Recognition: unknown
GRPO-TTA: Test-Time Visual Tuning for Vision-Language Models via GRPO-Driven Reinforcement Learning
Pith reviewed 2026-05-07 17:59 UTC · model grok-4.3
The pith
GRPO-TTA applies GRPO to test-time visual tuning of vision-language models via group-wise policy optimization on unlabeled class candidates, outperforming prior TTA methods especially under natural distribution shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GRPO-TTA consistently outperforms existing test-time adaptation methods, with notably larger performance gains under natural distribution shifts.
Load-bearing premise
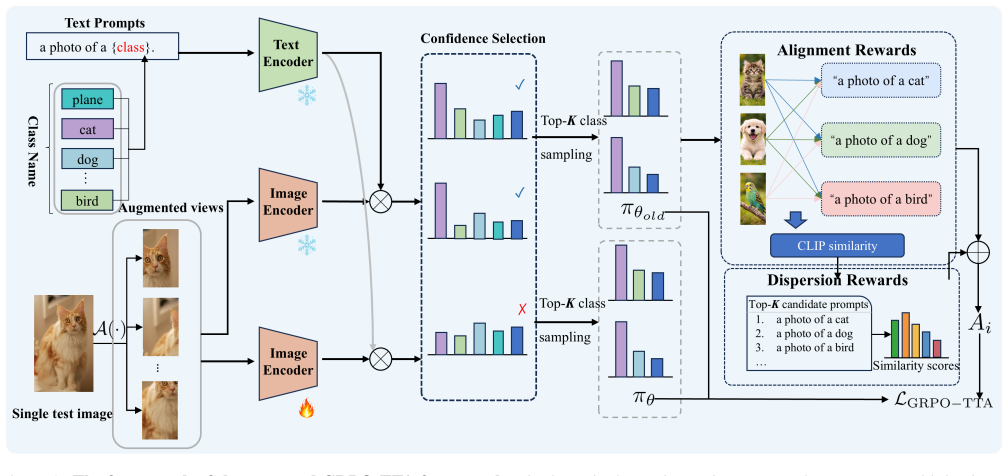
That constructing output groups by sampling top-K class candidates from CLIP similarity distributions enables effective probability-driven optimization without ground-truth labels, and that the designed alignment and dispersion rewards guide effective visual encoder tuning at test time.
Figures

read the original abstract
Group Relative Policy Optimization (GRPO) has recently shown strong performance in post-training large language models and vision-language models. It raises a question of whether the GRPO also significantly promotes the test-time adaptation (TTA) of vision language models. In this paper, we propose Group Relative Policy Optimization for Test-Time Adaptation (GRPO-TTA), which adapts GRPO to the TTA setting by reformulating class-specific prompt prediction as a group-wise policy optimization problem. Specifically, we construct output groups by sampling top-K class candidates from CLIP similarity distributions, enabling probability-driven optimization without access to ground-truth labels. Moreover, we design reward functions tailored to test-time adaptation, including alignment rewards and dispersion rewards, to guide effective visual encoder tuning. Extensive experiments across diverse benchmarks demonstrate that GRPO-TTA consistently outperforms existing test-time adaptation methods, with notably larger performance gains under natural distribution shifts.
Editorial analysis
A structured set of objections, weighed in public.
Axiom & Free-Parameter Ledger
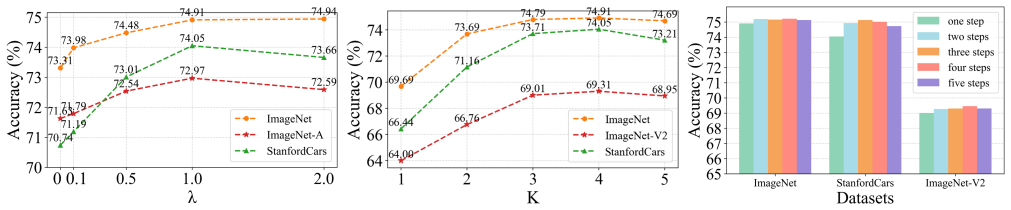
free parameters (2)
- K (number of top class candidates)
- Reward weighting coefficients
axioms (2)
- domain assumption CLIP similarity distributions provide useful probability signals for constructing class candidate groups without labels.
