Recognition: 3 theorem links
· Lean TheoremRefining Compositional Diffusion for Reliable Long-Horizon Planning
Pith reviewed 2026-05-08 17:43 UTC · model grok-4.3
The pith
Refining compositional diffusion uses reconstruction error and overlap consistency to steer sampling toward high-density coherent long-horizon plans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
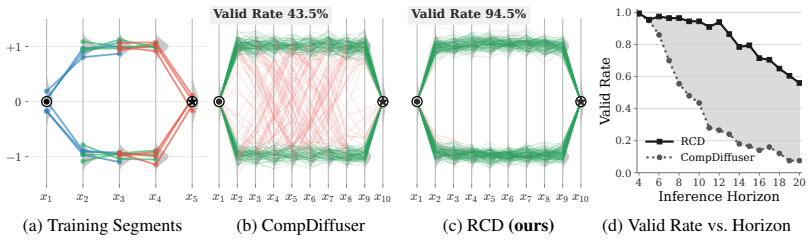
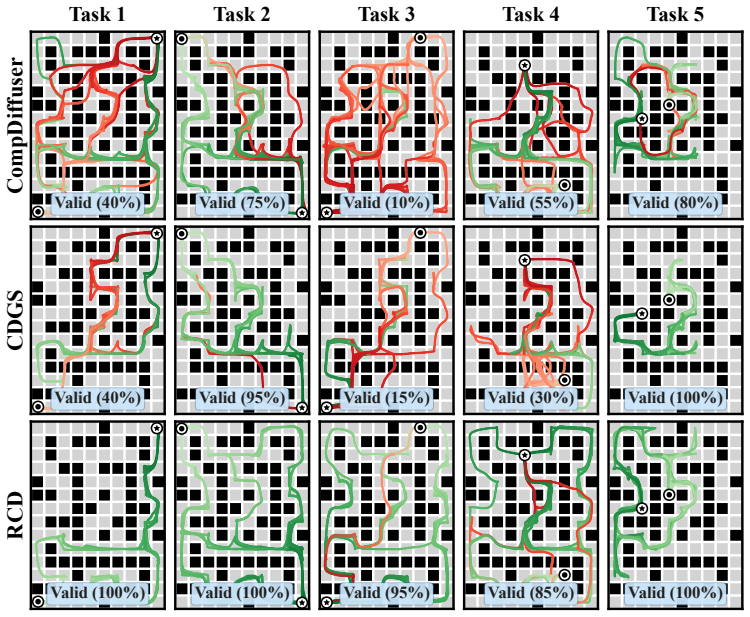
RCD is a guidance procedure that adds the self-reconstruction error of a pretrained diffusion model, interpreted as log-density of the stitched plan, to the composed score, together with an explicit overlap consistency penalty; the resulting guidance concentrates samples on high-density, boundary-consistent plans that avoid the mode-averaging failure mode of naive score composition.
What carries the argument
Self-reconstruction error treated as log-density proxy, combined with an overlap consistency term, used as additive guidance on the composed score.
If this is right
- Sampling concentrates on high-density regions of the composed plan distribution.
- Mode-averaging is reduced, yielding plans that remain locally feasible and globally coherent.
- No retraining or architectural change is required; the method applies to any pretrained diffusion planner.
- Performance improves on long-horizon locomotion, object manipulation, and pixel-based tasks.
Where Pith is reading between the lines
- The same reconstruction-error signal could serve as a cheap diagnostic for plan quality in other diffusion-based planners.
- Boundary consistency terms may be useful beyond diffusion when stitching any locally generated trajectory segments.
- If the proxy holds, it suggests that internal model signals already encode enough information to resolve global coherence without external rewards.
Load-bearing premise
The self-reconstruction error of the pretrained diffusion model remains a faithful proxy for the log-density of the stitched plan even when adjacent segments contain incompatible local modes.
What would settle it
A controlled test in which deliberately incompatible local modes are stitched; if the guided sampler still produces plans with feasibility rates no better than unguided compositional diffusion, the density-proxy assumption fails.
