Recognition: unknown
MemFlow: Intent-Driven Memory Orchestration for Small Language Model Agents
Pith reviewed 2026-05-09 16:50 UTC · model grok-4.3
The pith
MemFlow routes queries by intent to one of three fixed memory tiers, letting small language models achieve nearly twice the accuracy of full-context baselines on long-horizon tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
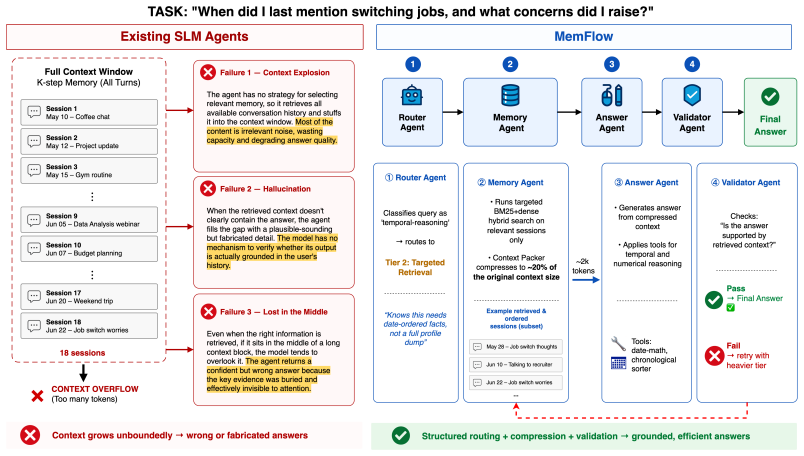
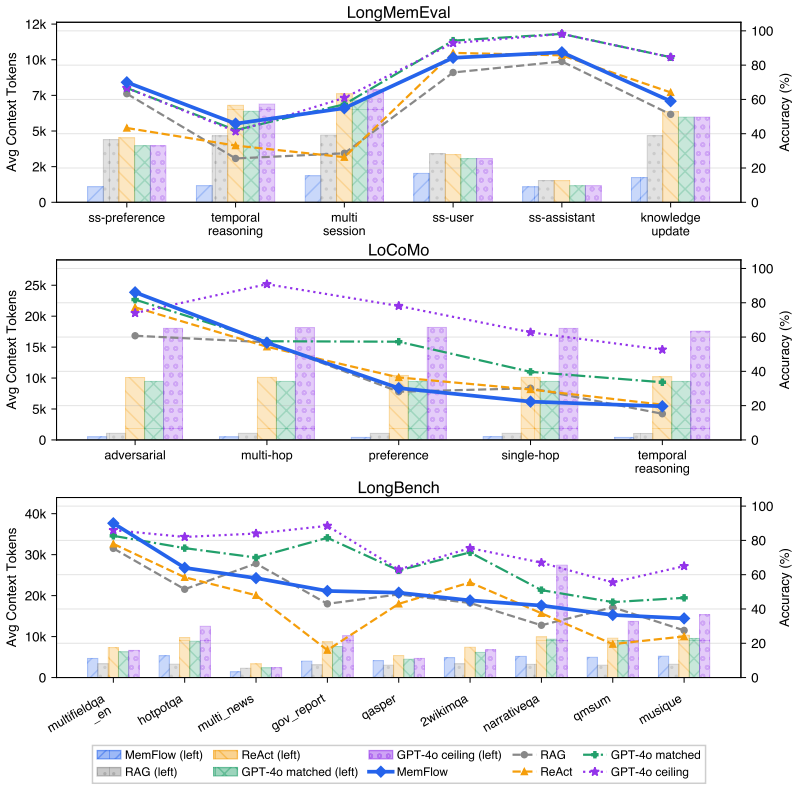
The central claim is that a training-free route-then-compile architecture, consisting of a Router Agent that assigns each query to Profile Lookup, Targeted Retrieval, or Deep Reasoning, followed by a Memory Agent that assembles evidence under a tier-specific budget and an optional Validator retry, produces nearly 2x higher accuracy than full-context prompting when the same frozen Qwen3-1.7B model is used on LongMemEval, LoCoMo, and LongBench.
What carries the argument
MemFlow's three-tier memory orchestration: a Router Agent classifies query intent, a Memory Agent executes one specialized tier and prepares evidence under a dynamic token limit, and an Answer Agent generates the final response from that compact context.
If this is right
- SLMs can sustain multi-turn performance on histories that exceed their native context window without increasing model size.
