Recognition: unknown
Revisiting Graph-Tokenizing Large Language Models: A Systematic Evaluation of Graph Token Understanding
Pith reviewed 2026-05-07 16:43 UTC · model grok-4.3
The pith
Graph-tokenizing LLMs do not fully understand the graph tokens they receive as input.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
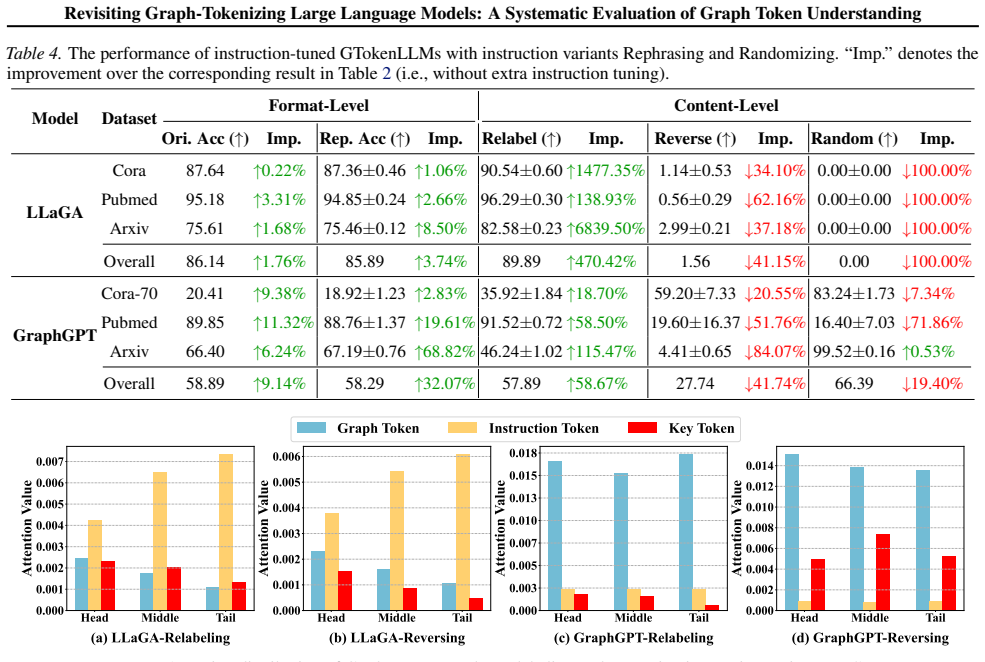
Existing GTokenLLMs do not fully understand graph tokens in the natural-language embedding space. They exhibit over-sensitivity or over-insensitivity to instruction changes and rely heavily on text for reasoning, even though the tokens preserve task-relevant graph information and receive attention across LLM layers. Additional instruction tuning improves performance on original and seen instructions but does not solve the graph-token understanding problem.
What carries the argument
GTEval, the evaluation pipeline that applies controlled transformations to instruction format and content to test whether models truly process the graph tokens rather than the surrounding text.
If this is right
- Graph tokens preserve task-relevant information yet their utilization still varies across models and instruction variants.
- Models continue to lean on text for reasoning even when graph tokens are provided as prefix input.
- Instruction tuning raises accuracy on original and previously seen instructions but does not remove the underlying sensitivity issues.
- Graph information reaches the models but is not consistently leveraged for stable performance under changed prompts.
Where Pith is reading between the lines
- Similar tokenization approaches for other structured data such as tables or molecular graphs may face the same utilization gap.
- New training signals that explicitly reward correct use of the graph tokens, rather than text fallback, could be tested next.
- Evaluation suites for multimodal LLMs should routinely include format and content perturbations to detect hidden text reliance.
Load-bearing premise
That the specific changes made to instruction format and content in GTEval isolate the model's graph token understanding without introducing unrelated biases from the transformation process itself.
What would settle it
A GTokenLLM that produces identical reasoning quality and final answers across every instruction variant while showing no measurable dependence on the text portions when graph tokens are supplied would falsify the central claim.
