Recognition: unknown
VLMaxxing through FrameMogging Training-Free Anti-Recomputation for Video Vision-Language Models
Pith reviewed 2026-05-08 01:26 UTC · model grok-4.3
The pith
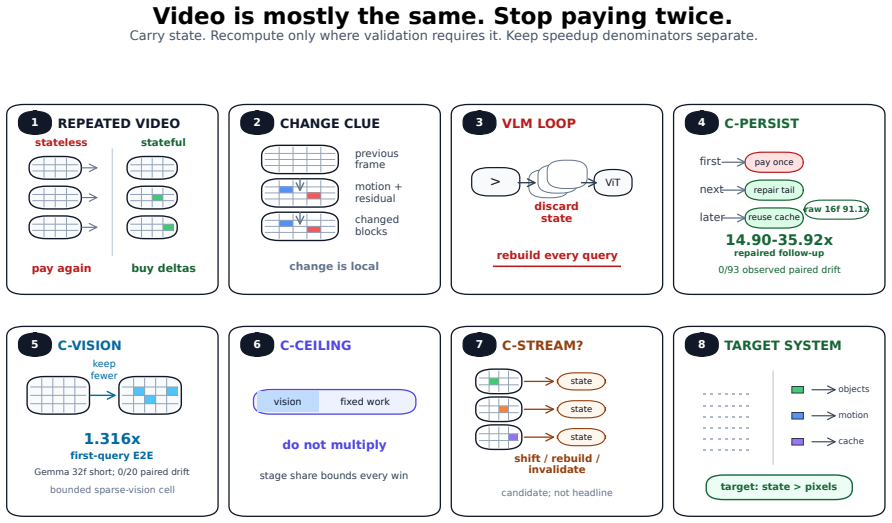
Video vision-language models can reuse prior visual state for follow-up questions on the same video, preserving answer correctness while cutting latency by up to 36 times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Video VLMs keep paying for visual state the stream already told us was stable. The factory wall did not move, but most VLM pipelines still hand the model dense RGB frames or a fresh prefix again. We study that waste as training-free anti-recomputation: reuse state when validation says it survives, and buy fresh evidence when the scene, query, or cache topology requires it. On frozen Qwen2.5-VL-7B-Instruct-4bit, adaptive same-video follow-up reuse preserves paired choices and correctness on a 93-query VideoMME breadth setting while reducing follow-up latency by 14.90-35.92x. Fresh-video pruning is smaller but real.
What carries the argument
adaptive same-video follow-up reuse that validates whether prior visual state remains stable enough to skip fresh processing
If this is right
- Follow-up latency drops 14.9 to 35.9 times on the tested Qwen model while choices and correctness stay identical to full processing.
- The first query on any new video remains fully cold-start; gains appear only on later questions about the same video.
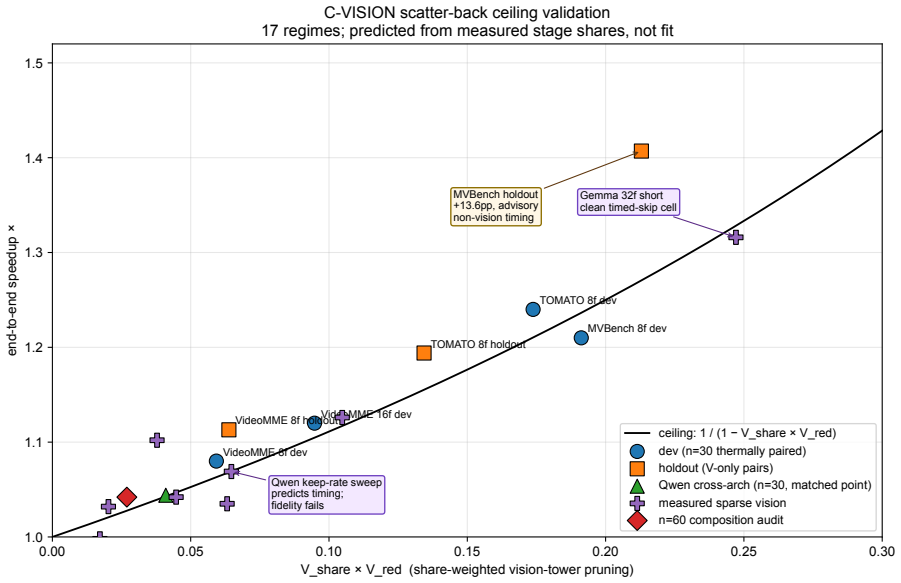
- C-VISION pruning of vision-tower work on fresh videos yields a 1.316 times first-query speedup on Gemma 4-E4B-4bit with no drift.