- Memory preparation becomes deterministic rather than dependent on the main model's open-ended reasoning.
- Token usage stays bounded per tier instead of growing with full history length.
- The same backbone model can be reused across tasks by swapping only the router and tier definitions.
Where Pith is reading between the lines
- The design could be extended by adding a fourth tier for very recent context or by making tier selection depend on observed token cost rather than fixed categories.
- If the three tiers prove insufficient on new domains, the framework would require either more tiers or a fallback to self-orchestration, testing the coverage assumption directly.
- The separation of router and memory execution suggests similar intent-driven orchestration could apply to tool-use or planning agents that currently rely on open-ended loops.
Load-bearing premise
The router can correctly classify every query into one of the three fixed tiers and those tiers plus the validator cover the memory needs that arise in long-horizon tasks.
What would settle it
Replace the trained router with random tier assignment on the same benchmarks and measure whether accuracy falls back to the full-context baseline level.
Figures



read the original abstract
Modern language agents must operate over long-horizon, multi-turn histories, yet deploying such agents with Small Language Models (SLMs) remains fundamentally difficult. Full-context prompting causes context overflow, flat retrieval exposes the model to noisy evidence, and open-ended agentic loops are unreliable under limited reasoning capacity. We argue that a substantial portion of SLM memory failure arises from mismatched memory operations: different query types demand categorically different retrieval strategies, evidence transformations, and context budgets that SLMs cannot reliably self-orchestrate through open-ended reasoning. We introduce MemFlow, a training-free memory orchestration framework that externalizes memory planning from the SLM. A Router Agent classifies each query by intent and dispatches it to the Memory Agent, which executes one of three specialized tiers (Profile Lookup, Targeted Retrieval, or Deep Reasoning) and assembles the resulting evidence under a dynamic, tier-aware token budget. An Answer Agent then generates a response from this compact context, and a Validator Agent optionally retries with a heavier memory tier when the response is not supported by the provided evidence. This route-then-compile design avoids tool-selection hallucination and reasoning loops while keeping the answer context compact. Evaluated on a frozen Qwen3-1.7B backbone across long-horizon memory benchmarks - LongMemEval, LoCoMo, and LongBench - MemFlow improves accuracy by nearly 2x over full-context SLM baselines. These results suggest that structured intent routing and deterministic evidence preparation can make limited-capacity models substantially more effective in resource-constrained long-horizon agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MemFlow, a training-free memory orchestration framework for small language model (SLM) agents operating over long-horizon histories. It externalizes memory planning via a Router Agent that classifies query intent and dispatches to a Memory Agent executing one of three fixed tiers (Profile Lookup, Targeted Retrieval, or Deep Reasoning), assembles evidence under a tier-aware token budget, and uses an Answer Agent plus optional Validator Agent for response generation and retry. Evaluated on a frozen Qwen3-1.7B backbone, the framework is claimed to nearly double accuracy over full-context SLM baselines on LongMemEval, LoCoMo, and LongBench by avoiding context overflow, noisy retrieval, and unreliable open-ended self-orchestration.
Significance. If the reported gains are substantiated with rigorous experiments, MemFlow would represent a meaningful advance for resource-constrained long-horizon agents. The core idea of structured intent routing plus deterministic evidence preparation offers a practical alternative to both flat retrieval and fully agentic loops, potentially improving reliability for SLMs without additional training. This could influence design patterns in multi-agent systems where capacity limits make self-orchestration fragile.
major comments (3)
- Abstract: The central performance claim of 'nearly 2x' accuracy improvement over full-context baselines on LongMemEval, LoCoMo, and LongBench is stated without any quantitative metrics, exact baseline scores, error bars, statistical significance tests, or ablation results. This absence prevents assessment of whether the gains are robust or attributable to the proposed design.
- The manuscript provides no measurement or ablation of Router Agent intent classification accuracy, nor any breakdown of tier invocation frequencies across the benchmarks. Without these data, it remains unclear whether the reported improvements derive from reliable intent-to-tier mapping or from ancillary factors such as dynamic token budgeting and evidence compilation.
- No analysis is given of query types that fall outside the three fixed tiers or of performance degradation when the Router misclassifies intent. This leaves the sufficiency of the tier set untested and risks overstating the framework's generality for arbitrary long-horizon memory needs.
minor comments (2)
- The description of the three memory tiers would be strengthened by concrete examples of query intents assigned to each tier and the precise evidence transformations performed by the Memory Agent.
