Recognition: unknown
Phoneme-Level Deepfake Detection Across Emotional Conditions Using Self-Supervised Embeddings
Pith reviewed 2026-05-08 02:42 UTC · model grok-4.3
The pith
Phoneme-level analysis detects emotionally manipulated speech by measuring divergence in specific sounds like complex vowels and fricatives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Phoneme behavior varies across categories, with complex vowels and fricatives exhibiting higher divergence while simpler phonemes remain more stable. Phonemes with larger distributional differences are also found to be more easily detected, consistently across multiple emotions and synthesis systems. These findings demonstrate that phoneme-level analysis is an effective and interpretable approach for detecting emotionally manipulated synthetic speech.
What carries the argument
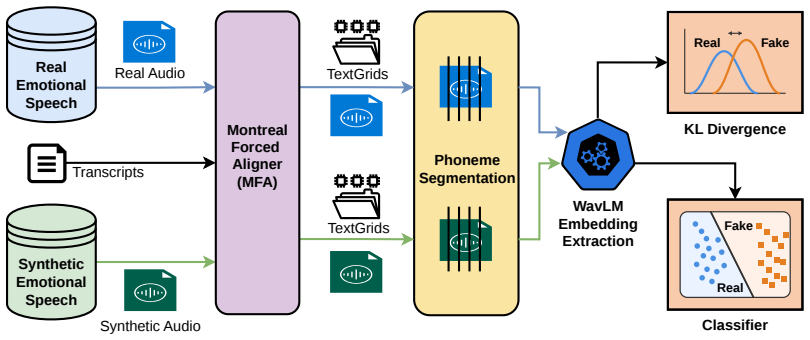
Phoneme-level framework that aligns real and EVC-generated speech via TextGrids under matched emotional conditions, then compares WavLM self-supervised embeddings to quantify per-phoneme distributional differences.
If this is right
- Complex vowels and fricatives serve as stronger indicators than simpler phonemes for spotting emotional manipulation.
- Detection performance remains consistent when the same framework is applied across different emotions and synthesis systems.
- Phoneme-specific divergence scores provide an interpretable alternative to treating entire utterances as homogeneous signals.
- Focusing analysis on high-divergence phonemes can improve both accuracy and explainability in deepfake detection pipelines.
Where Pith is reading between the lines
- The same phoneme divergence patterns could be used to build lightweight detectors that only process vulnerable sound classes instead of full audio streams.
- Testing the approach on cross-lingual data might reveal whether certain phoneme categories are universally easier to manipulate or detect.
- Combining phoneme-level scores with existing utterance-level detectors could produce hybrid systems that flag manipulation at both fine and coarse scales.
Load-bearing premise
That phoneme alignments stay accurate for both real and synthetic emotional speech and that the embeddings capture manipulation traces without being overwhelmed by emotion or speaker identity.
What would settle it
If per-phoneme detection performance shows no correlation with measured distributional divergence, or if alignment error rates rise sharply on EVC outputs, the claim that phoneme-level differences drive effective detection would not hold.
Figures

read the original abstract
Recent advances in emotional voice conversion (EVC) have enabled the generation of expressive synthetic speech, raising new concerns in audio deepfake detection. Existing approaches treat speech as a homogeneous signal and largely overlook its internal phonetic structure, limiting their interpretability in emotionally conditioned settings. In this work, we propose a phoneme-level framework to analyze emotionally manipulated synthetic speech using real and EVC-generated speech under matched emotional conditions with shared transcripts, phoneme-aligned TextGrids, and WavLM-based embeddings. Our results show that phoneme behavior varies across categories, with complex vowels and fricatives exhibiting higher divergence while simpler phonemes remain more stable. Phonemes with larger distributional differences are also found to be more easily detected, consistently across multiple emotions and synthesis systems. These findings demonstrate that phoneme-level analysis is an effective and interpretable approach for detecting emotionally manipulated synthetic speech.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a phoneme-level framework for detecting emotionally manipulated synthetic speech generated via emotional voice conversion (EVC). Using shared transcripts, phoneme-aligned TextGrids, and WavLM self-supervised embeddings on real and EVC speech under matched emotional conditions, it reports that phoneme behavior varies by category, with complex vowels and fricatives showing higher distributional divergence while simpler phonemes are more stable. Phonemes exhibiting larger distributional differences are claimed to be more easily detected, with this pattern holding consistently across multiple emotions and synthesis systems. The work concludes that phoneme-level analysis offers an effective and interpretable approach to deepfake detection in emotionally conditioned settings.
