category images, overlooking a fundamental requirement: the ability to correctly ground the textual prompt in the visual scene. In this paper, we show that several state-of-the-art CAC models often struggle to determine which object class should be counted based on the given prompt, revealing a misalignment between textual semantics and visual object representations. This limitation leads to spurious counting responses and reduced reliability in real-world scenarios. To systematically address these limitations, we propose a new evaluation framework focused on model robustness and trustworthiness. Our contribution is two-fold: (i) we introduce PrACo++ (Prompt-Aware Counting++), a novel test suite featuring two dedicated evaluation protocols -- the negative-label test and the distractor test -- paired with new specialized metrics; and (ii) we present the MUCCA (MUlti-Category Class-Agnostic counting) evaluation dataset, a new collection of real-world images featuring multiple annotated object categories per scene, unlike existing CAC benchmarks that typically include a single category per image. Our extensive experimental evaluation of 10 state-of-the-art methods shows that, despite strong performance under standard counting metrics, current models exhibit significant weaknesses in understanding and grounding object class descriptions. Finally, we provide a quantitative analysis of how semantic similarity between prompts influences these failures. Overall, our results underscore the need for more semantically grounded architectures and offer a reliable framework for future assessment in open-world text-guided CAC methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that state-of-the-art text-guided class-agnostic counting (CAC) models perform well on standard counting metrics for single-category images but exhibit significant failures in semantically grounding textual prompts to visual objects. To expose this, the authors introduce PrACo++ (with negative-label and distractor protocols plus new metrics) and the MUCCA dataset of multi-category real-world images. Experiments on 10 methods show prompt-induced errors and a quantitative link to semantic similarity between prompts; the work argues for more semantically grounded architectures and supplies a new evaluation framework.
Significance. If the central claim holds after addressing controls, the work is significant: it identifies a previously under-tested failure mode in open-world CAC, supplies the first dedicated protocols and multi-category benchmark for trustworthiness, and demonstrates that standard metrics are insufficient. The empirical analysis of semantic similarity provides a concrete, falsifiable direction for future model design.
major comments (3)
- [Abstract, §4] Abstract and §4 (MUCCA construction): the multi-category scenes increase localization and instance-separation demands relative to single-category benchmarks. Without reporting results on single-category subsets of MUCCA or localization-oracle baselines, it is unclear whether the observed drops on PrACo++ protocols are attributable to semantic grounding failures or to these confounding factors.
- [§3.2] §3.2 (negative-label and distractor protocols): the new prompt structures differ from the original training/inference prompts used in the 10 evaluated methods. Without an ablation that holds prompt phrasing fixed while varying only label semantics, performance degradation could reflect prompt sensitivity rather than grounding misalignment.
- [§5] §5 (experimental results): the abstract states strong standard-metric performance, yet the main text does not clarify whether those metrics were computed on the same multi-category MUCCA images used for the PrACo++ tests. This missing cross-protocol comparison weakens the claim that standard metrics are insufficient.
minor comments (2)
- [§3.3] Notation for the new metrics (e.g., definitions of negative-label accuracy and distractor error) should be collected in a single table or subsection for easier reference.
- [§4] The paper should report the number of images and category pairs in MUCCA and the exact train/test split used for the 10 methods.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important aspects of experimental controls and clarity that will strengthen the manuscript. We address each major comment below and will incorporate the suggested revisions in the next version.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (MUCCA construction): the multi-category scenes increase localization and instance-separation demands relative to single-category benchmarks. Without reporting results on single-category subsets of MUCCA or localization-oracle baselines, it is unclear whether the observed drops on PrACo++ protocols are attributable to semantic grounding failures or to these confounding factors.
Authors: We agree that multi-category scenes introduce additional localization and separation challenges. To isolate semantic grounding effects, the revised manuscript will include an analysis on single-category subsets of MUCCA (selected images containing only one annotated category) as well as localization-oracle baselines that supply ground-truth boxes to the models. These additions will allow direct comparison and better attribute performance drops to prompt grounding rather than localization demands. revision: yes
-
Referee: [§3.2] §3.2 (negative-label and distractor protocols): the new prompt structures differ from the original training/inference prompts used in the 10 evaluated methods. Without an ablation that holds prompt phrasing fixed while varying only label semantics, performance degradation could reflect prompt sensitivity rather than grounding misalignment.
