Recognition: unknown
S²tory: Story Spine Distillation for Movie Script Summarization
Pith reviewed 2026-05-07 16:55 UTC · model grok-4.3
The pith
Movie script summarization improves by distilling narratological theory to identify plot nuclei from character development trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
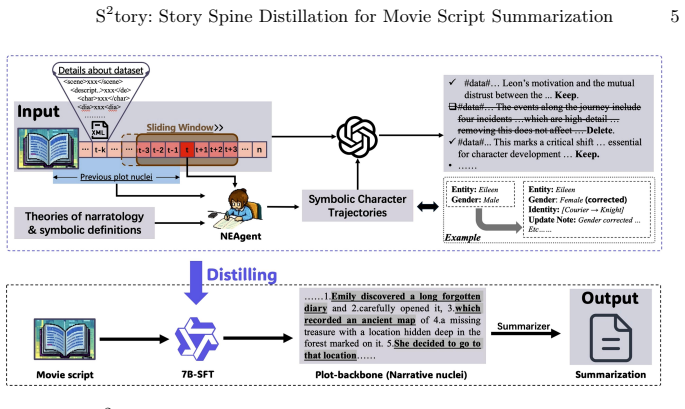
The central claim is that non-linear movie scripts can be summarized effectively by first using character development trajectories to locate plot nuclei—the essential events that drive narrative progression—via theory-constrained reasoning performed by a Narrative Expert Agent, whose output then conditions a compact model to produce the summary.
What carries the argument
Story Spine Distillation, which extracts plot nuclei by analyzing character development trajectories and uses a Narrative Expert Agent to perform theory-constrained reasoning that conditions the summarization model.
If this is right
- Summaries achieve state-of-the-art semantic fidelity at roughly 3.5 times compression on movie script data.
- The same trained components generalize in zero-shot fashion to book-length narratives.
- Human judges rate the outputs as preserving complex story structure more faithfully when narratological constraints are applied.
Where Pith is reading between the lines
- The same trajectory-based filtering could be tested on other non-linear formats such as episodic television or interactive stories.
- Distilling expert narrative reasoning this way may let smaller models handle creative generation tasks with less domain-specific data.
- If the approach holds, literary theory could become a standard conditioning layer for AI systems that process long-form fiction or drama.
Load-bearing premise
Character development trajectories can be tracked reliably enough to separate the essential plot-driving events from peripheral ones in non-linear scripts.
What would settle it
Human raters on a new set of movie scripts score summaries generated without character-trajectory analysis as equal or better in plot coherence and completeness than those produced by the full method.
Figures

read the original abstract
Movie scripts pose a fundamental challenge for automatic summarization due to their non-linear, cross-cut narrative structure, which makes surface-level saliency methods ineffective at preserving core story progression. To address this, we introduce S^2tory (Story Spine Distillation), a narratology-grounded framework that leverages character development trajectories to identify plot nuclei, the essential events that drive the narrative forward, while filtering out peripheral satellite events that merely enrich atmosphere or emotion. Our Narrative Expert Agent (NEAgent) performs theory-constrained reasoning, whose distilled knowledge conditions a small model to identify plot nuclei. Another model then uses these plot nuclei to generate the summary. Experiments on the MovieSum dataset demonstrate state-of-the-art semantic fidelity at approximately 3.5x compression, and zero-shot evaluation on BookSum confirms strong out-of-domain generalization. Human evaluation further validates that narratological theory provides an indispensable foundation for modeling complex, non-linear narratives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces S^2tory, a narratology-grounded framework for movie script summarization. It identifies plot nuclei (core driving events) from character development trajectories using a Narrative Expert Agent (NEAgent) that performs theory-constrained reasoning to distill knowledge; this conditions a small model for nuclei detection, after which a second model generates the summary. The authors claim state-of-the-art semantic fidelity on MovieSum at ~3.5x compression, strong zero-shot generalization on BookSum, and human evaluations confirming that narratological theory is an indispensable foundation for non-linear narratives.
Significance. If the performance claims and the necessity of the theoretical component hold, the work offers a principled way to move beyond surface saliency for complex narratives, with potential impact on story understanding and summarization tasks. The zero-shot transfer result is a notable strength if replicated.
major comments (2)
- [§5 Experiments and §5.2 Results] §5 Experiments and §5.2 Results: The SOTA semantic fidelity claim at 3.5x compression is not supported by explicit metric definitions (e.g., which semantic similarity measure, exact baselines, data splits, or error bars), preventing verification of the central performance assertions.
