Recognition: 3 theorem links
· Lean TheoremIConFace: Identity-Structure Asymmetric Conditioning for Unified Reference-Aware Face Restoration
Pith reviewed 2026-05-08 18:36 UTC · model grok-4.3
The pith
IConFace unifies reference-aware and no-reference face restoration by asymmetrically conditioning identity from references and structure from the degraded input.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
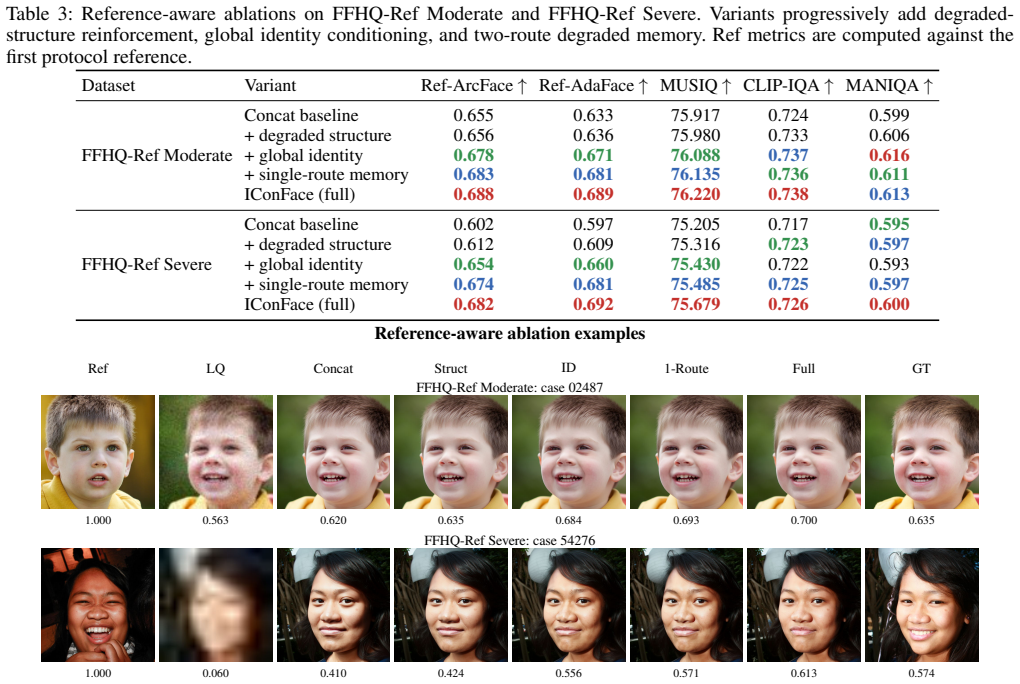
The core discovery is that identity and structure can be asymmetrically conditioned in a face restoration network: references are distilled into a norm-weighted global AdaFace identity anchor for image-only modulation, while the degraded input serves as the spatial anchor via low-rank residuals and block-wise degraded cross-attention with two-route memory. This produces one model that exploits references when present to boost identity consistency and detail recovery, and maintains high quality in no-reference mode.
What carries the argument
Identity-structure asymmetric conditioning, which distills references into a norm-weighted global AdaFace identity anchor for modulation while using the degraded image as structure anchor through low-rank residuals and block-wise cross-attention.
If this is right
- A single trained checkpoint suffices for both reference-present and reference-absent restoration scenarios without model switching.
- Identity consistency improves when same-identity references are supplied, reducing ambiguity from missing details in the degraded input.
- Fine-detail recovery benefits in cases where the input is severely degraded, as the identity anchor supplements missing information.
- Degraded-only restoration quality also rises because the shared architecture incorporates reference-handling components even when references are absent.
- The approach mitigates overuse of reference appearance by restricting references to identity modulation only.
Where Pith is reading between the lines
- The asymmetric anchoring idea could extend to restoring other image categories, such as objects or scenes, where content identity needs decoupling from spatial structure.
- In real-world apps, this could simplify pipelines for photo enhancement where reference images are sometimes but not always available.
- Testing the separation on video sequences or multi-frame inputs would reveal whether temporal consistency improves without explicit alignment of references.
- The method implies that careful global anchoring might reduce reliance on explicit pose or expression matching between reference and input.