- Implementation details for the Router, Memory, Answer, and Validator agents (e.g., prompting templates, decision criteria for validator retry) are referenced but not provided, hindering reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and describe the revisions planned for the manuscript.
read point-by-point responses
-
Referee: Abstract: The central performance claim of 'nearly 2x' accuracy improvement over full-context baselines on LongMemEval, LoCoMo, and LongBench is stated without any quantitative metrics, exact baseline scores, error bars, statistical significance tests, or ablation results. This absence prevents assessment of whether the gains are robust or attributable to the proposed design.
Authors: We agree that the abstract would be strengthened by including concrete numbers. In the revised version we will replace the qualitative 'nearly 2x' phrasing with the exact accuracy figures for MemFlow and the full-context baseline on each of the three benchmarks, drawn directly from the results tables in Section 4. We will also note the presence of ablation studies and any error bars or significance tests reported in the experimental section. revision: yes
-
Referee: The manuscript provides no measurement or ablation of Router Agent intent classification accuracy, nor any breakdown of tier invocation frequencies across the benchmarks. Without these data, it remains unclear whether the reported improvements derive from reliable intent-to-tier mapping or from ancillary factors such as dynamic token budgeting and evidence compilation.
Authors: Direct accuracy measurement of the Router is difficult because the benchmarks lack ground-truth intent labels. We will nevertheless add a breakdown of tier invocation frequencies (which can be extracted from the existing experimental logs) to the revised manuscript. This will make the usage patterns explicit and allow readers to assess how often each tier is selected. The end-to-end gains and tier-specific ablations already presented in Section 4 provide supporting evidence that the structured routing contributes to the observed improvements. revision: partial
-
Referee: No analysis is given of query types that fall outside the three fixed tiers or of performance degradation when the Router misclassifies intent. This leaves the sufficiency of the tier set untested and risks overstating the framework's generality for arbitrary long-horizon memory needs.
Authors: We accept that an explicit discussion of out-of-tier queries and misclassification effects would improve the paper. The three tiers were derived from the dominant query patterns in the evaluated benchmarks. In the revision we will add a limitations paragraph that enumerates query types observed to fall outside the current tier set and reports any performance degradation noted during error analysis of misrouted examples. This will clarify the scope of the framework without overstating generality. revision: yes
Circularity Check
No circularity: procedural framework with empirical claims only
full rationale
The paper describes a training-free procedural architecture (Router Agent classifies intent and routes to one of three fixed tiers executed by Memory Agent, followed by Answer Agent and optional Validator) without any equations, derivations, fitted parameters, or mathematical predictions. Central performance claims rest on benchmark evaluations (LongMemEval, LoCoMo, LongBench) with a frozen backbone rather than any reduction of results to self-defined quantities or self-citation chains. No load-bearing step equates outputs to inputs by construction, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A substantial portion of SLM memory failure arises from mismatched memory operations that SLMs cannot reliably self-orchestrate through open-ended reasoning.
invented entities (3)
-
Router Agent
no independent evidence
-
Memory Agent
no independent evidence
-
Validator Agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Jyoti Aneja, Hany Awadalla, et al. Phi-3 technical report: A highly capable language model locally on your phone.arXiv preprint arXiv:2404.14219, 2024
work page internal anchor Pith review arXiv 2024
-
[2]
Introducing the next generation of Claude.Anthropic Blog, 2024
Anthropic. Introducing the next generation of Claude.Anthropic Blog, 2024
2024
-
[3]
Self-RAG: Learning to retrieve, generate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-RAG: Learning to retrieve, generate, and critique through self-reflection. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[4]
LongBench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages ...