- [§4.3 and §5.3] §4.3 and §5.3: No ablation studies isolate the contribution of narratological theory and the NEAgent's theory-constrained reasoning from the two-stage architecture, generic multi-step prompting, or LLM capabilities alone. This directly undermines the human-evaluation claim that the theory is an 'indispensable foundation,' as alternative saliency or trajectory-free methods could produce equivalent results.
minor comments (2)
- [Abstract and §3] Abstract and §3: The compression ratio is stated as 'approximately 3.5x' without detailing the exact length-ratio calculation or per-script variance.
- [§3.2] §3.2: The conditioning mechanism from NEAgent output to the small model would benefit from pseudocode or an explicit diagram to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment point by point below, agreeing where clarifications and additional experiments are warranted, and outlining specific revisions to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [§5 Experiments and §5.2 Results] The SOTA semantic fidelity claim at 3.5x compression is not supported by explicit metric definitions (e.g., which semantic similarity measure, exact baselines, data splits, or error bars), preventing verification of the central performance assertions.
Authors: We acknowledge that the experimental reporting in §5.2 requires greater explicitness to enable verification. The manuscript references semantic fidelity metrics and 3.5x compression on MovieSum but does not enumerate the precise similarity measure (e.g., BERTScore F1 or embedding cosine), full baseline configurations, exact data splits, or error bars. In the revised version we will expand §5.2 with a dedicated subsection detailing all metrics, listing every baseline with hyperparameters, specifying the MovieSum train/validation/test splits, and adding error bars or confidence intervals to the reported results. This will directly support the SOTA claim without altering the underlying experiments. revision: yes
-
Referee: [§4.3 and §5.3] No ablation studies isolate the contribution of narratological theory and the NEAgent's theory-constrained reasoning from the two-stage architecture, generic multi-step prompting, or LLM capabilities alone. This directly undermines the human-evaluation claim that the theory is an 'indispensable foundation,' as alternative saliency or trajectory-free methods could produce equivalent results.
Authors: We agree that the absence of targeted ablations limits the strength of the claim that narratological theory is indispensable. While the human evaluations in §5.3 contrast S^2tory against non-narratological baselines and the NEAgent is described as theory-constrained, we did not include direct ablations that remove the theory component or replace it with generic multi-step prompting. In the revision we will add these ablation experiments to §5.3, comparing the full model against variants that omit character-trajectory modeling or use standard chain-of-thought prompting without narratological constraints. The human evaluation discussion will be updated to reflect the new results, allowing us to either reinforce or appropriately qualify the statement on the theory's foundational role. revision: yes
Circularity Check
No significant circularity; empirical claims rest on experiments rather than definitional reduction
full rationale
The paper proposes S^2tory as a narratology-grounded framework that uses character development trajectories and NEAgent theory-constrained reasoning to distill plot nuclei for summarization. No equations, derivations, or self-citations appear in the provided text that would make any prediction or result equivalent to its inputs by construction. Performance claims (SOTA semantic fidelity at 3.5x compression on MovieSum, zero-shot on BookSum) and the human-evaluation validation of narratological theory as indispensable are presented as outcomes of the two-stage architecture and experiments, not as tautologies or fitted parameters renamed as predictions. This is a standard empirical method paper whose central claims remain independent of the listed circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Narratological theory can identify plot nuclei via character development trajectories while distinguishing them from peripheral satellite events
invented entities (2)
-
Narrative Expert Agent (NEAgent)
no independent evidence
-
Plot nuclei
no independent evidence
Reference graph
Works this paper leans on
-
[1]
New literary history6(2), 237–272 (1975)
Barthes, R., Duisit, L.: An introduction to the structural analysis of narrative. New literary history6(2), 237–272 (1975)
1975
-
[2]
Longformer: The Long-Document Transformer
Beltagy, I., Peters, M.E., Cohan, A.: Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150 (2020)
work page internal anchor Pith review arXiv 2004
-
[3]
Brahman, F.: Modeling Key Narrative Elements for Story Understanding and Gen- eration. Ph.D. thesis, University of California, Santa Cruz (2022)
2022
-
[4]
Cornell university press (1978)
