Recognition: 3 theorem links
· Lean TheoremSCPRM: A Schema-aware Cumulative Process Reward Model for Knowledge Graph Question Answering
Pith reviewed 2026-05-08 17:51 UTC · model grok-4.3
The pith
SCPRM evaluates KG reasoning steps with prefix conditioning and schema distance to supply cumulative plus future rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
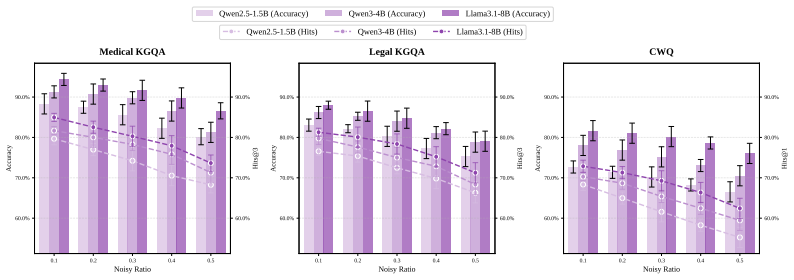
We propose a Schema-aware Cumulative Process Reward Model (SCPRM) that evaluates reasoning paths by conditioning on the reasoning prefix and incorporating schema distance between current reasoning step and the implicit target parsed from the query, which provides cumulative and future rewards to guide the path explorations. We further integrate SCPRM into Monte Carlo Tree Search (MCTS) as SCPRM-MCTS to conduct multi-hop reasoning on KGs for question answering tasks. Across medical and legal KGQA and CWQ, SCPRM-MCTS improves the performance of Hits@k by an average of 1.18 percent over strong baselines, demonstrating more accurate and risk-sensitive reasoning evaluation.
What carries the argument
The Schema-aware Cumulative Process Reward Model (SCPRM), which augments step-wise rewards by prefix conditioning and schema-distance future signals to the query-derived target.
Load-bearing premise
Schema distance to an implicit target parsed from the query can be computed reliably and supplies a meaningful future-reward signal that actually mitigates risk compensation without introducing new errors.
What would settle it
An ablation that removes the schema-distance term from SCPRM and measures whether Hits@k gains disappear, or manual inspection of scored paths showing that early risky steps followed by corrections still receive high cumulative rewards.
Figures



read the original abstract
Large language models excel at complex reasoning, yet evaluating their intermediate steps remains challenging. Although process reward models provide step-wise supervision, they often suffer from a risk compensation effect, where incorrect steps are offset by later correct ones, assigning high rewards to flawed reasoning paths. This issue is further exacerbated in knowledge graph (KG) reasoning, as there may exist multiple paths between the start and end entities in the KGs, and a risky step can make the reasoning path flawed. Those limitations are problematic in risk-sensitive tasks such as medical and legal KG reasoning. To address the issues, we propose a Schema-aware Cumulative Process Reward Model (SCPRM) that evaluates reasoning paths by conditioning on the reasoning prefix , and incorporating schema distance between current reasoning step and the implicit target parsed from the query, which provides cumulative and future rewards to guide the path explorations. We further integrate SCPRM into Monte Carlo Tree Search (MCTS) as SCPRM-MCTS to conduct multi-hop reasoning on KGs for question answering (QA) tasks. Across medical and legal KGQA and CWQ, SCPRM-MCTS improves the performance of Hits@k by an average of 1.18% over strong baselines, demonstrating more accurate and risk-sensitive reasoning evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Schema-aware Cumulative Process Reward Model (SCPRM) for knowledge graph question answering that evaluates reasoning paths by conditioning on the reasoning prefix and adding schema distance between the current step and an implicit target entity parsed from the query. This supplies both cumulative and future rewards to mitigate risk compensation in process reward models. The model is integrated into Monte Carlo Tree Search as SCPRM-MCTS for multi-hop KG reasoning. On medical and legal KGQA tasks plus CWQ, SCPRM-MCTS reports an average 1.18% improvement in Hits@k over strong baselines.
Significance. If the empirical gains hold and the schema-distance signal proves reliable, the work could strengthen process supervision for risk-sensitive KGQA in domains such as medicine and law by reducing the chance that flawed intermediate steps receive high rewards. The MCTS integration provides a concrete mechanism for guiding path search with future-oriented information.
major comments (2)
- [Abstract] Abstract: the central claim of a 1.18% average Hits@k improvement is stated without any reference to experimental protocol, baseline definitions, statistical significance tests, ablation results, or error analysis. This information is load-bearing for assessing whether the reported gain supports the model’s effectiveness.