Authors: This point is well taken. While the protocols were designed to probe semantic robustness, we will add a controlled ablation in the revision that fixes prompt phrasing to match the original methods' templates and varies only the label semantics (positive vs. negative or distractor). This will separate prompt sensitivity from true grounding misalignment and strengthen the interpretation of the results. revision: yes
-
Referee: [§5] §5 (experimental results): the abstract states strong standard-metric performance, yet the main text does not clarify whether those metrics were computed on the same multi-category MUCCA images used for the PrACo++ tests. This missing cross-protocol comparison weakens the claim that standard metrics are insufficient.
Authors: We apologize for the ambiguity. The strong standard-metric results cited in the abstract were obtained on existing single-category benchmarks such as FSC-147. In the revised §5 we will explicitly compute and report standard counting metrics on the MUCCA images themselves, enabling a direct side-by-side comparison with the PrACo++ protocol results on identical data. This will make the insufficiency of standard metrics on multi-category scenes unambiguous. revision: yes
Circularity Check
No circularity: new empirical protocols and dataset are independent contributions
full rationale
The paper introduces PrACo++ protocols (negative-label and distractor tests) and the MUCCA dataset as novel evaluation tools to measure semantic grounding failures in CAC models. These are not derived from prior fitted parameters or self-referential definitions; they are presented as new test suites with specialized metrics. The central claim of model weaknesses is supported by direct experimental results on these introduced benchmarks rather than any reduction to inputs by construction. No equations, uniqueness theorems, or ansatzes are invoked that loop back to the paper's own fitted values or self-citations. The work is self-contained against external benchmarks via the new dataset and protocols.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions about image annotation quality and metric computation in computer vision benchmarks
Reference graph
Works this paper leans on
-
[1]
Amato, G., Ciampi, L., Falchi, F., Gennaro, C., 2019. Counting vehicles with deep learning in onboard uav imagery, in: 2019 IEEE Symposium on Computers and Communications (ISCC), pp. 1–6. doi:10.1109/ISCC47284.2019.8969620
-
[2]
Open-world text-specified object counting, in: 34th British Machine VisionConference2023,BMVC2023,Aberdeen,UK,November20- 23, 2023
Amini-Naieni, N., Amini-Naieni, K., Han, T., Zisserman, A., 2023. Open-world text-specified object counting, in: 34th British Machine VisionConference2023,BMVC2023,Aberdeen,UK,November20- 23, 2023
2023
-
[3]
Countgd: Multi- modal open-world counting
Amini-Naieni, N., Han, T., Zisserman, A., 2024. Countgd: Multi- modal open-world counting. CoRR abs/2407.04619. doi:10.48550/ ARXIV.2407.04619,arXiv:2407.04619
-
[4]
Arteta, C., Lempitsky, V.S., Zisserman, A., 2016. Counting in the wild,in:ComputerVision-ECCV2016-14thEuropeanConference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, PartVII,Springer.pp.483–498. doi:10.1007/978-3-319-46478-7\_30
-
[5]
Anembeddedtoolsetforhumanactivitymonitoring in critical environments
Benedetto, M.D., Carrara, F., Ciampi, L., Falchi, F., Gennaro, C., Amato,G.,2022. Anembeddedtoolsetforhumanactivitymonitoring in critical environments. Expert Syst. Appl. 199, 117125. doi:10. 1016/J.ESWA.2022.117125
-
[6]
Insect counting through deep learning- based density maps estimation
