Recognition: unknown
Tutti: Making SSD-Backed KV Cache Practical for Long-Context LLM Serving
Pith reviewed 2026-05-09 16:14 UTC · model grok-4.3
The pith
A GPU-centric KV cache object store removes CPU from the critical I/O path to make SSD-backed LLM serving match DRAM performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
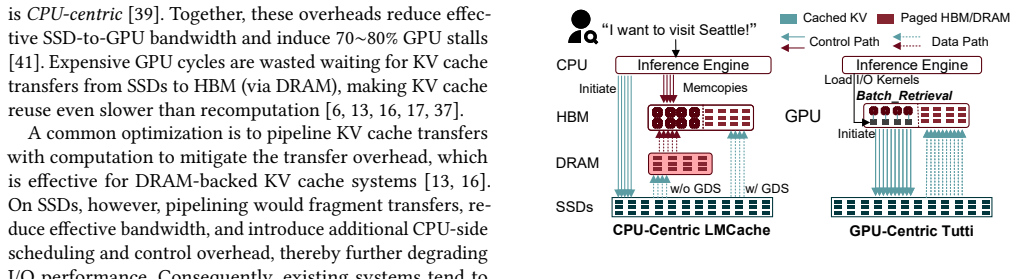
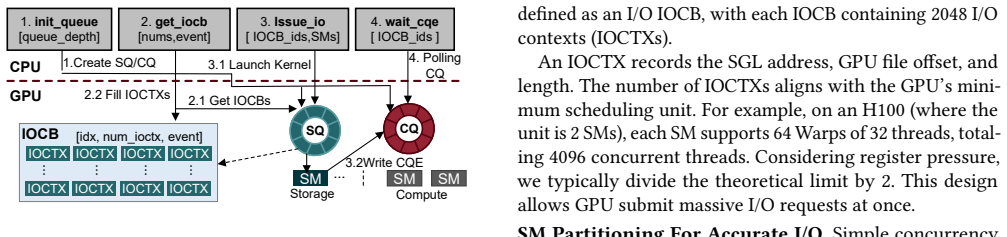
Tutti presents a GPU-centric KV cache object store that eliminates CPU intervention from the critical data and I/O control paths between HBM and SSDs. The CPU asynchronously loads I/O kernels once per layer; all transfers and management use GPU-native objects. The design combines a GPU-native object abstraction for bulk operations, GPU io_uring for asynchronous direct object I/O, and slack-aware I/O scheduling to avoid contention. These changes saturate NVMe SSD bandwidth, reduce GPU stalls to near zero, and achieve nearly the same inference performance as DRAM-backed LMCache while providing almost infinite capacity.
What carries the argument
GPU-centric KV cache object store enabling bulk transfers and GPU-direct asynchronous I/O with CPU limited to one-time kernel loading per layer.
If this is right
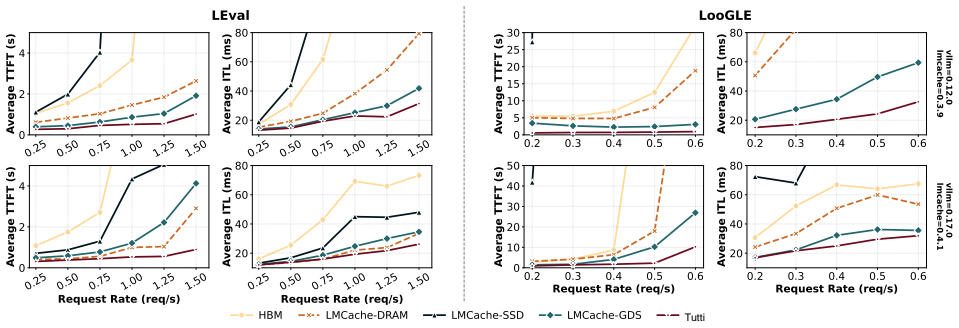
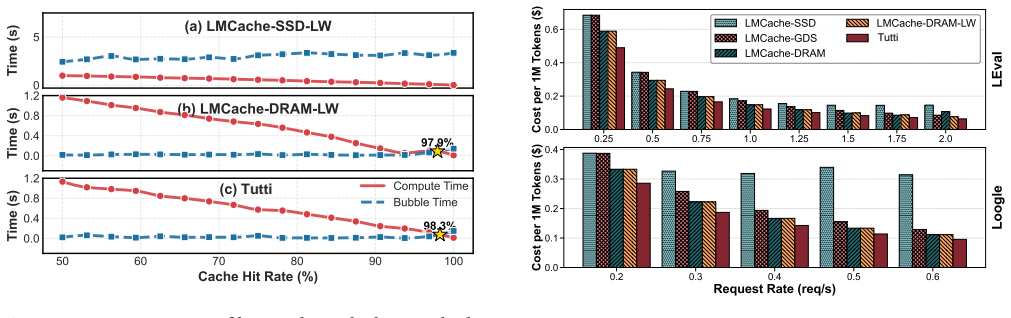
- Time-to-first-token drops by 78.3 percent under strict SLO constraints relative to GDS-enabled SSD caching.
