Recognition: unknown
Estimating peer effects in noisy, low-rank networks via network smoothing
Pith reviewed 2026-05-08 17:24 UTC · model grok-4.3
The pith
Peer effects on noisy networks are asymptotically equivalent to those on the expected adjacency matrix when it is low-rank.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
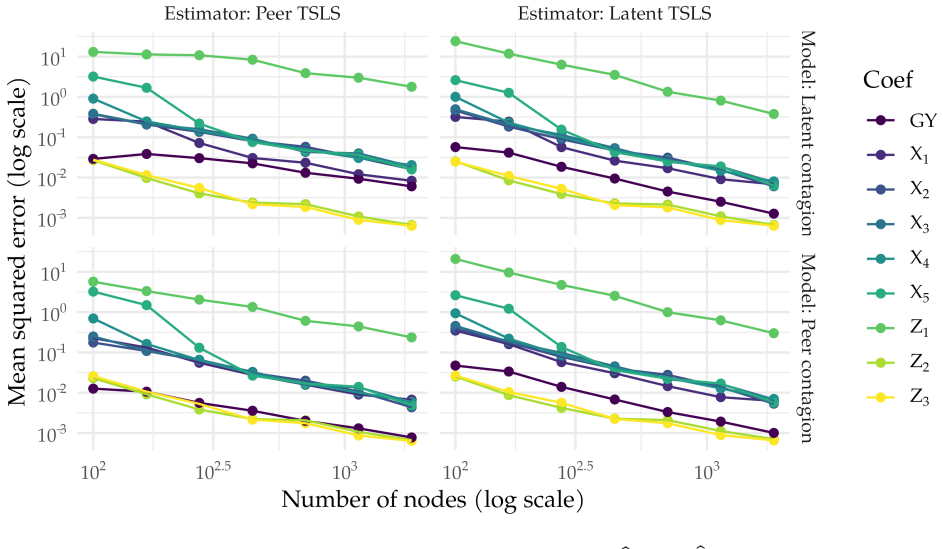
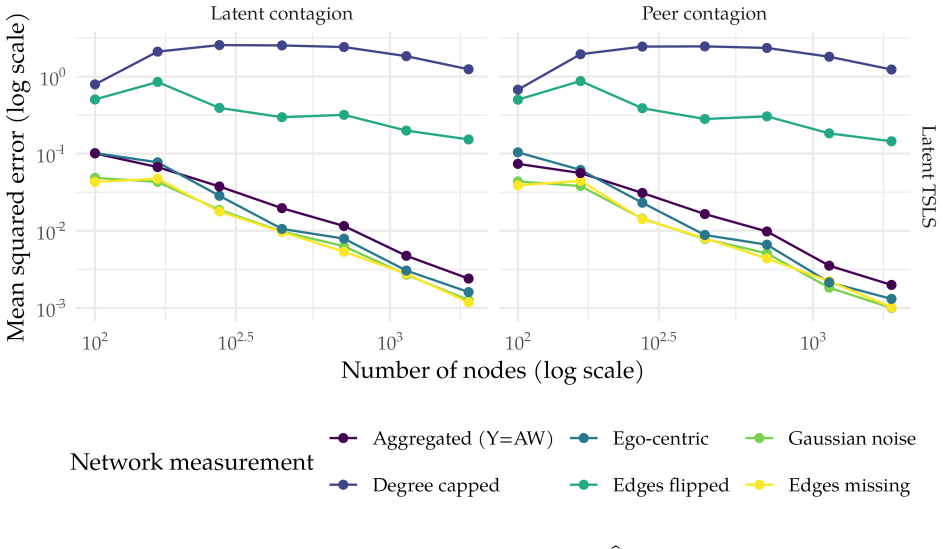
Our key result shows that peer effects over a true unobserved network are asymptotically equivalent to peer effects over the expected adjacency matrix. This result reduces peer effect estimation in noisy networks to low-rank matrix estimation targeting the expected adjacency matrix. We develop our theory for weighted networks observed with additive noise, but simulations suggest the approach can be applied more generally when there is a low-rank estimation method suited to a particular noise structure. We demonstrate via simulations that our approach applies to egocentric samples, aggregated relational data, and networks with missing edges, each requiring a different low-rank estimation.
What carries the argument
Low-rank estimator of the expected adjacency matrix, which acts as the smoothed network on which peer effects are computed.
If this is right
- Standard peer effect estimators become consistent when applied to the low-rank estimate of the expected adjacency matrix rather than the raw noisy network.