Bereciartua-Pérez, A., Gómez, L., Picón, A., Navarra-Mestre, R., Klukas, C., Eggers, T., 2022. Insect counting through deep learning- based density maps estimation. Computers and Electronics in Agri- culture 197, 106933. doi:https://doi.org/10.1016/j.compag.2022. 106933
-
[7]
Ciampi, L., Azmoudeh, A., Akbaba, E.E., Saritas, E., Yazici, Z.A., Ekenel, H.K., Amato, G., Falchi, F., 2026a. A survey on class- agnostic counting: Advancements from reference-based to open- world text-guided approaches. Comput. Vis. Image Underst. 267, 104703. URL:https://doi.org/10.1016/j.cviu.2026.104703, doi:10. 1016/J.CVIU.2026.104703
-
[8]
Learningtocount biologicalstructureswithraters’uncertainty
Ciampi,L.,Carrara,F.,Totaro,V.,Mazziotti,R.,Lupori,L.,Santiago, C.,Amato,G.,Pizzorusso,T.,Gennaro,C.,2022a. Learningtocount biologicalstructureswithraters’uncertainty. MedicalImageAnalysis 80, 102500. doi:https://doi.org/10.1016/j.media.2022.102500
-
[9]
Multi-camera vehicle counting using edge-ai
Ciampi,L.,Gennaro,C.,Carrara,F.,Falchi,F.,Vairo,C.,Amato,G., 2022b. Multi-camera vehicle counting using edge-ai. Expert Syst. Appl. 207, 117929. doi:10.1016/J.ESWA.2022.117929
-
[10]
Ciampi, L., Messina, N., Pierucci, M., Amato, G., Avvenuti, M., Falchi, F., 2025. Mind the prompt: A novel benchmark for prompt- based class-agnostic counting, in: IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2025, Tucson, AZ, USA, February 26 - March 6, 2025, IEEE. pp. 7970–7979. doi:10.1109/ WACV61041.2025.00774
-
[11]
Ciampi, L., Pacini, G., Messina, N., Amato, G., Falchi, F., 2026b. Mucca (multi-category class-agnostic counting) dataset: A collec- tion of multi-category images for class-agnostic object counting. URL:https://doi.org/10.5281/zenodo.19231375,doi:10.5281/zenodo. 19231375
-
[12]
beyond code snippets: Benchmarking llms on repository-level question answering
Ciampi,L.,Santiago,C.,Costeira,J.,Gennaro,C.,Amato,G.,2022c. Night and Day Instance Segmented Park (NDISPark) Dataset: a Col- lection of Images taken by Day and by Night for Vehicle Detection, Segmentation and Counting in Parking Areas. doi:10.5281/zenodo. 6560823
-
[13]
Ciampi,L.,Santiago,C.,Costeira,J.P.,Gennaro,C.,Amato,G.,2021. Domain adaptation for traffic density estimation, in: Proceedings of the 16th International Joint Conference on Computer Vision, Imag- ing and Computer Graphics Theory and Applications, VISIGRAPP 2021, Volume 5: VISAPP, Online Streaming, February 8-10, 2021, SCITEPRESS. pp. 185–195
2021
-
[14]
A deep learning-based pipeline for whitefly pest abundance estimation on chromotropic sticky traps
Ciampi, L., Zeni, V., Incrocci, L., Canale, A., Benelli, G., Falchi, F., Amato, G., Chessa, S., 2023a. A deep learning-based pipeline for whitefly pest abundance estimation on chromotropic sticky traps. Ecol. Informatics 78, 102384. doi:10.1016/J.ECOINF.2023.102384
-
[15]
Ciampi, L., Zeni, V., Incrocci, L., Canale, A., Benelli, G., Falchi, F., Amato, G., Chessa, S., 2023b. Pest sticky traps: a dataset for whitefly pest population density estimation in chromotropic sticky traps. doi:10.5281/zenodo.7801239
-
[16]
Cohen, J.P., Boucher, G., Glastonbury, C.A., Lo, H.Z., Bengio, Y.,
-
[17]
Count-ception: Counting by fully convolutional redundant counting, in: 2017 IEEE International Conference on Computer Vi- sion Workshops (ICCVW), pp. 18–26. doi:10.1109/ICCVW.2017.9
-
[19]
T-VSL: text-guided visual sound source localization in mixtures
Dai,S.,Liu,J.,Cheung,N.M.,2024b. ReferringExpressionCounting , in: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE Computer Society, Los Alamitos, CA, USA. pp. 16985–16995. doi:10.1109/CVPR52733.2024.01607
-
[20]
Afreeca: Annotation-free counting for all, in: Computer Vision - G
