Recognition: 2 theorem links
· Lean TheoremStanding on the Shoulders of Giants: Stabilized Knowledge Distillation for Cross--Language Code Clone Detection
Pith reviewed 2026-05-08 17:53 UTC · model grok-4.3
The pith
Stabilized knowledge distillation transfers reasoning from large models to make compact models reliable for detecting code clones across languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
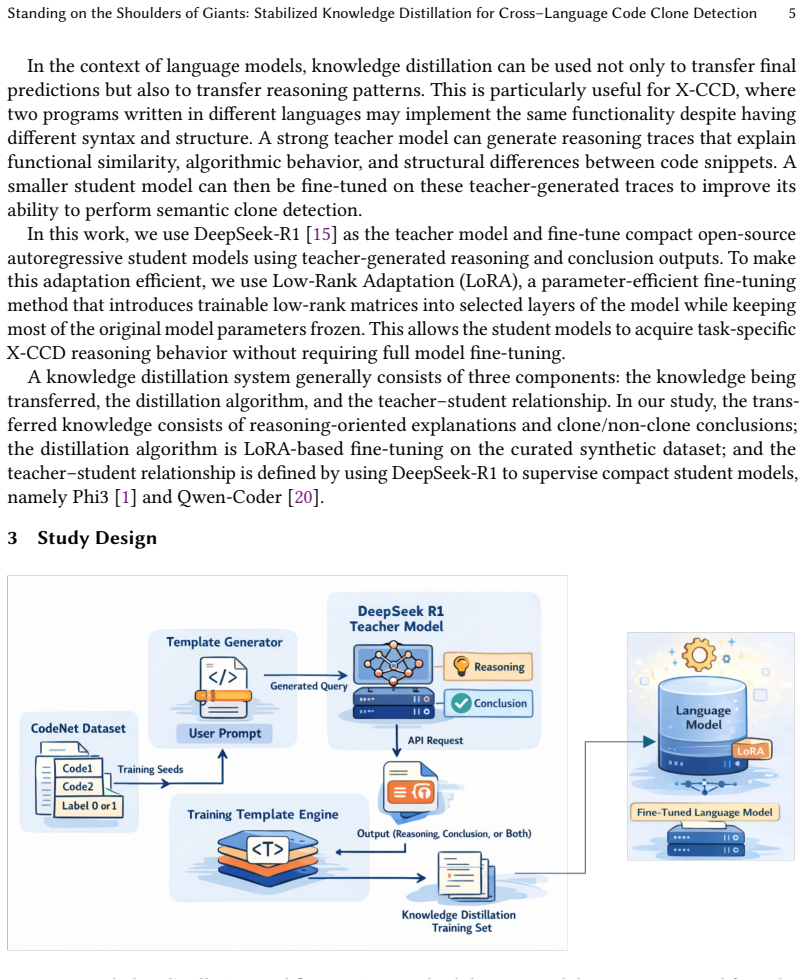
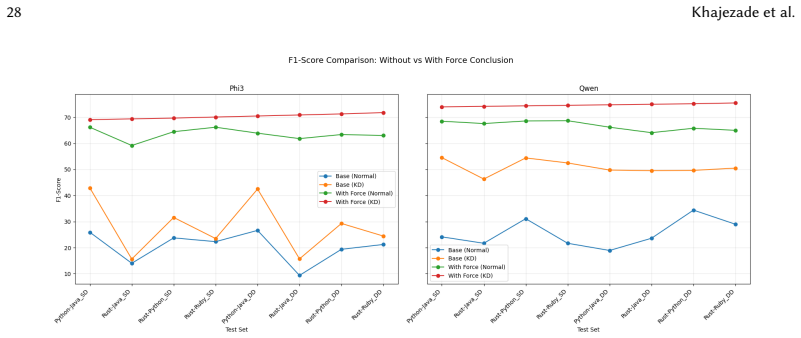
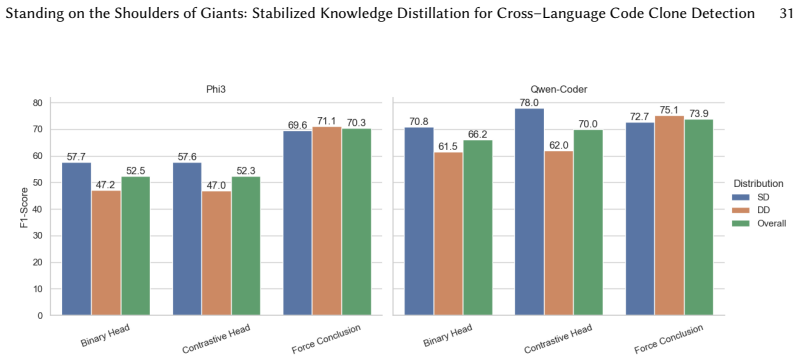
The paper claims that a distillation process which transfers reasoning-oriented capabilities from a large model into compact student models via synthetic cross-language code pairs, followed by response stabilization through forced conclusion prompting and the addition of binary or contrastive classification heads, produces outputs that can be reliably mapped to binary clone labels, improves predictive performance in many cases, and reduces inference time relative to generation-only inference.
