Recognition: 3 theorem links
Seeing Realism from Simulation: Efficient Video Transfer for Vision-Language-Action Data Augmentation
Pith reviewed 2026-05-08 18:16 UTC · model grok-4.3
The pith
An efficient pipeline turns simulated robotic videos into realistic ones that preserve actions and semantics, raising VLA model performance on real tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
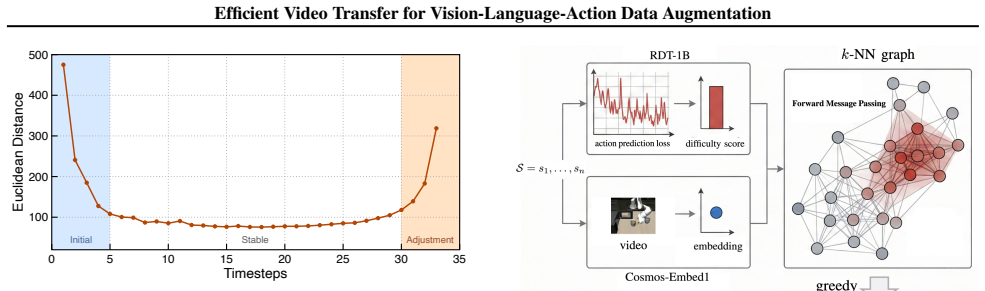
The central claim is that simulated VLA videos can be converted into realistic training videos through a pipeline of video semantic segmentation, caption extraction and rewriting, and conditional video synthesis, with added diffusion feature reuse and coreset sampling to keep the process fast and scalable, and that the resulting data measurably improves downstream VLA performance on both simulated and real robotic benchmarks.
What carries the argument
The conditional video transfer model that takes structured simulation conditions and generates realistic videos while holding action trajectories and task semantics fixed.
If this is right
- Large volumes of cheap simulated data become usable for real-world VLA training once the visual gap is closed.
- Models such as RDT-1B gain roughly 8 percent on Robotwin 2.0 and π0 gains 5.1 percent on the harder LIBERO-Plus set.
- The same augmentation works across several simulated environments and transfers to physical robot platforms.
- Feature reuse and coreset selection make the process fast enough to apply at the scale needed for modern VLA training.
Where Pith is reading between the lines
- The approach could cut the cost of collecting real robotic demonstrations by an order of magnitude if the realism transfer generalizes to new tasks.
- Similar condition-extraction plus rewriting steps might help close sim-to-real gaps in other video-heavy domains such as autonomous driving or human motion prediction.
- One could test whether feeding the rewritten captions back into the simulator itself creates even more diverse training distributions without extra generation cost.
Load-bearing premise
The generated videos must stay faithful to the original simulation's task meaning and motion paths without adding artifacts that confuse the downstream learner.
What would settle it
Train the same VLA models on the augmented dataset versus the original simulated data alone and measure whether real-world task success rates stay flat or drop instead of rising.
Figures












read the original abstract
Vision-language-action (VLA) models typically rely on large-scale real-world videos, whereas simulated data, despite being inexpensive and highly parallelizable to collect, often suffers from a substantial visual domain gap and limited environmental diversity, resulting in weak real-world generalization. We present an efficient video augmentation framework that converts simulated VLA videos into realistic training videos while preserving task semantics and action trajectories. Our pipeline extracts structured conditions from simulation via video semantic segmentation and video captioning, rewrites captions to diversify environments, and uses a conditional video transfer model to synthesize realistic videos. To make augmentation practical at scale, we introduce a diffusion feature-reuse mechanism that reuses video tokens across adjacent timesteps to accelerate generation, and a coreset sampling strategy that identifies a compact, non-redundant subset for augmentation under limited computation. Extensive experiments on Robotwin 2.0, LIBERO, LIBERO-Plus, and a real robotic platform demonstrate consistent improvements. For example, our method improves RDT-1B by 8% on Robotwin 2.0, and boosts $\pi_0$ by 5.1% on the more challenging LIBERO-Plus benchmark. Code is available at: https://github.com/nanfangxiansheng/Seeing-Realism-from-Simulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims an efficient video transfer pipeline that converts simulated VLA videos into realistic training data by extracting semantic segmentation and captions from simulation, rewriting captions for environmental diversity, and applying a conditional diffusion model. Efficiency is achieved via a diffusion feature-reuse mechanism across timesteps and coreset sampling; experiments on Robotwin 2.0, LIBERO, LIBERO-Plus, and a real robot platform report consistent gains such as +8% for RDT-1B on Robotwin 2.0 and +5.1% for π0 on LIBERO-Plus, with code released.