Load-bearing premise
That distilling references into a global identity anchor combined with low-rank residuals and block-wise cross-attention on the input will reliably separate identity from structure without introducing artifacts or identity leakage under mismatched reference conditions.
What would settle it
Restored face images that copy identity traits such as age, makeup, or expression from a mismatched reference, or that show new artifacts when references are provided.
Figures




















read the original abstract
Blind face restoration is highly ill-posed under severe degradation, where identity-critical details may be missing from the degraded input. Same-identity references reduce this ambiguity, but mismatched pose, expression, illumination, age, makeup, or local facial states can lead to overuse of reference appearance. We propose \textbf{IConFace}, a unified reference-aware and no-reference framework with identity--structure asymmetric conditioning. References are distilled into a norm-weighted global AdaFace identity anchor for image-only modulation, while the degraded image is reinforced as the spatial structure anchor through low-rank residuals and block-wise degraded cross-attention with two-route memory. The resulting single checkpoint exploits references when available and falls back to no-reference restoration when absent, improving identity consistency, fine-detail recovery, and degraded-only restoration quality in a unified model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes IConFace, a unified single-checkpoint framework for blind face restoration that handles both reference-aware and no-reference cases via identity-structure asymmetric conditioning. References are distilled into a norm-weighted global AdaFace identity anchor for image-only modulation, while the degraded input is reinforced as the spatial structure anchor using low-rank residuals and block-wise degraded cross-attention with two-route memory. The model claims to exploit references when present and fall back gracefully to no-reference restoration, yielding improvements in identity consistency, fine-detail recovery, and degraded-only quality.
Significance. If the asymmetric conditioning reliably isolates identity from structure without leakage or new artifacts under mismatched references, the work would offer a practical advance by replacing separate reference and no-reference pipelines with one model, which is valuable for real-world applications where reference availability is inconsistent.
major comments (2)
- [Method description] The central claim of clean identity-structure separation (and graceful no-reference fallback) rests on the assumption that the norm-weighted AdaFace anchor plus low-rank residuals and block-wise cross-attention suffice to prevent reference appearance leakage under mismatched pose/expression/illumination. No explicit enforcement mechanism (disentanglement loss, reference masking, or pose-invariant projection) is described, leaving the separation unverified and load-bearing for the unified-model improvement.
- [Abstract] The abstract asserts quantitative gains in identity consistency, detail recovery, and no-reference quality, yet supplies no supporting numbers, ablation tables, or error analysis on mismatched-reference cases. Without these, it is impossible to assess whether the proposed conditioning actually delivers the claimed benefits or merely reproduces standard AdaFace + cross-attention behavior.
minor comments (1)
- Notation for the two-route memory and low-rank residual blocks should be defined with explicit equations or a diagram to clarify how the degraded image is reinforced as the structure anchor.
Simulated Author's Rebuttal
We are grateful to the referee for their constructive feedback, which helps improve the clarity and rigor of our work. We respond to the major comments point by point as follows.
read point-by-point responses
-
Referee: [Method description] The central claim of clean identity-structure separation (and graceful no-reference fallback) rests on the assumption that the norm-weighted AdaFace anchor plus low-rank residuals and block-wise cross-attention suffice to prevent reference appearance leakage under mismatched pose/expression/illumination. No explicit enforcement mechanism (disentanglement loss, reference masking, or pose-invariant projection) is described, leaving the separation unverified and load-bearing for the unified-model improvement.
Authors: We thank the referee for this insightful comment. The separation is achieved architecturally through our identity-structure asymmetric conditioning: the reference images are processed only to extract a norm-weighted global AdaFace identity anchor, which is used exclusively for image-level modulation without spatial influence. In contrast, the degraded image is reinforced as the structure anchor using low-rank residuals and block-wise degraded cross-attention with two-route memory, preventing direct transfer of reference appearance details. This design is detailed in Section 3 of the manuscript. While we did not employ an additional disentanglement loss to preserve model simplicity and unification, the experiments demonstrate effective separation. To further address the verification aspect, we will include additional ablation studies and visualizations on mismatched reference scenarios in the revised version to explicitly show the absence of leakage. revision: yes
-
Referee: [Abstract] The abstract asserts quantitative gains in identity consistency, detail recovery, and no-reference quality, yet supplies no supporting numbers, ablation tables, or error analysis on mismatched-reference cases. Without these, it is impossible to assess whether the proposed conditioning actually delivers the claimed benefits or merely reproduces standard AdaFace + cross-attention behavior.
