Recognition: unknown
Deepfake Audio Detection Using Self-supervised Fusion Representations
Pith reviewed 2026-05-07 12:55 UTC · model grok-4.3
The pith
A dual-branch framework fuses XLS-R speech and BEATs environmental representations via a Matching Head and cross-attention to detect independently manipulated audio components.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
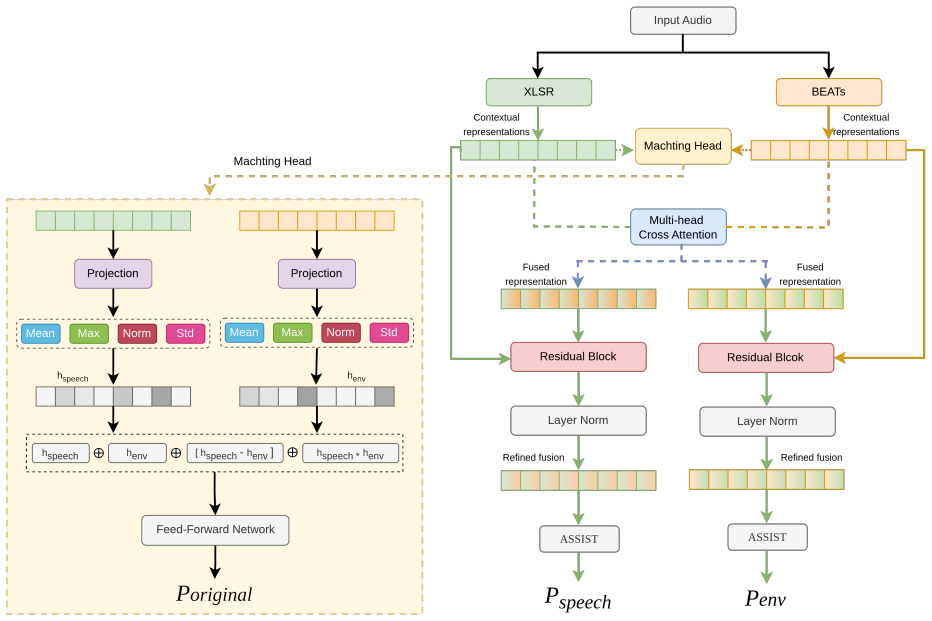
The dual-branch architecture jointly processes speech and environmental audio by feeding XLS-R and BEATs embeddings into a Matching Head for statistical normalization and interaction, applying multi-head cross-attention for bidirectional exchange, adding residual connections and layer normalization, and passing the result to an AASIST classifier that outputs original-class, speech-spoof, and environment-spoof probabilities; on the test set this produces 70.20% F1-score and 16.54% environmental EER, beating the baseline.
What carries the argument
The Matching Head that computes representation differences through statistical normalization and interaction, paired with multi-head cross-attention that enables information exchange between the speech and environmental branches.
If this is right
- The model produces three distinct outputs—original authenticity, speech spoof probability, and environment spoof probability—allowing targeted flagging of manipulated components.
- Residual connections and layer normalization after cross-attention stabilize the fused representations for the downstream AASIST classifier.
- Self-supervised pretrained extractors supply complementary contextual cues that a single audio model cannot capture when only one component is altered.
- The approach directly addresses the ESDD2 challenge requirement for independent manipulation detection in mixed speech-plus-environment audio.
Where Pith is reading between the lines
- The same fusion pattern could be tested on datasets containing music or multi-speaker mixtures to check whether the Matching Head still isolates spoofed elements.
- If the cross-attention weights consistently highlight the manipulated branch, the architecture might be adapted for real-time partial-audio verification in voice assistants.
- The performance gain over baseline suggests that explicit difference modeling between pretrained representations is more effective than simple concatenation for component-wise forgery detection.
Load-bearing premise
That the differences between XLS-R and BEATs embeddings reliably encode whether speech or environmental components have been spoofed, and that the Matching Head plus cross-attention can isolate those differences without being misled by natural acoustic variation.
What would settle it
Evaluating the same architecture on a held-out CompSpoofV2 variant where environmental manipulations are replaced by natural room impulse responses and measuring whether the environmental EER rises above the reported 16.54% or the F1-score falls below 65%.
