Recognition: no theorem link
DGPO: Distribution Guided Policy Optimization for Fine Grained Credit Assignment
Pith reviewed 2026-05-11 02:16 UTC · model grok-4.3
The pith
DGPO replaces the KL penalty with an entropy-gated Hellinger distance to assign credit to individual tokens in language model reasoning chains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
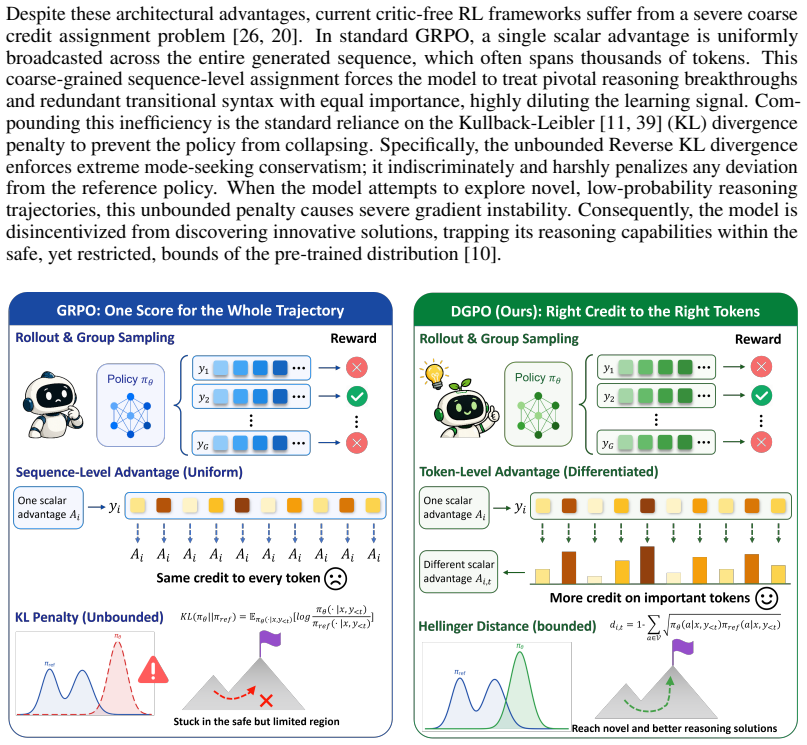
DGPO is a critic-free reinforcement learning framework that reinterprets distribution deviation as a guiding signal rather than a rigid penalty. It replaces the unbounded KL divergence with the bounded Hellinger distance to quantify token-level exploration safely. An entropy gating mechanism scales this deviation by the policy's epistemic uncertainty to distinguish genuine reasoning breakthroughs from noise. By redistributing the sequence-level advantage to tokens based on these gated scores, DGPO incentivizes critical steps and suppresses low-value deviations, completely eliminating the traditional token-level KL penalty and achieving fine-grained credit reallocation.
What carries the argument
The entropy gating mechanism applied to Hellinger distance, which scales distribution deviation by epistemic uncertainty to enable token-level credit redistribution.
If this is right
- Training becomes more stable by avoiding unbounded KL divergence and its gradient issues.
- Fine-grained credit assignment improves performance on complex reasoning benchmarks without added compute for value networks.
- Models can explore and discover novel reasoning trajectories more effectively.
- Critic-free alignment reaches state-of-the-art results on tasks like AIME math problems.
Where Pith is reading between the lines
- Similar gating ideas could be applied to other policy optimization methods in sequential decision making beyond language models.
- Removing the need for separate value networks might simplify scaling reinforcement learning to larger models.
- Further tests on non-math reasoning tasks would show if the approach generalizes to other domains.
Load-bearing premise
The entropy gating mechanism can reliably distinguish genuine reasoning breakthroughs from hallucinatory noise using only the policy's uncertainty estimates without introducing new biases.
