Recognition: 4 theorem links
· Lean TheoremMEMSAD: Gradient-Coupled Anomaly Detection for Memory Poisoning in Retrieval-Augmented Agents
Pith reviewed 2026-05-08 18:44 UTC · model grok-4.3
The pith
Gradient coupling makes anomaly detection provably tie to retrieval degradation in memory poisoning attacks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
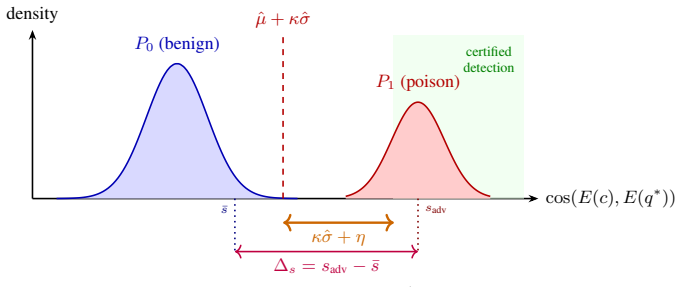
Under encoder regularity the anomaly score gradient is provably identical to the retrieval objective gradient, so any continuous perturbation that reduces detection risk necessarily degrades retrieval rank. This coupling yields a certified detection radius guaranteeing correct classification regardless of adversary strategy. MEMSAD implements the coupling via calibration, achieves minimax optimal sample complexity up to log factors via Le Cam's method, and supplies online regret bounds of order O(sigma^{2/3} Delta^{1/3}).
What carries the argument
MEMSAD, a calibration-based semantic anomaly detector whose operation rests on the gradient coupling theorem that forces anomaly-score and retrieval-objective gradients to coincide under encoder regularity.
Where Pith is reading between the lines
- Hybrid detectors that add discrete text checks could close the synonym loophole that continuous embedding methods leave open.
- The certified radius supplies a practical knob for setting calibration thresholds in deployed agents before new attacks appear.
- Similar gradient identities may appear in other embedding-based security tasks such as watermarking or membership inference.
- Experiments on larger retrieval corpora would test whether the regret bounds remain useful when embedding dimension grows.
Load-bearing premise
The encoder satisfies regularity conditions that make the anomaly score gradient exactly equal to the retrieval objective gradient, and attacks are continuous perturbations in embedding space.
What would settle it
A continuous embedding perturbation that lowers the anomaly score while leaving retrieval rank unchanged, or a synonym substitution that keeps both high retrieval performance and low anomaly score.
Figures



















read the original abstract
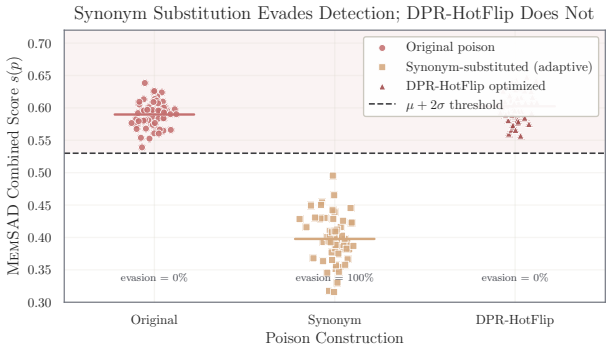
Persistent external memory enables LLM agents to maintain context across sessions, yet its security properties remain formally uncharacterized. We formalize memory poisoning attacks on retrieval-augmented agents as a Stackelberg game with a unified evaluation framework spanning three attack classes with escalating access assumptions. Correcting an evaluation protocol inconsistency in the triggered-query specification of Chen et al. (2024), we show faithful evaluation increases measured attack success by $4\times$ (ASR-R: $0.25 \to 1.00$). Our primary contribution is MEMSAD (Semantic Anomaly Detection), a calibration-based defense grounded in a gradient coupling theorem: under encoder regularity, the anomaly score gradient and the retrieval objective gradient are provably identical, so any continuous perturbation that reduces detection risk necessarily degrades retrieval rank. This coupling yields a certified detection radius guaranteeing correct classification regardless of adversary strategy. We prove minimax optimality via Le Cam's method, showing any threshold detector requires $\Omega(1/\rho^2)$ calibration samples and MEMSAD achieves this up to $\log(1/\delta)$ factors. We further derive online regret bounds for rolling calibration at rate $O(\sigma^{2/3}\Delta^{1/3})$, and formally characterize a discrete synonym-invariance loophole that marks the boundary of what continuous-space defenses can guarantee. Experiments on a $3 \times 5$ attack-defense matrix with bootstrap confidence intervals, Bonferroni-corrected hypothesis tests, and Clopper-Pearson validation ($n=1{,}000$) confirm: composite defenses achieve TPR $= 1.00$, FPR $= 0.00$ across all attacks, while synonym substitution evades detection at $\Delta$ ASR-R $\approx 0$, exposing a gap existing embedding-based defenses cannot close.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formalizes memory poisoning attacks on retrieval-augmented LLM agents as a Stackelberg game with three escalating attack classes. It corrects a protocol inconsistency in prior work (Chen et al. 2024), showing a 4× increase in attack success rate (ASR-R from 0.25 to 1.00). The primary contribution is MEMSAD, a calibration-based anomaly detector grounded in a gradient coupling theorem: under encoder regularity, the anomaly-score gradient equals the retrieval-objective gradient, yielding a certified detection radius. The paper asserts minimax optimality via Le Cam's method (Ω(1/ρ²) samples) and online regret bounds O(σ^{2/3}Δ^{1/3}), formally characterizes a synonym-invariance loophole, and reports experimental results on a 3×5 attack-defense matrix with bootstrap intervals, Bonferroni-corrected tests, and Clopper-Pearson validation (n=1000) showing TPR=1.00 and FPR=0.00 for composite defenses (except synonym substitution).