- Achievable request rate increases by a factor of two.
- Serving cost falls by 27 percent while maintaining near-DRAM inference speed.
- KV cache capacity becomes effectively unlimited without proportional hardware cost increases.
Where Pith is reading between the lines
- Deployment of very long contexts (hundreds of thousands of tokens) becomes economically viable on existing GPU clusters without major DRAM upgrades.
- Similar GPU-direct object abstractions could reduce offload penalties for other large data structures such as model weights or activations.
- Production serving stacks that integrate with vLLM could adopt this pattern as a default for cost-sensitive long-context workloads.
Load-bearing premise
The GPU can run the I/O kernels and manage object transfers without introducing new contention or requiring changes to existing GPU scheduling that would offset the gains.
What would settle it
Benchmarks on long-context workloads showing persistent GPU stalls above a few percent or SSD bandwidth utilization below 80 percent when running Tutti versus the GDS baseline.
Figures








read the original abstract
LLM serving relies on prefix caching to improve inference performance. As growing contexts push key-value (KV) cache footprint far beyond GPU HBM and CPU DRAM capacity, KV cache is increasingly offloaded to NVMe SSDs. Unfortunately, restoring KV cache from SSDs suffers from poor I/O performance and incurs significant GPU stalls. This is primarily because the fragmented GPU memory layout results in a massive number of tiny random I/Os, rendering the low-parallelism CPU a severe bottleneck even with GPU Direct Storage (GDS), which still relies on CPU intervention to initiate each I/O and thus remains CPU-centric. This paper presents Tutti, an efficient SSD-backed KV caching solution that eliminates CPU intervention from the critical data and I/O control paths between HBM and SSDs. At the core of Tutti is a GPU-centric KV cache object store, in which the CPU is only responsible for asynchronously loading I/O kernels once per layer to the GPU. Tutti saturates NVMe SSD bandwidth and reduces GPU stalls to near zero through the following designs: (i) we provide a GPU-native object abstraction that enables bulk KV cache transfers and management; (ii) we re-architect the GPU storage stack by introducing GPU io_uring to support asynchronous GPU direct object I/O; and (iii) we propose slack-aware I/O scheduling to avoid GPU resource contention. We have implemented Tutti and integrated it to vLLM. Extensive evaluation shows that compared to the state-of-the-art GDS-enabled, SSD-backed LMCache, Tutti reduces TTFT by 78.3% under strict SLO constraints and improves the achievable request rate by 2x. The serving cost is reduced by 27%. Tutti achieves nearly the same inference performance as DRAM-backed LMCache, while providing almost infinite capacity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Tutti, a GPU-centric SSD-backed KV cache system for long-context LLM serving integrated with vLLM. It replaces CPU-centric I/O (even with GDS) via a GPU-native object store for bulk transfers, GPU io_uring for asynchronous direct object I/O, and slack-aware scheduling to overlap I/O with compute without contention. The central claims are that this saturates NVMe bandwidth, reduces GPU stalls to near zero, and delivers 78.3% lower TTFT under strict SLOs, 2x higher request rate, and 27% lower serving cost versus GDS-enabled LMCache while matching DRAM-backed performance.