What would settle it
Running an ablation study that disables the entropy gating in DGPO and observing either no gain over baselines or increased instability on AIME2024 and AIME2025 would falsify the central claim.
Figures



read the original abstract
Reinforcement learning is crucial for aligning large language models to perform complex reasoning tasks. However, current algorithms such as Group Relative Policy Optimization suffer from coarse grained, sequence level credit assignment, which severely struggles to isolate pivotal reasoning steps within long Chain of Thought generations. Furthermore, the standard unbounded Kullback Leibler divergence penalty induces severe gradient instability and mode seeking conservatism, ultimately stifling the discovery of novel reasoning trajectories. To overcome these limitations, we introduce Distribution Guided Policy Optimization, a novel critic free reinforcement learning framework that reinterprets distribution deviation as a guiding signal rather than a rigid penalty. DGPO replaces the volatile KL divergence with the bounded Hellinger distance to safely quantify token level exploration without the risk of gradient explosion. To effectively distinguish genuine reasoning breakthroughs from hallucinatory noise, we propose an entropy gating mechanism that scales this deviation by the policy`s epistemic uncertainty. By dynamically redistributing the coarse sequence-level advantage to individual tokens based on these gated scores, DGPO heavily incentivizes critical exploratory steps while suppressing unwarranted, low-entropy deviations. Consequently, DGPO completely eliminates the traditional token-level KL penalty and achieves fine-grained credit reallocation without the computational overhead of an additional value network. Extensive empirical evaluations demonstrate that DGPO sets a new state-of-the-art for critic free alignment. Notably, on the Qwen2.5-32B architecture, DGPO achieves 60.0% Avg@32 accuracy and 46.0% Avg@32 accuracy on the challenging AIME2024 and AIME2025 benchmarks respectively, substantially outperforming competitive baselines like DAPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Distribution Guided Policy Optimization (DGPO), a critic-free RL framework for fine-grained credit assignment in LLM reasoning alignment. It replaces the standard KL divergence penalty with bounded Hellinger distance to quantify token-level exploration, introduces an entropy gating mechanism that scales distribution deviations by the policy's token entropy (as epistemic uncertainty proxy), and redistributes coarse sequence-level advantages to individual tokens. This is claimed to eliminate token-level KL penalties and value network overhead while achieving SOTA empirical results, including 60.0% Avg@32 on AIME2024 and 46.0% on AIME2025 with Qwen2.5-32B, outperforming baselines such as DAPO.
Significance. If the central claims hold, DGPO would represent a meaningful advance in critic-free RL for long CoT reasoning by enabling more stable, fine-grained credit assignment without KL-induced instability or extra value networks. The reported benchmark gains on challenging math problems are notable and could influence practical alignment pipelines for large models, provided the entropy gating avoids introducing new selection biases in advantage estimation.
major comments (2)
- [§3.2] §3.2 (Entropy Gating Mechanism) and the gated advantage estimator: the assumption that token entropy reliably proxies epistemic uncertainty to separate 'genuine reasoning breakthroughs' from 'hallucinatory noise' is load-bearing for the fine-grained redistribution claim. Token entropy in LLMs conflates aleatoric uncertainty, calibration, and data noise rather than isolating epistemic doubt over trajectories; without bias analysis, variance bounds, or a proof that the resulting estimator remains unbiased for policy gradients, the elimination of KL and value-network overhead may come at the cost of new selection bias on long CoT sequences.
- [§4] §4 (Experiments): the SOTA claims rest on Avg@32 accuracies (60.0% AIME2024, 46.0% AIME2025) outperforming DAPO, yet no ablations isolate the contribution of entropy gating versus Hellinger distance alone, and no statistical tests or variance estimates across runs are reported. This weakens attribution of gains to the proposed mechanisms.
minor comments (2)
- [Abstract] Abstract: minor typographical issues including 'policy`s' (should be 'policy's') and inconsistent spacing around 'Kullback Leibler'.