Chatman, S.B., Chatman, S.: Story and discourse: Narrative structure in fiction and film. Cornell university press (1978)
1978
-
[5]
In: Proceedings of the 60th Annual Meeting of the AssociationforComputationalLinguistics(Volume1:LongPapers).pp.8602–8615 (2022) 12 Authors Suppressed Due to Excessive Length
Chen, M., Chu, Z., Wiseman, S., Gimpel, K.: Summscreen: A dataset for abstrac- tive screenplay summarization. In: Proceedings of the 60th Annual Meeting of the AssociationforComputationalLinguistics(Volume1:LongPapers).pp.8602–8615 (2022) 12 Authors Suppressed Due to Excessive Length
2022
-
[6]
In: Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers)
Chitale, M.P., Bindal, U., Rajkumar, R.P., Mishra, R.: Discograms: Enhancing movie screen-play summarization using movie character-aware discourse graph. In: Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). pp. 954–965 (2025)
2025
-
[7]
In: Findings of the Association for Computational Linguistics: NAACL 2022
Guo, M., Ainslie, J., Uthus, D.C., Ontanon, S., Ni, J., Sung, Y.H., Yang, Y.: Longt5: Efficient text-to-text transformer for long sequences. In: Findings of the Association for Computational Linguistics: NAACL 2022. pp. 724–736 (2022)
2022
-
[8]
arXiv preprint arXiv:2405.10860 (2024)
Huang, Z., Zhao, J., Jin, Q.: Ecr-chain: Advancing generative language mod- els to better emotion-cause reasoners through reasoning chains. arXiv preprint arXiv:2405.10860 (2024)
-
[9]
In: Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)
Jiayang,C.,Qiu,L.,Chan,C.,Liu,X.,Song,Y.,Zhang,Z.:Eventground:Narrative reasoning by grounding to eventuality-centric knowledge graphs. In: Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). pp. 6622–6642 (2024)
2024
-
[10]
In: Findings of the as- sociation for computational linguistics: EMNLP 2022
Kryściński, W., Rajani, N., Agarwal, D., Xiong, C., Radev, D.: Booksum: A col- lection of datasets for long-form narrative summarization. In: Findings of the as- sociation for computational linguistics: EMNLP 2022. pp. 6536–6558 (2022)
2022
-
[11]
Cognitive science5(4), 293–331 (1981)
Lehnert, W.G.: Plot units and narrative summarization. Cognitive science5(4), 293–331 (1981)
1981
-
[12]
arXiv preprint arXiv:2410.19809 (2024)
Mahon, L., Lapata, M.: Screenwriter: Automatic screenplay generation and movie summarisation. arXiv preprint arXiv:2410.19809 (2024)
-
[13]
A Survey of Context Engineering for Large Language Models
Mei, L., Yao, J., Ge, Y., Wang, Y., Bi, B., Cai, Y., Liu, J., Li, M., Li, Z.Z., Zhang, D., et al.: A survey of context engineering for large language models. arXiv preprint arXiv:2507.13334 (2025)
work page internal anchor Pith review arXiv 2025
-
[14]
In: Proceedings of the 2004 conference on empirical methods in natural language processing
Mihalcea, R., Tarau, P.: Textrank: Bringing order into text. In: Proceedings of the 2004 conference on empirical methods in natural language processing. pp. 404–411 (2004)
2004
-
[15]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Phang, J., Zhao, Y., Liu, P.J.: Investigating efficiently extending transformers for long input summarization. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 3946–3961 (2023)
2023
-
[16]
In: Bobrow, D.G., Collins, A
Rumelhart, D.E.: Notes on a schema for stories. In: Bobrow, D.G., Collins, A. (eds.) Representation and Understanding: Studies in Cognitive Science (1975)
1975
-
[17]
In: Findings of the Association for Computational Linguistics: ACL
Saxena, R., Keller, F.: Moviesum: An abstractive summarization dataset for movie screenplays. In: Findings of the Association for Computational Linguistics: ACL
-
[18]
4043–4050 (2024)
pp. 4043–4050 (2024)
2024
-
[19]
In: Findings of the Association for Computational Linguistics: NAACL
Saxena, R., Keller, F.: Select and summarize: Scene saliency for movie script sum- marization. In: Findings of the Association for Computational Linguistics: NAACL
-
[20]
3439–3455 (2024)
pp. 3439–3455 (2024)
2024
-
[21]
Psychology press (2013)
Schank, R.C., Abelson, R.P.: Scripts, plans, goals, and understanding: An inquiry into human knowledge structures. Psychology press (2013)
2013
-
[22]
13 EmbeddingGemma: Powerful and Lightweight Text Representations G
Tay, Y., Dehghani, M., Tran, V.Q., Garcia, X., Wei, J., Wang, X., Chung, H.W., Shakeri, S., Bahri, D., Schuster, T., et al.: Ul2: Unifying language learn- ing paradigms. arXiv preprint arXiv:2205.05131 (2022)
-
[23]
Advances in neural information processing systems33, 17283–17297 (2020)
Zaheer, M., Guruganesh, G., Dubey, K.A., Ainslie, J., Alberti, C., Ontanon, S., Pham, P., Ravula, A., Wang, Q., Yang, L., et al.: Big bird: Transformers for longer sequences. Advances in neural information processing systems33, 17283–17297 (2020)
2020
-
[24]
Advances in neural information processing systems36, 46595–46623 (2023)
Zheng, L., Chiang, W.L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E., et al.: Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems36, 46595–46623 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.