- Stage-share ceiling means any component speedup contributes to end-to-end time only in proportion to how much wall-clock time that stage originally took.
- Stress tests confirm repeated-question schedules hold through 50 turns and that prompt variation separates conservative versus aggressive reuse policies.
Where Pith is reading between the lines
- Longer multi-turn video conversations could become feasible on current hardware if reuse scales to hours of footage.
- The same validation logic might extend to audio or text streams that also contain long stable segments.
- Models could be trained to emit explicit signals about motion or object state, making the validation step cheaper and more reliable.
- Testing the approach on videos with gradual lighting shifts or camera motion would reveal where the stability boundary actually lies.
Load-bearing premise
The validation check can reliably tell when visual state has stayed the same and is still sufficient for the correct answer, without missing changes that would alter what the model should say.
What would settle it
Run the 93 VideoMME queries with controlled small scene alterations inserted after the first answer; if reused answers diverge from full-recomputation answers on any query, the preservation claim fails.
Figures




read the original abstract
Video vision-language models (VLMs) keep paying for visual state the stream already told us was stable. The factory wall did not move, but most VLM pipelines still hand the model dense RGB frames or a fresh prefix again. We study that waste as training-free anti-recomputation: reuse state when validation says it survives, and buy fresh evidence when the scene, query, or cache topology requires it. The largest measured win is after ingest. On frozen Qwen2.5-VL-7B-Instruct-4bit, adaptive same-video follow-up reuse preserves paired choices and correctness on a 93-query VideoMME breadth setting while reducing follow-up latency by 14.90-35.92x. The first query is still cold; the win starts when later questions reuse the same video state. Stress tests bound the result: repeated-question schedules hold through 50 turns, while dense-answer-anchored prompt variation separates conservative fixed K=1 repair from faster aggressive policies that drift. Fresh-video pruning is smaller but real. C-VISION skips timed vision-tower work before the first answer is generated. On Gemma 4-E4B-4bit, the clean 32f short cell reaches 1.316x first-query speedup with no paired drift or parse failures on 20 items; Qwen shows the fidelity/speed boundary. Stage-share ceiling (C-CEILING) is the accounting guardrail: a component speedup becomes an end-to-end speedup only in proportion to the wall-clock share it accelerates, so C-VISION and after-ingest follow-up reuse do not multiply. Candidate C-STREAM remains a native-rate target, not a headline result here. The broader direction is VLM-native media that expose change, motion, uncertainty, object state, sensor time, and active tiles directly, so models do not have to rediscover the world from dense RGB every frame.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces training-free anti-recomputation techniques for video vision-language models (VLMs), focusing on adaptive reuse of visual state for follow-up queries on the same video (C-STREAM style) and fresh-video pruning (C-VISION). On frozen Qwen2.5-VL-7B-Instruct-4bit, it claims that adaptive same-video follow-up reuse preserves paired choices and correctness on a 93-query VideoMME setting while achieving 14.90-35.92x follow-up latency reduction. Additional results include 1.316x first-query speedup on Gemma 4-E4B-4bit with C-VISION, bounded by stress tests (50-turn repeated questions and dense-answer-anchored prompt variation). The work emphasizes component speedups, stage-share accounting (C-CEILING), and a broader call for VLM-native media exposing change and uncertainty.
Significance. If the empirical results hold under detailed validation, the approach could meaningfully improve inference efficiency for multi-turn video VLM applications by avoiding redundant visual recomputation, particularly for follow-up queries where state stability is high. The concrete speedups on named models (Qwen2.5-VL, Gemma) and benchmarks (VideoMME) with preserved correctness are a strength, as is the explicit accounting for wall-clock share via C-CEILING. However, the lack of description for the core stability validator limits immediate impact and reproducibility.
major comments (2)
- [Abstract] Abstract and § on adaptive reuse: the headline claim of preserved correctness with 14.90-35.92x latency reduction rests on an unspecified 'validation' procedure that decides when visual state survives. No details are provided on the detector (e.g., frame differencing, feature similarity, query-dependent check), its false-negative rate for changes affecting downstream answers, or failure modes under prompt variation. The stress tests bound only the chosen policy, not whether the underlying detector systematically misses relevant changes.