- domain assumption Group-wise relative policy optimization can be directly applied to visual encoder tuning in the test-time setting.
Reference graph
Works this paper leans on
-
[1]
Food-101–mining discriminative com- ponents with random forests
[Bossardet al., 2014 ] Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101–mining discriminative com- ponents with random forests. InEuropean conference on computer vision, pages 446–461. Springer, 2014. [Chenet al., 2025 ] Haoxian Chen, Hanyang Zhao, Henry
2014
-
[1]
Food-101–mining discriminative com- ponents with random forests
[Bossardet al., 2014 ] Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101–mining discriminative com- ponents with random forests. InEuropean conference on computer vision, pages 446–461. Springer,
2014
-
[2]
Mallowspo: Fine- tune your llm with preference dispersions
[Chenet al., 2025 ] Haoxian Chen, Hanyang Zhao, Henry Lam, David D Yao, and Wenpin Tang. Mallowspo: Fine- tune your llm with preference dispersions. InICLR,
2025
-
[3]
Describing textures in the wild
[Cimpoiet al., 2014 ] Mircea Cimpoi, Subhransu Maji, Ia- sonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 3606–3613,
2014
-
[4]
The many faces of robustness: A critical anal- ysis of out-of-distribution generalization
Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, et al. The many faces of robustness: A critical anal- ysis of out-of-distribution generalization. InProceedings of the IEEE/CVF international conference on computer vi- sion, pages 8340–8349, 2021. [Hendryckset al., 2021b ] Dan Hendrycks, Kevin Zhao, Steven Basart, Jacob Steinhardt, and Dawn Song...
2021
-
[4]
Imagenet: A large-scale hierarchical image database
[Denget al., 2009 ] Jia Deng, Wei Dong, Richard Socher, Li- Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee,
2009
-
[5]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
[Dosovitskiy, 2020] Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review arXiv 2020
-
[6]
Learning generative visual models from few train- ing examples: An incremental bayesian approach tested on 101 object categories
[Fei-Feiet al., 2004 ] Li Fei-Fei, Rob Fergus, and Pietro Per- ona. Learning generative visual models from few train- ing examples: An incremental bayesian approach tested on 101 object categories. In2004 conference on computer vision and pattern recognition workshop, pages 178–178. IEEE,
2004
-
[7]
Diverse data augmen- tation with diffusions for effective test-time prompt tuning
[Fenget al., 2023 ] Chun-Mei Feng, Kai Yu, Yong Liu, Salman Khan, and Wangmeng Zuo. Diverse data augmen- tation with diffusions for effective test-time prompt tuning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2704–2714,
2023
-
[8]
Learning transferable visual models from nat- ural language supervision
Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from nat- ural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. [Rafailovet al., 2023 ] Rafael Rafailov, Archit Sharma, Eric
2021
-
[8]
Clip-adapter: Better vision-language models with feature adapters.International Journal of Computer Vision, 132(2):581–595,
[Gaoet al., 2024 ] Peng Gao, Shijie Geng, Renrui Zhang, Teli Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li, and Yu Qiao. Clip-adapter: Better vision-language models with feature adapters.International Journal of Computer Vision, 132(2):581–595,
2024
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
[Guoet al., 2025 ] Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shi- rong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review arXiv 2025
-
[10]
Dota: Distributional test-time adaptation of vision-language models.arXiv preprint arXiv:2409.19375,
[Hanet al., 2024 ] Zongbo Han, Jialong Yang, Guangyu Wang, Junfan Li, Qianli Xu, Mike Zheng Shou, and Changqing Zhang. Dota: Distributional test-time adaptation of vision-language models.arXiv preprint arXiv:2409.19375,
-
[11]
Deep residual learning for image recog- nition
[Heet al., 2016 ] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recog- nition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778,
2016
-
[12]