Figures






read the original abstract
Compositional diffusion planning generates long-horizon trajectories by stitching together overlapping short-horizon segments through score composition. However, when local plan distributions are multimodal, existing compositional methods suffer from mode-averaging, where averaging incompatible local modes leads to plans that are neither locally feasible nor globally coherent. We propose Refining Compositional Diffusion (RCD), a training-free guidance method that steers compositional sampling toward high-density, globally coherent plans. RCD leverages the self-reconstruction error of a pretrained diffusion model as a proxy for the log-density of composed plans, combined with an overlap consistency term that enforces consistency at segment boundaries. We show that the combined guidance concentrates sampling on high-density plans that mitigate mode-averaging. Experiments on challenging long-horizon tasks from OGBench, including locomotion, object manipulation, and pixel-based observations, demonstrate that RCD consistently outperforms existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that compositional diffusion planning for long-horizon trajectories suffers from mode-averaging when stitching multimodal short-horizon segments, and proposes Refining Compositional Diffusion (RCD) as a training-free guidance technique. RCD combines the self-reconstruction error of a pretrained diffusion model (used as a proxy for the log-density of the composed plan) with an overlap consistency term to steer sampling toward high-density, coherent plans. Experiments on OGBench tasks (locomotion, object manipulation, pixel observations) show consistent outperformance over prior compositional methods.
Significance. If the reconstruction-error proxy reliably approximates the composed log-density and the guidance mitigates mode-averaging without new artifacts, the work would be significant for enabling reliable long-horizon planning from pretrained short-horizon models in a training-free manner. Strengths include the training-free design, explicit use of a pretrained model, and evaluation across diverse OGBench domains including pixel-based observations.
major comments (3)
- [§3.2] §3.2 (method): The central claim that self-reconstruction error on the concatenated trajectory serves as a proxy for log-density of the composed (product) distribution lacks any derivation, bound, or inequality showing that argmin of this error coincides with argmax of log p_composed. When local modes conflict, the joint error can be dominated by local denoising residuals rather than the measure of the stitched distribution; the overlap term addresses boundaries but does not correct this global mis-estimation.
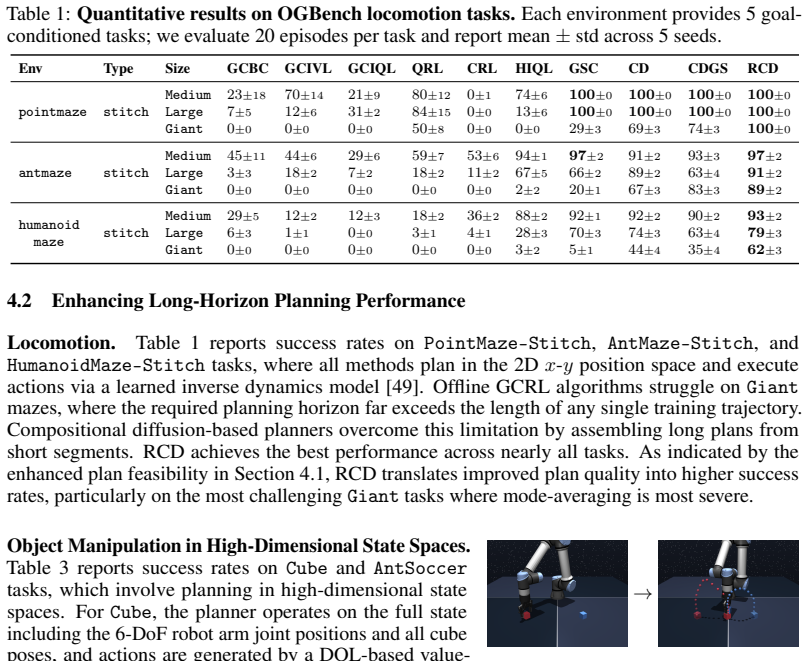
- [Experiments section, Tables 1-2] Experiments section, Tables 1-2: Reported outperformance on OGBench lacks quantitative details on effect sizes, standard deviations, number of random seeds, or ablation isolating the reconstruction-error guidance from the overlap-consistency term. Without these, it is impossible to verify whether the claimed mitigation of mode-averaging is robust or driven by one component.
- [§4.1] §4.1 (analysis): No theoretical or empirical examination is given of cases where incompatible local modes cause the reconstruction error to fail as a density proxy, nor of whether the combined guidance can still produce incoherent plans in highly multimodal settings.
minor comments (2)
- [Abstract] The abstract would benefit from brief quantitative effect sizes or success-rate deltas to ground the 'consistently outperforms' claim.
- [§3] Notation for the two guidance scales (e.g., weighting coefficients) could be introduced earlier and used consistently in the method equations.