Figures



read the original abstract
The remarkable success of large language models (LLMs) has motivated researchers to adapt them as universal predictors for various graph tasks. As a widely recognized paradigm, Graph-Tokenizing LLMs (GTokenLLMs) compress complex graph data into graph tokens and treat them as prefix tokens for querying LLMs, leading many to believe that LLMs can understand graphs more effectively and efficiently. In this paper, we challenge this belief: \textit{Do GTokenLLMs fully understand graph tokens in the natural-language embedding space?} Motivated by this question, we formalize a unified framework for GTokenLLMs and propose an evaluation pipeline, \textbf{GTEval}, to assess graph-token understanding via instruction transformations at the format and content levels. We conduct extensive experiments on 6 representative GTokenLLMs with GTEval. The primary findings are as follows: (1) Existing GTokenLLMs do not fully understand graph tokens. They exhibit over-sensitivity or over-insensitivity to instruction changes, and rely heavily on text for reasoning; (2) Although graph tokens preserve task-relevant graph information and receive attention across LLM layers, their utilization varies across models and instruction variants; (3) Additional instruction tuning can improve performance on the original and seen instructions, but it does not fully address the challenge of graph-token understanding, calling for further improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes a unified framework for Graph-Tokenizing LLMs (GTokenLLMs) and introduces the GTEval pipeline to evaluate graph-token understanding via format- and content-level instruction transformations. Experiments across six models show that these models exhibit over-sensitivity or over-insensitivity to such changes, rely heavily on text for reasoning, and do not fully utilize graph tokens despite preserving task-relevant information and receiving attention across layers; additional instruction tuning improves seen cases but does not resolve the core issue.
Significance. If the central findings hold after addressing methodological controls, the work is significant as a systematic empirical challenge to the assumption that prefixing graph tokens enables effective graph reasoning in LLMs. The breadth of experiments on multiple models and variants, plus the attention and information-preservation analyses, provide concrete evidence that motivates better graph-token integration methods. Reproducible evaluation across instruction variants is a clear strength.
major comments (1)
- [§3] §3 (GTEval pipeline): The instruction transformations alter overall prompt structure, tokenization boundaries, and attention distributions for any prefix tokens, not solely graph tokens. No ablation is described that holds the graph token representation fixed while varying only the instruction wrapper, nor any comparison against non-graph prefix tokens under the same transformations. This makes it difficult to attribute observed sensitivity specifically to deficient graph-token comprehension rather than generic instruction-following fragility.
minor comments (2)
- [Abstract] The abstract and §4 could more explicitly list the six models, the exact tasks/datasets, and the quantitative definition of 'over-sensitivity' (e.g., accuracy delta thresholds) to improve reproducibility.
- [Figures] Figure legends and captions should clarify how attention scores are aggregated across layers and heads when claiming 'receive attention across LLM layers'.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and detailed review of our manuscript. We address the major comment below and will incorporate revisions to strengthen the attribution of our findings to graph-token understanding.
read point-by-point responses
-
Referee: [§3] §3 (GTEval pipeline): The instruction transformations alter overall prompt structure, tokenization boundaries, and attention distributions for any prefix tokens, not solely graph tokens. No ablation is described that holds the graph token representation fixed while varying only the instruction wrapper, nor any comparison against non-graph prefix tokens under the same transformations. This makes it difficult to attribute observed sensitivity specifically to deficient graph-token comprehension rather than generic instruction-following fragility.
Authors: We appreciate the referee's point on potential confounds in attributing sensitivity to graph tokens specifically. Our GTEval design applies transformations while preserving the graph tokens and their positions in the prompt, and we complement this with analyses showing that graph tokens retain task-relevant information and receive attention across layers. However, we acknowledge that the current experiments do not include the suggested ablations holding graph token representations fixed or direct comparisons to non-graph prefixes under identical transformations. In the revised manuscript, we will add these controls: (1) experiments that fix the graph token embeddings and vary only the instruction wrapper, and (2) parallel evaluations using non-graph prefix tokens (e.g., random vectors or text embeddings) to isolate whether the observed over-/under-sensitivity is graph-specific or reflects broader instruction-following limitations. revision: yes
Circularity Check
No circularity: empirical evaluation with independent experimental results
full rationale