Figures

read the original abstract
This paper describes a submission to the Environment-Aware Speech and Sound Deepfake Detection Challenge (ESDD2) 2026, which addresses component-level deepfake detection using the CompSpoofV2 dataset, where speech and environmental sounds may be independently manipulated. To address this challenge, a dual-branch deepfake detection framework is proposed to jointly model speech and environmental contextual representations from input audio. Two pretrained models, XLS-R for speech and BEATs for environmental sound, are used to extract complementary contextual representations. A Matching Head is introduced to model representation differences through statistical normalization and representation interaction, enabling estimation of the original class. In parallel, multi-head cross-attention enables effective information exchange between speech and environmental components. The refined representations are processed with residual connections and layer normalization, and passed to an AASIST classifier to predict speech-based and environment-based spoofing probabilities. The model outputs original, speech, and environment predictions. On the test set, the proposed system achieves an F1-score of 70.20% and an environmental EER of 16.54%, outperforming the baseline system.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes a submission to the Environment-Aware Speech and Sound Deepfake Detection Challenge (ESDD2) 2026 using the CompSpoofV2 dataset. It proposes a dual-branch framework that extracts speech representations with frozen XLS-R and environmental representations with frozen BEATs, models their differences via a Matching Head (statistical normalization plus interaction), exchanges information with multi-head cross-attention, applies residual connections and layer normalization, and feeds the result to an AASIST classifier that produces original, speech-spoof, and environment-spoof probabilities. On the held-out test set the system reports an F1-score of 70.20 % and environmental EER of 16.54 %, outperforming the official baseline.
Significance. If the numbers are reproducible, the work supplies concrete evidence that fusing complementary self-supervised encoders with a lightweight difference-modeling head and cross-attention can improve component-level deepfake detection in mixed speech-plus-environment audio. The approach is practical for challenge settings because it keeps the large encoders frozen and adds only modest trainable modules.
major comments (1)
- Method section: the training protocol (optimizer, learning-rate schedule, batch size, epoch count, loss weighting between the three output heads, and hyper-parameter search) is not described. Without these details it is impossible to verify that the reported 70.20 % F1 and 16.54 % EER were obtained without data leakage or unintended overfitting, which directly affects the soundness of the central performance claim.
minor comments (1)
- Abstract: the CompSpoofV2 dataset is named but no size, class balance, or manipulation statistics are given, making it harder for readers to interpret the absolute values of F1 and EER.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance. We address the major comment below.
read point-by-point responses
-
Referee: Method section: the training protocol (optimizer, learning-rate schedule, batch size, epoch count, loss weighting between the three output heads, and hyper-parameter search) is not described. Without these details it is impossible to verify that the reported 70.20 % F1 and 16.54 % EER were obtained without data leakage or unintended overfitting, which directly affects the soundness of the central performance claim.