[Helberet al., 2019 ] Patrick Helber, Benjamin Bischke, An- dreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE Journal of Selected Top- ics in Applied Earth Observations and Remote Sensing, 12(7):2217–2226,
2019
-
[13]
Clipscore: A reference-free evaluation metric for image captioning
[Hesselet al., 2021 ] Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning. In Proceedings of the 2021 conference on empirical methods in natural language processing, pages 7514–7528,
2021
-
[14]
On the robustness of reward models for lan- guage model alignment.arXiv preprint arXiv:2505.07271,
[Honget al., 2025 ] Jiwoo Hong, Noah Lee, Eunki Kim, Gui- jin Son, Woojin Chung, Aman Gupta, Shao Tang, and James Thorne. On the robustness of reward models for lan- guage model alignment.arXiv preprint arXiv:2505.07271,
-
[15]
Enhance vision-language alignment with noise
[Huanget al., 2025 ] Sida Huang, Hongyuan Zhang, and Xuelong Li. Enhance vision-language alignment with noise. InProceedings of the AAAI Conference on Artifi- cial Intelligence, volume 39, pages 17449–17457,
2025
-
[16]
Efficient test-time adaptation of vision-language mod- els
[Karmanovet al., 2024 ] Adilbek Karmanov, Dayan Guan, Shijian Lu, Abdulmotaleb El Saddik, and Eric Xing. Efficient test-time adaptation of vision-language mod- els. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14162– 14171,
2024
-
[17]
3d object representations for fine- grained categorization
[Krauseet al., 2013 ] Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine- grained categorization. InProceedings of the IEEE inter- national conference on computer vision workshops, pages 554–561,
2013
-
[18]
Cliptta: Robust contrastive vision-language test-time adaptation.arXiv preprint arXiv:2507.14312,
[Lafonet al., 2025 ] Marc Lafon, Gustavo Adolfo Vargas Hakim, Cl´ement Rambour, Christian Desrosier, and Nico- las Thome. Cliptta: Robust contrastive vision-language test-time adaptation.arXiv preprint arXiv:2507.14312,
-
[19]
Rlaif: Scaling reinforcement learning from hu- man feedback with ai feedback
[Leeet al., 2023 ] Harrison Lee, Samrat Phatale, Hassan Mansoor, Kellie Ren Lu, Thomas Mesnard, Johan Ferret, Colton Bishop, Ethan Hall, Victor Carbune, and Abhinav Rastogi. Rlaif: Scaling reinforcement learning from hu- man feedback with ai feedback
2023
-
[20]
Fine-Grained Visual Classification of Aircraft
[Majiet al., 2013 ] Subhransu Maji, Esa Rahtu, Juho Kan- nala, Matthew Blaschko, and Andrea Vedaldi. Fine- grained visual classification of aircraft.arXiv preprint arXiv:1306.5151,
work page internal anchor Pith review arXiv 2013
-
[21]
Automated flower classification over a large number of classes
[Nilsback and Zisserman, 2008] Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In2008 Sixth Indian conference on computer vision, graphics & image processing, pages 722–729. IEEE,
2008
-
[22]
Watt: Weight aver- age test time adaptation of clip.Advances in neural infor- mation processing systems, 37:48015–48044,
[Osowiechiet al., 2024 ] David Osowiechi, Mehrdad Noori, Gustavo Vargas Hakim, Moslem Yazdanpanah, Ali Bahri, Milad Cheraghalikhani, Sahar Dastani, Farzad Beizaee, Is- mail Ayed, and Christian Desrosiers. Watt: Weight aver- age test time adaptation of clip.Advances in neural infor- mation processing systems, 37:48015–48044,
2024
-
[23]
Training language models to follow instruc- tions with human feedback.Advances in neural informa- tion processing systems, 35:27730–27744,
[Ouyanget al., 2022 ] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instruc- tions with human feedback.Advances in neural informa- tion processing systems, 35:27730–27744,
2022
-
[24]
Cats and dogs
[Parkhiet al., 2012 ] Omkar M Parkhi, Andrea Vedaldi, An- drew Zisserman, and CV Jawahar. Cats and dogs. In2012 IEEE conference on computer vision and pattern recogni- tion, pages 3498–3505. IEEE,
2012
-
[25]
Learning transferable visual models from nat- ural language supervision
[Radfordet al., 2021 ] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from nat- ural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR,
2021
-
[26]