D’Alessandro, A.C., Mahdavi-Amiri, A., Hamarneh, G., 2024. Afreeca: Annotation-free counting for all, in: Computer Vision - G. Pacini et al.:Preprint submitted to ElsevierPage 18 of 20 Does it Really Count? ECCV2024-18thEuropeanConference,Milan,Italy,September29- October 4, 2024, Proceedings, Part IV, Springer. pp. 75–91. doi:10. 1007/978-3-031-73235-5\_5
2024
-
[21]
Doubinsky, P., Audebert, N., Crucianu, M., Borgne, H.L., 2024. Semantic generative augmentations for few-shot counting, in: IEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2024, Waikoloa, HI, USA, January 3-8, 2024, IEEE. pp. 5431–5440. doi:10.1109/WACV57701.2024.00536
-
[22]
Dukic, N., Lukezic, A., Zavrtanik, V., Kristan, M., 2023. A low- shot object counting network with iterative prototype adaptation, in: ICCV, Paris, France, October 1-6, 2023, IEEE. pp. 18826–18835. doi:10.1109/ICCV51070.2023.01730
-
[23]
Adaptive and background- aware match for class-agnostic counting
Gong, S., Yang, J., Zhang, S., 2025. Adaptive and background- aware match for class-agnostic counting. IEEE Signal Process. Lett. 32, 1261–1265. URL:https://doi.org/10.1109/LSP.2025.3546891, doi:10.1109/LSP.2025.3546891
-
[24]
Guerrero-Gómez-Olmedo,R.,Torre-Jiménez,B.,López-Sastre,R.J., Maldonado-Bascón, S., Oñoro-Rubio, D., 2015. Extremely overlap- ping vehicle counting, in: Pattern Recognition and Image Analysis - 7th Iberian Conference, IbPRIA 2015, Santiago de Compostela, Spain,June17-19,2015,Proceedings,Springer.pp.423–431. doi:10. 1007/978-3-319-19390-8\_48
2015
-
[25]
Learning to count anything: Reference-lessclass-agnosticcountingwithweaksupervision
Hobley, M.A., Prisacariu, V., 2022. Learning to count anything: Reference-lessclass-agnosticcountingwithweaksupervision. CoRR abs/2205.10203. doi:10.48550/ARXIV.2205.10203,arXiv:2205.10203
-
[26]
Hobley,M.A.,Prisacariu,V.,2024. ABCeasyas123:Ablindcounter for exemplar-free multi-class class-agnostic counting, in: Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part XI, Springer. pp. 304–319. doi:10.1007/978-3-031-73247-8\_18
-
[27]
Crowdcountingusingscale-awareattentionnetworks,in:IEEEWin- ter Conference on Applications of Computer Vision, WACV 2019, Waikoloa Village, HI, USA, January 7-11, 2019, IEEE
Hossain, M.A., Hosseinzadeh, M., Chanda, O., Wang, Y., 2019. Crowdcountingusingscale-awareattentionnetworks,in:IEEEWin- ter Conference on Applications of Computer Vision, WACV 2019, Waikoloa Village, HI, USA, January 7-11, 2019, IEEE. pp. 1280–
2019
-
[28]
doi:10.1109/WACV.2019.00141
-
[29]
Huang, Z., Dai, M., Zhang, Y., Zhang, J., Shan, H., 2024. Point, segment and count: A generalized framework for object counting, in: IEEE/CVFConferenceonComputerVisionandPatternRecognition, CVPR2024,Seattle,WA,USA,June16-22,2024,IEEE.pp.17067– 17076. doi:10.1109/CVPR52733.2024.01615
-
[30]
Idrees, H., Tayyab, M., Athrey, K., Zhang, D., Al-Máadeed, S., Rajpoot, N.M., Shah, M., 2018. Composition loss for counting, den- sity map estimation and localization in dense crowds, in: Computer Vision-ECCV2018-15thEuropeanConference,Munich,Germany, September 8-14, 2018, Proceedings, Part II, Springer. pp. 544–559. doi:10.1007/978-3-030-01216-8\_33
-
[31]
Jiang, R., Liu, L., Chen, C., 2023. Clip-count: Towards text-guided zero-shot object counting, in: Proceedings of the 31st ACM Interna- tionalConferenceonMultimedia,MM2023,Ottawa,ON,Canada,29 October2023-3November2023,ACM.pp.4535–4545.URL:https: //doi.org/10.1145/3581783.3611789, doi:10.1145/3581783.3611789
-
[32]
Kang, S., Moon, W., Kim, E., Heo, J., 2024. Vlcounter: Text-aware visual representation for zero-shot object counting, in: Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty- Sixth Conference on Innovative Applications of Artificial Intelli- gence, IAAI 2024, Fourteenth Symposium on Educational Advances inArtificialIntelligence,EA...