Simulated Author's Rebuttal
Thank you for the constructive review and the recommendation for major revision. We appreciate the focus on strengthening the theoretical motivation, experimental reporting, and analysis of limitations. We address each major comment below and will incorporate revisions to improve the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (method): The central claim that self-reconstruction error on the concatenated trajectory serves as a proxy for log-density of the composed (product) distribution lacks any derivation, bound, or inequality showing that argmin of this error coincides with argmax of log p_composed. When local modes conflict, the joint error can be dominated by local denoising residuals rather than the measure of the stitched distribution; the overlap term addresses boundaries but does not correct this global mis-estimation.
Authors: We agree that §3.2 presents the reconstruction error as a proxy without a formal derivation or inequality establishing equivalence to the log-density of the composed distribution. The motivation is that, for a single diffusion model, reconstruction error correlates with negative log-likelihood under the learned distribution, and we extend this heuristically to the product of short-horizon models via concatenation. However, we acknowledge that local residuals can dominate when modes conflict and that the overlap term primarily enforces boundary consistency. In the revision we will explicitly label this as an approximation in §3.2, add a paragraph discussing the conditions under which the proxy may degrade, and note that empirical success on OGBench tasks supports its practical utility despite the lack of a tight bound. revision: partial
-
Referee: [Experiments section, Tables 1-2] Experiments section, Tables 1-2: Reported outperformance on OGBench lacks quantitative details on effect sizes, standard deviations, number of random seeds, or ablation isolating the reconstruction-error guidance from the overlap-consistency term. Without these, it is impossible to verify whether the claimed mitigation of mode-averaging is robust or driven by one component.
Authors: We accept that the current tables omit standard deviations, seed counts, effect sizes, and component ablations. The revised manuscript will update Tables 1 and 2 with means and standard deviations over 5 random seeds, include effect-size metrics (e.g., relative improvement percentages), and add a dedicated ablation table that runs RCD with reconstruction-error guidance disabled and with overlap consistency disabled. These additions will allow readers to assess the robustness of mode-averaging mitigation and the individual contributions of each term. revision: yes
-
Referee: [§4.1] §4.1 (analysis): No theoretical or empirical examination is given of cases where incompatible local modes cause the reconstruction error to fail as a density proxy, nor of whether the combined guidance can still produce incoherent plans in highly multimodal settings.
Authors: The existing §4.1 emphasizes successful long-horizon results but does not systematically explore failure regimes. We will expand this section with a new subsection that (i) provides theoretical intuition on when local denoising residuals may overwhelm the global density signal and (ii) presents empirical examples drawn from the OGBench locomotion and manipulation tasks, including both cases where the combined guidance yields coherent plans and cases where incompatible modes still produce artifacts. This will give a more balanced characterization of the method’s limitations. revision: yes
Circularity Check
No significant circularity; guidance terms are independently defined proxies.
full rationale
The paper introduces RCD as a training-free method that explicitly defines two guidance terms—the self-reconstruction error of a pretrained diffusion model used as a log-density proxy, plus an overlap consistency term—without reducing either to a fitted parameter, a self-citation chain, or a renamed input. The central claim that the combined guidance mitigates mode-averaging is supported by empirical results on OGBench tasks rather than by construction from the method's own definitions. No load-bearing step equates the claimed concentration on high-density plans to the inputs by definition or prior self-work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Self-reconstruction error of a pretrained diffusion model serves as a usable proxy for the log-density of a composed plan.
