Recognition: unknown
Can Multimodal Large Language Models Understand Pathologic Movements? A Pilot Study on Seizure Semiology
Pith reviewed 2026-05-08 01:20 UTC · model grok-4.3
The pith
Multimodal large language models recognize most seizure movement features in video without any special training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
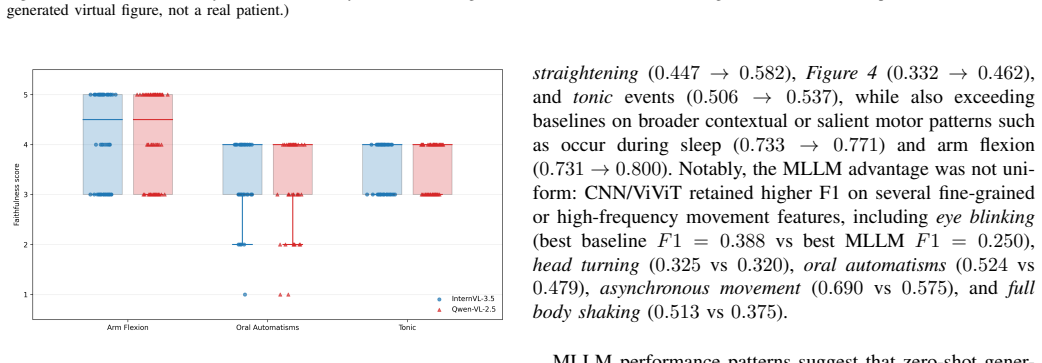
State-of-the-art multimodal large language models achieve higher accuracy than fine-tuned CNN and ViT baselines on 13 of 18 ILAE-defined semiological features in zero-shot evaluation across 90 clinical seizure videos. Feature-targeted preprocessing steps improve results on 10 of 20 features, and expert raters find 94.3 percent of the models' explanations for correct predictions at least 60 percent faithful to epileptologist reasoning.
What carries the argument
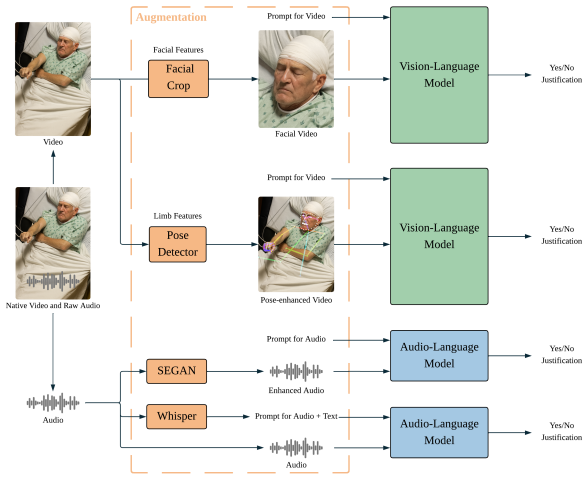
Zero-shot MLLM evaluation on ILAE semiological features in seizure videos, combined with feature-targeted signal enhancement such as facial cropping, pose estimation, and audio denoising.
If this is right
- General-purpose MLLMs offer a route to interpretable diagnostic assistance in epilepsy video monitoring.
- Targeted preprocessing can adapt off-the-shelf models to clinical video tasks without full retraining.
- AI explanations that align with expert reasoning could support review of long EEG-video recordings.
- The same pipeline may reduce the data requirements for applying AI to other movement-based neurological assessments.
Where Pith is reading between the lines
- Performance may improve further if the models are tested on videos from multiple hospitals and seizure types.
- Pairing MLLM outputs with simultaneous EEG signals could create stronger combined diagnostic tools.
- The zero-shot strength suggests the method could be tried on other involuntary movement disorders such as tics or dystonia.
- Real-time versions might eventually assist in emergency or home-monitoring settings where quick feature identification matters.
Load-bearing premise
The 90 seizure videos capture enough real-world variation in how seizures look and that the medical features can be spotted consistently by both models and experts.
What would settle it
A larger multi-center collection of seizure videos where the same MLLMs fall below the fine-tuned CNN and ViT baselines on most of the 18 features.