-
[33]
Revisiting crowd counting:State-of-the-art,trends,andfutureperspectives
Khan, M.A., Menouar, H., Hamila, R., 2023. Revisiting crowd counting:State-of-the-art,trends,andfutureperspectives. ImageVis. Comput. 129, 104597. doi:10.1016/J.IMAVIS.2022.104597
-
[34]
Kirillov,A.,Mintun,E.,Ravi,N.,Mao,H.,Rolland,C.,Gustafson,L., Xiao,T.,Whitehead,S.,Berg,A.C.,Lo,W.Y.,Dollár,P.,Girshick,R.,
-
[35]
Segment anything.arXiv:2304.02643
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Lempitsky, V.S., Zisserman, A., 2010. Learning to count objects in images, in: Advances in Neural Information Processing Systems 23: 24th Annual Conference on Neural Information Processing Systems 2010.Proceedingsofameetingheld6-9December2010,Vancouver, British Columbia, Canada, Curran Associates, Inc.. pp. 1324–1332
2010
-
[37]
Lin, T., Maire, M., Belongie, S.J., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L., 2014. Microsoft COCO: common objects in context, in: Computer Vision - ECCV 2014 - 13th European Confer- ence, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V, Springer. pp. 740–755. doi:10.1007/978-3-319-10602-1\_48
-
[38]
Lin,W.,Chan,A.B.,2024. Afixed-pointapproachtounifiedprompt- based counting, in: Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Sym- posium on Educational Advances in Artificial Intelligence, EAAI 2014, February 20-27, 2024, Vancouver,...
-
[39]
Countr: Transformer-based generalised visual counting, in: 33rd British Ma- chineVisionConference2022,BMVC2022,London,UK,November 21-24, 2022, BMVA Press
Liu, C., Zhong, Y., Zisserman, A., Xie, W., 2022. Countr: Transformer-based generalised visual counting, in: 33rd British Ma- chineVisionConference2022,BMVC2022,London,UK,November 21-24, 2022, BMVA Press. p. 370
2022
-
[40]
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Jiang, Q., Li, C., Yang, J., Su, H., Zhu, J., Zhang, L., 2024. Grounding DINO: marryingDINOwithgroundedpre-trainingforopen-setobjectdetec- tion,in:ComputerVision-ECCV2024-18thEuropeanConference, Milan,Italy,September29-October4,2024,Proceedings,PartXLVII, Springer. pp. 38–55. doi:10.1007/978-3-031-7...
-
[41]
Liu,W.,Salzmann,M.,Fua,P.,2019. Context-awarecrowdcounting, in: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, Computer Vision Foundation / IEEE. pp. 5099–5108. doi:10.1109/CVPR.2019. 00524
-
[42]
Mondal, A., Nag, S., Zhu, X., Dutta, A., 2025. Omnicount: Multi- label object counting with semantic-geometric priors, in: AAAI- 25, Sponsored by the Association for the Advancement of Artificial Intelligence, February 25 - March 4, 2025, Philadelphia, PA, USA, AAAI Press. pp. 19537–19545. doi:10.1609/AAAI.V39I18.34151
-
[43]
Norouzzadeh,M.S.,Nguyen,A.,Kosmala,M.,Swanson,A.,Palmer, M.S.,Packer,C.,Clune,J.,2018.Automaticallyidentifying,counting, and describing wild animals in camera-trap images with deep learn- ing. Proc. Natl. Acad. Sci. USA 115, E5716–E5725. doi:10.1073/ PNAS.1719367115
2018
-
[44]
Dave - a detect-and-verify paradigm for low-shot counting, in: Proceedings of theIEEE/CVFConferenceonComputerVisionandPatternRecogni- tion (CVPR), pp
Pelhan, J., Lukeži?, A., Zavrtanik, V., Kristan, M., 2024. Dave - a detect-and-verify paradigm for low-shot counting, in: Proceedings of theIEEE/CVFConferenceonComputerVisionandPatternRecogni- tion (CVPR), pp. 23293–23302
2024
-
[45]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agar- wal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever,I.,2021. Learningtransferablevisualmodelsfromnatural language supervision, in: Proceedings of the 38th International Con- ference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, PMLR. pp. 8748–8763
2021
-
[46]
Ranjan, V., Sharma, U., Nguyen, T., Hoai, M., 2021. Learning to count everything, in: IEEE Conference on Computer Vision and Pat- tern Recognition, CVPR 2021, virtual, June 19-25, 2021, Computer Vision Foundation / IEEE. pp. 3394–3403. doi:10.1109/CVPR46437. 2021.00340
-
[47]
Seenouvong, N., Watchareeruetai, U., Nuthong, C., Khongsomboon, K.,Ohnishi,N.,2016. Acomputervisionbasedvehicledetectionand counting system, in: 8th International Conference on Knowledge and Smart Technology, KST 2016, Chiangmai, Thailand, February 3-6, 2016, IEEE. pp. 224–227. doi:10.1109/KST.2016.7440510
-
[48]
Shi,Z.,Sun,Y.,Zhang,M.,2024. Training-freeobjectcountingwith prompts, in: 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), IEEE Computer Society, Los Alamitos, CA, USA. pp. 322–330. doi:10.1109/WACV57701.2024.00039
-
[49]
Wang, L., Li, J., Qi, C., Wu, X., Zou, R., Wang, F., Wang, P., 2025. A neighbor-aware feature enhancement network for crowd counting. Image Vis. Comput. 159, 105578. URL:https://doi.org/10.1016/j. imavis.2025.105578, doi:10.1016/J.IMAVIS.2025.105578. G. Pacini et al.:Preprint submitted to ElsevierPage 19 of 20 Does it Really Count?