- [Abstract] Abstract, stress-test paragraph: the 50-turn repeated-question and dense-answer-anchored variation tests are described only at high level. It is unclear how these isolate the stability detector's robustness versus test-distribution artifacts, or what controls were used for drift detection and error analysis.
minor comments (2)
- [Abstract] Abstract: 'C-VISION skips timed vision-tower work' and 'C-CEILING' are introduced without prior definition or cross-reference, making the first read harder.
- [Abstract] Abstract: the 93-query VideoMME breadth setting and 20-item Gemma evaluation lack any mention of query selection criteria or diversity controls.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. The feedback correctly identifies areas where additional description is needed for reproducibility. We will revise the manuscript with expanded sections on the stability validator and stress-test methodology, including implementation details, quantitative analysis, and controls. These changes will be incorporated as a major revision.
read point-by-point responses
-
Referee: [Abstract] Abstract and § on adaptive reuse: the headline claim of preserved correctness with 14.90-35.92x latency reduction rests on an unspecified 'validation' procedure that decides when visual state survives. No details are provided on the detector (e.g., frame differencing, feature similarity, query-dependent check), its false-negative rate for changes affecting downstream answers, or failure modes under prompt variation. The stress tests bound only the chosen policy, not whether the underlying detector systematically misses relevant changes.
Authors: We agree that the current manuscript provides insufficient detail on the stability validator, limiting immediate reproducibility. The validator combines lightweight frame differencing (pixel-level L2 threshold) with cosine similarity on pooled visual encoder features, applied query-dependently only when the follow-up query references visual content. In the revision we will add a dedicated subsection with the exact algorithm, chosen thresholds, false-negative rate estimation (via manual review of 50 VideoMME pairs), and enumerated failure modes under prompt variation. This directly addresses the concern that stress tests alone do not validate the detector. revision: yes
-
Referee: [Abstract] Abstract, stress-test paragraph: the 50-turn repeated-question and dense-answer-anchored variation tests are described only at high level. It is unclear how these isolate the stability detector's robustness versus test-distribution artifacts, or what controls were used for drift detection and error analysis.
Authors: We acknowledge the high-level presentation of the stress tests. The 50-turn repeated-question schedule uses identical prompts on an unchanged video to measure cumulative drift, while dense-answer-anchored variation inserts paraphrases that still require the same visual evidence. In the revised manuscript we will expand this paragraph to specify the exact prompt templates, the full-recomputation baseline used for drift detection, the error-analysis protocol (answer-choice agreement plus manual correctness check), and controls for test-distribution artifacts. These additions will clarify how the tests bound detector robustness rather than merely the chosen policy. revision: yes
Circularity Check
No circularity; empirical latency results on frozen VLMs with no derivation chain
full rationale
The manuscript reports measured speedups from adaptive state reuse on specific frozen models (Qwen2.5-VL-7B, Gemma) and query sets (VideoMME), bounded by stress tests such as 50-turn repetition and prompt variation. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear. The validation procedure for stable visual state is presented as an engineering choice whose correctness is evaluated directly by the reported paired-choice preservation and failure-mode tests rather than reduced to prior self-referential results. The work is therefore self-contained as an empirical optimization study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Visual state for a given video remains stable enough across follow-up queries that cached features can be reused without accuracy loss when validation passes.