Significance. If the empirical results hold under realistic workloads, Tutti would make SSD offloading a practical, near-zero-overhead option for KV cache, enabling cost-effective scaling of context lengths far beyond DRAM limits and reducing reliance on expensive HBM/DRAM. The GPU-centric design and reported near-parity with DRAM represent a notable systems advance for LLM inference infrastructure.
major comments (2)
- [Evaluation and §3.3 (slack-aware scheduler)] The headline performance numbers (78.3% TTFT reduction, 2x request rate, near-zero stalls, full SSD saturation) rest on the untested assumption that slack-aware scheduling plus GPU io_uring kernels can be launched and executed without stealing cycles from inference kernels or requiring CPU intervention on the critical path under realistic batching and layer-wise execution. No independent stress test of slack estimation accuracy, kernel launch overhead, or GPU scheduler serialization is described, which directly undermines the comparison to LMCache.
- [§3 (GPU-centric KV cache object store and GPU io_uring)] The claim that CPU intervention is eliminated from the data and I/O control paths is load-bearing for the entire contribution, yet the design still requires the CPU to asynchronously load I/O kernels once per layer. It is unclear whether this introduces measurable latency or serialization under high request rates; the paper should quantify any residual CPU involvement and its impact on the critical path.
minor comments (2)
- [Abstract and Evaluation] The abstract and evaluation should explicitly state the hardware configuration (GPU model, SSD model, PCIe generation), workload traces, batch sizes, context lengths, and whether error bars or multiple runs are reported for the 78.3% and 2x figures.
- [§3] Notation for the GPU object abstraction and io_uring interface should be introduced with a small diagram or pseudocode to clarify how bulk transfers differ from per-page GDS operations.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below with clarifications drawn from our existing evaluation and design. We agree that additional quantification and discussion will strengthen the paper and will incorporate the requested details in a revised version.
read point-by-point responses
-
Referee: [Evaluation and §3.3 (slack-aware scheduler)] The headline performance numbers (78.3% TTFT reduction, 2x request rate, near-zero stalls, full SSD saturation) rest on the untested assumption that slack-aware scheduling plus GPU io_uring kernels can be launched and executed without stealing cycles from inference kernels or requiring CPU intervention on the critical path under realistic batching and layer-wise execution. No independent stress test of slack estimation accuracy, kernel launch overhead, or GPU scheduler serialization is described, which directly undermines the comparison to LMCache.
Authors: We thank the referee for this observation. Our Section 4 evaluation was performed under realistic dynamic batching with varying context lengths and request rates on the target hardware, directly measuring GPU stall times and SSD bandwidth utilization. Slack is estimated from offline per-layer compute profiling (error <5% in our traces), and I/O is overlapped on separate CUDA streams to avoid contention with inference kernels. Microbenchmarks (not highlighted in the main text) show GPU io_uring submission overhead below 1% of layer time with no measurable serialization under the evaluated loads. We will add these microbenchmark results, slack-accuracy statistics, and a dedicated overhead discussion to §3.3. revision: yes
-
Referee: [§3 (GPU-centric KV cache object store and GPU io_uring)] The claim that CPU intervention is eliminated from the data and I/O control paths is load-bearing for the entire contribution, yet the design still requires the CPU to asynchronously load I/O kernels once per layer. It is unclear whether this introduces measurable latency or serialization under high request rates; the paper should quantify any residual CPU involvement and its impact on the critical path.