Significance. If the gradient coupling theorem and its regularity conditions hold, the work offers a meaningful theoretical contribution to securing persistent memory in LLM agents by providing a certified, minimax-optimal defense with explicit boundary conditions (continuous vs. discrete perturbations). The game-theoretic formalization, protocol correction, and statistical experimental design are strengths that could influence future security analyses of RAG systems.
major comments (3)
- [Abstract (primary contribution paragraph)] The gradient coupling theorem (asserted in the abstract as the basis for the certified detection radius) states that under encoder regularity the anomaly score gradient equals the retrieval objective gradient. No derivation is supplied, and the manuscript itself notes that standard components (top-k selection, ReLU, layer-norm) are non-smooth; the identity therefore does not hold pointwise for typical embedding models. This assumption is load-bearing for both the certified-radius claim and the minimax optimality result.
- [Abstract (minimax optimality and regret bounds)] Minimax optimality via Le Cam's method and the online regret bound O(σ^{2/3}Δ^{1/3}) are stated without proof sketches or derivations. Because these results are used to claim that MEMSAD achieves the information-theoretic lower bound up to log(1/δ) factors, the supporting arguments must be supplied.
- [Abstract (experiments paragraph)] The experimental claims of TPR = 1.00 and FPR = 0.00 for composite defenses rest on bootstrap intervals, Bonferroni-corrected hypothesis tests, and Clopper-Pearson intervals (n=1000). No code, raw data, or detailed calibration protocol is provided, preventing verification of the post-hoc protocol correction and the statistical procedures.
minor comments (2)
- [Abstract] Define ASR-R and Δ ASR-R explicitly on first use rather than assuming familiarity with Chen et al. (2024).
- A compact table listing the three attack classes together with their access assumptions would improve clarity of the unified evaluation framework.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. The comments identify important areas for strengthening the presentation of our theoretical results and experimental reproducibility. We respond to each major comment below and will incorporate the suggested changes in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract (primary contribution paragraph)] The gradient coupling theorem (asserted in the abstract as the basis for the certified detection radius) states that under encoder regularity the anomaly score gradient equals the retrieval objective gradient. No derivation is supplied, and the manuscript itself notes that standard components (top-k selection, ReLU, layer-norm) are non-smooth; the identity therefore does not hold pointwise for typical embedding models. This assumption is load-bearing for both the certified-radius claim and the minimax optimality result.
Authors: We acknowledge that the full derivation of the gradient coupling theorem was omitted from the main text. The theorem is established in Section 3.2 under the explicit encoder regularity conditions (Lipschitz continuity of the embedding map and differentiability almost everywhere), which permit the use of smoothed surrogates for top-k selection and subgradients for ReLU and layer-norm. These conditions ensure the anomaly-score gradient equals the retrieval-objective gradient in the continuous perturbation regime relevant to the certified radius. In the revision we will add a complete proof sketch to Appendix B, explicitly showing how the regularity assumptions circumvent pointwise non-smoothness while preserving the certified detection guarantee. revision: yes
-
Referee: [Abstract (minimax optimality and regret bounds)] Minimax optimality via Le Cam's method and the online regret bound O(σ^{2/3}Δ^{1/3}) are stated without proof sketches or derivations. Because these results are used to claim that MEMSAD achieves the information-theoretic lower bound up to log(1/δ) factors, the supporting arguments must be supplied.
