Recognition: no theorem link
Enhancing Performance Insight at Scale: A Heterogeneous Framework for Exascale Diagnostics
Pith reviewed 2026-05-12 02:31 UTC · model grok-4.3
The pith
A C++ and GPU-based framework ingests 100000 MPI ranks in under 10 seconds and accelerates trace analysis by up to 314 times while modeling potential application speedups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present an accelerated infrastructure for the hpcanalysis framework that leverages a high-performance C++ API and GPU parallelism to enable high-throughput diagnostics. Our C++ API achieves a 9.69-second ingestion time for 100000 MPI ranks on Aurora. Furthermore, our GPU-accelerated layer achieves up to 314x speedup over CPU-based processing when analyzing 100000 execution traces. We implement a topology-aware workflow that maps logical performance outliers to physical Slingshot interconnect coordinates, localizing network congestion across 22 distinct racks on Aurora. We introduce a novel tri-dimensional performance model that re-materializes iterative behavior from execution traces; us
What carries the argument
The GPU-accelerated analysis layer together with the tri-dimensional performance model that reconstructs iterative behavior from execution traces.
If this is right
- Performance diagnostics become feasible for systems with 100000 or more MPI ranks without prohibitive overhead.
- Network congestion points can be isolated to specific physical racks and interconnect coordinates.
- Iterative behavior in scientific codes can be quantified for speedup potential directly from existing traces.
- The framework can feed results into external analytical tools for deeper modeling.
Where Pith is reading between the lines
- If the model holds across more codes, it could support automated runtime adjustments during long exascale runs rather than post-mortem analysis.
- The same GPU and topology techniques might transfer to performance monitoring of large distributed training clusters in machine learning.
- Repeated use could reveal recurring congestion patterns that inform future interconnect designs.
Load-bearing premise
The tri-dimensional model and physical topology mapping accurately represent real iterative application behavior and network congestion without overfitting to the tested traces and machines.
What would settle it
Running the same workloads on a different exascale machine or with a new application and measuring whether the reported analysis speedups drop below 10x or the predicted 32 percent improvement fails to appear in actual execution time.
Figures
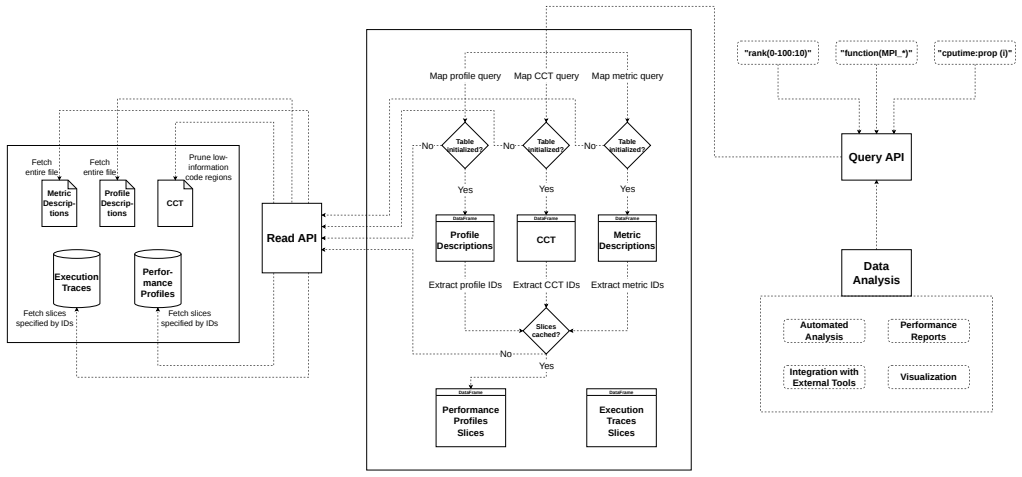





read the original abstract
As exascale systems reach unprecedented concurrency, traditional performance analysis tools struggle with the overhead of massive-scale telemetry. We present an accelerated infrastructure for the hpcanalysis framework that leverages a high-performance C++ API and GPU parallelism to enable high-throughput diagnostics. Our C++ API achieves a 9.69-second ingestion time for 100,000 MPI ranks on Aurora. Furthermore, our GPU-accelerated layer achieves up to 314x speedup over CPU-based processing when analyzing 100,000 execution traces. Finally, we implement a topology-aware workflow that maps logical performance outliers to physical Slingshot interconnect coordinates, localizing network congestion across 22 distinct racks on Aurora. We also demonstrate how the framework's advanced interface seamlessly integrates with external tools to provide sophisticated analytical models. We introduce a novel tri-dimensional performance model that "re-materializes" iterative behavior from execution traces; using this model, we identified a 32.28% potential speedup for a GAMESS workload on Frontier.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a heterogeneous framework extending the hpcanalysis infrastructure with a high-performance C++ API and GPU parallelism for scalable exascale diagnostics. It reports a 9.69 s ingestion time for 100k MPI ranks on Aurora, up to 314x GPU speedup over CPU processing of 100k traces, a topology-aware mapping of outliers to Slingshot coordinates that localizes congestion across 22 racks, and a novel tri-dimensional performance model that re-materializes iterative behavior to predict a 32.28% potential speedup for a GAMESS workload on Frontier.