Authors: The referee correctly notes the one-time CPU kernel load per layer. This step occurs asynchronously outside the data-transfer and I/O-control critical paths: it is performed via non-blocking CUDA operations at layer initialization and is amortized across the full inference. We measured the CPU-side loading cost at ~0.2 ms per layer, which is negligible relative to inference time and does not serialize requests because I/O proceeds on the GPU via io_uring while the CPU proceeds to the next layer. Our near-zero stall results under high request rates already reflect this residual cost. We will add explicit quantification and critical-path impact analysis to Section 3. revision: yes
Circularity Check
No circularity: empirical systems evaluation against external baselines
full rationale
The paper presents a systems implementation (GPU-centric KV object store, GPU io_uring, slack-aware scheduling) integrated into vLLM, with performance claims derived solely from measurements against an external baseline (GDS-enabled LMCache) and DRAM-backed LMCache. No mathematical derivations, fitted parameters, self-definitional equations, or load-bearing self-citations appear in the provided text or abstract. All reported metrics (TTFT reduction, request rate, stalls, bandwidth) are direct empirical outcomes, not reductions to prior inputs by construction. The design choices are justified by implementation details and evaluation, remaining self-contained without internal circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption NVMe SSDs can deliver high bandwidth under bulk, sequential-like I/O patterns when CPU intervention is removed from the data path.
- domain assumption GPU kernels for I/O can be loaded once per layer and executed asynchronously without interfering with model compute.
Reference graph
Works this paper leans on
-
[1]
Aliyun. 2025. PolarKVCache.https://help.aliyun.com/zh/polardb/pol ardb-for-mysql/user-guide/polarkvcache-inference-acceleration
2025
- [2]
-
[3]
AWS. 2025. Amazon ec2 p4d pricing.https://aws.amazon.com/ec2/ins tance-types/p4/
2025
-
[4]
AWS. 2025. Amazon ec2 pricing.https://aws.amazon.com/ec2/pricing /
2025
-
[5]
Chia-Hao Chang, Jihoon Han, Anand Sivasubramaniam, Vikram Sharma Mailthody, Zaid Qureshi, and Wen-Mei Hwu. 2024. GMT: GPU Orchestrated Memory Tiering for the Big Data Era. InProceed- ings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3. 464–478
2024
-
[6]
Weijian Chen, Shuibing He, Haoyang Qu, Ruidong Zhang, Siling Yang, Ping Chen, Yi Zheng, Baoxing Huai, and Gang Chen. 2025. IMPRESS: An Importance-InformedMulti-Tier Prefix KV Storage System for Large Language Model Inference. In23rd USENIX Conference on File and Storage Technologies (FAST 25). 187–201
2025
-
[7]
Deepseek. 2025. Models and Pricing.https://api-docs.deepseek.com/ quick_start/pricing/
2025
-
[8]
DeepSpeedAI. 2025. DeepNVMe: Affordable I/O scaling for Deep Learning Applications.https://github.com/deepspeedai/DeepSpeed/b lob/master/blogs/deepnvme/06-2025/README.md/
2025
-
[9]
Devansh. 2026. How Weka is Solving AI’s Trillion Dollar Memory Problem.https://www.artificialintelligencemadesimple.com/p/how- one-startup-is-breaking-nvidias?utm_source=publication-search
2026
-
[10]
Diego Didona, Jonas Pfefferle, Nikolas Ioannou, Bernard Metzler, and Animesh Trivedi. 2022. Understanding modern storage APIs: a sys- tematic study of libaio, SPDK, and io_uring. InProceedings of the 15th ACM International Conference on Systems and Storage. 120–127
2022
-
[11]
Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, and Pengfei Zuo. 2024. Attention- store: Cost-effective attention reuse across multi-turn conversations in large language model serving.arXiv preprint arXiv:2403.1970852 (2024), 20–38
-
[12]
Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, and Pengfei Zuo. 2024. Cost- Efficient large language model serving for multi-turn conversations with CachedAttention. In2024 USENIX Annual Technical Conference (USENIX ATC 24). 111–126
2024
-
[13]
Shiwei Gao, Youmin Chen, and Jiwu Shu. 2025. Fast state restoration in llm serving with hcache. InProceedings of the Twentieth European Conference on Computer Systems. 128–143
2025
-
[14]
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, et al. 2024. Chatglm: A family of large language models from glm-130b to glm-4 all tools.arXiv preprint arXiv:2406.12793(2024)
work page internal anchor Pith review arXiv 2024
-
[15]
Yang Hu, Hong Jiang, Dan Feng, Hao Luo, and Lei Tian. 2015. PASS: A proactive and adaptive SSD buffer scheme for data-intensive workloads. In2015 IEEE International Conference on Networking, Architecture and Storage (NAS). IEEE, 54–63
2015
-
[16]
Jinwoo Jeong and Jeongseob Ahn. 2025. Accelerating LLM Serving for Multi-turn Dialogues with Efficient Resource Management. In Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 1–15
2025
-
[17]
Chaoyi Jiang, Lei Gao, Hossein Entezari Zarch, and Murali Annavaram
- [18]
-
[19]
KIOXIA. 2025. KIOXIA CM7-V Series Enterprise NVMe™Mixed Use SSD.https://apac.kioxia.com/en-apac/business/ssd/enterprise- ssd/cm7-v.html
2025
-
[20]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[21]
InProceedings of the 29th symposium on operating systems principles
Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles. 611–626
-
[22]
Gonzalez, Hao Zhang, and Ion Sto- ica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Sto- ica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles
2023
-
[23]
Hyungwoo Lee, Kihyun Kim, Jinwoo Kim, Jungmin So, Myung-Hoon Cha, Hong-Yeon Kim, James J Kim, and Youngjae Kim. 2025. Disk- Based Shared KV Cache Management for Fast Inference in Multi- Instance LLM RAG Systems. In2025 IEEE 18th International Conference on Cloud Computing (CLOUD). IEEE, 199–209
2025
- [24]
-
[25]
Shaobo Li, Yirui Eric Zhou, Yuqi Xue, Yuan Xu, and Jian Huang. 2025. Managing Scalable Direct Storage Accesses for GPUs with GoFS. In Proceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles. 979–995
2025
- [26]
-
[27]
Renping Liu, Zhenhua Tan, Linbo Long, Yu Wu, Yujuan Tan, and Duo Liu. 2022. Improving fairness for SSD devices through DRAM over- provisioning cache management.IEEE Transactions on Parallel and Distributed Systems33, 10 (2022), 2444–2454
2022
-
[28]
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Anantha- narayanan, et al. 2024. Cachegen: Kv cache compression and streaming for fast large language model serving. InProceedings of the ACM SIG- COMM 2024 Conference. 38–56. 13
2024
-
[29]
Vikram Sharma Mailthody. 2025. Advancing Memory and Storage Architectures for Next-Gen AI Workloads.Flash Memory Summit (2025), 1–27
2025
-
[30]
Jonas Markussen, Lars Bjørlykke Kristiansen, Pål Halvorsen, Halvor Kielland-Gyrud, Håkon Kvale Stensland, and Carsten Griwodz. 2021. Smartio: Zero-overhead device sharing through pcie networking.ACM Transactions on Computer Systems (TOCS)38, 1-2 (2021), 1–78
2021
-
[31]
Meta. 2025. The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation.https://ai.meta.com/blog/llama-4-multim odal-intelligence/
2025
-
[32]
Meta AI. 2024. Meta-Llama-3-8B-Instruct.https://huggingface.co/met a-llama/Meta-Llama-3-8B-Instruct. Accessed: 2025-12-10
2024
-
[33]
Daye Nam, Andrew Macvean, Vincent Hellendoorn, Bogdan Vasilescu, and Brad Myers. 2024. Using an llm to help with code understanding. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–13
2024
-
[34]
NIVDIA. 2025. TensorRT LLM’s Documentation.https://nvidia.githu b.io/TensorRT-LLM/
2025
-
[35]
Nvidia. 2024. NVIDIA GPUDirect Storage.https://docs.nvidia.com/gp udirect-storage/index.html
2024
-
[36]
NVIDIA. 2025. Cuda-programming-guide Green Contexts.https: //docs.nvidia.com/cuda/cuda- programming- guide/04- special- topics/green-contexts.html/