- domain assumption Adding an overlap consistency term during sampling will concentrate probability mass on globally coherent plans.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost (J(x) = ½(x+x⁻¹) − 1)washburn_uniqueness_aczel unclearE_recon(τ̂_0;s) = E_ε[ ‖τ̂_0 − τ̂_0^rec(τ̂_0,ε,s)‖^2 ]
-
Foundation (parameter-free forcing chain)reality_from_one_distinction unclearWe use a single fixed set of RCD hyperparameters (w=0.25, λ_ov=0.5, s/T=0.4) across every benchmark
Reference graph
Works this paper leans on
-
[1]
floq: Training critics via flow- matching for scaling compute in value-based rl
Agrawalla, B., Nauman, M., Agrawal, K., and Kumar, A. floq: Training critics via flow- matching for scaling compute in value-based rl. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[2]
Option-aware temporally abstracted value for offline goal-conditioned reinforcement learning
Ahn, H., Choi, H., Han, J., and Moon, T. Option-aware temporally abstracted value for offline goal-conditioned reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[3]
B., Jaakkola, T
Ajay, A., Du, Y ., Gupta, A., Tenenbaum, J. B., Jaakkola, T. S., and Agrawal, P. Is conditional generative modeling all you need for decision making? InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[4]
Graph-assisted stitching for offline hierarchical reinforcement learning
Baek, S., Park, T., Park, J., Oh, S., and Kim, Y . Graph-assisted stitching for offline hierarchical reinforcement learning. InInternational Conference on Machine Learning (ICML), 2025
2025
-
[5]
Cai, Y ., Wu, Y ., Li, K., Zhou, Y ., Zheng, B., and Liu, H. Flooddiffusion: Tailored diffusion forcing for streaming motion generation.arXiv preprint arXiv:2512.03520, 2025
-
[6]
Char, I., Mehta, V ., Villaflor, A., Dolan, J. M., and Schneider, J. Bats: Best action trajectory stitching.arXiv preprint arXiv:2204.12026, 2022
-
[7]
Diffusion forcing: Next-token prediction meets full-sequence diffusion
Chen, B., Martí Monsó, D., Du, Y ., Simchowitz, M., Tedrake, R., and Sitzmann, V . Diffusion forcing: Next-token prediction meets full-sequence diffusion. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[8]
Simple hierarchical planning with diffusion.arXiv preprint arXiv:2401.02644, 2024
Chen, C., Deng, F., Kawaguchi, K., Gulcehre, C., and Ahn, S. Simple hierarchical planning with diffusion.arXiv preprint arXiv:2401.02644, 2024
-
[9]
Extendable long-horizon planning via hierarchical multiscale diffusion.arXiv e-prints, pp
Chen, C., Hamed, H., Baek, D., Kang, T., Bengio, Y ., and Ahn, S. Extendable long-horizon planning via hierarchical multiscale diffusion.arXiv e-prints, pp. arXiv–2503, 2025
2025
-
[10]
Diffusion policy: Visuomotor policy learning via action diffusion
Chi, C., Feng, S., Du, Y ., Xu, Z., Cousineau, E., Burchfiel, B., and Song, S. Diffusion policy: Visuomotor policy learning via action diffusion. InProceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[11]
T., Klasky, M
Chung, H., Kim, J., Mccann, M. T., Klasky, M. L., and Ye, J. C. Diffusion posterior sampling for general noisy inverse problems. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[12]
Clark, Q. and Shkurti, F. What do you need for diverse trajectory composition in diffusion planning?arXiv preprint arXiv:2505.18083, 2025
-
[13]
and Nichol, A
Dhariwal, P. and Nichol, A. Diffusion models beat gans on image synthesis. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[14]
Dong, J., Huang, W., Zhang, J., Chen, Z., Yuan, X., Gu, Q., Jiang, Z., and Ye, N. Proximal action replacement for behavior cloning actor-critic in offline reinforcement learning.arXiv preprint arXiv:2602.07441, 2026
-
[15]
Diffuserlite: Towards real-time diffusion planning
Dong, Z., Hao, J., Yuan, Y ., Ni, F., Wang, Y ., Li, P., and Zheng, Y . Diffuserlite: Towards real-time diffusion planning. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[16]
Cleandiffuser: An easy-to-use modularized library for diffusion models in decision making
Dong, Z., Yuan, Y ., Hao, J., Ni, F., Ma, Y ., Li, P., and Zheng, Y . Cleandiffuser: An easy-to-use modularized library for diffusion models in decision making. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2024
2024
-
[17]
Compositional visual generation with energy based models
Du, Y ., Li, S., and Mordatch, I. Compositional visual generation with energy based models. In Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[18]
B., Dieleman, S., Fergus, R., Sohl-Dickstein, J., Doucet, A., and Grathwohl, W