work page doi:10.1016/j 2025
-
[50]
Wang, Z., Xiao, L., Cao, Z., Lu, H., 2024. Vision transformer off- the-shelf: A surprising baseline for few-shot class-agnostic counting, in: Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artifi- cial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artifi...
2024
-
[51]
Sqlnet: Scale-modulated query and localization network for few-shot class-agnostic counting
Wu, H., Chen, Y., Liu, L., Chen, T., Wang, K., Lin, L., 2025. Sqlnet: Scale-modulated query and localization network for few-shot class-agnostic counting. IEEE Trans. Image Process. 34, 4631–
2025
-
[52]
URL:https://doi.org/10.1109/TIP.2025.3588255,doi:10.1109/ TIP.2025.3588255
-
[53]
Microscopy cell counting and detection with fully convolutional regression networks
Xie, W., Noble, J.A., Zisserman, A., 2018. Microscopy cell counting and detection with fully convolutional regression networks. Comput. methods Biomech. Biomed. Eng. Imaging Vis. 6, 283–292. doi:10. 1080/21681163.2016.1149104
-
[54]
Vision transformers are parameter- efficient audio-visual learners
Xu, J., Le, H., Nguyen, V., Ranjan, V., Samaras, D., 2023. Zero- shot object counting, in: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, IEEE. pp. 15548–15557. doi:10.1109/CVPR52729.2023. 01492
-
[55]
CREAM: few-shot object counting with cross refinement and adaptive density map
Xu, Y., Li, M., Ye, Q., Wang, S., Li, L., Zhang, H., 2025. CREAM: few-shot object counting with cross refinement and adaptive density map. Image Vis. Comput. 161, 105632. URL:https://doi.org/10. 1016/j.imavis.2025.105632, doi:10.1016/J.IMAVIS.2025.105632
-
[56]
Learning spatial similarity distribution for few-shot object counting
Xu, Y., Song, F., Zhang, H., 2024. Learning spatial similarity distribution for few-shot object counting. CoRR abs/2405.11770. doi:10.48550/ARXIV.2405.11770,arXiv:2405.11770
-
[57]
Zhang, S., Wu, G., Costeira, J.P., Moura, J.M.F., 2017. Fcn-rlstm: Deep spatio-temporal neural networks for vehicle counting in city cameras, in: IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017, IEEE Computer Society. pp. 3687–3696. doi:10.1109/ICCV.2017.396
-
[58]
Cfenet: Context-aware feature enhancement network for efficient few-shot object counting
Zhang, S., Zhai, G., Chen, K., Wang, H., Han, S., 2025. Cfenet: Context-aware feature enhancement network for efficient few-shot object counting. Image Vis. Comput. 154, 105383. URL:https: //doi.org/10.1016/j.imavis.2024.105383,doi:10.1016/J.IMAVIS.2024. 105383
-
[59]
Enhanced crowd counting with weighted attention network and multi-scale feature integration
Zhou, L., Hu, Z., 2025. Enhanced crowd counting with weighted attention network and multi-scale feature integration. Image Vis. Comput. 163, 105750. URL:https://doi.org/10.1016/j.imavis. 2025.105750, doi:10.1016/J.IMAVIS.2025.105750
-
[60]
Multi-branch pro- gressiveembeddingnetworkforcrowdcounting
Zhou, L., Rao, S., Li, W., Hu, B., Sun, B., 2024. Multi-branch pro- gressiveembeddingnetworkforcrowdcounting. ImageVis.Comput. 148, 105140. URL:https://doi.org/10.1016/j.imavis.2024.105140, doi:10.1016/J.IMAVIS.2024.105140. G. Pacini et al.:Preprint submitted to ElsevierPage 20 of 20
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.