- [Method] Method section (SCPRM definition): the implicit target is described as “parsed from the query” and schema distance is used to supply future reward, yet no formal definition, parsing procedure, or validation of parsing accuracy is supplied. Because this distance is the source of the future-reward term, any systematic parsing error would directly corrupt the reward signal and undermine the risk-compensation mitigation claim.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major comment below, indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 1.18% average Hits@k improvement is stated without any reference to experimental protocol, baseline definitions, statistical significance tests, ablation results, or error analysis. This information is load-bearing for assessing whether the reported gain supports the model’s effectiveness.
Authors: We agree that the abstract would benefit from additional context on the evaluation. In the revised version we will expand the abstract to briefly note the datasets (medical and legal KGQA tasks plus CWQ), the use of Hits@k against strong baselines, and that the reported gains are supported by ablation studies and statistical significance tests presented in the experimental section. Detailed protocols, baseline definitions, and error analysis remain in the main body due to abstract length constraints. revision: partial
-
Referee: [Method] Method section (SCPRM definition): the implicit target is described as “parsed from the query” and schema distance is used to supply future reward, yet no formal definition, parsing procedure, or validation of parsing accuracy is supplied. Because this distance is the source of the future-reward term, any systematic parsing error would directly corrupt the reward signal and undermine the risk-compensation mitigation claim.
Authors: We acknowledge that a formal definition and explicit parsing procedure are required for reproducibility and to substantiate the future-reward claim. In the revised manuscript we will add (1) a mathematical definition of schema distance, (2) a step-by-step description of the query-parsing procedure used to obtain the implicit target entity, and (3) empirical validation of parsing accuracy together with a brief discussion of how parsing errors would affect the reward signal. revision: yes
Circularity Check
No circularity: model proposal and empirical gains are independent of self-defined quantities
full rationale
The paper defines SCPRM as a new process reward model that conditions on reasoning prefixes and adds a schema-distance term to an implicit target parsed from the query. It then reports measured Hits@k improvements on external KGQA benchmarks against independent baselines. No equations, uniqueness theorems, or fitted parameters are shown to reduce by construction to the authors' own inputs; the reported 1.18% gain is an external-task measurement rather than a self-referential prediction. The derivation chain therefore remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Knowledge graphs possess usable schemas that allow distance computation between reasoning steps and an implicit target entity.
invented entities (1)
-
Implicit target parsed from the query
no independent evidence
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.AlphaCoordinateFixationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our reward function is defined as F(n) = G(n) + H(n), where G(n) denotes cumulative past rewards and H(n) indicates future rewards.
-
Cost.JcostJcost (J(x)=½(x+x⁻¹)−1) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
G(s_k) = r_past(π(k)) = log Π (1 - p_t) = Σ log(1 - p_t).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J. Baek, A. F. Aji, and A. Saffari. Knowledge-augmented language model prompting for zero-shot knowledge graph question answering. InProceedings of the 1st Workshop on Natural Language Reasoning and Structured Explanations (NLRSE), pages 78–106, 2023
2023
-
[2]
K. D. Bollacker, C. Evans, P. K. Paritosh, T. Sturge, and J. Taylor. Freebase: a collaboratively created graph database for structuring human knowledge. InProceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2008, Vancouver, BC, Canada, June 10-12, 2008, pages 1247–1250. ACM, 2008
2008
-
[3]
Bordes, N
A. Bordes, N. Usunier, A. García-Durán, J. Weston, and O. Yakhnenko. Translating embeddings for modeling multi-relational data. InAdvances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013. Proceedings of a meeting held December 5-8, 2013, Lake Tahoe, Nevada, United States, pages 2787–2795, 2013
2013
-
[4]
C. Bu, G. Chang, Z. Chen, C. Dang, Z. Wu, Y . He, and X. Wu. Query-driven multimodal graphrag: Dynamic local knowledge graph construction for online reasoning. InFindings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025, Findings of ACL, pages 21360–21380. Association for Computational Linguistics, 2025
2025
-
[5]
H. Cai, S. Zhao, L. Zhang, X. Shen, Q. Xu, W. Shen, Z. Wen, and T. Ban. Unilaw-r1: A large language model for legal reasoning with reinforcement learning and iterative inference. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 18128–18142, 2025
2025
-