Authors: We agree with the referee that including quantitative support in the abstract would strengthen the presentation. Due to the length constraints of the abstract, we focused on the conceptual contribution, but the full quantitative results, including identity consistency metrics, detail recovery measures, and no-reference quality improvements, are provided in the experimental section along with ablations. We will revise the abstract to incorporate key numerical results from our evaluations. Additionally, we will ensure that the analysis on mismatched-reference cases is more explicitly referenced. This revision will help readers better evaluate the benefits of the proposed conditioning. revision: yes
Circularity Check
No circularity: architectural design uses standard components without self-referential reduction
full rationale
The paper describes a neural architecture for unified reference-aware and no-reference face restoration via asymmetric conditioning (AdaFace identity anchor plus low-rank residuals and block-wise cross-attention). No equations, derivations, or first-principles predictions are presented that reduce to fitted inputs by construction. The single-checkpoint fallback behavior is an explicit design outcome of the conditioning scheme, not a tautology. Standard components (AdaFace, cross-attention) are invoked without self-citation load-bearing or ansatz smuggling for the core separation claim. This is the expected non-finding for a methods paper whose claims rest on empirical validation rather than closed-form derivation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
Cost/FunctionalEquation (J = ½(x+x⁻¹)−1)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
References are distilled into a norm-weighted global AdaFace identity anchor ... w_r = softmax(log q_r / T), e_ref = Norm(Σ w_r e_r)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Towards Real-World Blind Face Restoration with Generative Facial Prior , author =. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[2]
2022 , pages =
Gu, Yuchao and Wang, Xintao and Xie, Liangbin and Dong, Chao and Li, Gen and Shan, Ying and Cheng, Ming-Ming , booktitle =. 2022 , pages =
2022
-
[3]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Towards Robust Blind Face Restoration with Codebook Lookup Transformer , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[4]
2022 , pages =
Wang, Zhouxia and Zhang, Jiawei and Chen, Runjian and Wang, Wenping and Luo, Ping , booktitle =. 2022 , pages =
2022
-
[5]
2023 , volume =
Wang, Zhouxia and Zhang, Jiawei and Chen, Runjian and Wang, Wenping and Luo, Ping , journal =. 2023 , volume =
2023
-
[6]
International Conference on Learning Representations (ICLR) , year =
Dual Associated Encoder for Face Restoration , author =. International Conference on Learning Representations (ICLR) , year =
-
[7]
2021 , pages =
Yang, Tao and Ren, Peiran and Xie, Xuansong and Zhang, Lei , booktitle =. 2021 , pages =
2021
-
[8]
2023 , pages =
Wang, Zhixin and Zhang, Ziying and Zhang, Xiaoyun and Zheng, Huangjie and Zhou, Mingyuan and Zhang, Ya and Wang, Yanfeng , booktitle =. 2023 , pages =
2023
-
[9]
2024 , volume =
Yue, Zongsheng and Loy, Chen Change , journal =. 2024 , volume =
2024
-
[10]
Yang, Peiqing and Zhou, Shangchen and Tao, Qingyi and Loy, Chen Change , booktitle =
-
[11]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year =
Learning Dual Memory Dictionaries for Blind Face Restoration , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence , year =
-
[12]
Hsiao, Chi-Wei and Liu, Yu-Lun and Yang, Cheng-Kun and Kuo, Sheng-Po and Jou, Yucheun Kevin and Chen, Chia-Ping , booktitle =
-
[13]
Ying, Jiacheng and Liu, Mushui and Wu, Zhe and Zhang, Runming and Yu, Zhu and Fu, Siming and Cao, Si-Yuan and Wu, Chao and Yu, Yunlong and Shen, Hui-Liang , journal =
-
[14]
Zhang, Howard and Alaluf, Yuval and Ma, Sizhuo and Kadambi, Achuta and Wang, Jian and Aberman, Kfir , journal =