The paper proposes GTEval as an evaluation pipeline and reports experimental findings on six existing GTokenLLMs. No mathematical derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described framework. Claims rest on observed model sensitivities to instruction transformations rather than any step that reduces by construction to its own inputs. The work is self-contained against external benchmarks via direct experimentation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vicuna: An open- source chatbot impressing gpt-4 with 90%* chatgpt qual- ity, March 2023
Chiang, W.-L., Li, Z., Lin, Z., et al. Vicuna: An open- source chatbot impressing gpt-4 with 90%* chatgpt qual- ity, March 2023. URLhttps://lmsys.org/blog/ 2023-03-30-vicuna/
2023
-
[1]
URLhttps://lmsys.org/blog/ 2023-03-30-vicuna/. Dai, X., Qu, H., Shen, Y ., et al. How do large language mod- els understand graph patterns? a benchmark for graph pattern comprehension.arXiv preprint arXiv:2410.05298,
-
[2]
Vision Transformers Need Registers
Darcet, T., Oquab, M., Mairal, J., et al. Vision transformers need registers.arXiv preprint arXiv:2309.16588,
work page internal anchor Pith review arXiv
-
[3]
Bert: Pre-training of deep bidirectional transformers for language under- standing
Devlin, J., Chang, M.-W., Lee, K., et al. Bert: Pre-training of deep bidirectional transformers for language under- standing. InProceedings of the 2019 conference of the North American chapter of the association for computa- tional linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186,
2019
-
[4]
Bert: Pre-training of deep bidirectional transformers for language under- standing
Devlin, J., Chang, M.-W., Lee, K., et al. Bert: Pre-training of deep bidirectional transformers for language under- standing. InProceedings of the 2019 conference of the North American chapter of the association for computa- tional linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186, 2019
2019
-
[4]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review arXiv 2010
-
[5]
Duan, K., Liu, Q., Chua, T.-S., et al. Simteg: A frustratingly simple approach improves textual graph learning.arXiv preprint arXiv:2308.02565,
- [6]
-
[7]
arXiv preprint arXiv:2305.15066 , year=
Guo, J., Du, L., Liu, H., et al. Gpt4graph: Can large language models understand graph structured data? an empirical evaluation and benchmarking.arXiv preprint arXiv:2305.15066,
-
[8]
Talk like a graph: Encoding graphs for large language models
Fatemi, B., Halcrow, J., and Perozzi, B. Talk like a graph: Encoding graphs for large language models. InThe Twelfth International Conference on Learning Represen- tations, 2024
2024
-
[8]
Guo, K., Liu, Z., Chen, Z., et al. Learning on graphs with large language models (llms): A deep dive into model robustness.arXiv preprint arXiv:2407.12068,
-
[9]
In-context autoencoder for context compression in a large language model
Ge, T., Jing, H., Wang, L., et al. In-context autoencoder for context compression in a large language model. InThe Twelfth International Conference on Learning Represen- tations, 2024
2024
-
[9]
Can llms effectively leverage graph structural information: when and why
Huang, J., Zhang, X., Mei, Q., et al. Can llms effectively leverage graph structural information: when and why. arXiv preprint arXiv:2309.16595,
-
[10]
Robustness of graph neural networks at scale.Advances in Neural Information Processing Systems, 34:7637–7649, 2021
Geisler, S., Schmidt, T.,S ¸irin, H., et al. Robustness of graph neural networks at scale.Advances in Neural Information Processing Systems, 34:7637–7649, 2021
2021
-
[10]
Kipf, T. N. and Welling, M. Semi-supervised classification with graph convolutional networks. In5th International Conference on Learning Representations, ICLR 2017, 9 Revisiting Graph-Tokenizing Large Language Models: A Systematic Evaluation of Graph Token Understanding Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net,
2017
-
[11]
Active instruction tuning: Improving cross-task generalization by training on prompt sensitive tasks
Kung, P.-N., Yin, F., Wu, D., et al. Active instruction tuning: Improving cross-task generalization by training on prompt sensitive tasks. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 1813–1829,
2023
-
[12]
Li, X., Chen, W., Chu, Q., et al. Can large language models analyze graphs like professionals? a benchmark, datasets and models.arXiv preprint arXiv:2409.19667,
-
[13]
and Wang, H
Guo, Z. and Wang, H. A deep graph neural network-based mechanism for social recommendations.IEEE Transac- tions on Industrial Informatics, 17(4):2776–2783, 2020
2020
-
[13]
Mernyei, P. and Cangea, C. Wiki-cs: A wikipedia-based benchmark for graph neural networks.arXiv preprint arXiv:2007.02901,
-
[14]
Inductive repre- sentation learning on large graphs.Advances in neural information processing systems, 30, 2017
Hamilton, W., Ying, Z., and Leskovec, J. Inductive repre- sentation learning on large graphs.Advances in neural information processing systems, 30, 2017
2017
-
[14]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, N. Sentence-bert: Sentence embeddings using siamese bert-networks.arXiv preprint arXiv:1908.10084,
work page internal anchor Pith review arXiv 1908
-
[15]
Harris, Z. S. Distributional structure.Word, 10(2-3):146– 162, 1954
1954
-
[15]
Tan, Y ., Lv, H., Huang, X., et al. Musegraph: Graph- oriented instruction tuning of large language models for generic graph mining.arXiv preprint arXiv:2403.04780, 2024a. Tan, Y ., Zhou, Z., Lv, H., et al. Walklm: A uniform lan- guage model fine-tuning framework for attributed graph embedding.Advances in Neural Information Processing Systems, 36, 2024b. ...