Reference graph
Works this paper leans on
-
[1]
CodecSight: Leveraging Video Codec Signals for Efficient Streaming VLM Inference
Yulin Zou, Yan Chen, Wenyan Chen, JooYoung Park, Shivaraman Nitin, Luo Tao, Fran- cisco Romero, and Dmitrii Ustiugov. CodecSight: Leveraging Video Codec Signals for Efficient Streaming VLM Inference . arXiv:2604.06036, 2026. 32
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
arXiv preprint arXiv:2602.13191 , year=
Sayan Deb Sarkar, Rémi Pautrat, Ondrej Miksik, Marc Pollefeys, Iro Armeni, Mahdi Rad, and Mihai Dusmanu. CoPE-VideoLM: Leveraging Codec Primitives For Efficient Video Language Modeling. arXiv:2602.13191, 2026
-
[3]
Chao-Yuan Wu, Manzil Zaheer, Hexiang Hu, R. Manmatha, Alexander J. Smola, and Philipp Krähenbühl. Compressed Video Action Recognition . CVPR 2018; arXiv:1712.00636. Pages 6026–6035. doi:10.1109/CVPR.2018.00631
-
[4]
CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion . EuroSys 2025; arXiv:2405.16444
-
[5]
Déjà Vu: Efficient Video-Language Query Engine with Learning-based Inter-Frame Computation Reuse
Jinwoo Hwang, Daeun Kim, Sangyeop Lee, Yoonsung Kim, Guseul Heo, Hojoon Kim, Yunseok Jeong, Tadiwos Meaza, Eunhyeok Park, Jeongseob Ahn, and Jongse Park. Déjà Vu: Efficient Video-Language Query Engine with Learning-based Inter-Frame Computation Reuse . PVLDB 18(10):3284–3298, 2025; arXiv:2506.14107
-
[6]
Eventful Transformers: Leveraging Temporal Redundancy in Vision Transformers
Matthew Dutson, Yin Li, and Mohit Gupta. Eventful Transformers: Leveraging Temporal Redundancy in Vision Transformers . ICCV 2023, pages 16911–16923; arXiv:2308.13494
-
[7]
EvoPrune: Early-Stage Visual Token Prun- ing for Efficient MLLMs
Yuhao Chen, Bin Shan, Xin Ye, and Cheng Chen. EvoPrune: Early-Stage Visual Token Prun- ing for Efficient MLLMs . arXiv:2603.03681, 2026
-
[8]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An Image is Worth 1/2 Tokens After Layer 2: Plug-and-Play Inference Acceleration for Large Vision-Language Models . ECCV 2024 Oral; pages 19–35. doi:10.1007/978-3-031-73004- 7_2. arXiv:2403.06764
-
[9]
arXiv preprint arXiv:2503.11187 (2025)
Leqi Shen, Guoqiang Gong, Tao He, Yifeng Zhang, Pengzhang Liu, Sicheng Zhao, and Guiguang Ding. FastVID: Dynamic Density Pruning for Fast Video Large Language Mod- els. NeurIPS 2025 poster; arXiv:2503.11187; OpenReview: https://openreview.net/forum? id=2xS4VtpApy
-
[10]
FastVLM: Efficient Vision Encoding for Vision Language Models
Pavan Kumar Anasosalu Vasu, Fartash Faghri, Chun-Liang Li, Cem Koc, Nate True, Albert Antony, Gokula Santhanam, James Gabriel, Peter Grasch, Oncel Tuzel, and Hadi Pouransari. FastVLM: Efficient Vision Encoding for Vision Language Models . CVPR 2025, pages 19769– 19780; arXiv:2412.13303
-
[11]
Ziyang Fan, Keyu Chen, Ruilong Xing, Yulin Li, Li Jiang, and Zhuotao Tian. FlashVID: Ef- ficient Video Large Language Models via Training-free Tree-based Spatiotemporal Token Merg- ing. ICLR 2026 Oral; arXiv:2602.08024; OpenReview: https://openreview.net/forum?id= H6rDX4w6Al
-
[12]
Tianyu Fu, Tengxuan Liu, Qinghao Han, Guohao Dai, Shengen Yan, Huazhong Yang, Xuefei Ning, and Yu Wang. FrameFusion: Combining Similarity and Importance for Video Token Reduction on Large Vision Language Models . In Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV) , pages 22654–22663, 2025; arXiv:2501.01986. https://openacc...