Significance. If the central claims are substantiated, the work would meaningfully advance performance diagnostics for exascale systems by addressing telemetry overhead through GPU acceleration and topology integration. The reported speedups and the ability to map logical outliers to physical network locations could directly aid optimization of large-scale HPC codes; the model’s integration with external tools also offers a pathway for more sophisticated analysis beyond raw trace inspection.
major comments (3)
- [Abstract] Abstract: the 314x GPU speedup claim for 100,000 execution traces is presented without baseline CPU implementations, error bars, or scaling curves, so it is impossible to determine whether the gain is load-bearing or arises from unaccounted data-movement costs.
- [Abstract] Abstract: the tri-dimensional performance model is introduced as novel and used to derive the 32.28% GAMESS speedup on Frontier, yet no equations, fitting procedure, or quantitative validation (e.g., against ground-truth iterative traces or alternative models) are supplied, leaving the prediction vulnerable to overfitting.
- [Abstract] Abstract: the topology-aware workflow maps logical outliers to physical Slingshot coordinates across 22 racks on Aurora and claims to localize congestion, but no error metrics, false-positive rates, or direct comparison to network counters are provided to confirm the mapping’s accuracy.
minor comments (1)
- [Abstract] The abstract states that the framework “seamlessly integrates with external tools” but does not name the tools or describe the interface contract, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and commit to revisions that will strengthen the substantiation of the reported results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 314x GPU speedup claim for 100,000 execution traces is presented without baseline CPU implementations, error bars, or scaling curves, so it is impossible to determine whether the gain is load-bearing or arises from unaccounted data-movement costs.
Authors: We agree that the abstract does not supply these supporting details. In the revision we will add a concise description of the single-threaded CPU baseline, include error bars derived from repeated runs, and reference the scaling curves that demonstrate performance from smaller trace counts up to 100,000. We will also explicitly quantify data-movement overhead to confirm that the reported speedup reflects genuine computational improvement rather than unaccounted costs. revision: yes
-
Referee: [Abstract] Abstract: the tri-dimensional performance model is introduced as novel and used to derive the 32.28% GAMESS speedup on Frontier, yet no equations, fitting procedure, or quantitative validation (e.g., against ground-truth iterative traces or alternative models) are supplied, leaving the prediction vulnerable to overfitting.
Authors: We acknowledge that the current manuscript does not present the explicit equations, fitting procedure, or validation results in sufficient detail. We will revise the relevant section to include the mathematical formulation of the tri-dimensional model, describe the least-squares fitting procedure applied to the execution traces, and add quantitative validation comparing model predictions against held-out ground-truth iterative traces as well as against simpler baseline models. These additions will directly address the risk of overfitting and support the 32.28% speedup claim. revision: yes
-
Referee: [Abstract] Abstract: the topology-aware workflow maps logical outliers to physical Slingshot coordinates across 22 racks on Aurora and claims to localize congestion, but no error metrics, false-positive rates, or direct comparison to network counters are provided to confirm the mapping’s accuracy.