Du, Y ., Durkan, C., Strudel, R., Tenenbaum, J. B., Dieleman, S., Fergus, R., Sohl-Dickstein, J., Doucet, A., and Grathwohl, W. S. Reduce, reuse, recycle: Compositional generation with energy-based diffusion models and mcmc. InInternational Conference on Machine Learning (ICML), 2023. 10
2023
-
[19]
Eysenbach, B., Zhang, T., Levine, S., and Salakhutdinov, R. R. Contrastive learning as goal- conditioned reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[20]
Temporal difference flows
Farebrother, J., Pirotta, M., Tirinzoni, A., Munos, R., Lazaric, A., and Touati, A. Temporal difference flows. InInternational Conference on Machine Learning (ICML), 2025
2025
-
[21]
Ada- diffuser: Latent-aware adaptive diffusion for decision-making
Feng, F., Ge, S., Fu, M., Li, Z., Zheng, Y ., Tang, Z., Hu, Y ., Huang, B., and Zhang, K. Ada- diffuser: Latent-aware adaptive diffusion for decision-making. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[22]
Resisting stochastic risks in diffusion planners with the trajectory aggregation tree
Feng, L., Gu, P., An, B., and Pan, G. Resisting stochastic risks in diffusion planners with the trajectory aggregation tree. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[23]
Frans, K., Park, S., Abbeel, P., and Levine, S. Diffusion guidance is a controllable policy improvement operator.arXiv preprint arXiv:2505.23458, 2025
-
[24]
Learning to reach goals via iterated supervised learning, 2020
Ghosh, D., Gupta, A., Reddy, A., Fu, J., Devin, C., Eysenbach, B., and Levine, S. Learning to reach goals via iterated supervised learning.arXiv preprint arXiv:1912.06088, 2019
-
[25]
Closing the gap between td learning and supervised learning–a generalisation point of view
Ghugare, R., Geist, M., Berseth, G., and Eysenbach, B. Closing the gap between td learning and supervised learning–a generalisation point of view. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[26]
Hierarchical entity- centric reinforcement learning with factored subgoal diffusion
Haramati, D., Qi, C., Daniel, T., Zhang, A., Tamar, A., and Konidaris, G. Hierarchical entity- centric reinforcement learning with factored subgoal diffusion. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[27]
Z., Salakhutdinov, R., et al
He, Y ., Murata, N., Lai, C.-H., Takida, Y ., Uesaka, T., Kim, D., Liao, W.-H., Mitsufuji, Y ., Kolter, J. Z., Salakhutdinov, R., et al. Manifold preserving guided diffusion. InInternational Conference on Learning Representations (ICLR), 2024
2024
- [28]
-
[29]
Denoising diffusion probabilistic models
Ho, J., Jain, A., and Abbeel, P. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[30]
Policy-guided diffusion.arXiv preprint arXiv:2404.06356, 2024
Jackson, M. T., Matthews, M. T., Lu, C., Ellis, B., Whiteson, S., and Foerster, J. Policy-guided diffusion.arXiv preprint arXiv:2404.06356, 2024
-
[31]
B., and Levine, S
Janner, M., Du, Y ., Tenenbaum, J. B., and Levine, S. Planning with diffusion for flexible behavior synthesis. InInternational Conference on Machine Learning (ICML), 2022
2022
-
[32]
Tree-guided diffusion planner
Jeon, H., Min, C., and Park, J. Tree-guided diffusion planner. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[33]
Prior-guided diffusion planning for offline reinforce- ment learning
Ki, D., Oh, J., Shim, S.-W., and Lee, B.-J. Prior-guided diffusion planning for offline reinforce- ment learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[34]
DEAS: DEtached value learning with action sequence for scalable offline RL
Kim, C., Lee, H., Seo, Y ., Lee, K., and Zhu, Y . DEAS: DEtached value learning with action sequence for scalable offline RL. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[35]
Offline reinforcement learning with implicit q-learning
Kostrikov, I., Nair, A., and Levine, S. Offline reinforcement learning with implicit q-learning. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[36]
Lee, J., Yun, S., Yun, T., and Park, J. Gta: Generative trajectory augmentation with guidance for offline reinforcement learning.arXiv preprint arXiv:2405.16907, 2024
-
[37]
and Choi, J
Lee, K. and Choi, J. Local manifold approximation and projection for manifold-aware diffusion planning. InInternational Conference on Machine Learning (ICML), 2025
2025
-
[38]
and Choi, J
Lee, K. and Choi, J. State-covering trajectory stitching for diffusion planners. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. 11
2025
-
[39]
Deep reinforcement learning in continuous action spaces: a case study in the game of simulated curling
Lee, K., Kim, S.-A., Choi, J., and Lee, S.-W. Deep reinforcement learning in continuous action spaces: a case study in the game of simulated curling. InInternational Conference on Machine Learning (ICML), 2018