Authors: We agree that the training protocol details were omitted from the manuscript. In the revised version we will add a dedicated subsection to the Method section providing a complete description of the optimizer, learning-rate schedule, batch size, epoch count, loss weighting between the three output heads, and hyper-parameter search procedure. This addition will enable full verification of the reported metrics and address concerns about reproducibility, data leakage, and overfitting. revision: yes
Circularity Check
No significant circularity; empirical performance result on external test set
full rationale
The paper describes an empirical architecture (dual-branch fusion of frozen XLS-R and BEATs encoders, Matching Head, cross-attention, AASIST classifier) and reports F1-score and EER on the ESDD2 challenge test set. No equations, predictions, or first-principles derivations are presented that reduce by construction to fitted inputs, self-citations, or renamed known results. The central claim is an outperformance number measured against an external baseline on held-out data; the evaluation is independent of any internal fitting loop described in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Natural tts synthesis by conditioning wavenet on mel spectrogram predictions,
Jonathan Shen, Ruoming Pang, Ron J Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, Rj Skerrv-Ryan, et al., “Natural tts synthesis by conditioning wavenet on mel spectrogram predictions,” inICASSP 2018-2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018, pp. 4779–4783
2018
-
[2]
Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,
Jaehyeon Kim, Jungil Kong, and Juhee Son, “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,” in International conference on machine learning. PMLR, 2021, pp. 5530– 5540
2021
-
[3]
Styletts 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech lan- guage models,
Yinghao Aaron Li, Cong Han, Vinay Raghavan, Gavin Mischler, and Nima Mesgarani, “Styletts 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech lan- guage models,”Advances in neural information processing systems, vol. 36, pp. 19594–19621, 2023
2023
-
[4]
Yourtts: Towards zero- shot multi-speaker tts and zero-shot voice conversion for everyone,
Edresson Casanova, Julian Weber, Christopher D Shulby, Arnaldo Can- dido Junior, Eren G ¨olge, and Moacir A Ponti, “Yourtts: Towards zero- shot multi-speaker tts and zero-shot voice conversion for everyone,” in International conference on machine learning. PMLR, 2022, pp. 2709– 2720
2022
-
[5]
Starganv2-vc: A diverse, unsupervised, non-parallel framework for natural-sounding voice conversion,
Yinghao Aaron Li, Ali Zare, and Nima Mesgarani, “Starganv2-vc: A diverse, unsupervised, non-parallel framework for natural-sounding voice conversion,” inProc. Interspeech 2021, 2021, pp. 1349–1353
2021
-
[6]
Asvspoof 2019: Future horizons in spoofed and fake audio detection,
Massimiliano Todisco, Xin Wang, Ville Vestman, Md Sahidullah, H ´ector Delgado, Andreas Nautsch, Junichi Yamagishi, Nicholas Evans, Tomi Kinnunen, and Kong Aik Lee, “Asvspoof 2019: Future horizons in spoofed and fake audio detection,” inInterspeech 2019, 2019
2019
-
[7]
Spoofceleb: Speech deepfake detection and sasv in the wild,
Jee-weon Jung, Yihan Wu, Xin Wang, Ji-Hoon Kim, Soumi Maiti, Yuta Matsunaga, Hye-jin Shim, Jinchuan Tian, Nicholas Evans, Joon Son Chung, et al., “Spoofceleb: Speech deepfake detection and sasv in the wild,”IEEE Open Journal of Signal Processing, 2025
2025
-
[8]
Partial fake speech attacks in the real world using deepfake audio,
Abdulazeez Alali and George Theodorakopoulos, “Partial fake speech attacks in the real world using deepfake audio,”Journal of Cybersecurity and Privacy, vol. 5, no. 1, pp. 6, 2025
2025
-
[9]
H ´ector Delgado, Nicholas Evans, Tomi Kinnunen, Kong Aik Lee, Xuechen Liu, Andreas Nautsch, Jose Patino, Md Sahidullah, Massim- iliano Todisco, Xin Wang, et al., “Asvspoof 2021: Automatic speaker verification spoofing and countermeasures challenge evaluation plan,” arXiv preprint arXiv:2109.00535, 2021
-
[10]
Add 2022: the first audio deep synthesis detection challenge,
Jiangyan Yi, Ruibo Fu, Jianhua Tao, Shuai Nie, Haoxin Ma, Chenglong Wang, Tao Wang, Zhengkun Tian, Ye Bai, Cunhang Fan, et al., “Add 2022: the first audio deep synthesis detection challenge,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 9216–9220
2022
-
[11]
Wavefake: A data set to facilitate audio deepfake detection,
Joel Frank and Lea Sch ¨onherr, “Wavefake: A data set to facilitate audio deepfake detection,” inProceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021) Track on Datasets and Benchmarks, 2021
2021
-
[12]
Deepfake audio detection via mfcc features using machine learning,
Ameer Hamza, Abdul Rehman Rehman Javed, Farkhund Iqbal, Natalia Kryvinska, Ahmad S Almadhor, Zunera Jalil, and Rouba Borghol, “Deepfake audio detection via mfcc features using machine learning,” IEEE Access, vol. 10, pp. 134018–134028, 2022
2022
-
[13]
Hybrid transformer architectures with diverse audio features for deepfake speech classification,
Khalid Zaman, Islam JAM Samiul, Melike Sah, Cem Direkoglu, Shogo Okada, and Masashi Unoki, “Hybrid transformer architectures with diverse audio features for deepfake speech classification,”IEEe Access, vol. 12, pp. 149221–149237, 2024
2024
-
[14]
Asvspoof 2019: Spoofing countermeasures for the detection of synthesized, converted and replayed speech,
Andreas Nautsch, Xin Wang, Nicholas Evans, Tomi H Kinnunen, Ville Vestman, Massimiliano Todisco, H ´ector Delgado, Md Sahidullah, Junichi Yamagishi, and Kong Aik Lee, “Asvspoof 2019: Spoofing countermeasures for the detection of synthesized, converted and replayed speech,”IEEE Transactions on Biometrics, Behavior , and Identity Science, vol. 3, no. 2, pp....