Authors: We agree that the abstract and current presentation lack quantitative accuracy measures. In the revision we will augment the topology-aware workflow section with error metrics for the logical-to-physical coordinate mapping, false-positive rates obtained from controlled synthetic congestion experiments, and direct comparisons against Slingshot network counter data collected during the same runs. These additions will provide the requested evidence for the accuracy of the congestion localization across the 22 racks. revision: yes
Circularity Check
No significant circularity; claims grounded in hardware measurements
full rationale
The paper reports concrete measured quantities (9.69 s ingestion for 100k ranks on Aurora, up to 314x GPU speedup on 100k traces, congestion localized to 22 racks) obtained via direct execution on exascale hardware. The tri-dimensional model is presented as a new analytical tool that extracts iterative behavior from traces and then computes a 32.28 % potential speedup for a separate GAMESS workload on Frontier; no equations, fitted parameters, or self-citations are shown that would make this output definitionally equivalent to its inputs. Because the central results rest on external benchmark runs rather than on quantities defined or fitted from the same data by construction, the derivation chain is self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Execution traces from MPI ranks can be ingested and analyzed in a topology-aware manner on exascale interconnects
invented entities (1)
-
tri-dimensional performance model
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
——, “Frontier User Guide,” 2026, Accessed: April 2026. [Online]. Available: https://docs.olcf.ornl.gov/systems/frontier user guide.html
work page 2026
- [3]
-
[4]
——, “Aurora User Guide,” 2026, Accessed: April 2026. [Online]. Available: https://docs.alcf.anl.gov/aurora/getting-started-on-aurora
work page 2026
-
[5]
El Capitan: Preparing for NNSA’s first exascale machine,
Lawrence Livermore National Laboratory, “El Capitan: Preparing for NNSA’s first exascale machine,” 2026, Accessed: April 2026. [Online]. Available: https://asc.llnl.gov/exascale/el-capitan
work page 2026
-
[6]
HPCToolkit: Tools for performance analysis of optimized parallel programs,
L. Adhianto, S. Banerjee, M. Fagan, M. Krentel, G. Marin, J. Mellor-Crummey, and N. R. Tallent, “HPCToolkit: Tools for performance analysis of optimized parallel programs,”Concurrency and Computation: Practice and Experience, vol. 22, no. 6, pp. 685–701,
-
[7]
Available: https://www.doi.org/10.1002/cpe.1553
[Online]. Available: https://www.doi.org/10.1002/cpe.1553
-
[8]
Measurement and analysis of GPU-accelerated applications with HPCToolkit,
K. Zhou, L. Adhianto, J. Anderson, A. Cherian, D. Grubisic, M. Krentel, Y . Liu, X. Meng, and J. Mellor-Crummey, “Measurement and analysis of GPU-accelerated applications with HPCToolkit,” Parallel Computing, vol. 108, p. 102837, 2021. [Online]. Available: https://www.doi.org/10.1016/j.parco.2021.102837
-
[9]
Analyzing the Performance of Applications at Exascale,
D. Grbic and J. Mellor-Crummey, “Analyzing the Performance of Applications at Exascale,” inProceedings of the 39th ACM International Conference on Supercomputing, 2025, pp. 792–806. [Online]. Available: https://www.doi.org/10.1145/3721145.3730417
-
[10]
Thicket: seeing the performance experiment forest for the individual run trees,
S. Brink, M. McKinsey, D. Boehme, C. Scully-Allison, I. Lumsden, D. Hawkins, T. Burgess, V . Lama, J. L ¨uttgau, K. E. Isaacset al., “Thicket: seeing the performance experiment forest for the individual run trees,” inProceedings of the 32nd International Symposium on High- Performance Parallel and Distributed Computing, 2023, pp. 281–293. [Online]. Availa...
-
[11]
NVIDIA Corporation, “NVIDIA Nsight Systems,” 2026, Accessed: April 2026. [Online]. Available: https://developer.nvidia.com/nsight-sys tems
work page 2026
-
[12]
——, “NVIDIA Nsight Compute,” 2026, Accessed: April 2026. [Online]. Available: https://developer.nvidia.com/nsight-compute
work page 2026
-
[13]
Advances in the TAU performance system,
A. Malony, S. Shende, W. Spear, C. W. Lee, and S. Biersdorff, “Advances in the TAU performance system,” inTools for High Performance Computing 2011: Proceedings of the 5th International Workshop on Parallel Tools for High Performance Computing, September 2011, ZIH, Dresden. Springer, 2012, pp. 119–130. [Online]. Available: https://www.doi.org/10.1007/978-...