2018
-
[40]
Refining diffusion planner for reliable behavior synthesis by automatic detection of infeasible plans
Lee, K., Kim, S., and Choi, J. Refining diffusion planner for reliable behavior synthesis by automatic detection of infeasible plans. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[41]
Diffstitch: Boosting offline reinforcement learning with diffusion-based trajectory stitching
Li, G., Shan, Y ., Zhu, Z., Long, T., and Zhang, W. Diffstitch: Boosting offline reinforcement learning with diffusion-based trajectory stitching. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[42]
Decoupled q-chunking
Li, Q., Park, S., and Levine, S. Decoupled q-chunking. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[43]
Hierarchical diffusion for offline decision making
Li, W., Wang, X., Jin, B., and Zha, H. Hierarchical diffusion for offline decision making. In International Conference on Machine Learning (ICML), 2023
2023
-
[44]
K., Koenig, S., and Fioretto, F
Liang, J., Christopher, J. K., Koenig, S., and Fioretto, F. Simultaneous multi-robot motion planning with projected diffusion models. InInternational Conference on Machine Learning (ICML), 2025
2025
-
[45]
Adaptdiffuser: Diffusion models as adaptive self-evolving planners
Liang, Z., Mu, Y ., Ding, M., Ni, F., Tomizuka, M., and Luo, P. Adaptdiffuser: Diffusion models as adaptive self-evolving planners. InInternational Conference on Machine Learning (ICML), 2023
2023
-
[46]
What makes a good diffusion planner for decision making? InInternational Conference on Learning Representations (ICLR), 2025
Lu, H., Han, D., Shen, Y ., and Li, D. What makes a good diffusion planner for decision making? InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[47]
Lu, Y ., Han, D., Wang, Y ., and Li, D. Improving diffusion planners by self-supervised action gating with energies.arXiv preprint arXiv:2603.02650, 2026
-
[48]
B., and Du, Y
Luo, Y ., Sun, C., Tenenbaum, J. B., and Du, Y . Potential based diffusion motion planning. In International Conference on Machine Learning (ICML), 2024
2024
-
[49]
A., Du, Y ., and Xu, D
Luo, Y ., Mishra, U. A., Du, Y ., and Xu, D. Generative trajectory stitching through diffusion composition. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[50]
Learning latent plans from play
Lynch, C., Khansari, M., Xiao, T., Kumar, V ., Tompson, J., Levine, S., and Sermanet, P. Learning latent plans from play. InConference on robot learning, 2020
2020
-
[51]
A., Xue, S., Chen, Y ., and Xu, D
Mishra, U. A., Xue, S., Chen, Y ., and Xu, D. Generative skill chaining: Long-horizon skill planning with diffusion models. InConference on Robot Learning, pp. 2905–2925. PMLR, 2023
2023
-
[52]
A., He, D., Chen, Y ., and Xu, D
Mishra, U. A., He, D., Chen, Y ., and Xu, D. Compositional diffusion with guided search for long-horizon planning. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[53]
Hdflow: Hierarchical diffusion-flow planning for long-horizon robotic assembly
Nandiraju, G., Ju, Y ., Xu, C., and Wang, H. Hdflow: Hierarchical diffusion-flow planning for long-horizon robotic assembly. InNeurIPS 2025 Workshop on Embodied World Models for Decision Making, 2025
2025
-
[54]
Opryshko, E., Quan, J., V oelcker, C., Du, Y ., and Gilitschenski, I. Test-time graph search for goal-conditioned reinforcement learning.arXiv preprint arXiv:2510.07257, 2025
-
[55]
Scalable offline model-based RL with action chunks
Park, K., Park, S., Lee, Y ., and Levine, S. Scalable offline model-based RL with action chunks. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[56]
Offline goal-conditioned rl with latent states as actions
Park, S., Ghosh, D., Eysenbach, B., and Levine, S. Offline goal-conditioned rl with latent states as actions. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[57]
Foundation policies with hilbert representations
Park, S., Kreiman, T., and Levine, S. Foundation policies with hilbert representations. In International Conference on Machine Learning (ICML), 2024. 12
2024
-
[58]
Ogbench: Benchmarking offline goal- conditioned rl
Park, S., Frans, K., Eysenbach, B., and Levine, S. Ogbench: Benchmarking offline goal- conditioned rl. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[59]
Horizon reduction makes rl scalable
Park, S., Frans, K., Mann, D., Eysenbach, B., Kumar, A., and Levine, S. Horizon reduction makes rl scalable. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[60]
Flow q-learning
Park, S., Li, Q., and Levine, S. Flow q-learning. InInternational Conference on Machine Learning (ICML), 2025
2025
-
[61]
Dual goal representations