[6]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word problems.CoRR, abs/2110.14168, 2021
work page internal anchor Pith review arXiv 2021
-
[7]
H. Cui, T. Peng, R. Han, J. Han, and L. Liu. Path-based multi-hop reasoning over knowledge graph for answering questions via adversarial reinforcement learning.Knowl. Based Syst., 276:110760, 2023
2023
-
[8]
S. Cui, S. Yu, H.-Y . Huang, Y .-C.-D. Lin, Y . Huang, B. Zhang, J. Xiao, H. Zuo, J. Wang, and Z. Li. mirtarbase 2025: updates to the collection of experimentally validated microrna–target interactions.Nucleic Acids Res., 53(D1):D147–D156, 2025
2025
-
[9]
R. Das, S. Dhuliawala, M. Zaheer, L. Vilnis, I. Durugkar, A. Krishnamurthy, A. Smola, and A. McCallum. Go for a walk and arrive at the answer: Reasoning over paths in knowledge bases using reinforcement learning. In6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings, 2018
2018
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.CoRR, abs/2501.12948, 2025
work page internal anchor Pith review arXiv 2025
-
[11]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
A. Gunjal, A. Wang, E. Lau, V . Nath, B. Liu, and S. Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains.CoRR, abs/2507.17746, 2025
work page internal anchor Pith review arXiv 2025
-
[12]
P. E. Hart, N. J. Nilsson, and B. Raphael. A formal basis for the heuristic determination of minimum cost paths.IEEE transactions on Systems Science and Cybernetics, 4(2):100–107, 1968. 10
1968
-
[13]
Huang, J
Z. Huang, J. Shi, Y . Gao, C. Cui, S. Zhang, J. Li, Y . Zhou, and Q. Cui. HMDD v3.0: a database for experimentally supported human microrna-disease associations.Nucleic Acids Res., 47(Database-Issue):D1013–D1017, 2019
2019
-
[14]
Reinforcement learning with rubric anchors
Z. Huang, Y . Zhuang, G. Lu, Z. Qin, H. Xu, T. Zhao, R. Peng, J. Hu, Z. Shen, X. Hu, X. Gu, P. Tu, J. Liu, W. Chen, Y . Fu, Z. Fan, Y . Gu, Y . Wang, Z. Yang, J. Li, and J. Zhao. Reinforcement learning with rubric anchors.CoRR, abs/2508.12790, 2025
-
[15]
Jiang, Y
S. Jiang, Y . Liao, Z. Chen, Y . Zhang, Y . Wang, and Y . Wang. Meds3: Towards medical slow thinking with self-evolved soft dual-sided process supervision. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 31319–31327, 2026
2026
-
[16]
J. Li, P. Cao, Y . Chen, J. Xu, H. Li, X. Jiang, K. Liu, and J. Zhao. Towards better chain-of- thought: A reflection on effectiveness and faithfulness. InFindings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025, Findings of ACL, pages 10747–10765. Association for Computational Linguistics, 2025
2025
-
[17]
Q. Li, X. Dai, X. Li, W. Zhang, Y . Wang, R. Tang, and Y . Yu. Codeprm: Execution feedback- enhanced process reward model for code generation. InFindings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025, pages 8169–
2025
-
[18]
Association for Computational Linguistics, 2025
2025
-
[19]
S. Li, Z. Liu, Z. Gui, H. Chen, and W. Zhang. Enrich-on-graph: Query-graph alignment for complex reasoning with LLM enriching. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP 2025, Suzhou, China, November 4-9, 2025, pages 7672–7692. Association for Computational Linguistics, 2025
2025
-
[20]
Li and Y
W. Li and Y . Li. Process reward model with q-value rankings. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025, 2025
2025
-
[21]
Lightman, V
H. Lightman, V . Kosaraju, Y . Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024, 2024
2024
-
[22]
X. V . Lin, R. Socher, and C. Xiong. Multi-hop knowledge graph reasoning with reward shaping. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018, pages 3243–3253. Association for Computational Linguistics, 2018
2018
-
[23]
L. Luo, Y . Li, G. Haffari, and S. Pan. Reasoning on graphs: Faithful and interpretable large lan- guage model reasoning. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024, 2024
2024
-
[24]
C. Ma, Y . Chen, T. Wu, A. Khan, and H. Wang. Large language models meet knowledge graphs for question answering: Synthesis and opportunities. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP 2025, Suzhou, China, November 4-9, 2025, pages 24578–24597. Association for Computational Linguistics, 2025
2025
-
[25]
Mavromatis and G
C. Mavromatis and G. Karypis. GNN-RAG: graph neural retrieval for efficient large language model reasoning on knowledge graphs. InFindings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025, Findings of ACL, pages 16682–16699. Association for Computational Linguistics, 2025
2025
-
[26]
T. Mu, A. Helyar, J. Heidecke, J. Achiam, A. Vallone, I. Kivlichan, M. Lin, A. Beutel, J. Schul- man, and L. Weng. Rule based rewards for language model safety. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, 2024
2024
-
[27]
A. Ni, S. Iyer, D. Radev, V . Stoyanov, W. Yih, S. I. Wang, and X. V . Lin. LEVER: learning to verify language-to-code generation with execution. InInternational Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 ofProceedings of Machine Learning Research, pages 26106–26128, 2023. 11
2023
-
[28]
Ouyang, J
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. F. Christiano, J. Leike, and R. Lowe. Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems 35: ...