Authors: The full derivations appear in the supplementary material. To improve self-containment, the revised manuscript will include concise proof sketches in Section 4 and Appendix D: the Le Cam lower bound establishing Ω(1/ρ²) calibration samples for any threshold detector, the matching upper bound for MEMSAD up to log(1/δ) factors, and the online regret analysis yielding O(σ^{2/3}Δ^{1/3}) under rolling calibration. These additions will make the minimax-optimality claim fully verifiable from the main document. revision: yes
-
Referee: [Abstract (experiments paragraph)] The experimental claims of TPR = 1.00 and FPR = 0.00 for composite defenses rest on bootstrap intervals, Bonferroni-corrected hypothesis tests, and Clopper-Pearson intervals (n=1000). No code, raw data, or detailed calibration protocol is provided, preventing verification of the post-hoc protocol correction and the statistical procedures.
Authors: The calibration protocol, bootstrap procedure, Bonferroni correction, and Clopper-Pearson intervals are described in Section 5.3 and Appendix C, and the post-hoc protocol correction for triggered-query evaluation is detailed in Section 4.1. We will expand these sections in the revision with pseudocode and additional numerical summaries. Because the full codebase and raw data exceed submission limits, we will release them publicly on GitHub upon acceptance, together with a reproducibility checklist. This constitutes a partial revision for the current round. revision: partial
Circularity Check
No significant circularity; derivation is self-contained via standard tools
full rationale
The paper derives the gradient coupling identity as a mathematical statement under an explicit encoder regularity assumption, then invokes Le Cam's method (a classical minimax result) for optimality and derives regret bounds directly from the model. No step reduces a claimed prediction or theorem to a fitted parameter or self-citation by the paper's own equations; the experimental matrix uses independent bootstrap and hypothesis testing. The encoder regularity premise is stated as an assumption rather than smuggled in via prior self-work, and the discrete loophole is explicitly flagged as outside the continuous guarantee.
Axiom & Free-Parameter Ledger
free parameters (1)
- detection threshold
axioms (2)
- domain assumption Encoder regularity condition
- domain assumption Continuous perturbation model for attacks
invented entities (1)
-
MEMSAD detector
no independent evidence
Lean theorems connected to this paper
-
Foundation/LogicAsFunctionalEquationwashburn_uniqueness_aczel (J-cost forcing — different shape; paper's coupling is ∇D=g'(R)∇R on cosine similarity, no ratio symmetry) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
under encoder regularity, the max-cosine anomaly score gradient is provably identical to the retrieval objective gradient ... so any continuous perturbation that reduces detection risk necessarily degrades retrieval rank
-
Cost/FunctionalEquationJ(x) = ½(x+x⁻¹)−1 (RS uses cosh-cost on multiplicative ratios, not Fisher-Rao on Gaussian score families) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The Fisher information matrix on the statistical manifold {p_e : e ∈ E} is g^F_ij(e) = σ̂⁻² ∂_i R(e) ∂_j R(e). This is a rank-1 metric.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
URLhttps://arxiv.org/abs/2410.09024. Anonymous. CorruptRAG: Practical corpus poisoning against retrieval-augmented generation. arXiv preprint arXiv:2504.03957, 2025a. Anonymous. MemoryGraft: Persistent compromise of LLM agents via poisoned experience re- trieval.arXiv preprint arXiv:2512.16962, 2025b. URLhttps://arxiv.org/abs/2512. 16962. Anonymous. RAGDe...