2024
-
[5]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E. Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review arXiv 2004
-
[6]
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, et al. SmolLM2: When smol goes big – data-centric training of a small language model.arXiv preprint arXiv:2502.02737, 2025
work page internal anchor Pith review arXiv 2025
-
[7]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
Lingjiao Chen, Matei Zaharia, and James Zou. FrugalGPT: How to use large language models while reducing cost and improving performance.arXiv preprint arXiv:2305.05176, 2023
work page internal anchor Pith review arXiv 2023
-
[8]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready AI agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review arXiv 2025
-
[9]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[10]
Pan, Ruifeng Xu, and Kam-Fai Wong
Yiming Du, Bingbing Wang, Yang He, Bin Liang, Baojun Wang, Zhongyang Li, Lin Gui, Jeff Z. Pan, Ruifeng Xu, and Kam-Fai Wong. MemGuide: Intent-driven memory selection for goal-oriented multi-session LLM agents.arXiv preprint arXiv:2505.20231, 2025
-
[11]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph RAG approach to query-focused summarization.arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review arXiv 2024
-
[12]
Tool preferences in agentic LLMs are unreliable
Kazem Faghih, Wenxiao Wang, Yize Cheng, Siddhant Bharti, Gaurang Sriramanan, Sriram Balasubramanian, Parsa Hosseini, and Soheil Feizi. Tool preferences in agentic LLMs are unreliable. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20954–20969, 2025
2025
-
[13]
Gemma Team. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Gemini: A Family of Highly Capable Multimodal Models
Google DeepMind. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The LLaMA 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
REALM: Retrieval-augmented language model pre-training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. REALM: Retrieval-augmented language model pre-training. InProceedings of the 37th International Conference on Machine Learning, pages 3929–3938, 2020
2020
-
[17]
Unsupervised Dense Information Retrieval with Contrastive Learning
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. Unsupervised dense information retrieval with contrastive learning. arXiv preprint arXiv:2112.09118, 2021. 10
work page internal anchor Pith review arXiv 2021
-
[18]
Leveraging passage retrieval with generative models for open domain question answering
Gautier Izacard and Edouard Grave. Leveraging passage retrieval with generative models for open domain question answering. InProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 874–880, 2021
2021
-
[19]
LongLLMLingua: Accelerating and enhancing LLMs in long context scenarios via prompt compression
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. LongLLMLingua: Accelerating and enhancing LLMs in long context scenarios via prompt compression. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1658–1677, 2024
2024
-
[20]
Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig
Zhengbao Jiang, Frank F. Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. InProceedings of EMNLP, 2023
2023
-
[21]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas O ˘guz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781, 2020
2020
-
[22]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks.arXiv preprint arXiv:2005.11401, 2020
work page internal anchor Pith review arXiv 2005
-
[23]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173, 2024
2024
-
[24]
Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, Liangzhen Lai, and Vikas Chandra. MobileLLM: Optimizing sub-billion parameter language models for on-device use cases.arXiv preprint arXiv:2402.14905, 2024
-
[25]
Evaluating very long-term conversational memory of LLM agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851–13870, 2024
2024
-
[26]
Query routing for homogeneous tools: An instantiation in the RAG scenario
Feiteng Mu, Yong Jiang, Liwen Zhang, Chu Liu, Wenjie Li, Pengjun Xie, and Fei Huang. Query routing for homogeneous tools: An instantiation in the RAG scenario. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 10225–10230, Miami, Florida, USA, 2024. Association for Computational Linguistics
2024
-
[27]
RouteLLM: Learning to Route LLMs with Preference Data
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E Gonzalez, M Waleed Kadous, and Ion Stoica. RouteLLM: Learning to route LLMs with preference data. arXiv preprint arXiv:2406.18665, 2024
work page internal anchor Pith review arXiv 2024
-
[28]
GPT-4o mini: Advancing cost-efficient intelligence.OpenAI Blog, 2024
OpenAI. GPT-4o mini: Advancing cost-efficient intelligence.OpenAI Blog, 2024
2024
-
[29]
OpenAI. GPT-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards llms as operating systems.arXiv preprint arXiv:2310.08560, 2023
work page internal anchor Pith review arXiv 2023
-
[31]
Vicky Zhao, Lili Qiu, and Dongmei Zhang
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Menglin Xia, Xufang Luo, Jue Zhang, Qingwei Lin, Victor Rühle, Yuqing Yang, Chin-Yew Lin, H. Vicky Zhao, Lili Qiu, and Dongmei Zhang. LLMLingua-2: Data distillation for efficient and faithful task-agnostic prompt compression. In Findings of the Association for Computational Linguistics: ACL 2024, pages 963–981, 2024
2024
-
[32]
O’Brien, Carrie J