-
[15]
Liu, Siyu and Duan, Zheng-Peng and OuYang, Jia and Fu, Jiayi and Park, Hyunhee and Liu, Zikun and Guo, Chunle and Li, Chongyi , booktitle =
-
[16]
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , year =
Copy or Not? Reference-Based Face Image Restoration with Fine Details , author =. IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , year =
-
[17]
International Conference on Learning Representations (ICLR) , year =
Overcoming False Illusions in Real-World Face Restoration with Multi-Modal Guided Diffusion Model , author =. International Conference on Learning Representations (ICLR) , year =
-
[18]
IEEE/CVF International Conference on Computer Vision (ICCV) , year =
Adding Conditional Control to Text-to-Image Diffusion Models , author =. IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[19]
Ye, Hu and Zhang, Jun and Liu, Sibo and Han, Xiao and Yang, Wei , journal =
-
[20]
2024 , pages =
Li, Zhen and Cao, Mingdeng and Wang, Xintao and Qi, Zhongang and Cheng, Ming-Ming and Shan, Ying , booktitle =. 2024 , pages =
2024
-
[21]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
-
[22]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
High-Resolution Image Synthesis with Latent Diffusion Models , author =. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[23]
2024 , howpublished =
2024
-
[24]
International Conference on Learning Representations (ICLR) , year =
Flow Matching for Generative Modeling , author =. International Conference on Learning Representations (ICLR) , year =
-
[25]
2019 , pages =
Deng, Jiankang and Guo, Jia and Xue, Niannan and Zafeiriou, Stefanos , booktitle =. 2019 , pages =
2019
-
[26]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
A Style-Based Generator Architecture for Generative Adversarial Networks , author =. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[27]
IEEE International Conference on Computer Vision (ICCV) , year =
Deep Learning Face Attributes in the Wild , author =. IEEE International Conference on Computer Vision (ICCV) , year =
-
[28]
Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments , author =
-
[29]
IEEE Signal Processing Letters , year =
Making a ``Completely Blind'' Image Quality Analyzer , author =. IEEE Signal Processing Letters , year =
-
[30]
2021 , pages =
Ke, Junjie and Wang, Qifei and Wang, Yilin and Milanfar, Peyman and Yang, Feng , booktitle =. 2021 , pages =
2021
-
[31]
and Loy, Chen Change , booktitle =
Wang, Jianyi and Chan, Kelvin C.K. and Loy, Chen Change , booktitle =. Exploring. 2023 , pages =
2023
-
[32]
Heusel, Martin and Ramsauer, Hubert and Unterthiner, Thomas and Nessler, Bernhard and Hochreiter, Sepp , booktitle =
-
[33]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric , author =. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[34]
ACM Computing Surveys , year =
Survey on Deep Face Restoration: From Non-blind to Blind and Beyond , author =. ACM Computing Surveys , year =
-
[35]
Proceedings of the European Conference on Computer Vision (ECCV) , pages =
Learning Warped Guidance for Blind Face Restoration , author =. Proceedings of the European Conference on Computer Vision (ECCV) , pages =
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Enhanced Blind Face Restoration with Multi-Exemplar Images and Adaptive Spatial Feature Fusion , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[37]
Proceedings of the European Conference on Computer Vision (ECCV) , pages =
Blind Face Restoration via Deep Multi-scale Component Dictionaries , author =. Proceedings of the European Conference on Computer Vision (ECCV) , pages =
-
[38]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Progressive Semantic-Aware Style Transformation for Blind Face Restoration , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[39]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages =
Towards Authentic Face Restoration with Iterative Diffusion Models and Beyond , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages =
-
[40]
Proceedings of the 31st ACM International Conference on Multimedia , pages =
DiffBFR: Bootstrapping Diffusion Model Towards Blind Face Restoration , author =. Proceedings of the 31st ACM International Conference on Multimedia , pages =
-
[41]
Lin, Xinqi and He, Jingwen and Chen, Ziyan and Lyu, Zhaoyang and Dai, Bo and Yu, Fanghua and Qiao, Yu and Ouyang, Wanli and Dong, Chao , booktitle =
-
[42]
IEEE Transactions on Circuits and Systems for Video Technology , year =
Toward Real-World Blind Face Restoration with Generative Diffusion Prior , author =. IEEE Transactions on Circuits and Systems for Video Technology , year =
-
[43]
Varanka, Tuomas and Toivonen, Tapani and Tripathy, Soumya and Zhao, Guoying and Acar, Erman , booktitle =
-
[44]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages =
Unlocking the Potential of Diffusion Priors in Blind Face Restoration , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , pages =
-
[45]
Wang, Jingkai and Gong, Jue and Zhang, Lin and Chen, Zheng and Liu, Xing and Gu, Hong and Liu, Yutong and Zhang, Yulun and Yang, Xiaokang , booktitle =
-
[46]
Yin, Zhicun and Chen, Junjie and Liu, Ming and Wang, Zhixin and Li, Fan and Pei, Renjing and Li, Xiaoming and Lau, Rynson W. H. and Zuo, Wangmeng , booktitle =
-
[47]
and Sun, Jinqiu and Zhu, Yu and Kweon, In So and Zhang, Yanning , booktitle =
Niu, Axi and Zhang, Kang and Pham, Trung X. and Sun, Jinqiu and Zhu, Yu and Kweon, In So and Zhang, Yanning , booktitle =
-
[48]
and Zhang, Kang and Sun, Jinqiu and Zhu, Yu and Yan, Qingsen and Kweon, In So and Zhang, Yanning , journal =
Niu, Axi and Pham, Trung X. and Zhang, Kang and Sun, Jinqiu and Zhu, Yu and Yan, Qingsen and Kweon, In So and Zhang, Yanning , journal =. 2024 , doi =
2024
-
[49]
IEEE Transactions on Circuits and Systems for Video Technology , volume =
Learning From Multi-Perception Features for Real-Word Image Super-Resolution , author =. IEEE Transactions on Circuits and Systems for Video Technology , volume =. 2025 , doi =
2025
-
[50]
2024 , doi =
Yan, Qingsen and Niu, Axi and Wang, Chaoqun and Dong, Wei and Wozniak, Marcin and Zhang, Yanning , journal =. 2024 , doi =
2024
-
[51]
Multimedia Systems , volume =
Modeling Optical Imaging Pipeline and Learning Contrastive-Based Representation for Hybrid-Corrupted Image Restoration , author =. Multimedia Systems , volume =. 2025 , doi =
2025
-
[52]
2025 , doi =
Niu, Axi and Zhang, Kang and Tee, Joshua Tian Jin and Yan, Qingsen and Wei, Sun and Sun, Jinqiu and Kweon, In So and Zhang, Yanning , journal =. 2025 , doi =
2025
-
[53]
arXiv preprint arXiv:2308.03021 , year =
All-in-One Multi-Degradation Image Restoration Network via Hierarchical Degradation Representation , author =. arXiv preprint arXiv:2308.03021 , year =
-
[54]
Tu, Yanjie and Yan, Qingsen and Niu, Axi and Tang, Jiacong , journal =
-
[55]
2026 , doi =
Sun, Wei and Wang, Qianzhou and Wang, Yilin and Hou, Zhenyu and Yan, Qingsen and Zhang, Yanning , journal =. 2026 , doi =
2026
-
[56]
IEEE Transactions on Image Processing , volume =
Two-Stream Convolutional Networks for Blind Image Quality Assessment , author =. IEEE Transactions on Image Processing , volume =. 2019 , doi =
2019
-
[57]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Blindly Assess Image Quality in the Wild Guided by a Self-Adaptive Hyper Network , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[58]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Attention-Guided Network for Ghost-Free High Dynamic Range Imaging , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =. 2019 , doi =
2019
-
[59]
Yan, Qingsen and Zhang, Lei and Liu, Yu and Zhu, Yu and Sun, Jinqiu and Shi, Qinfeng and Zhang, Yanning , journal =. Deep. 2020 , doi =
2020
-
[60]
Advances in Neural Information Processing Systems , volume =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems , volume =
-
[61]