Figures
read the original abstract
Multimodal Large Language Models (MLLMs) have demonstrated robust capabilities in recognizing everyday human activities, yet their potential for analyzing clinically significant involuntary movements in neurological disorders remains largely unexplored. This pilot study evaluates the capability of MLLMs for automated recognition of pathological movements in seizure videos. We assessed the zero-shot performance of state-of-the-art MLLMs on 20 ILAE-defined semiological features across 90 clinical seizure recordings. MLLMs outperformed fine-tuned Convolutional Neural Network (CNN) and Vision Transformer (ViT) baseline models on 13 of 18 features without task-specific training, demonstrating particular strength in recognizing salient postural and contextual features while struggling with subtle, high-frequency movements. Feature-targeted signal enhancement (facial cropping, pose estimation, audio denoising) improved performance on 10 of 20 features. Expert evaluation showed that 94.3 percent of MLLM-generated explanations for correctly predicted cases achieved at least 60 percent faithfulness scores, aligning with epileptologist reasoning. These findings demonstrate the potential of adapting general-purpose MLLMs for specialized clinical video analysis through targeted preprocessing strategies, offering a path toward interpretable, efficient diagnostic assistance. Our code is publicly available at https://github.com/LinaZhangUCLA/PathMotionMLLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a pilot study evaluating the zero-shot performance of multimodal large language models (MLLMs) on recognizing 20 ILAE-defined semiological features from 90 clinical seizure videos. It reports that MLLMs outperform fine-tuned CNN and ViT baselines on 13 of 18 features, that feature-targeted signal enhancements (facial cropping, pose estimation, audio denoising) improve results on 10 of 20 features, and that expert review found 94.3% of MLLM explanations for correct predictions to be at least 60% faithful to epileptologist reasoning. Code is released publicly.
Significance. If the empirical claims hold after addressing dataset and statistical gaps, the work indicates that general-purpose MLLMs can be adapted via lightweight preprocessing for clinical video analysis of pathological movements, providing an interpretable alternative to task-specific models in epilepsy semiology. The public code release supports reproducibility.
major comments (3)
- [Methods and Results] Methods/Results: No per-feature positive example counts, patient demographics, seizure-type distribution, or cross-validation scheme are reported despite the small n=90. This is load-bearing for the headline claim of MLLM superiority on 13/18 features, as low-prevalence features could produce chance-level differences or reflect under-trained baselines rather than genuine capability.
- [Results] Results: The manuscript provides no statistical testing (e.g., paired tests, confidence intervals, or p-values) for the reported performance differences between MLLMs and baselines or for the signal-enhancement gains. With a pilot-scale dataset this omission prevents assessing whether observed advantages are reliable.
- [Abstract and Results] Abstract and Results: The comparison is stated as 13 of 18 features while enhancement results use 20 features; the manuscript must clarify the exact feature set, which features were excluded from the baseline comparison, and why.
minor comments (3)
- [Methods] Provide the exact protocol and inter-rater details for the expert faithfulness scoring of explanations.
- [Methods] Clarify whether the 90 videos include multiple seizures per patient and any steps taken to avoid data leakage.
- [Supplementary Material] Add per-feature prevalence or confusion matrices to the supplementary material to allow readers to interpret the reported accuracies.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our pilot study. We address each major comment below and will revise the manuscript to incorporate additional details, statistical analyses, and clarifications while preserving the integrity of the reported findings.
read point-by-point responses
-
Referee: [Methods and Results] Methods/Results: No per-feature positive example counts, patient demographics, seizure-type distribution, or cross-validation scheme are reported despite the small n=90. This is load-bearing for the headline claim of MLLM superiority on 13/18 features, as low-prevalence features could produce chance-level differences or reflect under-trained baselines rather than genuine capability.