Direct preference optimization: Your lan- guage model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741,
[Rafailovet al., 2023 ] Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your lan- guage model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741,
2023
-
[27]
Do imagenet classi- fiers generalize to imagenet? InInternational conference on machine learning, pages 5389–5400
[Rechtet al., 2019 ] Benjamin Recht, Rebecca Roelofs, Lud- wig Schmidt, and Vaishaal Shankar. Do imagenet classi- fiers generalize to imagenet? InInternational conference on machine learning, pages 5389–5400. PMLR,
2019
-
[28]
Proximal Policy Optimization Algorithms
[Schulmanet al., 2017 ] John Schulman, Filip Wolski, Pra- fulla Dhariwal, Alec Radford, and Oleg Klimov. Prox- imal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review arXiv 2017
-
[29]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
[Shenet al., 2025 ] Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, et al. Vlm-r1: A stable and generalizable r1-style large vision-language model.arXiv preprint arXiv:2504.07615,
work page internal anchor Pith review arXiv 2025
-
[30]
Test-time prompt tuning for zero-shot gen- eralization in vision-language models.Advances in Neural Information Processing Systems, 35:14274–14289,
[Shuet al., 2022 ] Manli Shu, Weili Nie, De-An Huang, Zhiding Yu, Tom Goldstein, Anima Anandkumar, and Chaowei Xiao. Test-time prompt tuning for zero-shot gen- eralization in vision-language models.Advances in Neural Information Processing Systems, 35:14274–14289,
2022
-
[31]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
[Soomroet al., 2012 ] Khurram Soomro, Amir Roshan Za- mir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402,
work page internal anchor Pith review arXiv 2012
-
[32]
Learning robust global repre- sentations by penalizing local predictive power.Advances in neural information processing systems, 32,
[Wanget al., 2019 ] Haohan Wang, Songwei Ge, Zachary Lipton, and Eric P Xing. Learning robust global repre- sentations by penalizing local predictive power.Advances in neural information processing systems, 32,
2019
-
[33]
Sun database: Large-scale scene recognition from abbey to zoo
[Xiaoet al., 2010 ] Jianxiong Xiao, James Hays, Krista A Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large-scale scene recognition from abbey to zoo. In2010 IEEE computer society conference on computer vision and pattern recognition, pages 3485–3492. IEEE,
2010
-
[34]
[Xuet al., 2025 ] Yanchen Xu, Ziheng Jiao, Hongyuan Zhang, and Xuelong Li. Grpo-rm: Fine-tuning representa- tion models via grpo-driven reinforcement learning.arXiv preprint arXiv:2511.15256,
-
[35]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
[Yuet al., 2025 ] Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review arXiv 2025
-
[36]
Dual prototype evolving for test- time generalization of vision-language models.Advances in Neural Information Processing Systems, 37:32111– 32136,
[Zhanget al., 2024 ] Ce Zhang, Simon Stepputtis, Katia Sycara, and Yaqi Xie. Dual prototype evolving for test- time generalization of vision-language models.Advances in Neural Information Processing Systems, 37:32111– 32136,
2024
-
[37]
[Zhanget al., 2025 ] Xinjie Zhang, Jintao Guo, Shanshan Zhao, Minghao Fu, Lunhao Duan, Jiakui Hu, Yong Xien Chng, Guo-Hua Wang, Qing-Guo Chen, Zhao Xu, et al. Unified multimodal understanding and generation models: Advances, challenges, and opportunities.arXiv preprint arXiv:2505.02567,
-
[38]
Test-time adaptation with clip reward for zero-shot gen- eralization in vision-language models
[Zhaoet al., 2024 ] S Zhao, X Wang, L Zhu, and Y Yang. Test-time adaptation with clip reward for zero-shot gen- eralization in vision-language models. In12th Inter- national Conference on Learning Representations, ICLR 2024,
2024
-
[39]
Learning to prompt for vision-language models.International Journal of Computer Vision, 130(9):2337–2348, 2022
[Zhouet al., 2022b ] Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.International Journal of Computer Vision, 130(9):2337–2348, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.