- The theory covers weighted networks with additive noise and extends in practice to other noise types via appropriate low-rank methods.
- The same peer effect model can be fit without modification once the network has been replaced by its low-rank estimate.
- Different data collection designs (egocentric, aggregated, missing edges) each admit their own low-rank estimator while preserving the asymptotic equivalence.
Where Pith is reading between the lines
- Social scientists could collect cheaper, noisier network data and still recover peer effects if the expected structure is low-rank.
- The result points toward designing network surveys around low-rank recovery rather than minimizing measurement error directly.
- Similar smoothing may apply to dynamic or multiplex networks if their expected slices remain low-rank.
Load-bearing premise
The expected adjacency matrix is low-rank and the observed noise permits a consistent low-rank estimator of it.
What would settle it
A simulation or dataset where the expected adjacency matrix is low-rank yet peer effect estimates from the low-rank estimate diverge from those on the true network at large sample sizes.
Figures




read the original abstract
Peer effect estimation requires precise network measurement, yet most empirical networks are noisy, rendering standard estimators inconsistent. To address measurement error in networks, we propose a method to estimate peer effects in networks whose expected adjacency matrix is low-rank. Our key result shows that peer effects over a true unobserved network are asymptotically equivalent to peer effects over the expected adjacency matrix. This result reduces peer effect estimation in noisy networks to low-rank matrix estimation targeting the expected adjacency matrix. We develop our theory for weighted networks observed with additive noise, but simulations suggest approach can be applied more generally when there is a low-rank estimation method suited to a particular noise structure. We demonstrate via simulations that our approach applies to egocentric samples, aggregated relational data, and networks with missing edges, each requiring a different low-rank estimation method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that peer effects computed on a true unobserved network are asymptotically equivalent to those computed on the expected adjacency matrix when the latter is low-rank. This equivalence reduces peer-effect estimation in noisy networks to a low-rank matrix recovery problem targeting the expectation. Theory is developed for weighted networks observed under additive noise; simulations are used to suggest that any suitable low-rank estimator can be substituted for other noise structures (egocentric sampling, aggregated relational data, missing edges).
Significance. If the asymptotic equivalence holds with explicit conditions and rates, the result supplies a clean reduction of a measurement-error problem to low-rank estimation, a structure that appears frequently in social and economic networks. The explicit theory for the additive-noise case and the demonstration that different low-rank estimators can be plugged in for different sampling schemes are concrete strengths that could make the method usable in applied work.
major comments (2)
- [Abstract; simulation section (likely §5)] The central asymptotic equivalence (abstract and the key result referenced in the introduction) is derived only for weighted networks under additive noise. For the three additional settings highlighted in the abstract and simulation section (egocentric samples, aggregated relational data, missing edges), the manuscript supplies only simulation evidence that a matched low-rank estimator can be used; no corresponding derivation is given showing that the equivalence itself continues to hold or that the resulting peer-effect estimator remains consistent.
- [Theory development section (likely §3–4)] The statement that the approach 'reduces peer effect estimation in noisy networks to low-rank matrix estimation' (abstract) is load-bearing for the paper's contribution, yet the manuscript does not state explicit conditions on the low-rank estimator (e.g., convergence rate, bias, or operator-norm error) that are required for the asymptotic equivalence to carry over from the additive-noise case.
minor comments (2)
- Notation distinguishing the realized adjacency matrix A from its expectation E[A] should be introduced once and used consistently; current usage occasionally blurs the two in the simulation descriptions.
- [Simulation section] The simulation tables would benefit from reporting the exact low-rank estimator employed for each noise structure (e.g., nuclear-norm, SVD truncation, or matrix completion method) alongside the peer-effect estimates.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope of our theoretical contributions. We address each major point below and will revise the manuscript to improve precision and transparency.
read point-by-point responses
-
Referee: [Abstract; simulation section (likely §5)] The central asymptotic equivalence (abstract and the key result referenced in the introduction) is derived only for weighted networks under additive noise. For the three additional settings highlighted in the abstract and simulation section (egocentric samples, aggregated relational data, missing edges), the manuscript supplies only simulation evidence that a matched low-rank estimator can be used; no corresponding derivation is given showing that the equivalence itself continues to hold or that the resulting peer-effect estimator remains consistent.