-
[13]
Gemma 4 E4B model card
Google DeepMind. Gemma 4 E4B model card . https://huggingface.co/google/ gemma-4-E4B. Accessed 2026-04-30. 33
2026
-
[14]
gemma-4-e4b-4bit model card
MLX Community. gemma-4-e4b-4bit model card . https://huggingface.co/mlx-community/ gemma-4-e4b-4bit . Accessed 2026-04-30
2026
-
[15]
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, and Yu Qiao. MVBench: A Comprehensive Multi-modal Video Understanding Benchmark . CVPR 2024, pages 22195–22206; arXiv:2311.17005
-
[16]
FFmpeg Codecs Documentation: export_mvs and motion vector side data
FFmpeg. FFmpeg Codecs Documentation: export_mvs and motion vector side data . https: //ffmpeg.org/ffmpeg-codecs.html. Accessed 2026-04-29
2026
-
[17]
FFmpeg Filters Documentation: codecview
FFmpeg. FFmpeg Filters Documentation: codecview. https://ffmpeg.org/ ffmpeg-filters.html. Accessed 2026-04-29
2026
-
[18]
ISO/IEC DIS 23888-2, Information technology — Artificial intelligence for mul- timedia — Part 2: Video coding for machines
ISO/IEC. ISO/IEC DIS 23888-2, Information technology — Artificial intelligence for mul- timedia — Part 2: Video coding for machines . Draft International Standard, enquiry phase; ISO stage 40.20, DIS ballot initiated for 12 weeks; under development, 2026. https://www. mpeg.org/standards/MPEG-AI/2/; https://www.iso.org/standard/88879.html. Accessed 2026-04-29
2026
-
[19]
JPEG. JPEG AI . https://jpeg.org/jpegai/. Accessed 2026-04-29
2026
-
[20]
JPEG. JPEG XE activity status . https://jpeg.org/items/20241121_jpeg_xe_activity_ status.html. Accessed 2026-04-29
-
[21]
HERMES: KV Cache as Hierarchical Memory for Efficient Streaming Video Understanding
Haowei Zhang, Shudong Yang, Jinlan Fu, See-Kiong Ng, and Xipeng Qiu. HERMES: KV Cache as Hierarchical Memory for Efficient Streaming Video Understanding . ACL 2026 Main; arXiv:2601.14724
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Llava-prumerge: Adaptive token reduction for efficient large multimodal models
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. LLaV A-PruMerge: Adap- tive Token Reduction for Efficient Large Multimodal Models . ICCV 2025, pages 22857–22867; arXiv:2403.15388
-
[23]
Dolby Atmos Master File
Library of Congress. Dolby Atmos Master File . https://www.loc.gov/preservation/ digital/formats/fdd/fdd000646.shtml. Accessed 2026-04-29
2026
-
[24]
MPEG-4, Visual Coding, Main Profile
Library of Congress. MPEG-4, Visual Coding, Main Profile . https://www.loc.gov/ preservation/digital/formats/fdd/fdd000048.shtml. Accessed 2026-04-29
2026
-
[25]
MLX-VLM: Vision Language Models on your Mac using MLX
Bayram Annakov. MLX-VLM: Vision Language Models on your Mac using MLX . https:// github.com/Blaizzy/mlx-vlm. Accessed 2026-04-30
2026
-
[26]
QuickVideo: Real-Time Long Video Understanding with System Algorithm Co-Design
Benjamin Schneider, Dongfu Jiang, Chao Du, Tianyu Pang, and Wenhu Chen. QuickVideo: Real-Time Long Video Understanding with System Algorithm Co-Design . Transactions on Ma- chine Learning Research, 2026; arXiv:2505.16175; OpenReview: https://openreview.net/ forum?id=Rpcxgzcsuc
-
[27]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-VL Technical Report. a...
work page internal anchor Pith review arXiv 2025
-
[28]
Shangzhe Di, Zhelun Yu, Guanghao Zhang, Haoyuan Li, Tao Zhong, Hao Cheng, Bolin Li, Wanggui He, Fangxun Shu, and Hao Jiang. Streaming Video Question-Answering with In- context Video KV-Cache Retrieval . ICLR 2025; arXiv:2503.00540
-
[29]
Martin C. Rinard. Approximate Computing . CSAIL research overview. https://people. csail.mit.edu/rinard/research/ApproximateComputing/. Accessed 2026-04-29
2026
-
[30]
SGLang: Efficient Execution of Structured Language Model Programs
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. SGLang: Efficient Execution of Structured Language Model Programs . NeurIPS 2024; arXiv:2312.07104
work page internal anchor Pith review arXiv 2024
-
[31]
Sparsevlm: Vi- sual token sparsification for efficient vision-language model inference
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis A. Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, and Shanghang Zhang. Sparse- VLM: Visual Token Sparsification for Efficient Vision-Language Model Inference . In Proceed- ings of the 42nd International Conference on Machine Learning (ICML) , PMLR 267:74840– 74857, 2025...