-
[14]
Score-P: A unified performance measurement system for petascale applications,
D. A. Mey, S. Biersdorf, C. Bischof, K. Diethelm, D. Eschweiler, M. Gerndt, A. Kn ¨upfer, D. Lorenz, A. Malony, W. E. Nagel et al., “Score-P: A unified performance measurement system for petascale applications,” inCompetence in High Performance Computing 2010: Proceedings of an International Conference on Competence in High Performance Computing, June 201...
-
[15]
Caliper: performance introspection for HPC software stacks,
D. Boehme, T. Gamblin, D. Beckingsale, P.-T. Bremer, A. Gimenez, M. LeGendre, O. Pearce, and M. Schulz, “Caliper: performance introspection for HPC software stacks,” inSC’16: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2016, pp. 550–560. [Online]. Available: https://www.doi.org/10.110...
-
[16]
A. Munera, S. Royuela, G. Llort, E. Mercadal, F. Wartel, and E. Qui ˜nones, “Experiences on the characterization of parallel applications in embedded systems with extrae/paraver,” inProceedings of the 49th International Conference on Parallel Processing, 2020, pp. 1–11. [Online]. Available: https://www.doi.org/10.1145/3404397.3404 440
-
[17]
The Scalasca performance toolset architecture,
M. Geimer, F. Wolf, B. J. Wylie, E. ´Abrah´am, D. Becker, and B. Mohr, “The Scalasca performance toolset architecture,”Concurrency and computation: Practice and experience, vol. 22, no. 6, pp. 702–719,
-
[18]
Available: https://www.doi.org/10.1002/cpe.1556
[Online]. Available: https://www.doi.org/10.1002/cpe.1556
-
[19]
Parallel performance engineering using Score-P and Vampir,
W. Williams and H. Brunst, “Parallel performance engineering using Score-P and Vampir,” inCompanion of the 2023 ACM/SPEC International Conference on Performance Engineering, 2023, pp. 121–
work page 2023
-
[20]
Available: https://www.doi.org/10.1145/3578245.3583715
[Online]. Available: https://www.doi.org/10.1145/3578245.3583715
-
[21]
B. J. Wylie, J. Gim ´enez, C. Feld, M. Geimer, G. Llort, S. Mendez, E. Mercadal, A. Visser, and M. Garc ´ıa-Gasulla, “15+ years of joint parallel application performance analysis/tools training with Scalasca/Score-P and Paraver/Extrae toolsets,”Future Generation Computer Systems, vol. 162, p. 107472, 2025. [Online]. Available: https://www.doi.org/10.1016/...
-
[22]
Refining HPCToolkit for application performance analysis at exascale,
L. Adhianto, J. Anderson, R. M. Barnett, D. Grbic, V . Indic, M. Krentel, Y . Liu, S. Milakovi ´c, W. Phan, and J. Mellor- Crummey, “Refining HPCToolkit for application performance analysis at exascale,”The International Journal of High Performance Computing Applications, vol. 38, no. 6, pp. 612–632, 2024. [Online]. Available: https://www.doi.org/10.1177/...
