Recognition: no theorem link
AsymTalker: Identity-Consistent Long-Term Talking Head Generation via Asymmetric Distillation
Pith reviewed 2026-05-12 02:21 UTC · model grok-4.3
The pith
AsymTalker resolves temporal misalignment and identity drift in long talking-head videos by using asymmetric distillation where a teacher model with ground-truth references supervises a student that sees only self-generated references.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AsymTalker anchors the teacher on ground-truth continuity references to supply drift-free chunk supervision and trains the student exclusively on self-generated references through distribution matching, thereby removing the train-inference mismatch that previously forced a choice between drift and quality loss.
What carries the argument
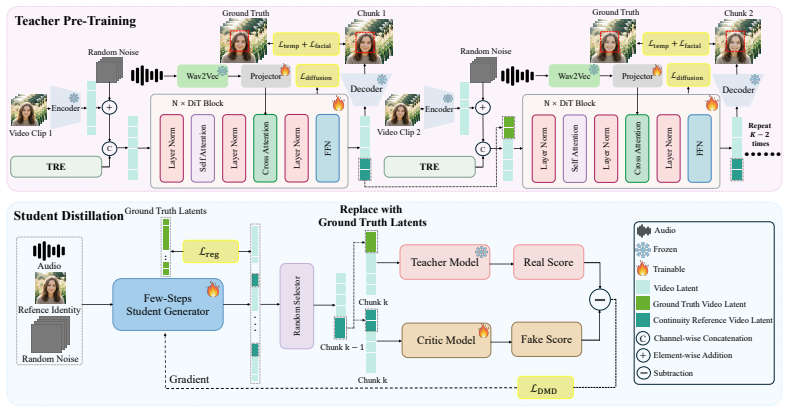
Asymmetric Knowledge Distillation (AKD) paired with Temporal Reference Encoding (TRE): TRE encodes a replicated pseudo-video of the static identity image to produce temporally coherent conditioning without new parameters, while AKD lets the teacher use clean references and the student use inference-style references so supervision stays aligned with deployment.
If this is right
- High-fidelity talking-head synthesis becomes feasible for videos at least 600 seconds long.
- Real-time inference reaches 66 frames per second on standard hardware.
- State-of-the-art identity consistency and visual quality are reported on the HDTF and VFHQ benchmarks.
- No extra parameters are required beyond the base diffusion model once TRE is applied.
Where Pith is reading between the lines
- The same teacher-student split could be tested on other autoregressive video tasks where self-reference causes compounding errors.
- If the method scales, it opens direct use in live virtual meetings or long-form synthetic media without periodic re-initialization.
- Measuring how identity preservation changes when the teacher-student gap in reference quality is widened or narrowed would test the robustness of the distribution-matching step.
Load-bearing premise
The teacher can transfer drift-free guidance to the student across chunk boundaries without creating new mismatches or quality drops that accumulate over hundreds of seconds.
What would settle it
Run the model on a 600-second video, extract identity embeddings from frames spaced 10 seconds apart, and check whether the average embedding distance exceeds the distance seen in short single-chunk baselines; if the long-sequence drift is no smaller than prior chunk-wise methods, the central claim does not hold.
Figures















read the original abstract
Diffusion-based talking head generation has achieved remarkable visual quality, yet scaling it to long-term videos remains challenging. The widely adopted chunk-wise paradigm introduces two fundamental failures: (1) temporal-spatial misalignment between static identity references and dynamic audio streams, and (2) cascading identity drift propagated through self-generated continuity references across chunks. To address both issues, we propose AsymTalker, a novel diffusion-based talking head generation method comprising Temporal Reference Encoding (TRE) and Asymmetric Knowledge Distillation (AKD). First, TRE mitigates temporal-spatial misalignment by transforming the static identity image into a temporally coherent latent representation through encoding of a temporally replicated pseudo-video, without introducing additional parameters. Second, AKD resolves the inherent conditioning dilemma in chunk-wise training: using ground-truth references causes train-inference mismatch, while self-generated references entangle supervision with identity drift. Our asymmetric design circumvents this by anchoring the teacher model with ground-truth continuity references to provide drift-free, chunk-level supervision, thereby avoiding the teacher bottleneck. Meanwhile, the student model learns under inference-aligned conditions, conditioned only on self-generated references, and is trained via distribution matching to preserve identity over long horizons. Extensive experiments show AsymTalker achieves state-of-the-art results on HDTF and VFHQ. It guarantees high-fidelity, identity-consistent synthesis over 600-second videos and reaches a real-time inference speed of 66 FPS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to present AsymTalker, a diffusion-based talking head generation method that uses Temporal Reference Encoding (TRE) and Asymmetric Knowledge Distillation (AKD) to overcome temporal-spatial misalignment and cascading identity drift in chunk-wise video synthesis. It reports achieving state-of-the-art results on the HDTF and VFHQ datasets, identity-consistent high-fidelity synthesis for up to 600-second videos, and real-time performance at 66 FPS.