What carries the argument
Response stabilization methods consisting of forced conclusion prompting, a binary classification head, and a contrastive classification head, which convert the model's output into consistent binary decisions while preserving the transferred reasoning.
Load-bearing premise
The synthetic reasoning examples generated by the large model supply a generalizable clone-detection logic that transfers cleanly to compact models and to real-world code pairs.
What would settle it
If stabilized compact models show no gain in response consistency or detection accuracy on a fresh collection of cross-language code pairs drawn from actual developer projects, the claimed benefit would not hold.
Figures





read the original abstract
Cross-language code clone detection (X-CCD) is challenging because semantically equivalent programs written in different languages often share little surface similarity. Although large language models (LLMs) have shown promise for semantic clone detection, their use as black-box systems raises concerns about cost, reproducibility, privacy, and unreliable output formatting. In particular, compact open-source models often struggle to follow reasoning-oriented prompts and to produce outputs that can be consistently mapped to binary clone labels. To address these limitations, we propose a knowledge distillation framework that transfers reasoning capabilities from DeepSeek-R1 into compact open-source student models for X-CCD. Using cross-language code pairs derived from Project CodeNet, we construct reasoning-oriented synthetic training data and fine-tune Phi3 and Qwen-Coder with LoRA adapters. We further introduce response stabilization methods, including forced conclusion prompting, a binary classification head, and a contrastive classification head, and evaluate model behavior using both predictive metrics and response rate. Experiments on Python--Java, Rust--Java, Rust--Python, and Rust--Ruby show that knowledge distillation consistently improves the reliability of compact models and often improves predictive performance, especially under distribution shift. In addition, classification-head variants substantially reduce inference time compared to generation-based inference. Overall, our results show that reasoning-oriented distillation combined with response stabilization makes compact open-source models more practical and reliable for X-CCD detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a knowledge distillation framework to transfer reasoning capabilities from DeepSeek-R1 to compact open-source models (Phi-3 and Qwen-Coder) for cross-language code clone detection (X-CCD). Using synthetic reasoning-oriented data constructed from Project CodeNet cross-language pairs, the authors fine-tune student models with LoRA and introduce response stabilization techniques (forced conclusion prompting, binary classification head, contrastive classification head). Experiments on Python-Java, Rust-Java, Rust-Python, and Rust-Ruby pairs report improved reliability, predictive performance (especially under distribution shift), and faster inference for classification-head variants compared to generation-based inference.
Significance. If the quantitative results and controls hold, the work demonstrates a practical path to making smaller open-source models reliable for semantic X-CCD tasks, addressing cost, reproducibility, privacy, and output consistency issues with large black-box LLMs. The emphasis on reasoning-oriented distillation plus stabilization is a targeted contribution that could improve deployability in code analysis pipelines.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: The claims of 'consistent reliability gains' and 'often improves predictive performance' are stated without any numerical metrics, baseline comparisons (e.g., against non-distilled Phi-3/Qwen-Coder or prior X-CCD methods), statistical significance tests, or details on data splits and distribution-shift construction. This absence prevents assessment of effect sizes and undermines support for the central claim of improved practicality.