Significance. If the central findings hold after validation of alignment quality, the work would provide a useful step toward interpretable, phonetically grounded deepfake detectors that move beyond treating speech as a homogeneous signal. The matched emotional conditions and use of self-supervised embeddings are strengths that could help isolate manipulation artifacts from emotion or speaker effects. However, the absence of reported quantitative metrics, statistical tests, or dataset details in the abstract makes it difficult to gauge the magnitude or robustness of the claimed improvements over existing methods.
major comments (2)
- [Abstract] Abstract: the central claim that 'phonemes with larger distributional differences are also found to be more easily detected, consistently across multiple emotions and synthesis systems' is presented without any quantitative metrics, statistical tests, dataset sizes, or controls for confounds. This leaves the interpretability argument unsupported at the level of the stated contribution.
- [Methods] Methods (phoneme alignment description): the manuscript relies on TextGrids generated via forced alignment for both real and EVC speech but provides no ablation, manual validation, or error analysis of alignment accuracy on the EVC set. Because EVC alters prosody, duration, and spectral detail, boundary errors are expected to be larger for complex vowels and fricatives—the very phonemes reported as most divergent—raising the possibility that observed distributional differences reflect misalignment artifacts rather than genuine phoneme-specific detectability of manipulation.
minor comments (1)
- [Abstract] The abstract would benefit from explicit mention of the number of emotions, synthesis systems, and phoneme instances analyzed to allow readers to assess the scope of the consistency claim.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment below and have updated the paper to incorporate the suggested improvements where they strengthen the work.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'phonemes with larger distributional differences are also found to be more easily detected, consistently across multiple emotions and synthesis systems' is presented without any quantitative metrics, statistical tests, dataset sizes, or controls for confounds. This leaves the interpretability argument unsupported at the level of the stated contribution.
Authors: We agree that the abstract, in its current form, states the central claim at a high level without quantitative anchors. The body of the manuscript reports the supporting metrics, statistical comparisons, and dataset details (including matched emotional conditions from the ESD corpus and multiple synthesis systems). To ensure the abstract itself better substantiates the contribution, we have revised it to include concise references to the scale of the evaluation, the consistent cross-emotion and cross-system pattern, and the nature of the phoneme-category differences. This revision directly addresses the concern while respecting abstract length constraints. revision: yes
-
Referee: [Methods] Methods (phoneme alignment description): the manuscript relies on TextGrids generated via forced alignment for both real and EVC speech but provides no ablation, manual validation, or error analysis of alignment accuracy on the EVC set. Because EVC alters prosody, duration, and spectral detail, boundary errors are expected to be larger for complex vowels and fricatives—the very phonemes reported as most divergent—raising the possibility that observed distributional differences reflect misalignment artifacts rather than genuine phoneme-specific detectability of manipulation.
Authors: This is a valid methodological concern. The manuscript describes the uniform application of forced alignment to produce TextGrids for both real and EVC speech but does not report validation, error rates, or robustness checks. We will add a dedicated subsection that includes manual boundary verification on a representative sample of utterances across emotions and an ablation that perturbs alignment boundaries to test whether the reported distributional divergences and detection patterns remain stable. These additions will allow readers to assess whether the phoneme-specific findings could be driven by alignment artifacts. revision: yes
Circularity Check
No significant circularity; empirical comparisons are independent of inputs
full rationale