-
[32]
Pla- taniotis, Yao Lu, Song Han, and Zhijian Liu
Samir Khaki, Junxian Guo, Jiaming Tang, Shang Yang, Yukang Chen, Konstantinos N. Pla- taniotis, Yao Lu, Song Han, and Zhijian Liu. SparseVILA: Decoupling Visual Sparsity for Efficient VLM Inference . ICCV 2025, pages 23784–23794; arXiv:2510.17777
-
[33]
A Simple Baseline for Streaming Video Understanding
Yujiao Shen, Shulin Tian, Jingkang Yang, and Ziwei Liu. A Simple Baseline for Streaming Video Understanding. arXiv:2604.02317, 2026
-
[34]
Multi-Granular Spatio-Temporal Token Merging for Training-Free Acceleration of Video LLMs
Jeongseok Hyun, Sukjun Hwang, Su Ho Han, Taeoh Kim, Inwoong Lee, Dongyoon Wee, Joon-Young Lee, Seon Joo Kim, and Minho Shim. Multi-Granular Spatio-Temporal Token Merging for Training-Free Acceleration of Video LLMs . ICCV 2025, pages 23990–24000; arXiv:2507.07990
-
[35]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient Streaming Language Models with Attention Sinks . ICLR 2024; arXiv:2309.17453
work page internal anchor Pith review arXiv 2024
-
[36]
arXiv preprint arXiv:2510.09608 , year=
Ruyi Xu, Guangxuan Xiao, Yukang Chen, Liuning He, Kelly Peng, Yao Lu, and Song Han. StreamingVLM: Real-Time Understanding for Infinite Video Streams . arXiv:2510.09608, 2025
-
[37]
Tomato: Assessing visual temporal reasoning capabilities in multimodal foundation models,
Ziyao Shangguan, Chuhan Li, Yuxuan Ding, Yanan Zheng, Yilun Zhao, Tesca Fitzgerald, and Arman Cohan. TOMATO: Assessing Visual Temporal Reasoning Capabilities in Multimodal Foundation Models. ICLR 2025 poster; arXiv:2410.23266. https://openreview.net/forum? id=fCi4o83Mfs
-
[38]
Token Merging: Your ViT But Faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token Merging: Your ViT But Faster . ICLR 2023; arXiv:2210.09461
work page internal anchor Pith review arXiv 2023
-
[39]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Caifeng Shan, Ran He, and Xing Sun. Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis. CVP...
work page internal anchor Pith review arXiv 2025
-
[40]
VisionZip: Longer is Better but Not Necessary in Vision Language Models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. VisionZip: Longer is Better but Not Necessary in Vision Language Models . CVPR 35 2025, pages 19792–19802; arXiv:2412.04467. https://openaccess.thecvf.com/content/ CVPR2025/html/Yang_VisionZip_Longer_is_Better_but_Not_Necessary_in_Vision_ Language_CVPR_2025_paper.html
-
[41]
VLCache: Computing 2% Vision Tokens and Reusing 98% for Vision-Language Inference
Shengling Qin, Hao Yu, Chenxin Wu, Zheng Li, Yizhong Cao, Zhengyang Zhuge, Yuxin Zhou, Wentao Yao, Yi Zhang, Zhengheng Wang, Shuai Bai, Jianwei Zhang, and Junyang Lin. VLCache: Computing 2% Vision Tokens and Reusing 98% for Vision-Language Inference . arXiv:2512.12977, 2025
-
[42]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient Memory Management for Large Language Model Serving with PagedAttention . SOSP 2023; arXiv:2309.06180
work page internal anchor Pith review arXiv 2023
-
[43]
VScan: Rethinking Visual Token Reduction for Efficient Large Vision- Language Models
Ce Zhang, Kaixin Ma, Tianqing Fang, Wenhao Yu, Hongming Zhang, Zhisong Zhang, Haitao Mi, and Dong Yu. VScan: Rethinking Visual Token Reduction for Efficient Large Vision- Language Models. Transactions on Machine Learning Research, 2026; arXiv:2505.22654; Open- Review: https://openreview.net/forum?id=KZYhyilFnt. A Source Traceability and Provenance The publi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.