Advances in Neural Information Processing Systems , volume =
Denoising Diffusion Probabilistic Models , author =. Advances in Neural Information Processing Systems , volume =
-
[62]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
Scalable Diffusion Models with Transformers , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
-
[63]
International Conference on Learning Representations , year =
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , author =. International Conference on Learning Representations , year =
-
[64]
Meng, Chenlin and He, Yutong and Song, Yang and Song, Jiaming and Wu, Jiajun and Zhu, Jun-Yan and Ermon, Stefano , booktitle =
-
[65]
Liang, Jingyun and Cao, Jiezhang and Sun, Guolei and Zhang, Kai and Van Gool, Luc and Timofte, Radu , booktitle =
-
[66]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Restormer: Efficient Transformer for High-Resolution Image Restoration , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[67]
Menon, Sachit and Damian, Alexandru and Hu, Shijia and Ravi, Nikhil and Rudin, Cynthia , booktitle =
-
[68]
Yang, Lingbo and Wang, Shanshe and Ma, Siwei and Gao, Wen and Liu, Chang and Wang, Pan and Ren, Peiran , booktitle =
-
[69]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Scaling Up to Excellence: Practicing Model Scaling for Photo-Realistic Image Restoration in the Wild , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[70]
J.; Xu, D.; Zhang, Y.; Wang, Z.; and Forsyth, D
Chong, M. J.; Xu, D.; Zhang, Y.; Wang, Z.; and Forsyth, D. 2025. Copy or Not? Reference-Based Face Image Restoration with Fine Details. In IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
2025
-
[71]
Gu, Y.; Wang, X.; Xie, L.; Dong, C.; Li, G.; Shan, Y.; and Cheng, M.-M. 2022. VQFR : Blind Face Restoration with Vector-Quantized Dictionary and Parallel Decoder. In European Conference on Computer Vision (ECCV), 126--143
2022
-
[72]
K.; and Chen, C.-P
Hsiao, C.-W.; Liu, Y.-L.; Yang, C.-K.; Kuo, S.-P.; Jou, Y. K.; and Chen, C.-P. 2024. ReF-LDM : A Latent Diffusion Model for Reference-based Face Image Restoration. In Advances in Neural Information Processing Systems (NeurIPS)
2024
-
[73]
Li, W.; Wang, M.; Zhang, K.; Li, J.; Li, X.; Zhang, Y.; Gao, G.; Deng, W.; and Lin, C.-W. 2025. Survey on Deep Face Restoration: From Non-blind to Blind and Beyond. ACM Computing Surveys
2025
-
[74]
Li, X.; Chen, C.; Zhou, S.; Lin, X.; Zuo, W.; and Zhang, L. 2020 a . Blind Face Restoration via Deep Multi-scale Component Dictionaries. In Proceedings of the European Conference on Computer Vision (ECCV), 399--415
2020
-
[75]
Li, X.; Li, W.; Ren, D.; Zhang, H.; Wang, M.; and Zuo, W. 2020 b . Enhanced Blind Face Restoration with Multi-Exemplar Images and Adaptive Spatial Feature Fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2706--2715
2020
-
[76]
Li, X.; Liu, M.; Ye, Y.; Zuo, W.; Lin, L.; and Yang, R. 2018. Learning Warped Guidance for Blind Face Restoration. In Proceedings of the European Conference on Computer Vision (ECCV), 272--289
2018
-
[77]
Li, X.; Zhang, S.; Zhou, S.; Zhang, L.; and Zuo, W. 2022. Learning Dual Memory Dictionaries for Blind Face Restoration. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(5): 5904--5919
2022
-
[78]
Lin, X.; He, J.; Chen, Z.; Lyu, Z.; Dai, B.; Yu, F.; Qiao, Y.; Ouyang, W.; and Dong, C. 2024. DiffBIR : Toward Blind Image Restoration with Generative Diffusion Prior. In Proceedings of the European Conference on Computer Vision (ECCV)
2024
-
[79]
Liu, S.; Duan, Z.-P.; OuYang, J.; Fu, J.; Park, H.; Liu, Z.; Guo, C.; and Li, C. 2025. FaceMe : Robust Blind Face Restoration with Personal Identification. In AAAI Conference on Artificial Intelligence
2025
-
[80]
Meng, C.; He, Y.; Song, Y.; Song, J.; Wu, J.; Zhu, J.-Y.; and Ermon, S. 2022. SDEdit : Guided Image Synthesis and Editing with Stochastic Differential Equations. In International Conference on Learning Representations
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.