2019
-
[15]
Deep attention mechanism residual network for audio deepfake detection using multi scale cepstral coeffi- cient features,
Haitao Yang, Yingzhuo Xiong, Nan Zhao, Xiai Yan, Dongliang Zhang, Yun Zhang, and Huapeng Wang, “Deep attention mechanism residual network for audio deepfake detection using multi scale cepstral coeffi- cient features,”Signal Processing, p. 110668, 2026
2026
-
[16]
Mixture of experts fusion for fake audio detection using frozen wav2vec 2.0,
Zhiyong Wang, Ruibo Fu, Zhengqi Wen, Jianhua Tao, Xiaopeng Wang, Yuankun Xie, Xin Qi, Shuchen Shi, Yi Lu, Yukun Liu, et al., “Mixture of experts fusion for fake audio detection using frozen wav2vec 2.0,” in ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[17]
V oice deepfake detection using the self-supervised pre-training model hubert,
Lanting Li, Tianliang Lu, Xingbang Ma, Mengjiao Yuan, and Da Wan, “V oice deepfake detection using the self-supervised pre-training model hubert,”Applied Sciences, vol. 13, no. 14, pp. 8488, 2023
2023
-
[18]
Wavlm model ensemble for audio deepfake detection,
David Combei, Adriana Stan, Dan Oneata, and Horia Cucu, “Wavlm model ensemble for audio deepfake detection,” inProc. ASVspoof 2024, 2024, pp. 170–175
2024
-
[19]
Training-free deepfake voice recognition by leveraging large-scale pre-trained models,
Alessandro Pianese, Davide Cozzolino, Giovanni Poggi, and Luisa Verdoliva, “Training-free deepfake voice recognition by leveraging large-scale pre-trained models,” inProceedings of the 2024 ACM Workshop on Information Hiding and Multimedia Security, 2024, pp. 289–294
2024
-
[20]
Xls-r: Self-supervised cross-lingual speech representation learning at scale,
Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, et al., “Xls-r: Self-supervised cross-lingual speech representation learning at scale,”Interspeech 2022, 2022
2022
-
[21]
Beats: Audio pre-training with acoustic tokenizers,
Sanyuan Chen, Yu Wu, Chengyi Wang, Shujie Liu, Daniel Tompkins, Zhuo Chen, Wanxiang Che, Xiangzhan Yu, and Furu Wei, “Beats: Audio pre-training with acoustic tokenizers,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 5178–5193
2023
-
[22]
Aasist: Audio anti-spoofing using integrated spectro-temporal graph attention networks,
Jee-weon Jung, Hee-Soo Heo, Hemlata Tak, Hye-jin Shim, Joon Son Chung, Bong-Jin Lee, Ha-Jin Yu, and Nicholas Evans, “Aasist: Audio anti-spoofing using integrated spectro-temporal graph attention networks,” inICASSP 2022-2022 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2022, pp. 6367–6371
2022
-
[23]
Esdd2: Environment-aware speech and sound deepfake detection challenge evaluation plan,
Xueping Zhang, Han Yin, Yang Xiao, Lin Zhang, Ting Dang, Rohan Ku- mar Das, and Ming Li, “Esdd2: Environment-aware speech and sound deepfake detection challenge evaluation plan,”arXiv e-prints, pp. arXiv– 2601, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.