Authors: The referee is correct that the formal asymptotic equivalence between peer effects on the unobserved network and on its expectation is derived exclusively for the weighted additive-noise model. For egocentric sampling, aggregated relational data, and missing edges, the manuscript offers only simulation evidence that an appropriate low-rank estimator can be substituted, without claiming or proving that the same equivalence holds or that consistency is preserved. We will revise the abstract, introduction, and simulation section to explicitly distinguish the proven result from the simulation-based illustrations of broader applicability, and we will add a limitations paragraph noting that full theoretical extensions would require case-specific noise models and proofs. revision: partial
-
Referee: [Theory development section (likely §3–4)] The statement that the approach 'reduces peer effect estimation in noisy networks to low-rank matrix estimation' (abstract) is load-bearing for the paper's contribution, yet the manuscript does not state explicit conditions on the low-rank estimator (e.g., convergence rate, bias, or operator-norm error) that are required for the asymptotic equivalence to carry over from the additive-noise case.
Authors: We agree that the reduction claim requires explicit conditions on the low-rank estimator. The current proof implicitly relies on the estimator converging to the true expectation in operator norm at a rate sufficient to preserve the asymptotic equivalence of the peer-effect estimators. We will add a dedicated subsection in the theory development (likely §3 or §4) that states the precise requirements, including the necessary operator-norm convergence rate (e.g., ||Â − A||_op = o_p(1) or faster, depending on the moment conditions), bounded bias, and any additional assumptions needed for the equivalence to hold. This will make the load-bearing statement fully rigorous. revision: yes
Circularity Check
No significant circularity; central asymptotic equivalence derived from model assumptions
full rationale
The paper's key result establishes an asymptotic equivalence between peer effects computed on the unobserved true network and those on the expected adjacency matrix, under the stated low-rank assumption and additive noise model for weighted networks. This equivalence is obtained via direct analysis of the probabilistic model rather than by fitting parameters to data or by self-referential definition. The reduction of estimation to low-rank matrix recovery follows as a consequence of the proven equivalence, not as a tautology. For egocentric sampling, aggregated relational data, and missing edges, the paper explicitly limits the formal theory to additive noise and uses simulations only to suggest applicability, without claiming or deriving a general equivalence for those cases. No load-bearing step reduces by construction to its own inputs, and no self-citation chain is invoked to justify the uniqueness or validity of the core theorem.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The expected adjacency matrix is low-rank
Reference graph
Works this paper leans on
-
[1]
How to Generate Personal Net- works: Issues and T ools for a Sociological Perspective
DOI: 10.1111/j.2517-6161.1974.tb00999.x. Bhatia, Rajendra (1997). Matrix Analysis. Springer. Bidart, Claire and Johanne Charbonneau (Aug. 2011). “How to Generate Personal Net- works: Issues and T ools for a Sociological Perspective”. In: Field Methods 23.3, pp. 266–
-
[2]
A Review of Software for Spatial Econometrics in R
DOI: 10.1177/1525822X11408513. Bivand, Roger, Giovanni Millo, and Gianfranco Piras (June 2021). “ A Review of Software for Spatial Econometrics in R”. In:Mathematics 9.11, p. 1276. DOI:10.3390/math9111276. Boucher, Vincent and Aristide Houndetoungan (Oct. 2025). “Estimating Peer Effects Us- ing Partial Network Data”. In: Review of Economics and Statistics...
-
[3]
Regression Adjustments for Estimating the Global Treatment Effect in Experiments with Interference
DOI: 10.1016/j.jeconom.2022.10.005. Chin, Alex (Sept. 2019). “Regression Adjustments for Estimating the Global Treatment Effect in Experiments with Interference”. In: Journal of Causal Inference 7.2, p. 20180026. DOI: 10.1515/jci-2018-0026. Cho, Juhee, Donggyu Kim, and Karl Rohe (Apr. 2019). “Intelligent Initialization and Adap- tive Thresholding for Iter...
-
[4]
DOI: 10.1017/S0266466602182028. — (Jan. 2003). “Best Spatial T wo-Stage Least Squares Estimators for a Spatial Autoregres- sive Model with Autoregressive Disturbances”. In: Econometric Reviews 22.4, pp. 307–
-
[5]
Asymptotic Distributions of Quasi-Maximum Likelihood Estimators for Spatial Autoregressive Models
DOI: 10.1081/ETC-120025891. — (Nov . 2004). “ Asymptotic Distributions of Quasi-Maximum Likelihood Estimators for Spatial Autoregressive Models”. In: Econometrica 72.6, pp. 1899–1925. DOI: 10.1111/j. 1468-0262.2004.00558.x. Lee, Lung-Fei, Xiaodong Liu, and Xu Lin (July 2010). “Specification and Estimation of So- cial Interaction Models with Network Struct...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.