Park, S., Mann, D., and Levine, S. Dual goal representations. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[62]
Transitive rl: Value learning via divide and conquer
Park, S., Oberai, A., Atreya, P., and Levine, S. Transitive rl: Value learning via divide and conquer. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[63]
M., and Han, J
Ren, Y ., Gao, W., Ying, L., Rotskoff, G. M., and Han, J. Driftlite: Lightweight drift control for inference-time scaling of diffusion models. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[64]
Robbins, H. E. An empirical bayes approach to statistics. InBreakthroughs in Statistics: Foundations and basic theory, pp. 388–394. Springer, 1992
1992
-
[65]
Multi-robot motion planning with diffusion models
Shaoul, Y ., Mishani, I., Vats, S., Li, J., and Likhachev, M. Multi-robot motion planning with diffusion models. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[66]
Understanding and improving training-free loss-based diffusion guidance
Shen, Y ., Jiang, X., Yang, Y ., Wang, Y ., Han, D., and Li, D. Understanding and improving training-free loss-based diffusion guidance. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[67]
J., Guez, A., Sifre, L., Van Den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V ., Lanctot, M., et al
Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., Van Den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V ., Lanctot, M., et al. Mastering the game of go with deep neural networks and tree search.nature, 529(7587):484–489, 2016
2016
-
[68]
Mastering the game of go without human knowledge
Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., Hubert, T., Baker, L., Lai, M., Bolton, A., et al. Mastering the game of go without human knowledge. nature, 550(7676):354–359, 2017
2017
-
[69]
Denoising diffusion implicit models
Song, J., Meng, C., and Ermon, S. Denoising diffusion implicit models. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[70]
Loss- guided diffusion models for plug-and-play controllable generation
Song, J., Zhang, Q., Yin, H., Mardani, M., Liu, M.-Y ., Kautz, J., Chen, Y ., and Vahdat, A. Loss- guided diffusion models for plug-and-play controllable generation. InInternational Conference on Machine Learning (ICML), 2023
2023
-
[71]
P., Kumar, A., Ermon, S., and Poole, B
Song, Y ., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., and Poole, B. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[72]
Synthesis and stabilization of complex behaviors through online trajectory optimization
Tassa, Y ., Erez, T., and Todorov, E. Synthesis and stabilization of complex behaviors through online trajectory optimization. In2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 4906–4913, 2012
2012
-
[73]
Optimal goal-reaching reinforcement learning via quasimetric learning
Wang, T., Torralba, A., Isola, P., and Zhang, A. Optimal goal-reaching reinforcement learning via quasimetric learning. InInternational Conference on Machine Learning (ICML), 2023
2023
-
[74]
Inference-time policy steering through human interactions
Wang, Y ., Wang, L., Du, Y ., Sundaralingam, B., Yang, X., Chao, Y .-W., Pérez-D’Arpino, C., Fox, D., and Shah, J. Inference-time policy steering through human interactions. InIEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[75]
Wang, Z., Hunt, J. J., and Zhou, M. Diffusion policies as an expressive policy class for offline reinforcement learning.arXiv preprint arXiv:2208.06193, 2022
-
[76]
Latent diffusion planning for imitation learning
Xie, A., Rybkin, O., Sadigh, D., and Finn, C. Latent diffusion planning for imitation learning. InInternational Conference on Machine Learning (ICML), 2025. 13
2025
-
[77]
Guidance with spherical gaussian constraint for conditional diffusion
Yang, L., Ding, S., Cai, Y ., Yu, J., Wang, J., and Shi, Y . Guidance with spherical gaussian constraint for conditional diffusion. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[78]
S., Freeman, W
Yedidia, J. S., Freeman, W. T., and Weiss, Y . Constructing free-energy approximations and generalized belief propagation algorithms.IEEE Transactions on information theory, 51(7): 2282–2312, 2005
2005
-
[79]
Monte carlo tree diffusion for system 2 planning
Yoon, J., Cho, H., Baek, D., Bengio, Y ., and Ahn, S. Monte carlo tree diffusion for system 2 planning. InInternational Conference on Machine Learning (ICML), 2025
2025
-
[80]
Yoon, J., Cho, H., Bengio, Y ., and Ahn, S. Fast monte carlo tree diffusion: 100x speedup via parallel sparse planning.arXiv preprint arXiv:2506.09498, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.