- [§3] Notation: the manuscript introduces Hellinger distance and gated scores but does not explicitly define the final advantage redistribution formula in a single equation; adding a consolidated expression would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, providing the strongest honest responses possible while committing to revisions that improve the work without overstating its current theoretical or empirical foundations.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Entropy Gating Mechanism) and the gated advantage estimator: the assumption that token entropy reliably proxies epistemic uncertainty to separate 'genuine reasoning breakthroughs' from 'hallucinatory noise' is load-bearing for the fine-grained redistribution claim. Token entropy in LLMs conflates aleatoric uncertainty, calibration, and data noise rather than isolating epistemic doubt over trajectories; without bias analysis, variance bounds, or a proof that the resulting estimator remains unbiased for policy gradients, the elimination of KL and value-network overhead may come at the cost of new selection bias on long CoT sequences.
Authors: We agree that token entropy is an imperfect proxy that mixes epistemic uncertainty with aleatoric noise, calibration issues, and data artifacts, and that this approximation is central to the gated redistribution claim. In the original manuscript we present it as a practical heuristic motivated by observed training dynamics in long CoT, where low-entropy tokens tend to reflect confident but potentially spurious continuations. To respond to the concern, we have added a dedicated limitations paragraph in the revised Section 3.2 that explicitly discusses the conflation of uncertainty types and provides supporting empirical plots of gated versus ungated advantage variance during training. A full bias analysis, variance bounds, or proof of unbiasedness for the resulting policy-gradient estimator is not present in the current work and would require a separate theoretical treatment; we therefore flag this as an open direction rather than claiming theoretical guarantees. revision: partial
-
Referee: [§4] §4 (Experiments): the SOTA claims rest on Avg@32 accuracies (60.0% AIME2024, 46.0% AIME2025) outperforming DAPO, yet no ablations isolate the contribution of entropy gating versus Hellinger distance alone, and no statistical tests or variance estimates across runs are reported. This weakens attribution of gains to the proposed mechanisms.
Authors: We accept that the lack of component-wise ablations and run-level statistics limits the strength of causal attribution for the reported gains. In the revised manuscript we have inserted a new subsection in Section 4 that presents ablation results for four variants: (i) Hellinger distance without gating, (ii) KL distance with gating, (iii) full DGPO, and (iv) a no-redistribution baseline. We also now report mean Avg@32 scores together with standard deviations computed across five independent random seeds for both AIME2024 and AIME2025. These additions allow readers to assess the individual and combined contributions of the two proposed mechanisms. revision: yes
- A formal proof, bias analysis, or variance bounds establishing that the entropy-gated advantage estimator is unbiased for the policy gradient.
Circularity Check
No significant circularity detected in DGPO derivation
full rationale
The paper presents DGPO as a new critic-free RL framework that replaces KL divergence with bounded Hellinger distance and introduces an entropy gating mechanism for token-level credit redistribution. The abstract and described construction rely on reinterpretation of distribution deviation as a guiding signal, empirical benchmarks on AIME tasks, and architectural claims about eliminating token-level KL penalties and value networks. No equations, fitted parameters, or self-citations are shown that reduce the central results to inputs by construction, self-definition, or tautology. The derivation chain remains self-contained against external benchmarks and does not invoke load-bearing uniqueness theorems or ansatzes from prior self-work.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Policy gradient methods can be applied to token-level advantages derived from sequence-level rewards