Significance. If the generated videos preserve action trajectories and task semantics, the framework could meaningfully expand the scale of VLA training by bridging the sim-to-real gap with inexpensive simulated data. The explicit code release at the cited GitHub repository is a clear strength that supports reproducibility and downstream use.
major comments (2)
- [§3] §3 (method pipeline): The claim that the conditional diffusion model 'preserves task semantics and action trajectories' rests on indirect conditioning via segmentation masks and rewritten captions alone; no explicit motion or optical-flow conditioning is described, and no quantitative verification metrics (e.g., trajectory MSE, flow consistency, or policy rollout divergence) are reported to confirm preservation. This is load-bearing for the downstream generalization improvements.
- [§4] §4 (experimental results): The reported gains (8% on RDT-1B, 5.1% on π0) are stated without accompanying details on the number of random seeds, statistical significance tests, full ablation controls, or exhaustive baseline comparisons; this weakens the ability to attribute improvements specifically to the video transfer rather than other factors.
minor comments (2)
- [Abstract] Abstract: The model name π0 should be expanded on first use for readers unfamiliar with the specific VLA architecture.
- [§3.3] The coreset sampling strategy is introduced for computational efficiency but lacks a precise algorithmic description or pseudocode that would allow exact reproduction from the text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential impact of the framework along with the code release. We address each major comment below and will revise the manuscript to strengthen the claims with additional evidence and details.
read point-by-point responses
-
Referee: [§3] §3 (method pipeline): The claim that the conditional diffusion model 'preserves task semantics and action trajectories' rests on indirect conditioning via segmentation masks and rewritten captions alone; no explicit motion or optical-flow conditioning is described, and no quantitative verification metrics (e.g., trajectory MSE, flow consistency, or policy rollout divergence) are reported to confirm preservation. This is load-bearing for the downstream generalization improvements.
Authors: We agree that the conditioning relies on semantic segmentation masks and captions rather than explicit optical flow. The per-frame segmentation masks extracted from simulation explicitly encode spatial layout and change across timesteps to reflect the executed actions, providing implicit but strong motion guidance that the conditional diffusion model is trained to follow. Caption rewriting further ensures semantic consistency while allowing environmental diversity. This design choice prioritizes efficiency and scalability without requiring additional motion estimators. We acknowledge the value of direct quantitative verification; in the revised manuscript we will add optical-flow consistency metrics (e.g., endpoint error between input and generated videos) and policy-rollout divergence comparisons in §3 and the experiments section to directly support the preservation claim. revision: yes
-
Referee: [§4] §4 (experimental results): The reported gains (8% on RDT-1B, 5.1% on π0) are stated without accompanying details on the number of random seeds, statistical significance tests, full ablation controls, or exhaustive baseline comparisons; this weakens the ability to attribute improvements specifically to the video transfer rather than other factors.
Authors: The main results were obtained with 3 random seeds per setting, with mean performance reported; ablations isolating the feature-reuse mechanism and coreset sampling appear in the supplementary material. We did not include error bars, p-values, or an exhaustive set of baselines in the primary text. In the revision we will expand §4 to report standard deviations, statistical significance tests (paired t-tests), and additional baselines including raw simulation data, standard domain randomization, and alternative video translation methods. These additions will strengthen attribution of gains to the proposed video transfer pipeline. revision: yes
Circularity Check
No circularity: forward pipeline evaluated on external benchmarks
full rationale
The paper presents an engineering pipeline that extracts segmentation and captions from simulation, rewrites captions, and applies a conditional diffusion model with feature reuse and coreset sampling. All central claims rest on empirical results from independent public benchmarks (Robotwin 2.0, LIBERO, LIBERO-Plus, real robot) rather than any fitted parameter renamed as prediction, self-referential definition, or load-bearing self-citation chain. No equations or uniqueness theorems are invoked that reduce the reported gains to the method's own inputs by construction. The derivation chain is therefore self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Video semantic segmentation and captioning accurately extract structured conditions from simulated videos.
- domain assumption Conditional video synthesis models can alter visual realism while preserving action trajectories and task semantics.