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, 2023. 11
2023
-
[33]
Daivik Patel and Shrenik Patel. ENGRAM: Effective, lightweight memory orchestration for conversational agents.arXiv preprint arXiv:2511.12960, 2025
-
[34]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large language model connected with massive APIs.arXiv preprint arXiv:2305.15334, 2023
work page internal anchor Pith review arXiv 2023
-
[35]
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: A temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956, 2025
work page internal anchor Pith review arXiv 2025
-
[37]
System-1.x: Learning to balance fast and slow planning with language models
Swarnadeep Saha, Archiki Prasad, Justin Chih-Yao Chen, Peter Hase, Elias Stengel-Eskin, and Mohit Bansal. System-1.x: Learning to balance fast and slow planning with language models. arXiv preprint arXiv:2407.14414, 2024
-
[38]
ColBERTv2: Effective and efficient retrieval via lightweight late interaction
Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia. ColBERTv2: Effective and efficient retrieval via lightweight late interaction. InProceedings of NAACL, 2022
2022
-
[39]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. RAPTOR: Recursive abstractive processing for tree-organized retrieval. InInterna- tional Conference on Learning Representations (ICLR), 2024
2024
-
[40]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.arXiv preprint arXiv:2302.04761, 2023
work page internal anchor Pith review arXiv 2023
-
[41]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.arXiv preprint arXiv:2303.11366, 2023
work page internal anchor Pith review arXiv 2023
-
[42]
Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10014–10037, 2023
2023
-
[43]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- MemEval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813, 2024
work page internal anchor Pith review arXiv 2024
-
[44]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Awadallah, Ryen W. White, Doug Burger, and Chi Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversation.arXiv preprint arXiv:2308.08155, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Corrective Retrieval Augmented Generation
Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, and Zhen-Hua Ling. Corrective retrieval augmented generation.arXiv preprint arXiv:2401.15884, 2024
work page internal anchor Pith review arXiv 2024
-
[46]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[47]
Rankrag: Unifying context ranking with retrieval-augmented generation in llms
Yue Yu, Wei Ping, Zihan Liu, Boxin Wang, Jiaxuan You, Chao Zhang, Mohammad Shoeybi, and Bryan Catanzaro. RankRAG: Unifying context ranking with retrieval-augmented generation in LLMs.arXiv preprint arXiv:2407.02485, 2024
-
[48]
Big bird: Transformers for longer sequences
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontañón, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. Big bird: Transformers for longer sequences. InAdvances in Neural Information Processing Systems, 2020
2020
-
[49]
Patil, Naman Jain, Sheng Shen, Matei Zaharia, Ion Stoica, and Joseph E
Tianhao Zhang, Shishir G. Patil, Naman Jain, Sheng Shen, Matei Zaharia, Ion Stoica, and Joseph E. Gonzalez. RAFT: Adapting language model to domain specific RAG.arXiv preprint arXiv:2403.10131, 2024. 12
-
[50]
H2O: Heavy-hitter oracle for efficient generative inference of large language models
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, Zhangyang Wang, and Beidi Chen. H2O: Heavy-hitter oracle for efficient generative inference of large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[51]
Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A realistic web environment for building autonomous agents. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[52]
Revisiting pruning vs quantization for small language models.Findings of the Association for Computational Linguistics: EMNLP 2025, pages 12055–12070, 2025
Zihan Zhou, Simon Kurz, and Zhixue Zhao. Revisiting pruning vs quantization for small language models.Findings of the Association for Computational Linguistics: EMNLP 2025, pages 12055–12070, 2025
2025
-
[53]
Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Jinhua Zhao, Bryan Kian Hsiang Low, and Paul Pu Liang. Mem1: Learning to synergize memory and reasoning for efficient long-horizon agents.arXiv preprint arXiv:2506.15841, 2025. 13 A System Implementation Details A.1 Computational Setup All MemFlow experiments are conducted onGoogle ...
-
[54]
not found
Hard-failure detection.Empty answers, the exact string ESCALATE_REQUIRED (or variants matched by a regex), and “not found” patterns immediately trigger escalation. No LLM call is made. 18
-
[55]
5”,“21 days
Short-answer passthrough.Answers of ≤6 words, purely numeric answers (e.g.“5”,“21 days”), and boolean answers (“yes”/“no”) bypass the grounding check entirely. Single-number or short factual extractions are almost always correct when they appear in the answer agent’s output
-
[56]
Session depth
LLM grounding check.For all remaining answers, the validator calls Qwen3-1.7B with the prompt above. If the response cannot be parsed as yes/no, the validator falls back to a token- overlap heuristic (τground = 0.07). C Benchmark and Evaluation Details C.1 Benchmark Composition Table 7 summarizes the three benchmarks used in our evaluation. Table 7: Bench...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.