- [Experiments] Data construction and evaluation (Experiments section): The central assumption that synthetic reasoning data from DeepSeek-R1 encodes generalizable clone-detection logic (rather than teacher-specific biases or prompt artifacts) is load-bearing but untested. No ablations isolate reasoning transfer from format mimicry or CodeNet artifacts, and all reported gains use held-out pairs from the same source; this leaves the transferability claim unsupported.
minor comments (2)
- [Abstract] The abstract would benefit from one or two key quantitative results (e.g., accuracy deltas or response-rate improvements) to give readers an immediate sense of the gains.
- [Method] Notation for the stabilization methods (forced conclusion prompting, binary/contrastive heads) should be defined more explicitly when first introduced, including how the binary label is extracted from generated text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to strengthen the clarity of our quantitative claims and the validation of our distillation approach. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The claims of 'consistent reliability gains' and 'often improves predictive performance' are stated without any numerical metrics, baseline comparisons (e.g., against non-distilled Phi-3/Qwen-Coder or prior X-CCD methods), statistical significance tests, or details on data splits and distribution-shift construction. This absence prevents assessment of effect sizes and undermines support for the central claim of improved practicality.
Authors: We agree that the abstract would benefit from explicit numerical support for the central claims. In the revised version we will update the abstract to report key metrics (e.g., reliability rates, accuracy deltas under distribution shift, and inference-time reductions) drawn from the Experiments section. The Experiments section already contains comparisons against the non-distilled Phi-3 and Qwen-Coder baselines, details on the Project CodeNet splits, and the construction of the distribution-shift test sets; however, we will add (i) explicit comparisons against representative prior X-CCD methods and (ii) statistical significance tests (paired t-tests across seeds) to make effect sizes and reliability gains easier to assess. revision: yes
-
Referee: [Experiments] Data construction and evaluation (Experiments section): The central assumption that synthetic reasoning data from DeepSeek-R1 encodes generalizable clone-detection logic (rather than teacher-specific biases or prompt artifacts) is load-bearing but untested. No ablations isolate reasoning transfer from format mimicry or CodeNet artifacts, and all reported gains use held-out pairs from the same source; this leaves the transferability claim unsupported.
Authors: We acknowledge that isolating the contribution of reasoning-oriented distillation from format mimicry or dataset artifacts is necessary to substantiate the transferability claim. Our current evaluation uses held-out CodeNet pairs to demonstrate within-distribution generalization, and the response-stabilization techniques (forced conclusion prompting and classification heads) were introduced precisely to reduce format artifacts. To strengthen the evidence, we will add two ablations in the revised Experiments section: (1) a direct comparison of reasoning-oriented distillation versus standard supervised fine-tuning on identical CodeNet pairs (to separate reasoning transfer from format mimicry), and (2) an evaluation on an additional cross-language split constructed to increase distribution shift beyond the original held-out sets. These additions will provide a clearer test of whether the distilled logic generalizes beyond teacher-specific or CodeNet-specific patterns. revision: yes
Circularity Check
No circularity: empirical KD setup uses external teacher and held-out evaluation
full rationale
The paper presents a standard empirical knowledge-distillation pipeline: synthetic reasoning data is generated by an external model (DeepSeek-R1) on Project CodeNet pairs, students (Phi-3, Qwen-Coder) are fine-tuned with LoRA, and performance is measured on held-out cross-language splits. No equations, self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. All claims rest on externally generated data and separate test sets rather than reducing to the training inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic reasoning traces produced by DeepSeek-R1 on Project CodeNet pairs constitute effective supervision for student models on unseen cross-language code.