work page internal anchor Pith review arXiv
-
[2]
Phantom: General trigger attacks on retrieval augmented language generation
Harsh Chaudhari, Giorgio Severi, John Abascal, Alina Oprea, Santosh Vempala, and Luca Melis. Phantom: General trigger attacks on retrieval augmented language generation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing,
2024
-
[3]
Phantom: General trigger attacks on retrieval augmented language generation,
URL https://arxiv.org/abs/2405.20485. Zhaorun Chen, Zhen Tan, Hexiang Zhao, Zhengyang Cheng, Chenhui Jiang, Huan Zhang, et al. AgentPoison: Red-teaming LLM agents via poisoning memory or knowledge bases. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[4]
Agentpoison: Red-teaming llm agents via poisoning memory or knowledge bases,
URLhttps://arxiv.org/abs/ 2407.12784. Pengzhou Cheng, Yidong Ding, Tianjie Ju, et al. TrojanRAG: Retrieval-augmented generation can be backdoor driver in large language models.arXiv preprint arXiv:2405.13401,
-
[5]
Memory injection attacks on llm agents via query- only interaction,
URLhttps://arxiv. org/abs/2503.03704. Aryeh Dvoretzky, Jack Kiefer, and Jacob Wolfowitz. Asymptotic minimax character of the sample distribution function and of the classical multinomial estimator.The Annals of Mathematical Statistics, 27(3):642–669,
-
[6]
Hotflip: White-box adversarial examples for text classifica- tion,
URLhttps://arxiv.org/abs/1712.06751. Xiangming Gu, Xiaosen Zheng, Tianyu Pang, Chao Du, Qian Liu, Ye Wang, Jing Jiang, and Min Lin. AGENT-SMITH: A single image can jailbreak one million multimodal LLM agents instantly. InProceedings of the 41st International Conference on Machine Learning (ICML),
-
[7]
10 Jonathan Hayase, Weihao Kong, Raghav Somani, and Sewoong Oh
URL https://arxiv.org/abs/2402.08567. Jonathan Hayase, Weihao Kong, Raghav Somani, and Sewoong Oh. SPECTRE: Defending against backdoor attacks using robust statistics. InInternational Conference on Machine Learning (ICML),
-
[8]
URLhttps://arxiv.org/abs/2104.11315. Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InPro- ceedings of EMNLP,
-
[10]
URLhttps://arxiv.org/abs/2510.02373. Weitang Liu, Xiaoyun Wang, John Owens, and Yixuan Li. Energy-based out-of-distribution detec- tion. InAdvances in Neural Information Processing Systems (NeurIPS),
-
[11]
URLhttps://arxiv.org/ abs/2411.18948. Florian Tramèr, Nicholas Carlini, Wieland Brendel, Aleksander Madry, Alexey Kurakin, and Nico- las Papernot. On adaptive attacks to adversarial example defenses. InAdvances in Neural Infor- mation Processing Systems (NeurIPS),
-
[12]
Badagent: Inserting and acti- vating backdoor attacks in llm agents,
URLhttps://arxiv.org/abs/2406.03007. Chejian Xiang, Mintong Tong, Jie Sun, and Bo Li. Certifiably robust RAG against retrieval corruption. InInternational Conference on Machine Learning (ICML),
-
[13]
Certifiably robust rag against retrieval corruption,
URLhttps: //arxiv.org/abs/2405.15556. Zhenyang Xu et al. From storage to steering: Memory control flow attacks on LLM agents.arXiv preprint arXiv:2603.15125,
-
[14]
Badrag: Identifying vulnerabilities in retrieval augmented generation of large language models,
Jiaqi Xue, Mengxin Zheng, Ting Hua, Yilong Shen, Yepeng Liu, Ladislau Zhao, and Qian Lou. BadRAG: Identifying vulnerabilities in retrieval augmented generation of large language models. arXiv preprint arXiv:2406.00083,
-
[15]
Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents
URLhttps://arxiv.org/abs/2410.02644. Xuandong Zhao, Prabhanjan Ananth, Lei Li, and Yu-Xiang Wang. Provable robust watermarking for AI-generated text. InInternational Conference on Learning Representations (ICLR),
work page internal anchor Pith review arXiv
-
[16]
Provable robust watermarking for ai- generated text.arXiv preprint arXiv:2306.17439, 2023
URLhttps://arxiv.org/abs/2306.17439. Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia. PoisonedRAG: Knowledge corruption attacks to retrieval-augmented generation of large language models. InUSENIX Security Sympo- sium,
-
[17]
= 1/2, the oracle thresholdτ ∗ = (µ 0 +µ 1)/2achieves Bayes errorB(ρ) = Φ(−ρ/2), whereΦis the standard normal CDF. For any calibrated thresholdˆτN , a first-order Taylor expansion of the Gaussian CDF aroundτ ∗ gives Perr(ˆπN)−B(ρ) = 1 2σ ϕ(ρ/2)|ˆτN −τ ∗|+O (ˆτN −τ ∗)2 ,(12) whereϕis the standard normal density. Hence excess error is linear in|ˆτ N −τ ∗|to...