Authors: We agree these details are essential for proper interpretation given the pilot scale. The revised manuscript will add a supplementary table reporting per-feature positive example counts, patient demographics (age, sex, epilepsy syndrome), and seizure-type distribution across the 90 videos. For the cross-validation scheme, we employed a single fixed 70/30 train/test split for the fine-tuned CNN and ViT baselines to ensure no data leakage and a direct comparison to zero-shot MLLMs; we will state this explicitly in Methods and discuss the small-sample limitation. We note that baselines were trained with standard augmentations and hyperparameters, but the added counts will allow readers to evaluate prevalence effects. revision: yes
-
Referee: [Results] Results: The manuscript provides no statistical testing (e.g., paired tests, confidence intervals, or p-values) for the reported performance differences between MLLMs and baselines or for the signal-enhancement gains. With a pilot-scale dataset this omission prevents assessing whether observed advantages are reliable.
Authors: We acknowledge the lack of statistical testing. In revision we will report 95% bootstrap confidence intervals for all accuracy and F1 scores, as well as for the MLLM-baseline differences and enhancement gains. We will apply McNemar's test for paired binary predictions on each feature (with Bonferroni correction) and paired t-tests or Wilcoxon tests for enhancement improvements. These will be added to Results and a new statistical methods subsection; we recognize that power will be limited for low-prevalence features but believe the tests will still aid assessment of reliability. revision: yes
-
Referee: [Abstract and Results] Abstract and Results: The comparison is stated as 13 of 18 features while enhancement results use 20 features; the manuscript must clarify the exact feature set, which features were excluded from the baseline comparison, and why.
Authors: We will revise the abstract, Methods, and Results to state that all 20 ILAE-defined features were evaluated for MLLMs and signal enhancements. Two features (automatisms and eye deviation) had fewer than five positive examples and were therefore excluded from baseline training and the 13/18 comparison to avoid unreliable models due to extreme imbalance; we will list the full 20-feature set, mark the two excluded features, and explain the exclusion criterion in a dedicated paragraph. revision: yes
Circularity Check
No circularity: purely empirical evaluation with no derivations or self-referential predictions
full rationale
The paper conducts a pilot empirical study evaluating zero-shot MLLM performance on 20 ILAE semiological features from 90 seizure videos, comparing against fine-tuned CNN and ViT baselines, with optional preprocessing and expert faithfulness checks. No mathematical derivations, equations, parameter fitting to subsets, or predictions that reduce to inputs by construction are present. Claims rest on direct accuracy measurements and human ratings against external video data and ILAE definitions, not on any self-definitional loop or self-citation chain. The evaluation is self-contained and falsifiable via the public code and dataset.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Video-based data-driven models for diagnosing movement disorders: Review and future directions,
R. Mart ´ınez-Garc´ıa-Pe˜na, L. H. Koens, G. Azzopardi, and M. A. J. Tijssen, “Video-based data-driven models for diagnosing movement disorders: Review and future directions,”Movement Disorders, vol. 40, no. 10, pp. 2046–2066, 2025
2046
-
[2]
Mini-asterixis in hepatic encephalopa- thy induced by pathologic thalamo-motor-cortical coupling,
L. Timmermann, J. Grosset al., “Mini-asterixis in hepatic encephalopa- thy induced by pathologic thalamo-motor-cortical coupling,”Neurology, pp. 295–298, 2002
2002
-
[3]
Limb myokymia with involuntary finger movement caused by peripheral neuropathy due to systemic lupus erythematosus: a case report,
T. Uchihara and H. Tsukagoshi, “Limb myokymia with involuntary finger movement caused by peripheral neuropathy due to systemic lupus erythematosus: a case report,”Clinical Neurology and Neurosurgery, pp. 321–324, 1994