-
[16]
J., Shen, Y ., Wallis, P., et al
Hu, E. J., Shen, Y ., Wallis, P., et al. Lora: Low-rank adapta- tion of large language models.ICLR, 1(2):3, 2022
2022
-
[16]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review arXiv
-
[17]
Open graph benchmark: Datasets for machine learning on graphs.Advances in neural information processing systems, 33:22118–22133, 2020
Hu, W., Fey, M., Zitnik, M., et al. Open graph benchmark: Datasets for machine learning on graphs.Advances in neural information processing systems, 33:22118–22133, 2020
2020
-
[17]
Wang, H., Feng, S., He, T., et al. Can language models solve graph problems in natural language?Advances in Neural Information Processing Systems, 36, 2024b. Wang, J., Wu, J., Hou, Y ., et al. Instructgraph: Boost- ing large language models via graph-centric instruc- tion tuning and preference alignment.arXiv preprint arXiv:2402.08785, 2024c. Yan, H., Li,...
-
[18]
Natural language is all a graph needs.arXiv preprint arXiv:2308.07134, 4(5):7,
Ye, R., Zhang, C., Wang, R., et al. Natural language is all a graph needs.arXiv preprint arXiv:2308.07134, 4(5):7,
-
[19]
From anchors to answers: A novel node tokenizer for integrating graph structure into large language models
Ji, Y ., Liu, C., Chen, X., et al. From anchors to answers: A novel node tokenizer for integrating graph structure into large language models. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pp. 1124–1134, 2025
2025
-
[19]
Graphtranslator: Align- ing graph model to large language model for open-ended tasks
Zhang, M., Sun, M., Wang, P., et al. Graphtranslator: Align- ing graph model to large language model for open-ended tasks. InProceedings of the ACM on Web Conference 2024, pp. 1003–1014,
2024
-
[20]
Kipf, T. N. and Welling, M. Semi-supervised classification with graph convolutional networks. In5th International Conference on Learning Representations, ICLR 2017, 9 Revisiting Graph-Tokenizing Large Language Models: A Systematic Evaluation of Graph Token Understanding
2017
-
[20]
Graphtext: Graph rea- soning in text space.arXiv preprint arXiv:2310.01089,
Zhao, J., Zhuo, L., Shen, Y ., et al. Graphtext: Graph rea- soning in text space.arXiv preprint arXiv:2310.01089,
-
[21]
OpenReview.net, 2017
Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017. URL https:// openreview.net/forum?id=SJU4ayYgl
2017
-
[21]
Related Work In this section, we briefly discuss applications of LLMs to text-attributed graphs and existing benchmarks and evaluations of LLMs for graphs
10 Revisiting Graph-Tokenizing Large Language Models: A Systematic Evaluation of Graph Token Understanding A. Related Work In this section, we briefly discuss applications of LLMs to text-attributed graphs and existing benchmarks and evaluations of LLMs for graphs. LLMs for Graphs.Existing applications of LLMs to TAGs can be broadly categorized into two l...
2023
-
[22]
S., Reid, M., et al
Kojima, T., Gu, S. S., Reid, M., et al. Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
2022
-
[22]
The second line of work is GTokenLLMs, which integrates real-world graphs into LLMs by encoding graph structures and textual features into token-level embeddings
to improve their general capabilities on graph-related tasks. The second line of work is GTokenLLMs, which integrates real-world graphs into LLMs by encoding graph structures and textual features into token-level embeddings. As introduced in Section B, representative GTokenLLMs include InstructGLM (Ye et al., 2023), GraphGPT (Tang et al., 2024), GraphTran...
2023
-
[23]
Gofa: A generative one-for-all model for joint graph language modeling
Kong, L., Feng, J., Liu, H., et al. Gofa: A generative one-for-all model for joint graph language modeling. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[23]
highlight the importance of label space design and structural information in applying LLMs to graph tasks. In addition, existing benchmarks and evaluations examine LLM capabilities across a range of graph-related problems, including graph reasoning (Guo et al., 2023), adversarial robustness (Guo et al., 2024), graph theory problems (Wang et al., 2024b; Fa...
2023
-
[24]
Active instruction tuning: Improving cross-task generalization by training on prompt sensitive tasks
Kung, P.-N., Yin, F., Wu, D., et al. Active instruction tuning: Improving cross-task generalization by training on prompt sensitive tasks. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 1813–1829, 2023
2023
-
[24]
In stage 2, it projects GEs into GTs via a learned multilayer perceptron (MLP)
or SimTeG (Duan et al., 2023), to obtain node embeddings from textual attributes, and transforms graph structures into structure-aware GE sequences using predefined templates. In stage 2, it projects GEs into GTs via a learned multilayer perceptron (MLP). Finally, these GTs are used as prefix tokens to query the LLM for node classification, link predictio...