Lean theorems connected to this paper
-
Cost.FunctionalEquation (J(x)=½(x+x⁻¹)−1, washburn_uniqueness_aczel)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lcon = -(1/N) Σ (1/|P(i)|) Σ log exp(s_ij)/Σ exp(s_ik); Ltotal = L_BCE + λ L_con
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, et al. 2024. Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone.arXiv preprint arXiv:2404.14219(2024)
work page internal anchor Pith review arXiv 2024
-
[2]
Amal Alazba, Hamoud Aljamaan, and Mohammad Alshayeb. 2024. Cort: transformer-based code representations with self-supervision by predicting reserved words for code smell detection.Empirical Software Engineering29, 3 (2024), 59
2024
-
[3]
Asra Sulaiman Alshabib, Sajjad Mahmood, and Mohammad Alshayeb. 2025. A systematic literature review on cross-language source code clone detection.Computer Science Review58 (2025), 100786
2025
-
[4]
Baxter, Andrew Yahin, Leonardo Moura, Marcelo Sant’Anna, and Lorraine Bier
Ira D. Baxter, Andrew Yahin, Leonardo Moura, Marcelo Sant’Anna, and Lorraine Bier. 1998. Clone Detection Using Abstract Syntax Trees. InProceedings of the International Conference on Software Maintenance (ICSM). IEEE Computer Society, 368–377. https://doi.org/10.1109/ICSM.1998.738528
- [5]
-
[6]
Giordano d’Aloisio, Luca Traini, Federica Sarro, and Antinisca Di Marco. 2025. On the compression of language models for code: An empirical study on codebert. In2025 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 12–23
2025
-
[8]
Shihan Dou, Junjie Shan, Haoxiang Jia, Wenhao Deng, Zhiheng Xi, Wei He, Yueming Wu, Tao Gui, Yang Liu, and Xuanjing Huang. 2023. Towards Understanding the Capability of Large Language Models on Code Clone Detection: A Survey.arXiv preprint arXiv:2308.01191(2023). arXiv:2308.01191 [cs.SE] https://arxiv.org/abs/2308.01191
-
[9]
Yangkai Du, Tengfei Ma, Lingfei Wu, Xuhong Zhang, and Shouling Ji. 2024. AdaCCD: Adaptive Semantic Contrasts Discovery Based Cross Lingual Adaptation for Code Clone Detection. InProceedings of the AAAI Conference on Artificial ACM Trans. Softw. Eng. Methodol., Vol. 1, No. 1, Article . Publication date: May . 36 Khajezade et al. Intelligence, Vol. 38. 17942–17950
2024
-
[10]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. 2020. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. In Findings of the Association for Computational Linguistics: EMNLP 2020. Association for Computational Linguistics, 1536–1547. https://doi.org/10.1...
-
[11]
Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, et al. 2023. Textbooks are all you need.arXiv preprint arXiv:2306.11644(2023)
work page internal anchor Pith review arXiv 2023
-
[12]
Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. 2022. UniXcoder: Unified Cross-Modal Pre-training for Code Representation. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL). Association for Computational Linguistics, 7212–7225. https://doi.org/10.18653/v1/2022.acl-long.499
-
[13]
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, Michele Tufano, Shao Kun Deng, Colin Clement, Dawn Drain, Neel Sundaresan, Jian Yin, Daxin Jiang, and Ming Zhou. 2021. GraphCodeBERT: Pre-training Code Representations with Data Flow. InProceedings of the 9th International Conference o...
2021
-
[15]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review arXiv 2025
- [16]
-
[17]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the Knowledge in a Neural Network.arXiv preprint arXiv:1503.02531(2015)
work page Pith review arXiv 2015
-
[18]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
-
[19]
InInternational Conference on Learning Representations
LoRA: Low-Rank Adaptation of Large Language Models. InInternational Conference on Learning Representations
-
[20]
Baizhou Huang, Shuai Lu, Xiaojun Wan, and Nan Duan. 2024. Enhancing Large Language Models in Coding Through Multi-Perspective Self-Consistency. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Bangkok, Thailand, 1429–1450. https: //doi.org/10.18653...