1994
-
[4]
The spectrum of involuntary vocalizations in humans: A video atlas,
T. Mainka, T. B ¨uttneret al., “The spectrum of involuntary vocalizations in humans: A video atlas,”Movement Disorders, pp. 1036–1045, 2019
2019
-
[5]
Ex- plainability for artificial intelligence in healthcare: a multidisciplinary perspective,
J. Amann, A. Blasimme, E. Vayena, D. Frey, and V . I. Madai, “Ex- plainability for artificial intelligence in healthcare: a multidisciplinary perspective,”BMC Medical Informatics and Decision Making, vol. 20, no. 1, p. 310, 2020
2020
-
[6]
Automatic segmentation of episodes containing epileptic clonic seizures in video sequences,
S. Kalitzin, G. Petkov, D. Velis, B. Vledder, and F. Lopes da Silva, “Automatic segmentation of episodes containing epileptic clonic seizures in video sequences,”IEEE Transactions on Biomedical Engineering, vol. 59, no. 12, pp. 3379–3385, 2012
2012
-
[7]
A guide to deep learning in healthcare,
A. Esteva, A. Robicquet, B. Ramsundar, V . Kuleshov, M. DePristo, K. Chou, C. Cui, G. S. Corrado, S. Thrun, and J. Dean, “A guide to deep learning in healthcare,”Nature Medicine, vol. 27, no. 2, pp. 166–176, 2021
2021
-
[8]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” inProceedings of the International Conference on Machine Learning (ICML), 2021
2021
-
[9]
Robust speech recognition via large-scale weak supervi- sion,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervi- sion,” inProceedings of the 40th International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol. 202, 2023, pp. 28 492–28 518
2023
-
[10]
Flamingo: a Visual Language Model for Few-Shot Learning
J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y . Hasson, K. Lenc et al., “Flamingo: a visual language model for few-shot learning,”arXiv preprint arXiv:2204.14198, 2022
work page internal anchor Pith review arXiv 2022
-
[11]
J. Li, D. Li, S. Savarese, and S. C. H. Hoi, “Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,”arXiv preprint arXiv:2301.12597, 2023
work page internal anchor Pith review arXiv 2023
-
[12]
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,”arXiv preprint arXiv:2304.08485, 2023
work page internal anchor Pith review arXiv 2023
-
[13]
Operational classification of seizure types by the international league against epilepsy: Position paper of the ilae commission for classification and terminology,
R. S. Fisher, J. H. Cross, C. D’Souza, J. A. French, S. R. Haut, N. Higurashi, E. Hirsch, F. E. Jansen, L. Lagae, S. L. Mosh ´eet al., “Operational classification of seizure types by the international league against epilepsy: Position paper of the ilae commission for classification and terminology,”Epilepsia, vol. 58, no. 4, pp. 522–530, 2017
2017
-
[14]
Slowfast networks for video recognition,
C. Feichtenhofer, H. Fan, J. Malik, and K. He, “Slowfast networks for video recognition,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019
2019
-
[15]
Videomae: Masked autoen- coders are data-efficient learners for self-supervised video pre-training,
Z. Tong, Y . Song, J. Wang, and L. Wang, “Videomae: Masked autoen- coders are data-efficient learners for self-supervised video pre-training,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[16]
Videoclip: Contrastive pre- training for zero-shot video-text understanding,
H. Xu, G. Ghosh, P.-Y . Huang, D. Okhonko, A. Aghajanyan, F. Metze, L. Zettlemoyer, and C. Feichtenhofer, “Videoclip: Contrastive pre- training for zero-shot video-text understanding,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2021, pp. 6787–6800
2021
-
[17]
Medvit: a robust vision transformer for generalized medical image classification,
O. N. Manzari, H. Ahmadabadi, H. Kashiani, S. B. Shokouhi, and A. Ayatollahi, “Medvit: a robust vision transformer for generalized medical image classification,”Computers in Biology and Medicine, vol. 157, p. 106791, 2023
2023
-
[18]
Video-based detection of tonic- clonic seizures using a three-dimensional convolutional neural network,
A. Boyne, H. J. Yeh, A. K. Allam, B. M. Brown, M. Tabaeizadeh, J. M. Stern, R. J. Cotton, and Z. Haneef, “Video-based detection of tonic- clonic seizures using a three-dimensional convolutional neural network,” Epilepsia, vol. 66, no. 7, pp. 2495–2506, 2025