Reference graph
Works this paper leans on
- [1]
-
[2]
Cosmos-transfer1: Conditional world generation with adaptive multimodal control, 2025
Alhaija, H. A., Alvarez, J., Bala, M., Cai, T., Cao, T., Cha, L., Chen, J., Chen, M., Ferroni, F., Fidler, S., et al. Cosmos-transfer1: Conditional world genera- tion with adaptive multimodal control. arXiv preprint arXiv:2503.14492,
-
[3]
World Simulation with Video Foundation Models for Physical AI
Ali, A., Bai, J., Bala, M., Balaji, Y ., Blakeman, A., Cai, T., Cao, J., Cao, T., Cha, E., Chao, Y .-W., et al. World simulation with video foundation models for physical ai. arXiv preprint arXiv:2511.00062,
work page internal anchor Pith review arXiv
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
doi: 10.48550. arXiv preprint ARXIV .2410.24164. Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y ., English, Z., V oleti, V ., Letts, A., et al. Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127,
work page internal anchor Pith review arXiv
-
[6]
RT-1: Robotics Transformer for Real-World Control at Scale
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y ., Dabis, J., Finn, C., Gopalakrishnan, K., Hausman, K., Herzog, A., Hsu, J., et al. Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817,
work page internal anchor Pith review arXiv
-
[7]
Chen, T., Chen, Z., Chen, B., Cai, Z., Liu, Y ., Li, Z., Liang, Q., Lin, X., Ge, Y ., Gu, Z., et al. Robotwin 2.0: A scal- able data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation. arXiv preprint arXiv:2506.18088,
work page internal anchor Pith review arXiv
-
[8]
Dong, Z., Wang, X., Zhu, Z., Wang, Y ., Wang, Y ., Zhou, Y ., Wang, B., Ni, C., Ouyang, R., Qin, W., et al. Emma: Gen- eralizing real-world robot manipulation via generative visual transfer. arXiv preprint arXiv:2509.22407,
-
[9]
Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets
Ebert, F., Yang, Y ., Schmeckpeper, K., Bucher, B., Geor- gakis, G., Daniilidis, K., Finn, C., and Levine, S. Bridge data: Boosting generalization of robotic skills with cross- domain datasets. arXiv preprint arXiv:2109.13396,
work page internal anchor Pith review arXiv
-
[10]
Fang, I., Zhang, J., Tong, S., and Feng, C. From inten- tion to execution: Probing the generalization bound- aries of vision-language-action models. arXiv preprint arXiv:2506.09930, 2025a. Fang, Y ., Yang, Y ., Zhu, X., Zheng, K., Bertasius, G., Szafir, D., and Ding, M. Rebot: Scaling robot learning with real- to-sim-to-real robotic video synthesis. arXiv...
-
[11]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., Foster, C., Phang, J., He, H., Thite, A., Nabeshima, N., et al. The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027,
work page internal anchor Pith review arXiv
-
[12]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
URL https://arxiv. org/abs/2504.16054, 1(2):3. 9 Efficient Video Transfer for Vision-Language-Action Data Augmentation Intelligence, P., Amin, A., Aniceto, R., Balakrishna, A., Black, K., Conley, K., Connors, G., Darpinian, J., Dha- balia, K., DiCarlo, J., Driess, D., Equi, M., Esmail, A., Fang, Y ., Finn, C., Glossop, C., Godden, T., Goryachev, I., Groom...
-
[13]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
URL https://arxiv.org/abs/2511.14759. Jiang, Z., Han, Z., Mao, C., Zhang, J., Pan, Y ., and Liu, Y . Vace: All-in-one video creation and editing. arXiv preprint arXiv:2503.07598,
-
[14]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M. J., Pertsch, K., Karamcheti, S., Xiao, T., Balakr- ishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., San- keti, P., et al. Openvla: An open-source vision-language- action model. arXiv preprint arXiv:2406.09246,
work page internal anchor Pith review arXiv
-
[15]
Crafting papers on machine learning
Langley, P. Crafting papers on machine learning. In Langley, P. (ed.), Proceedings of the 17th International Conference on Machine Learning (ICML 2000), pp. 1207–1216, Stanford, CA,
2000
-
[16]
Flow Matching for Generative Modeling
URL https://openreview. net/forum?id=jtrhwfgseW. Li, W., Su, X., You, S., Wang, F., Qian, C., and Xu, C. Diff- nas: Bootstrapping diffusion models by prompting for bet- ter architectures. In 2023 IEEE International Conference on Data Mining (ICDM), pp. 1121–1126. IEEE, 2023b. Lipman, Y ., Chen, R. T., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for...