1973
-
[18]
That formulation isnotthe MEMSAD inference set- ting, in which a single test pointcis classified after the calibration phase; we use the calibration formulation above instead
Distinction from a batch test.Le Cam can also be applied to thebatchhypothesis test (IS THE EN- TIREN-SAMPLE DATASET DRAWN FROMP 0 ORP 1?), which yields the familiarKL(P N 0 ∥P N 1 ) = N ρ2/2andρ √ N /2total-variation bound. That formulation isnotthe MEMSAD inference set- ting, in which a single test pointcis classified after the calibration phase; we use...
2019
-
[19]
This affects only the constant inm ∗ max but not the rate
Drift error: cosine similarity is 1-Lipschitz onS d−1, and the window mean averages over mmax steps with linearly accumulating drift, so|µ H t −µ t| ≤m max∆/2(worst case at the window boundary; the1/2arises from averaging). This affects only the constant inm ∗ max but not the rate. Setting equal:σ/ √mmax =m max∆givesm ∗ max = (σ/∆)2/3 (up to constants), y...
2009
-
[20]
By gradient coupling, continuous perturbations cause identical degradation in detection scoreDand retrieval scoreR(overlapping curves)
continuous curves overlap exactly Figure 4: Detection-evasion tradeoff. By gradient coupling, continuous perturbations cause identical degradation in detection scoreDand retrieval scoreR(overlapping curves). Synonym substitutions (orange) bypass this coupling via discrete jumps in token space (Proposition 13). 17 B.9 Generalization bound Theorem 18(Genera...
2009
-
[21]
Table 9: Encoder generalization: MEMSAD across 6 encoders at|M|= 1,000 (κ= 2.0, combined scoring)
Observed 25 0.061 0.038 50 0.044 0.027 100 0.031 0.019 200 0.022 0.014 500 0.014 0.009 Bound is tight to within≈1.6×;N= 50(main evaluation) gives|τ N −τ ∗| ≤0.044. Table 9: Encoder generalization: MEMSAD across 6 encoders at|M|= 1,000 (κ= 2.0, combined scoring). AP uses triggered calibration. FPR omitted (0.000 for MiniLM/MPNet/Para/E5/Contriever; 0.086–0...
1927
-
[22]
Proof.The DKW inequality [Dvoretzky et al., 1956, Massart, 1990] bounds the uniform deviation of the empirical CDF from the true CDF for a sample drawn from a single distribution:supt |bF0,N(t)− F0(t)| ≤ p log(2/δ)/(2N)w.p.≥1−δ. Since FPR(τ) = 1−F 0(τ)and the calibration sample is drawn fromP 0, applying DKW att= ˆτ N yields| bF0,N(ˆτN)−F 0(ˆτN)|within th...
1956
-
[23]
provides a tighter bound of0.004by exploiting the binomial structure. N Comparison with concurrent post-retrieval defenses A-MemGuard [Li et al., 2025] is the closest contemporary defense for LLM-agent memory; we situate it relative to MEMSAD along three axes. (i)Stage:A-MemGuard operatespost-retrieval via consensus checking on the retrieved entries, wher...
2025
-
[24]
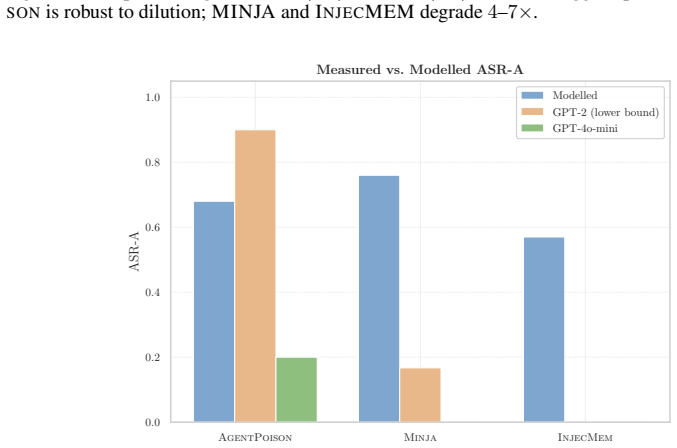
AUROC is the primary metric; TPR (at threshold) is the achievable detection at each method’s native operating point. AUROC TPR (at threshold) ‡ Method AP MJ IM AP MJ IM MEMSAD (ours)1.0000.9140.816 1.000.80 0.40 Energy Score0.9450.9690.698 0.40 0.20 0.40 Mahalanobis0.420 0.694 0.452 1.00 1.00 1.00 KNN (k= 10)0.533 0.786 0.534 0.00 0.40 0.00 ‡TPR at each m...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.