2025
-
[19]
Convulsive seizure detection using a wrist-worn electrodermal activity and accelerometry biosensor,
M.-Z. Poh, T. Loddenkemper, C. Reinsberger, N. C. Swenson, S. Goyal, M. C. Sabtala, J. R. Madsen, and R. W. Picard, “Convulsive seizure detection using a wrist-worn electrodermal activity and accelerometry biosensor,”Epilepsia, vol. 53, no. 5, pp. e93–e97, 2012
2012
-
[20]
J. Achiam, S. Adler, S. Agarwalet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review arXiv 2023
-
[21]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Google, “Gemini: A family of highly capable multimodal models,”arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review arXiv 2023
-
[22]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
W. Wang, Z. Gaoet al., “Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency,” arXiv:2508.18265, 2025
work page internal anchor Pith review arXiv 2025
-
[23]
S. Bai, K. Chenet al., “Qwen2.5-vl technical report,”arXiv:2502.13923, 2025
work page internal anchor Pith review arXiv 2025
-
[24]
Motionbench: Benchmarking and improving fine-grained video motion understanding for vision language models,
W. Hong, Y . Cheng, Z. Yang, W. Wang, L. Wang, X. Gu, S. Huang, Y . Dong, and J. Tang, “Motionbench: Benchmarking and improving fine-grained video motion understanding for vision language models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 8450–8460
2025
-
[25]
Gla-ai4biomed at rrg24: Visual instruction-tuned adaptation for radiology report generation,
X. Zhang, Z. Meng, J. Lever, and E. S. L. Ho, “Gla-ai4biomed at rrg24: Visual instruction-tuned adaptation for radiology report generation,” in Proceedings of the BioNLP Workshop and Shared Task (ACL), 2024
2024
-
[26]
Pre-trained multimodal large language model enhances dermatological diagnosis using skingpt-4,
J. Zhou, X. He, L. Sun, J. Xu, X. Chen, Y . Chu, L. Zhou, X. Liao, B. Zhang, S. Afvari, and X. Gao, “Pre-trained multimodal large language model enhances dermatological diagnosis using skingpt-4,”Nature Com- munications, vol. 15, p. 5606, 2024
2024
-
[27]
Med-flamingo: a multimodal medical few-shot learner,
M. Moor, Q. Huang, S. Wu, M. Yasunaga, Y . Dalmia, J. Leskovec, C. Zakka, E. P. Reis, and P. Rajpurkar, “Med-flamingo: a multimodal medical few-shot learner,” inProceedings of Machine Learning Research (PMLR), 3rd Machine Learning for Health Symposium (ML4H), vol. 225, 2023, pp. 353–367
2023
-
[28]
Instruction manual for the ILAE 2017 operational classification of seizure types,
R. S. Fisher, J. H. Crosset al., “Instruction manual for the ILAE 2017 operational classification of seizure types,”Epilepsia, pp. 531– 542, 2017
2017
-
[29]
A closer look at spatiotemporal convolutions for action recognition,
D. Tran, H. Wang, L. Torresani, J. Ray, Y . LeCun, and M. Paluri, “A closer look at spatiotemporal convolutions for action recognition,” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2018, pp. 6450–6459
2018
-
[30]
Vivit: A video vision transformer,
A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Lu ˇci´c, and C. Schmid, “Vivit: A video vision transformer,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 6836–6846
2021
-
[31]
Quo vadis, action recognition? a new model and the kinetics dataset,
J. Carreira and A. Zisserman, “Quo vadis, action recognition? a new model and the kinetics dataset,” inproceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 6299–6308
2017
-
[32]
Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,
A. Goel, S. Ghosh, J. Kim, S. Kumar, Z. Kong, S.-g. Lee, C.-H. H. Yang, R. Duraiswami, D. Manocha, R. Valle, and B. Catanzaro, “Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,”arXiv preprint arXiv:2507.08128, 2025
-
[33]
Realtime multi-person 2d pose estimation using part affinity fields,
Z. Cao, T. Simonet al., “Realtime multi-person 2d pose estimation using part affinity fields,” inCVPR, 2017, pp. 7291–7299
2017
-
[34]
Segan: Speech enhancement generative adversarial network,
S. Pascual, A. Bonafonte, and J. Serr `a, “Segan: Speech enhancement generative adversarial network,” 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.