Significance. Should the claims be substantiated through rigorous experiments, this work would represent a notable advance in long-term video generation for talking heads, offering solutions to persistent issues in maintaining identity consistency over extended durations without additional parameters or quality degradation.
major comments (2)
- [Abstract] Abstract: The central claims of SOTA performance on HDTF and VFHQ, 600-second identity consistency, and 66 FPS inference are asserted without any quantitative metrics, ablation results, baseline comparisons, or error analysis, which are load-bearing for evaluating the method's effectiveness.
- [Abstract] Abstract: The AKD description relies on the unverified assumption that anchoring the teacher with ground-truth references transfers drift-free supervision to the student without new quality losses or mismatches over long sequences, but provides no implementation details on the distribution matching or validation procedure.
minor comments (1)
- [Abstract] Abstract: The text refers to 'extensive experiments' and 'guarantees' but supplies no supporting details on datasets, metrics, or implementation, limiting clarity on how TRE encodes the pseudo-video without additional parameters.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address the major points raised regarding the abstract below, providing clarifications based on the full paper while noting where revisions may strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of SOTA performance on HDTF and VFHQ, 600-second identity consistency, and 66 FPS inference are asserted without any quantitative metrics, ablation results, baseline comparisons, or error analysis, which are load-bearing for evaluating the method's effectiveness.
Authors: We agree that the abstract, being a concise summary, does not embed specific numerical values or tables. The full manuscript contains the requested quantitative support: SOTA comparisons on HDTF and VFHQ (with identity, lip-sync, and quality metrics), ablation studies isolating TRE and AKD, long-horizon consistency evaluations up to 600 seconds, and runtime measurements confirming 66 FPS. We will revise the abstract to include a small number of key quantitative highlights (e.g., representative FID, ID similarity, and FPS figures) to make the claims more immediately verifiable while preserving its brevity. revision: partial
-
Referee: [Abstract] Abstract: The AKD description relies on the unverified assumption that anchoring the teacher with ground-truth references transfers drift-free supervision to the student without new quality losses or mismatches over long sequences, but provides no implementation details on the distribution matching or validation procedure.
Authors: The abstract outlines the core rationale of AKD at a high level. The full paper provides the implementation details: the teacher is conditioned on ground-truth continuity references to supply stable, drift-free targets; the student is trained exclusively under self-generated references to match inference conditions; and distribution matching is performed via a chosen divergence loss whose effectiveness is validated through both short- and long-sequence experiments showing preserved identity and no introduced quality degradation. These elements are substantiated by the reported results rather than left as an unverified assumption. revision: no
Circularity Check
No significant circularity in available text
full rationale
The abstract describes TRE and AKD at a high level without any equations, parameter fittings, derivations, or self-citations that could form a load-bearing chain. Claims of SOTA results, 600-second consistency, and 66 FPS are presented as experimental outcomes rather than reductions to self-defined quantities. No self-definitional, fitted-prediction, or uniqueness-imported steps exist to inspect, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Diffusion models conditioned on audio and identity references can produce high-quality frames when temporal alignment is provided.
- domain assumption Knowledge distillation from a teacher using ground-truth references can guide a student using self-generated references without quality degradation.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.