Recognition: no theorem link
Delay, Plateau, or Collapse: Evaluating the Impact of Systematic Verification Error on RLVR
Pith reviewed 2026-05-10 18:49 UTC · model grok-4.3
The pith
Systematic verification errors can drive RLVR into plateaus or collapse rather than mere delays.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
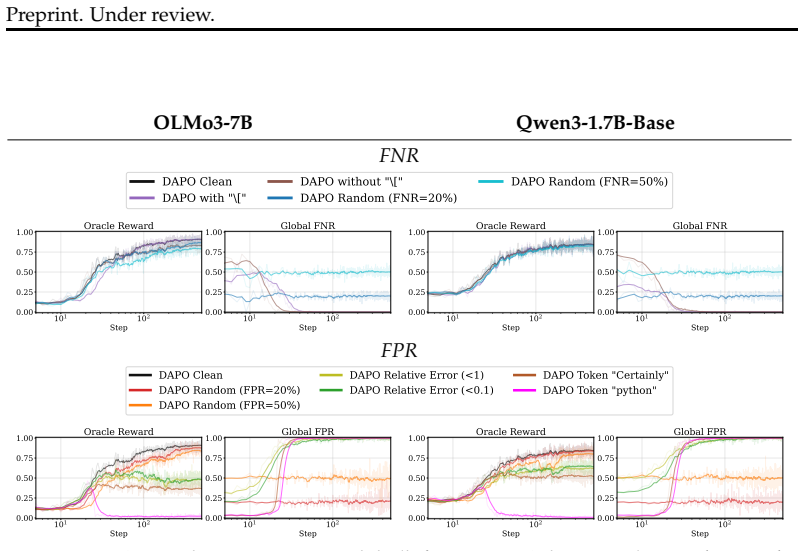
Through controlled experiments on arithmetic tasks, systematic false negatives produce effects similar to random noise by only delaying progress, while systematic false positives trigger a range of outcomes from sub-optimal plateaus to outright performance collapse. These results depend on the exact pattern of introduced errors rather than the overall error rate, allowing models to internalize unwanted but consistent responses from the flawed reward signal.
What carries the argument
The specific pattern of systematic false positives introduced into the reward signal for generated answers, which creates a structurally incorrect but consistent training objective.
If this is right
- Models can learn to produce answers that exploit the verifier's systematic mistakes instead of correct reasoning.
- Training success hinges on the structure of errors more than on the verifier's overall accuracy.
- RLVR can fail to improve or degrade when verifiers contain certain false-positive patterns even at low error rates.
- Mitigation before training is difficult without detailed knowledge of the error patterns.
Where Pith is reading between the lines
- Verifier development should target detection and removal of systematic biases in addition to lowering random error rates.
- Comparable risks likely exist in code-generation settings where static analyzers have recurring limitations.
- Repeating the controlled experiments on non-arithmetic tasks would test whether the plateau and collapse behaviors generalize.
Load-bearing premise
The patterns of systematic errors created for the arithmetic tasks match the kinds of errors that appear in real-world verifiers used for RLVR.
What would settle it
Apply a real-world verifier known to have patterned false positives, such as a static code checker with documented biases, to RLVR training and measure whether the model performance plateaus or collapses as the error pattern predicts.
Figures









read the original abstract
Reinforcement Learning with Verifiable Rewards (RLVR) has become a powerful approach for improving the reasoning capabilities of large language models (LLMs). While RLVR is designed for tasks with verifiable ground-truth answers, real-world verifiers (e.g., static code checkers) can introduce errors into the reward signal. Prior analyses have largely treated such errors as random and independent across samples, concluding that errors merely slow training with limited effect on final performance. However, practical verifiers tend to exhibit systematic errors. This introduces a risk of models learning unwanted consistent behavior from a structurally incorrect reward signal. In this work, we study the impact of such systematic verification errors on RLVR. Through controlled experiments on arithmetic tasks, we show that systematic false negatives lead to similar effects as random noise. On the other hand, systematic false positives can cause a wide range of behaviors from sub-optimal plateaus to performance collapse. Crucially, these outcomes are not determined by the overall error rate but by the specific pattern of introduced errors, making pre-hoc mitigation difficult. Our results show that, in contrast to prior conclusions, realistic verification errors can critically shape RLVR outcomes and that verifier quality has to be understood beyond its sample-level error rate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the effects of systematic (as opposed to random) verification errors on Reinforcement Learning with Verifiable Rewards (RLVR) for improving LLM reasoning. Through controlled experiments on arithmetic tasks, it finds that systematic false negatives produce effects similar to random noise, while systematic false positives can induce suboptimal plateaus or outright performance collapse; crucially, these outcomes depend on the specific structure of the errors rather than the aggregate error rate. The work contrasts this with prior analyses that treated verifier errors as random and concludes that verifier quality must be assessed beyond sample-level accuracy.