2025
-
[37]
Doug O’Laughlin. 2026. Another Conversation with Val Bercovici Memory Markets.https://www.fabricatedknowledge.com/p/another- conversation-with-val-bercovici
2026
-
[38]
OpenAI. 2025. API Pricing.https://openai.com/api/pricing/
2025
-
[39]
Xiurui Pan, Endian Li, Qiao Li, Shengwen Liang, Yizhou Shan, Ke Zhou, Yingwei Luo, Xiaolin Wang, and Jie Zhang. 2025. InstAttention: In-Storage Attention Offloading for Cost-Effective Long-Context LLM Inference. In2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 1510–1525
2025
- [40]
-
[41]
Shi Qiu, Weinan Liu, Yifan Hu, Jianqin Yan, Zhirong Shen, Xin Yao, Renhai Chen, Gong Zhang, and Yiming Zhang. 2025. GeminiFS: A Companion File System for GPUs. In23rd USENIX Conference on File and Storage Technologies (FAST 25). 221–236
2025
-
[42]
Zaid Qureshi, Vikram Sharma Mailthody, Isaac Gelado, Seungwon Min, Amna Masood, Jeongmin Park, Jinjun Xiong, Chris J Newburn, Dmitri Vainbrand, I-Hsin Chung, et al. 2023. GPU-initiated on-demand high-throughput storage access in the BaM system architecture. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming La...
2023
-
[43]
Zebin Ren, Krijn Doekemeijer, Tiziano De Matteis, Christian Pinto, Radu Stoica, and Animesh Trivedi. 2025. An I/O Characterizing Study of Offloading LLM Models and KV Caches to NVMe SSD. InProceedings of the 5th Workshop on Challenges and Opportunities of Efficient and Performant Storage Systems. 23–33
2025
-
[44]
SGLang. 2024. SGLang.https://github.com/sgl-project/sglang?tab=r eadme-ov-file
2024
- [45]
-
[46]
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang
-
[47]
InInternational Conference on Machine Learning
Flexgen: High-throughput generative inference of large language models with a single gpu. InInternational Conference on Machine Learning. PMLR, 31094–31116
-
[48]
solidigm. 2024. Solidigm D7-PS1010.https://www.solidigm.com/pro ducts/data-center/d7/ps1010.html
2024
-
[49]
Solidigm. 2025. Solidigm D7-PS1010.https://www.solidigm.com/pro ducts/data-center/d7/ps1010.html#configurator
2025
-
[50]
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. 2024. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530 (2024)
work page internal anchor Pith review arXiv 2024
-
[51]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. At- tention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[52]
NVM Express Workgroup. 2022. NVM Express Base Specification Revision 2.0c.https://nvmexpress.org/wp-content/uploads/NVM- Express-Base-Specification-2.0c-2022.10.04-Ratified.pdf
2022
-
[53]
Zhiqiang Xie, Ziyi Xu, Mark Zhao, Yuwei An, Vikram Sharma Mailthody, Scott Mahlke, Michael Garland, and Christos Kozyrakis
- [54]
-
[55]
Xie, Zhiqiang. 2025. SGLang HiCache: Fast Hierarchical KV Caching with Your Favorite Storage Backends.https://lmsys.org/blog/2025-09- 10-sglang-hicache/
2025
-
[56]
Jianqin Yan, Shi Qiu, Yina Lv, Yifan Hu, Hao Chen, Zhirong Shen, Xin Yao, Renhai Chen, Jiwu Shu, Gong Zhang, et al . 2025. Phoenix: A Refactored I/O Stack for GPU Direct Storage without Phony Buffers. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 1267–1283
2025
-
[57]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
-
[58]
Qwen3 Technical Report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. 2025. CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowl- edge Fusion. InProceedings of the Twentieth European Conference on Computer Systems(Rotterdam, Netherlands)(EuroSys ’25). As- sociation for Computing Machinery, Ne...
- [60]
- [61]
-
[62]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Livia Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. 2024. Sglang: Efficient execution of structured language model programs.Advances in neural information processing systems37 (2024), 62557–62583. 14
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.