-
[21]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. 2024. Qwen2.5-Coder Technical Report.arXiv preprint arXiv:2409.12186(2024)
work page internal anchor Pith review arXiv 2024
-
[22]
Lingxiao Jiang, Ghassan Misherghi, Zhendong Su, and Stephane Glondu. 2007. DECKARD: Scalable and Accurate Tree-Based Detection of Code Clones. InProceedings of the 29th International Conference on Software Engineering (ICSE). IEEE Computer Society, 96–105. https://doi.org/10.1109/ICSE.2007.30
-
[23]
Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. 2020. TinyBERT: Distilling BERT for Natural Language Understanding. InFindings of the Association for Computational Linguistics: EMNLP
2020
-
[24]
TinyBERT: Distilling BERT for natural language understanding
Association for Computational Linguistics, 4163–4174. https://doi.org/10.18653/v1/2020.findings-emnlp.372
-
[25]
Toshihiro Kamiya, Shinji Kusumoto, and Katsuro Inoue. 2002. CCFinder: A Multilinguistic Token-Based Code Clone Detection System for Large Scale Source Code. InIEEE Transactions on Software Engineering, Vol. 28. IEEE, 654–670. https://doi.org/10.1109/TSE.2002.1019480
-
[26]
Mohamad Khajezade, Jie JW Wu, Fatemeh Hendijani Fard, Gema Rodríguez-Pérez, and Mohamed Sami Shehata. 2024. Investigating the Efficacy of Large Language Models for Code Clone Detection. InProceedings of the 32nd IEEE/ACM International Conference on Program Comprehension. 161–165
2024
-
[27]
Maggie Lei, Hao Li, Ji Li, Namrata Aundhkar, and Dae-Kyoo Kim. 2022. Deep learning application on code clone detection: A review of current knowledge.Journal of Systems and Software184 (2022), 111141
2022
-
[28]
Yonglin Li, Shanzhi Gu, and Mingyang Geng. 2025. Symmetry-Aware Code Generation: Distilling Pseudocode Reasoning for Lightweight Deployment of Large Language Models.Symmetry17, 8 (2025), 1325
2025
- [29]
- [30]
-
[31]
Chenyao Liu, Zeqi Lin, Jian-Guang Lou, Lijie Wen, and Dongmei Zhang. 2021. Can neural clone detection generalize to unseen functionalitiesƒ. In2021 36th IEEE/ACM International Conference on Automated Software Engineering (ASE). ACM Trans. Softw. Eng. Methodol., Vol. 1, No. 1, Article . Publication date: May . Standing on the Shoulders of Giants: Stabilize...
2021
-
[32]
Min, Yangruibo Ding, Luca Buratti, Saurabh Pujar, Gail Kaiser, Suman Jana, and Baishakhi Ray
Marcus J. Min, Yangruibo Ding, Luca Buratti, Saurabh Pujar, Gail Kaiser, Suman Jana, and Baishakhi Ray. 2023. Beyond Accuracy: Evaluating Self-Consistency of Code Large Language Models with IdentityChain. InProceedings of the 12th International Conference on Learning Representations (ICLR). https://openreview.net/forum?id=caW7LdAALh
2023
-
[33]
Mawal A Mohammed, Mohammad Alshayeb, and Jameleddine Hassine. 2022. A search-based approach for detecting circular dependency bad smell in goal-oriented models.Software and Systems Modeling21, 5 (2022), 2007–2037
2022
- [34]
-
[35]
Micheline Bénédicte Moumoula, Abdoul Kader Kaboré, Jacques Klein, and Tegawendé F Bissyandé. 2025. The Struggles of LLMs in Cross-Lingual Code Clone Detection.Proceedings of the ACM on Software Engineering2, FSE (2025), 1023–1045
2025
-
[36]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training Language Models to Follow Instructions with Human Fee...
2022
-
[37]
Ruchir Puri, David S Kung, Geert Janssen, Wei Zhang, Giacomo Domeniconi, Vladimir Zolotov, Julian Dolby, Jie Chen, Mihir Choudhury, Lindsey Decker, et al. 2021. Codenet: A large-scale ai for code dataset for learning a diversity of coding tasks.arXiv preprint arXiv:2105.12655(2021)
-
[38]
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter.arXiv preprint arXiv:1910.01108(2019). arXiv:1910.01108 [cs.CL] https://arxiv. org/abs/1910.01108
work page internal anchor Pith review arXiv 2019
-
[39]
Jieke Shi, Zhou Yang, Bowen Xu, Hong Jin Kang, Hongwei He, David Lo Lu, and David Lo. 2024. Greening Large Language Models of Code. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP ’24). Association for Computing Machinery, 142–153. https://doi.org/10. 1145/3639475.3640097
-
[40]
Jieke Shi, Zhou Yang, Bowen Xu, Hong Jin Kang Liu, Hongwei He, David Lo Lu, and David Lo. 2022. Compressing Pre-trained Models of Code into 3 MB. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering (ASE ’22). Association for Computing Machinery. https://doi.org/10.1145/3551349.3556964
-
[41]
Tim Sonnekalb, Bernd Gruner, Clemens-Alexander Brust, and Patrick Mäder. 2022. Generalizability of code clone detection on codebert. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering. 1–3
2022
-
[42]
Nikita Sorokin, Tikhonov Anton, Dmitry Abulkhanov, Ivan Sedykh, Irina Piontkovskaya, and Valentin Malykh. 2025. CCT-Code: Cross-Consistency Training for Multilingual Clone Detection and Code Search. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Vol...