2023
-
[25]
aims to align LLMs’ reasoning ability with graph-domain structural knowledge learned by a pretrained GNN, thereby improving the generalization of graph learning. Specifically, GraphGPT employs a text-grounded GNN trained with CLIP-style contrastive alignment to obtain GEs, where node features are text embeddings encoded by BERT (Devlin et al., 2019). Thes...
2019
-
[26]
S., et al
Liu, J., Yang, C., Lu, Z., Chen, J., Li, Y ., Zhang, M., Bai, T., Fang, Y ., Sun, L., Yu, P. S., et al. Graph foundation models: Concepts, opportunities and challenges.IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 2025
2025
-
[26]
to obtain GEs. It then employs a Translator module based on a 11 Revisiting Graph-Tokenizing Large Language Models: A Systematic Evaluation of Graph Token Understanding Table 7.Example of GTextLLM prompts. Type Instruction Zero-Shot Paper: {text feature} Task: Please predict the most appropriate category for the paper. Your answer should be chosen from{cl...
2019
-
[27]
K., Nigam, K., Rennie, J., et al
McCallum, A. K., Nigam, K., Rennie, J., et al. Automating the construction of internet portals with machine learning. Information Retrieval, 3(2):127–163, 2000
2000
-
[27]
zero-shot
to learn memory embeddings that capture both structural and attribute semantic information, whose final-layer outputs serve as GTs. These GTs are then directly used as query tokens for another LLM, enabling graph-conditioned generation and reasoning. C. GTextLLM Prompts We list the GTextLLM prompts used in Table 7, including two commonly used prompts from...
2016
-
[28]
Cora Research Paper Classification Dataset
from a web link network. Our data include shallow embeddings commonly used in classical methods, raw node texts, edge indices, node labels, label names, and masks for training, validation, and testing. All datasets are under the MIT License unless otherwise specified. Detailed descriptions of these datasets are provided below: • Corais a citation network ...
2020
-
[31]
Graphgpt: Graph instruc- tion tuning for large language models
Tang, J., Yang, Y ., Wei, W., et al. Graphgpt: Graph instruc- tion tuning for large language models. InProceedings of the 47th International ACM SIGIR Conference on Re- search and Development in Information Retrieval, pp. 491–500, 2024
2024
-
[33]
Unigte: Unified graph–text encoding for zero-shot generalization across graph tasks and domains
Wang, D., Zuo, Y ., Lu, G., et al. Unigte: Unified graph–text encoding for zero-shot generalization across graph tasks and domains. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[35]
A comprehensive study on text-attributed graphs: Benchmarking and rethinking
Yan, H., Li, C., Long, R., et al. A comprehensive study on text-attributed graphs: Benchmarking and rethinking. Advances in Neural Information Processing Systems, 36: 17238–17264, 2023
2023
-
[36]
Revisiting semi-supervised learning with graph embeddings
Yang, Z., Cohen, W., and Salakhudinov, R. Revisiting semi-supervised learning with graph embeddings. In International conference on machine learning, pp. 40–48. PMLR, 2016
2016
-
[38]
efraudcom: An e- commerce fraud detection system via competitive graph neural networks.ACM Transactions on Information Sys- tems (TOIS), 40(3):1–29, 2022
Zhang, G., Li, Z., Huang, J., et al. efraudcom: An e- commerce fraud detection system via competitive graph neural networks.ACM Transactions on Information Sys- tems (TOIS), 40(3):1–29, 2022
2022
-
[39]
Graphtranslator: Align- ing graph model to large language model for open-ended tasks
Zhang, M., Sun, M., Wang, P., et al. Graphtranslator: Align- ing graph model to large language model for open-ended tasks. InProceedings of the ACM on Web Conference 2024, pp. 1003–1014, 2024
2024
-
[40]
Instruction tuning for large language models: A survey.ACM Computing Surveys, 58(7):1–36, 2026
Zhang, S., Dong, L., Li, X., et al. Instruction tuning for large language models: A survey.ACM Computing Surveys, 58(7):1–36, 2026
2026
-
[41]
Can large language models improve the adversarial robustness of graph neural net- works? InProceedings of the 31st ACM SIGKDD Con- ference on Knowledge Discovery and Data Mining V
Zhang, Z., Wang, X., et al. Can large language models improve the adversarial robustness of graph neural net- works? InProceedings of the 31st ACM SIGKDD Con- ference on Knowledge Discovery and Data Mining V . 1, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.