Significance. If the empirical patterns hold under broader conditions, the result is significant because it identifies a previously under-appreciated failure mode in RLVR pipelines: structured reward corruption can produce qualitatively worse training dynamics than unstructured noise. The controlled arithmetic-task design isolates error-type effects cleanly and supplies concrete evidence that pre-hoc mitigation is difficult when error patterns are unknown, which has direct implications for verifier engineering in code-generation and mathematical-reasoning applications.
major comments (2)
- [§3] §3 (Error Model and Injection): The specific systematic false-positive patterns injected into the arithmetic reward signal are presented as representative of real-world verifiers, yet the manuscript provides no empirical mapping or citation showing that these patterns (e.g., consistent acceptance of particular incorrect answers) occur in deployed checkers such as expression evaluators or static code analyzers. Because the central claim is that “realistic verification errors can critically shape RLVR outcomes,” this unverified representativeness is load-bearing.
- [§4.2] §4.2 (Training Curves and Collapse Regimes): The reported collapse under certain false-positive regimes is shown via single-run learning curves; without reported variance across random seeds, statistical significance tests, or ablation on model scale, it remains unclear whether the collapse is a robust phenomenon or sensitive to initialization and hyper-parameters. This weakens the contrast drawn with prior random-error baselines.
minor comments (2)
- [Introduction] The abstract and introduction cite “prior conclusions” about random errors but do not list the specific references; adding explicit citations in the related-work section would clarify the contrast.
- [Figures] Figure captions for the arithmetic-task results could explicitly state the exact false-positive pattern (e.g., “always rewards answers ending in 0”) rather than generic labels, improving reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments, which help clarify the scope and robustness of our findings on systematic verification errors in RLVR. We address each major comment below and are prepared to revise the manuscript accordingly to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [§3] §3 (Error Model and Injection): The specific systematic false-positive patterns injected into the arithmetic reward signal are presented as representative of real-world verifiers, yet the manuscript provides no empirical mapping or citation showing that these patterns (e.g., consistent acceptance of particular incorrect answers) occur in deployed checkers such as expression evaluators or static code analyzers. Because the central claim is that “realistic verification errors can critically shape RLVR outcomes,” this unverified representativeness is load-bearing.
Authors: We agree that stronger justification for the chosen error patterns would improve the manuscript. Our patterns were selected to reflect plausible systematic biases that arise in practice, such as incomplete rule coverage in expression parsers or consistent misclassification of specific arithmetic edge cases (e.g., sign errors or operator precedence issues). In the revised version we will expand §3 with additional discussion and citations to existing literature on verifier error modes in mathematical reasoning and code evaluation pipelines, thereby better grounding the representativeness claim without altering the experimental design. revision: yes
-
Referee: [§4.2] §4.2 (Training Curves and Collapse Regimes): The reported collapse under certain false-positive regimes is shown via single-run learning curves; without reported variance across random seeds, statistical significance tests, or ablation on model scale, it remains unclear whether the collapse is a robust phenomenon or sensitive to initialization and hyper-parameters. This weakens the contrast drawn with prior random-error baselines.