Reference graph
Works this paper leans on
-
[1]
Shun-ichi Amari.Information geometry and its applications. Springer, 2016
work page 2016
-
[2]
Rudolf Beran. Minimum hellinger distance estimates for parametric models.The annals of Statistics, pages 445–463, 1977
work page 1977
-
[3]
Rm-r1: Reward modeling as reasoning.arXiv preprint arXiv:2505.02387, 2025
Xiusi Chen, Gaotang Li, Ziqi Wang, Bowen Jin, Cheng Qian, Yu Wang, Hongru Wang, Yu Zhang, Denghui Zhang, Tong Zhang, et al. Rm-r1: Reward modeling as reasoning.arXiv preprint arXiv:2505.02387, 2025
-
[4]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Pre-trained policy discriminators are general reward models.arXiv preprint arXiv:2507.05197, 2025
Shihan Dou, Shichun Liu, Yuming Yang, Yicheng Zou, Yunhua Zhou, Shuhao Xing, Chenhao Huang, Qiming Ge, Demin Song, Haijun Lv, et al. Pre-trained policy discriminators are general reward models.arXiv preprint arXiv:2507.05197, 2025
-
[6]
Group-in-Group Policy Optimization for LLM Agent Training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978, 2025
work page internal anchor Pith review arXiv 2025
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Videocurl: Video curriculum reinforcement learning with orthogonal difficulty decomposition, 2025
Hongbo Jin, Kuanwei Lin, Wenhao Zhang, Yichen Jin, and Ge Li. Videocurl: Video curriculum reinforcement learning with orthogonal difficulty decomposition, 2025
work page 2025
-
[9]
Himac: Hierarchical macro-micro learning for long-horizon llm agents, 2026
Hongbo Jin, Rongpeng Zhu, Jiayu Ding, Wenhao Zhang, and Ge Li. Himac: Hierarchical macro-micro learning for long-horizon llm agents, 2026
work page 2026
-
[10]
Tomasz Korbak, Hady Elsahar, Germán Kruszewski, and Marc Dymetman. On reinforcement learning and distribution matching for fine-tuning language models with no catastrophic forget- ting. InAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - ...
work page 2022
-
[11]
On information and sufficiency.The annals of mathematical statistics, 22(1):79–86, 1951
Solomon Kullback and Richard A Leibler. On information and sufficiency.The annals of mathematical statistics, 22(1):79–86, 1951
work page 1951
-
[12]
Zhaochun Li, Chen Wang, Jionghao Bai, Shisheng Cui, Ge Lan, Zhou Zhao, and Yue Wang. Distribution-centric policy optimization dominates exploration-exploitation trade-off.arXiv preprint arXiv:2601.12730, 2026
-
[13]
Ziniu Li, Tian Xu, Yushun Zhang, Zhihang Lin, Yang Yu, Ruoyu Sun, and Zhi-Quan Luo. Remax: A simple, effective, and efficient reinforcement learning method for aligning large language models. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, pages 29128–29163
work page 2024
-
[14]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. 10
work page 2024
-
[15]
Yuliang Liu, Junjie Lu, Zhaoling Chen, Chaofeng Qu, Jason Klein Liu, Chonghan Liu, Zefan Cai, Yunhui Xia, Li Zhao, Jiang Bian, et al. Adaptivestep: Automatically dividing reasoning step through model confidence.arXiv preprint arXiv:2502.13943, 2025
-
[16]
Fipo: Eliciting deep reasoning with future-kl influenced policy optimization, 2026
Chiyu Ma, Shuo Yang, Kexin Huang, Jinda Lu, Haoming Meng, Shangshang Wang, Bolin Ding, Soroush V osoughi, Guoyin Wang, and Jingren Zhou. Fipo: Eliciting deep reasoning with future-kl influenced policy optimization.arXiv preprint arXiv:2603.19835, 2026
-
[17]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human fee...
work page 2022
-
[18]
Qwen2.5 technical report, 2025
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page 2025
-
[19]
Manning, Stefano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023
work page 2023
-
[20]
Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianté Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hannaneh Hajishirzi, and Yejin Choi. Is reinforcement learning (not) for natural language processing: Benchmarks, baselines, and building blocks for natural language policy optimization. InThe Eleventh International Conference on Learning Representa...