work page Pith review arXiv 2023
-
[17]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Liu, F., Zhang, S., Wang, X., Wei, Y ., Qiu, H., Zhao, Y ., Zhang, Y ., Ye, Q., and Wan, F. Timestep em- bedding tells: It’s time to cache for video diffusion model. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 7353–7363, 2025a. Liu, L., Wang, X., Zhao, G., Li, K., Qin, W., Zhu, J., Qiu, J., Zhu, Z., Huang, G., and Su, Z. ...
work page internal anchor Pith review arXiv
-
[18]
D2 pruning: Message passing for balancing diversity and difficulty in data pruning
Maharana, A., Yadav, P., and Bansal, M. D2 pruning: Mes- sage passing for balancing diversity and difficulty in data pruning. arXiv preprint arXiv:2310.07931,
-
[19]
URL https://research. nvidia.com/labs/dir/cosmos-embed1. Pei, X., Chen, Y ., Xu, S., Wang, Y ., Shi, Y ., and Xu, C. Action-aware dynamic pruning for efficient vision-language-action manipulation. arXiv preprint arXiv:2509.22093,
-
[20]
Penedo, G., Malartic, Q., Hesslow, D., Cojocaru, R., Cap- pelli, A., Alobeidli, H., Pannier, B., Almazrouei, E., and Launay, J. The refinedweb dataset for falcon llm: out- performing curated corpora with web data, and web data only. arXiv preprint arXiv:2306.01116,
work page internal anchor Pith review arXiv
-
[21]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V ., Hu, Y .-T., Hu, R., Ryali, C., Ma, T., Khedr, H., R ¨adle, R., Rolland, C., Gustafson, L., et al. Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714,
work page internal anchor Pith review arXiv
-
[22]
Team, G., Ye, A., Wang, B., Ni, C., Huang, G., Zhao, G., Li, H., Li, J., Zhu, J., Feng, L., et al. Gigabrain-0: A world model-powered vision-language-action model. arXiv preprint arXiv:2510.19430, 2025a. Team, G., Ye, A., Wang, B., Ni, C., Huang, G., Zhao, G., Li, H., Zhu, J., Li, K., Xu, M., et al. Gigaworld-0: World models as data engine to empower embo...
-
[23]
Wang, B., Meng, X., Wang, X., Zhu, Z., Ye, A., Wang, Y ., Yang, Z., Ni, C., Huang, G., and Wang, X. Embod- iedreamer: Advancing real2sim2real transfer for policy training via embodied world modeling. arXiv preprint arXiv:2507.05198,
-
[24]
Videoclip-xl: Advancing long description understanding for video clip models, 2024
Wang, J., Wang, C., Huang, K., Huang, J., and Jin, L. Videoclip-xl: Advancing long description understanding for video clip models. arXiv preprint arXiv:2410.00741,
-
[25]
Xu, S., Wang, Y ., Xia, C., Zhu, D., Huang, T., and Xu, C. Vla-cache: Efficient vision-language-action ma- nipulation via adaptive token caching. arXiv preprint arXiv:2502.02175, 2025a. Xu, S., Wang, Z., Wang, Y ., Xia, C., Huang, T., and Xu, C. Affordance field intervention: Enabling vlas to escape memory traps in robotic manipulation. arXiv preprint arX...
-
[26]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Zhao, T. Z., Kumar, V ., Levine, S., and Finn, C. Learn- ing fine-grained bimanual manipulation with low-cost hardware. arXiv preprint arXiv:2304.13705,
work page internal anchor Pith review arXiv
-
[27]
arXiv preprint arXiv:2507.02860 (2025) 4 1.x-Distill 19 Appendix Table of Contents 1 Introduction
Zhou, X., Liang, D., Chen, K., Feng, T., Chen, X., Lin, H., Ding, Y ., Tan, F., Zhao, H., and Bai, X. Less is enough: Training-free video diffusion acceleration via runtime- adaptive caching. arXiv preprint arXiv:2507.02860, 2025a. Zhou, X., Xu, Y ., Tie, G., Chen, Y ., Zhang, G., Chu, D., Zhou, P., and Sun, L. Libero-pro: Towards robust and fair evaluati...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.