Authors: We acknowledge that single-run curves provide limited evidence of robustness. Although the collapse behavior appeared consistently in our internal multi-seed checks, we did not report variance or conduct formal statistical tests in the submitted manuscript. We will revise §4.2 to include results aggregated over multiple random seeds (with mean and standard deviation), add statistical comparisons against the random-error baselines, and include a limitations paragraph noting that the study uses a fixed model scale to isolate error-pattern effects; we will also discuss the implications for larger models as future work. revision: yes
Circularity Check
No significant circularity in empirical RLVR error analysis
full rationale
The paper is an empirical study that runs controlled RLVR training experiments on arithmetic tasks while injecting specific patterns of systematic false-positive and false-negative verification errors. It reports observed outcomes (plateaus, collapse, or delay) and contrasts them against prior random-error baselines. No equations, derivations, or first-principles results are presented that reduce to fitted parameters or self-citations by construction. The central claim rests on experimental observations rather than any self-definitional loop, uniqueness theorem imported from the authors' prior work, or renaming of known results. The analysis is therefore self-contained against external benchmarks and receives a score of 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption RLVR training dynamics are governed by standard policy-gradient or value-based reinforcement learning updates
Reference graph
Works this paper leans on
-
[2]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models. arXiv preprint arXiv:2508.06471, 2025
work page internal anchor Pith review arXiv 2025
-
[3]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Bing Liu, and Sean Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains. CoRR, abs/2507.17746, 2025. doi:10.48550/ARXIV.2507.17746. URL https://doi.org/10.48550/arXiv.2507.17746
work page internal anchor Pith review doi:10.48550/arxiv.2507.17746 2025
-
[5]
Rate or fate? rlv r: Reinforcement learning with verifiable noisy rewards
Ali Rad, Khashayar Filom, Darioush Keivan, Peyman Mohajerin Esfahani, and Ehsan Kamalinejad. Rate or fate? rlv r: Reinforcement learning with verifiable noisy rewards. arXiv preprint arXiv:2601.04411, 2026
-
[6]
Xin-Qiang Cai, Wei Wang, Feng Liu, Tongliang Liu, Gang Niu, and Masashi Sugiyama. Reinforcement learning with verifiable yet noisy rewards under imperfect verifiers. arXiv preprint arXiv:2510.00915, 2025
-
[7]
The climb carves wisdom deeper than the summit: On the noisy rewards in learning to reason
Ang Lv, Ruobing Xie, Xingwu Sun, Zhanhui Kang, and Rui Yan. The climb carves wisdom deeper than the summit: On the noisy rewards in learning to reason. arXiv preprint arXiv:2505.22653, 2025
-
[8]
Yuzhen Huang, Weihao Zeng, Xingshan Zeng, Qi Zhu, and Junxian He. From accuracy to robustness: A study of rule-and model-based verifiers in mathematical reasoning. arXiv preprint arXiv:2505.22203, 2025
-
[9]
Yang Chen, Zhuolin Yang, Zihan Liu, Chankyu Lee, Peng Xu, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. Acereason-nemotron: Advancing math and code reasoning through reinforcement learning. arXiv preprint arXiv:2505.16400, 2025
-
[10]
Yulai Zhao, Haolin Liu, Dian Yu, Sunyuan Kung, Meijia Chen, Haitao Mi, and Dong Yu. One token to fool llm-as-a-judge. arXiv preprint arXiv:2507.08794, 2025
-
[11]
Reasoninggym: Reasoningenvironmentsforreinforcementlearningwithverifiable rewards, 2025
Zafir Stojanovski, Oliver Stanley, Joe Sharratt, Richard Jones, Abdulhakeem Adefioye, Jean Kaddour, and Andreas K \"o pf. Reasoning gym: Reasoning environments for reinforcement learning with verifiable rewards. arXiv preprint arXiv:2505.24760, 2025
-
[12]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Y Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, et al. Kimi k2: Open agentic intelligence. arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Team Qwen. Qwen3 technical report, 2025. URL https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Goedel-Prover-V2: Scaling Formal Theorem Proving with Scaffolded Data Synthesis and Self-Correction
Yong Lin, Shange Tang, Bohan Lyu, Ziran Yang, Jui - Hui Chung, Haoyu Zhao, Lai Jiang, Yihan Geng, Jiawei Ge, Jingruo Sun, Jiayun Wu, Jiri Gesi, Ximing Lu, David Acuna, Kaiyu Yang, Hongzhou Lin, Yejin Choi, Danqi Chen, Sanjeev Arora, and Chi Jin. Goedel-prover-v2: Scaling formal theorem proving with scaffolded data synthesis and self-correction. CoRR, abs/...