work page 2023
-
[21]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
R- prm: Reasoning-driven process reward modeling
Shuaijie She, Junxiao Liu, Yifeng Liu, Jiajun Chen, Xin Huang, and Shujian Huang. R- prm: Reasoning-driven process reward modeling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 13449–13462, 2025
work page 2025
-
[24]
Hybridflow: A flexible and efficient RLHF framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient RLHF framework. InProceedings of the Twentieth European Conference on Computer Systems, EuroSys 2025, Rotterdam, The Netherlands, 30 March 2025 - 3 April 2025, pages 1279–1297
work page 2025
-
[25]
Espo: Entropy importance sampling policy optimization.arXiv preprint arXiv:2512.00499, 2025
Yuepeng Sheng, Yuwei Huang, Shuman Liu, Anxiang Zeng, and Haibo Zhang. Espo: Entropy importance sampling policy optimization.arXiv preprint arXiv:2512.00499, 2025
-
[26]
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
work page 1998
-
[27]
Solving math word problems with process- and outcome-based feedback
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process-and outcome-based feedback.arXiv preprint arXiv:2211.14275, 2022. 11
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Beyond reverse KL: generalizing direct preference optimization with diverse divergence constraints
Chaoqi Wang, Yibo Jiang, Chenghao Yang, Han Liu, and Yuxin Chen. Beyond reverse KL: generalizing direct preference optimization with diverse divergence constraints. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024
work page 2024
-
[29]
Chen Wang, Zhaochun Li, Jionghao Bai, Yuzhi Zhang, Shisheng Cui, Zhou Zhao, and Yue Wang. Arbitrary entropy policy optimization: Entropy is controllable in reinforcement finetuning.arXiv e-prints, pages arXiv–2510, 2025
work page 2025
-
[30]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122, 2024
work page internal anchor Pith review arXiv 2024
-
[31]
Chenlu Ye, Zhou Yu, Ziji Zhang, Hao Chen, Narayanan Sadagopan, Jing Huang, Tong Zhang, and Anurag Beniwal. Beyond correctness: Harmonizing process and outcome rewards through rl training.arXiv preprint arXiv:2509.03403, 2025
-
[32]
Dynamic and generalizable process reward modeling
Zhangyue Yin, Qiushi Sun, Zhiyuan Zeng, Qinyuan Cheng, Xipeng Qiu, and Xuan-Jing Huang. Dynamic and generalizable process reward modeling. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4203–4233, 2025
work page 2025
-
[33]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Token- level direct preference optimization
Yongcheng Zeng, Guoqing Liu, Weiyu Ma, Ning Yang, Haifeng Zhang, and Jun Wang. Token- level direct preference optimization. InForty-first International Conference on Machine Learn- ing, ICML 2024, Vienna, Austria, July 21-27, 2024, pages 58348–58365
work page 2024
-
[35]
Yao Zhang, Yu Wu, Haowei Zhang, Weiguo Li, Haokun Chen, Jingpei Wu, Guohao Li, Zhen Han, and V olker Tresp. Groundedprm: Tree-guided and fidelity-aware process reward modeling for step-level reasoning.arXiv preprint arXiv:2510.14942, 2025
-
[36]
Zheng Zhang, Ziwei Shan, Kaitao Song, Yexin Li, and Kan Ren. Linking process to outcome: Conditional reward modeling for llm reasoning.arXiv preprint arXiv:2509.26578, 2025
-
[37]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
arXiv preprint arXiv:2603.01162v3 , year=
Hongyi Zhou, Kai Ye, Erhan Xu, Jin Zhu, Ying Yang, Shijin Gong, and Chengchun Shi. Demystifying group relative policy optimization: Its policy gradient is a u-statistic.arXiv preprint arXiv:2603.01162, 2026
-
[39]
Fine-Tuning Language Models from Human Preferences
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019. 12 A Theoretical Analysis and Proofs In this section, we provide detailed mathematical derivations and theoretical proofs for the core mechan...
work page internal anchor Pith review Pith/arXiv arXiv 1909
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.