-
[43]
Chenning Tao, Qi Zhan, Xing Hu, and Xin Xia. 2022. C4: Contrastive cross-language code clone detection. InProceedings of the 30th IEEE/ACM International Conference on Program Comprehension. 413–424
2022
-
[44]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Alpaca: A Strong, Replicable Instruction-Following Model. https://crfm.stanford.edu/2023/03/13/ alpaca.html
2023
-
[45]
Boshi Wang, Sewon Min, Xiang Deng, Jiaming Shen, You Wu, Luke Zettlemoyer, and Huan Sun. 2023. Towards Understanding Chain-of-Thought Prompting: An Empirical Study of What Matters. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (Eds.). A...
- [47]
-
[48]
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. 2020. MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers. InAdvances in Neural Information Processing Systems, Vol. 33. 5776–5788. https://proceedings.neurips.cc/paper/2020/hash/3f5ee243547dee91fbd053c1c4a845aa- Abstract.html
2020
-
[49]
Le, Ed H
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-Consistency Improves Chain of Thought Reasoning in Language Models. InProceedings of the 11th ACM Trans. Softw. Eng. Methodol., Vol. 1, No. 1, Article . Publication date: May . 38 Khajezade et al. International Conference on Learn...
2022
-
[50]
Yue Wang, Weishi Wang, Shafiq Joty, and Steven C. H. Hoi. 2021. CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, 8696–8708. https: //doi.org/10.18653/v1/2021....
-
[51]
Finetuned Language Models Are Zero-Shot Learners
Jason Wei, Maarten Bosma, Vincent Y. Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V. Le. 2021. Finetuned Language Models Are Zero-Shot Learners.arXiv preprint arXiv:2109.01652(2021)
work page internal anchor Pith review arXiv 2021
-
[52]
Violet Xiang, Charlie Snell, Kanishk Gandhi, Alon Albalak, Anikait Singh, Chase Blagden, Duy Phung, Rafael Rafailov, Nathan Lile, Dakota Mahan, et al . 2025. Towards system 2 reasoning in llms: Learning how to think with meta chain-of-thought.arXiv preprint arXiv:2501.04682(2025)
- [53]
-
[54]
Cheng Yang, Chufan Shi, Siheng Li, Bo Shui, Yujiu Yang, and Wai Lam. 2025. Llm2: Let large language models harness system 2 reasoning. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). 168–177
2025
-
[55]
Hao Yu, Wing Lam, Long Chen, Ge Li, Tao Xie, and Qianxiang Wang. 2019. Neural detection of semantic code clones via tree-based convolution. In2019 IEEE/ACM 27th International Conference on Program Comprehension (ICPC). IEEE, 70–80
2019
-
[56]
Dejiao Zhang, Wasi Uddin Ahmad, Ming Tan, Hantian Ding, Ramesh Nallapati, Dan Roth, Xiaofei Ma, and Bing Xiang
-
[57]
InProceedings of the 12th International Conference on Learning Representations (ICLR)
CodeSage: Code Representation Learning at Scale. InProceedings of the 12th International Conference on Learning Representations (ICLR). https://openreview.net/forum?id=vfzRRjumpX
-
[58]
Haibo Zhang and Kouichi Sakurai. 2021. A survey of software clone detection from security perspective.IEEE Access9 (2021), 48157–48173
2021
-
[59]
Renrui Zhang, Jiaming Han, Chris Liu, Peng Gao, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, and Yu Qiao. 2023. LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention.arXiv preprint arXiv:2303.16199(2023)
work page Pith review arXiv 2023
-
[60]
Maksim Zubkov, Egor Spirin, Egor Bogomolov, and Timofey Bryksin. 2022. Evaluation of contrastive learning with various code representations for code clone detection.arXiv preprint arXiv:2206.08726(2022). ACM Trans. Softw. Eng. Methodol., Vol. 1, No. 1, Article . Publication date: May
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.