The paper describes an empirical framework that extracts WavLM embeddings from phoneme-aligned segments of real and EVC speech using shared transcripts and TextGrids, then reports distributional differences and detection performance across phoneme categories. No equations, fitted parameters, or self-citations are invoked to derive the central claims; the reported divergences and detectability patterns are presented as direct observations from the data rather than reductions of any prediction back to the alignment or embedding steps themselves. The analysis therefore remains self-contained against external benchmarks and does not exhibit self-definitional, fitted-input, or self-citation load-bearing circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption WavLM embeddings encode phoneme-specific differences between real and emotionally converted speech
- domain assumption TextGrid phoneme alignments are reliable for both real and synthetic emotional speech
Reference graph
Works this paper leans on
-
[1]
Y . Ren, Y . Ruan, X. Tan, T. Qin, S. Zhao, Z. Zhao, and T.-Y . Liu, ”Fastspeech: Fast, robust and controllable text to speech,”Advances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[2]
Prenger, R
R. Prenger, R. Valle, and B. Catanzaro, ”WaveGlow: A Flow-Based Generative Network for Speech Synthesis,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2019, pp. 3617–3621
2019
-
[3]
Kameoka, T
H. Kameoka, T. Kaneko, K. Tanaka, and N. Hojo, ”StarGAN-VC: Non-Parallel Many-to-Many V oice Conversion Using Star Generative Adversarial Networks,” inProc. IEEE Spoken Lang. Technol. Work- shop (SLT), 2018, pp. 266–273
2018
-
[4]
K. Qian, Y . Zhang, S. Chang, X. Yang, and M. Hasegawa-Johnson, ”AutoVC: Zero-Shot V oice Style Transfer with Only Autoencoder Loss,” inProc. Int. Conf. Mach. Learn. (ICML), 2019, pp. 5210–5219
2019
- [5]
-
[6]
H. Delgado et al., ”ASVspoof 2021: Automatic Speaker Verifi- cation Spoofing and Countermeasures Challenge Evaluation Plan,” arXiv:2109.00535, 2021
-
[7]
Baevski, Y
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, ”wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations,” Advances in Neural Information Processing Systems, vol. 33, pp. 12449–12460, 2020
2020
-
[8]
Chen et al., ”WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing,”IEEE J
S. Chen et al., ”WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing,”IEEE J. Sel. Topics Signal Process., vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[9]
Schr ¨oder, R
M. Schr ¨oder, R. Cowie, E. Douglas-Cowie, M. Westerdijk, and S. C. A. M. Gielen, ”Acoustic Correlates of Emotion Dimensions in View of Speech Synthesis,” inProc. Interspeech, 2001, pp. 87–90
2001
-
[10]
Barhate, S
S. Barhate, S. Kshirsagar, N. Sanghvi, K. Sabu, P. Rao, and N. Bondale, ”Prosodic Features of Marathi News Reading Style,” inProc. IEEE Region 10 Conf. (TENCON), 2016, pp. 2215–2218
2016
-
[11]
P. Rao, H. Mixdorff, I. Deshpande, N. Sanghvi, and S. Kshirsagar, ”A Quantitative Study of Focus Shift in Marathi,” inProc. Speech Prosody, 2014
2014
-
[12]
Gender Fairness in Audio Deepfake Detection: Performance and Disparity Analysis
A. Fursule, S. Kshirsagar, and A. R. Avila, ”Gender Fairness in Audio Deepfake Detection: Performance and Disparity Analysis,” arXiv:2603.09007, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
S. Kshirsagar et al., ”Investigating the Impact of Speech En- hancement on Audio Deepfake Detection in Noisy Environments,” arXiv:2603.14767, 2026
-
[14]
D. E. Temmar, A. Hamadene, V . Nallaguntla, A. Fursule, M. S. Allili, S. Kshirsagar, and A. R. Avila, ”Phonetic Analysis of Real and Synthetic Speech Using HuBERT Embeddings: Perspectives for Deepfake Detection,” inProc. IEEE Int. Conf. Syst., Man, Cybern. (SMC), 2025, pp. 86–91
2025
-
[15]
T. Yang, C. Sun, S. Lyu, and P. Rose, ”Forensic Deepfake Audio Detection Using Segmental Speech Features,”Forensic Sci. Int., p. 112768, 2025
2025
-
[16]
PhonemeDF: A Synthetic Speech Dataset for Audio Deepfake De- tection and Naturalness Evaluation,
V . Nallaguntla, A. Fursule, S. Kshirsagar, and A. R. Avila, ”PhonemeDF: A Synthetic Speech Dataset for Audio Deepfake De- tection and Naturalness Evaluation,” arXiv:2603.15037, 2026
-
[17]
Cortes and V
C. Cortes and V . Vapnik, ”Support-Vector Networks,”Mach. Learn., vol. 20, no. 3, pp. 273–297, 1995
1995
-
[18]
Y . Zhao, J. Yi, J. Tao, C. Wang, and Y . Dong, ”EmoFake: An Initial Dataset for Emotion Fake Audio Detection,” inProc. Chin. Nat. Conf. Comput. Linguistics, 2024, pp. 1286–1297
2024
-
[19]
K. Zhou, B. Sisman, and H. Li, ”Emotional V oice Conversion: Theory, Databases and ESD,”Speech Commun., vol. 137, pp. 1–18, 2022
2022
- [20]
-
[21]
K. Zhou, B. Sisman, R. Liu, and H. Li, ”Seen and Unseen Emotional Style Transfer for V oice Conversion With a New Emotional Speech Dataset,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2021, pp. 920–924
2021
-
[22]
McAuliffe, M
M. McAuliffe, M. Socolof, S. Mihuc, M. Wagner, and M. Sonderegger, ”Montreal Forced Aligner: Trainable Text-Speech Alignment Using Kaldi,” inProc. Interspeech, 2017, pp. 498–502
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.