2022
-
[29]
X. Song, S. Zhang, and T. Yu. Rekg-mcts: Reinforcing LLM reasoning on knowledge graphs via training-free monte carlo tree search. InFindings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025, pages 9288–9306. Association for Computational Linguistics, 2025
2025
-
[30]
J. Sun, C. Xu, L. Tang, S. Wang, C. Lin, Y . Gong, L. Ni, H.-Y . Shum, and J. Guo. Think-on- graph: Deep and responsible reasoning of large language model on knowledge graph. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[31]
Z. Sun, Z. Deng, J. Nie, and J. Tang. Rotate: Knowledge graph embedding by relational rotation in complex space. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019, 2019
2019
-
[32]
Talmor and J
A. Talmor and J. Berant. The web as a knowledge-base for answering complex questions. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2018, New Orleans, Louisiana, USA, June 1-6, 2018, Volume 1 (Long Papers), pages 641–651. Association for Computat...
2018
-
[33]
X. Tan, X. Wang, Q. Liu, X. Xu, X. Yuan, and W. Zhang. Paths-over-graph: Knowledge graph empowered large language model reasoning. InProceedings of the ACM on Web Conference 2025, WWW 2025, Sydney, NSW, Australia, 28 April 2025- 2 May 2025, pages 3505–3522. ACM, 2025
2025
-
[34]
Turpin, J
M. Turpin, J. Michael, E. Perez, and S. R. Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023
2023
-
[35]
Solving math word problems with process- and outcome-based feedback
J. Uesato, N. Kushman, R. Kumar, H. F. Song, N. Y . Siegel, L. Wang, A. Creswell, G. Irving, and I. Higgins. Solving math word problems with process- and outcome-based feedback.CoRR, abs/2211.14275, 2022
work page Pith review arXiv 2022
-
[36]
H. Wang, C. Gao, Q. Xu, B. Liu, G. Hussein, H. R. Korsapati, M. E. Labban, K. Iheasirim, M. Hassan, and G. Anil. Process-supervised reward models for verifying clinical note generation: A scalable approach guided by domain expertise. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 19138–19158, 2025
2025
-
[37]
P. Wang, L. Li, Z. Shao, R. Xu, D. Dai, Y . Li, D. Chen, Y . Wu, and Z. Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 9426–9439, 2024
2024
- [38]
-
[39]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. H. Chi, Q. V . Le, and D. Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022
2022
-
[40]
Xiong, T
W. Xiong, T. Hoang, and W. Y . Wang. Deeppath: A reinforcement learning method for knowledge graph reasoning. InProceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, EMNLP 2017, Copenhagen, Denmark, September 9-11, 2017, pages 564–573. Association for Computational Linguistics, 2017. 12
2017
-
[41]
J. Xu, H. Fei, H. Zhou, X. Quan, Q. Huang, S. Wu, W. Y . Wang, M.-L. Lee, and W. Hsu. Logicreward: Incentivizing llm reasoning via step-wise logical supervision.The International Conference on Learning Representations, 2026
2026
-
[42]
S. Yao, D. Yu, J. Zhao, I. Shafran, T. Griffiths, Y . Cao, and K. Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023
2023
- [43]
-
[44]
F. Yu, A. Gao, and B. Wang. Ovm, outcome-supervised value models for planning in mathe- matical reasoning. InFindings of the Association for Computational Linguistics: NAACL 2024, Mexico City, Mexico, June 16-21, 2024, pages 858–875, 2024
2024
-
[45]
J. Yun, J. Sohn, J. Park, H. Kim, X. Tang, Y . Shao, Y . Koo, M. Ko, Q. Chen, M. Gerstein, M. Moor, and J. Kang. Med-prm: Medical reasoning models with stepwise, guideline-verified process rewards. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 16565–16582, 2025
2025
-
[46]
Zhang, S
D. Zhang, S. Zhoubian, Z. Hu, Y . Yue, Y . Dong, and J. Tang. Rest-mcts*: LLM self-training via process reward guided tree search. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, 2024
2024
-
[47]
Z. Zhang, Z. Shan, K. Song, Y . Li, and K. Ren. Linking process to outcome: Conditional reward modeling for LLM reasoning.CoRR, abs/2509.26578, 2025
-
[48]
C. Zheng, J. Zhu, Z. Ou, Y . Chen, K. Zhang, R. Shan, Z. Zheng, M. Yang, J. Lin, Y . Yu, and W. Zhang. A survey of process reward models: From outcome signals to process supervisions for large language models.CoRR, abs/2510.08049, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.