-
[16]
RLTF: reinforcement learning from unit test feedback
Jiate Liu, Yiqin Zhu, Kaiwen Xiao, Qiang Fu, Xiao Han, Wei Yang, and Deheng Ye. RLTF: reinforcement learning from unit test feedback. Trans. Mach. Learn. Res., 2023, 2023 a . URL https://openreview.net/forum?id=hjYmsV6nXZ
2023
-
[17]
Yuxiang Wei, Olivier Duchenne, Jade Copet, Quentin Carbonneaux, Lingming Zhang, Daniel Fried, Gabriel Synnaeve, Rishabh Singh, and Sida I. Wang. SWE-RL: advancing LLM reasoning via reinforcement learning on open software evolution. CoRR, abs/2502.18449, 2025. doi:10.48550/ARXIV.2502.18449. URL https://doi.org/10.48550/arXiv.2502.18449
-
[18]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective. arXiv preprint arXiv:2503.20783, 2025
work page Pith review arXiv 2025
-
[20]
arXiv preprint arXiv:2511.20347 , year=
Chang Gao, Chujie Zheng, Xiong-Hui Chen, Kai Dang, Shixuan Liu, Bowen Yu, An Yang, Shuai Bai, Jingren Zhou, and Junyang Lin. Soft adaptive policy optimization. arXiv preprint arXiv:2511.20347, 2025
-
[21]
Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. Advances in neural information processing systems, 36: 0 21558--21572, 2023 b
2023
-
[22]
Tinyv: Reducing false negatives in verification improves rl for llm reasoning
Zhangchen Xu, Yuetai Li, Fengqing Jiang, Bhaskar Ramasubramanian, Luyao Niu, Bill Yuchen Lin, and Radha Poovendran. Tinyv: Reducing false negatives in verification improves rl for llm reasoning. arXiv preprint arXiv:2505.14625, 2025
-
[23]
Is llm-as-a-judge robust? investigating universal adversarial attacks on zero-shot llm assessment
Vyas Raina, Adian Liusie, and Mark Gales. Is llm-as-a-judge robust? investigating universal adversarial attacks on zero-shot llm assessment. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 7499--7517, 2024
2024
-
[24]
Variation in Verification: Understanding Verification Dynamics in Large Language Models
Yefan Zhou, Austin Xu, Yilun Zhou, Janvijay Singh, Jiang Gui, and Shafiq Joty. Variation in verification: Understanding verification dynamics in large language models. arXiv preprint arXiv:2509.17995, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Verifybench: A systematic benchmark for evaluating reasoning verifiers across domains
Xuzhao Li, Xuchen Li, Shiyu Hu, Yongzhen Guo, and Wentao Zhang. Verifybench: A systematic benchmark for evaluating reasoning verifiers across domains. In Proceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[26]
Verifybench: Benchmarking reference-based reward systems for large language models
Yuchen Yan, Jin Jiang, Zhenbang Ren, Yijun Li, Xudong Cai, Yang Liu, Xin Xu, Mengdi Zhang, Jian Shao, Yongliang Shen, et al. Verifybench: Benchmarking reference-based reward systems for large language models. arXiv preprint arXiv:2505.15801, 2025
-
[27]
Noisy data is destructive to reinforcement learning with verifiable rewards
Yuxuan Zhu and Daniel Kang. Noisy data is destructive to reinforcement learning with verifiable rewards. arXiv preprint arXiv:2603.16140, 2026
-
[28]
Russell, and Anca D
Dylan Hadfield - Menell, Smitha Milli, Pieter Abbeel, Stuart J. Russell, and Anca D. Dragan. Inverse reward design. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett, editors, Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Sys...
2017
-
[29]
Joar Skalse, Nikolaus H. R. Howe, Dmitrii Krasheninnikov, and David Krueger. Defining and characterizing reward hacking. CoRR, abs/2209.13085, 2022. doi:10.48550/ARXIV.2209.13085. URL https://doi.org/10.48550/arXiv.2209.13085
-
[30]
Scaling laws for reward model overoptimization
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. In International Conference on Machine Learning, pages 10835--10866. PMLR, 2023
2023
-
[31]
Roc-n-reroll: How verifier imperfection affects test-time scaling
Florian E Dorner, Yatong Chen, Andr \'e F Cruz, and Fanny Yang. Roc-n-reroll: How verifier imperfection affects test-time scaling. arXiv preprint arXiv:2507.12399, 2025
-
[32]
TRL: Transformers Reinforcement Learning , 2020
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. TRL: Transformers Reinforcement Learning , 2020. URL https://github.com/huggingface/trl
2020
-
[33]
Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, et al. Olmo 3. arXiv preprint arXiv:2512.13961, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
langdetect , 2021
Michal Danilk and Shuyo Nakatani. langdetect , 2021. URL https://pypi.org/project/langdetect/
2021
-
[35]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.