-
[23]
Hatchet: Pruning the overgrowth in parallel profiles,
A. Bhatele, S. Brink, and T. Gamblin, “Hatchet: Pruning the overgrowth in parallel profiles,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2019, pp. 1–21. [Online]. Available: https://www.doi.org/10.1145/3295 500.3356219
-
[24]
Python data analysis with pandas,
J. Bernard, “Python data analysis with pandas,” inPython recipes handbook: A problem-solution approach. Springer, 2016, pp. 37–48. [Online]. Available: https://www.doi.org/10.1007/978-1-4842-0241-8 5
-
[25]
Pipit: Scripting the analysis of parallel execution traces,
A. Bhatele, R. Dhakal, A. Movsesyan, A. K. Ranjan, and O. Cankur, “Pipit: Scripting the analysis of parallel execution traces,”arXiv preprint arXiv:2306.11177, 2023. [Online]. Available: https://www.doi. org/10.48550/arXiv.2306.11177
-
[26]
Scaling applications to massively parallel machines using projections performance analysis tool,
L. V . Kale, G. Zheng, C. W. Lee, and S. Kumar, “Scaling applications to massively parallel machines using projections performance analysis tool,”Future Generation Computer Systems, vol. 22, no. 3, pp. 347–358, 2006. [Online]. Available: https://www.doi.org/10.1016/j.futu re.2004.11.020
-
[27]
Introducing the open trace format (OTF),
A. Kn ¨upfer, R. Brendel, H. Brunst, H. Mix, and W. E. Nagel, “Introducing the open trace format (OTF),” inInternational Conference on Computational Science. Springer, 2006, pp. 526–533. [Online]. Available: https://www.doi.org/10.1007/11758525 71
-
[28]
Preparing for performance analysis at exascale,
J. Anderson, Y . Liu, and J. Mellor-Crummey, “Preparing for performance analysis at exascale,” inProceedings of the 36th ACM International Conference on Supercomputing, 2022, pp. 1–13. [Online]. Available: https://www.doi.org/10.1145/3524059.3532397
-
[29]
Project Jupyter: Interactive Computing across Programming Languages,
Project Jupyter, “Project Jupyter: Interactive Computing across Programming Languages,” 2026, Accessed: April 2026. [Online]. Available: https://jupyter.org
work page 2026
-
[30]
A. P. Thompson, H. M. Aktulga, R. Berger, D. S. Bolintineanu, W. M. Brown, P. S. Crozier, P. J. In’t Veld, A. Kohlmeyer, S. G. Moore, T. D. Nguyenet al., “LAMMPS-a flexible simulation tool for particle-based materials modeling at the atomic, meso, and continuum scales,”Computer physics communications, vol. 271, p. 108171, 2022. [Online]. Available: https:...
-
[31]
Linux Man-Pages Project, “mmap(2) — Linux Manual Page,” 2026, Accessed: April 2026. [Online]. Available: https://man7.org/linux/man -pages/man2/mmap.2.html
work page 2026
-
[32]
Joblib: Running Python Functions as Pipeline Jobs,
Joblib Development Team, “Joblib: Running Python Functions as Pipeline Jobs,” 2026, Accessed: April 2026. [Online]. Available: https://joblib.readthedocs.io
work page 2026
-
[33]
pybind11: Seamless Operability Between C++11 and Python,
pybind11 Development Team, “pybind11: Seamless Operability Between C++11 and Python,” 2026, Accessed: April 2026. [Online]. Available: https://pybind11.readthedocs.io
work page 2026
-
[34]
C. R. Harris, K. J. Millman, S. J. Van Der Walt, R. Gommers, P. Virtanen, D. Cournapeau, E. Wieser, J. Taylor, S. Berg, N. J. Smithet al., “Array programming with NumPy,”nature, vol. 585, no. 7825, pp. 357–362, 2020. [Online]. Available: https://www.doi.org/10.1038/s41586-020-2649-2
-
[35]
cuDF: GPU-Accelerated Pandas-like DataFrames,
RAPIDS Development Team, “cuDF: GPU-Accelerated Pandas-like DataFrames,” 2026, Accessed: April 2026. [Online]. Available: https://docs.rapids.ai/api/cudf/stable
work page 2026
-
[36]
hipDF: HIP-based DataFrames for AMD GPUs,
AMD ROCm Development Team, “hipDF: HIP-based DataFrames for AMD GPUs,” 2026, Accessed: April 2026. [Online]. Available: https://rocm.docs.amd.com/projects/hipDF/en/latest
work page 2026
-
[37]
dpnp: NumPy-compliant Interface for Data Parallel C++ (DPC++),
Intel oneAPI Development Team, “dpnp: NumPy-compliant Interface for Data Parallel C++ (DPC++),” 2026, Accessed: April 2026. [Online]. Available: https://intelpython.github.io/dpnp
work page 2026
-
[38]
AMG: Algebraic Multi-Grid Parallel Iterative Solver Benchmark,
Lawrence Livermore National Laboratory, “AMG: Algebraic Multi-Grid Parallel Iterative Solver Benchmark,” 2026, Accessed: April 2026. [Online]. Available: https://www.osti.gov/biblio/1389816
- [39]
-
[40]
——, “Polaris User Guide,” 2026, Accessed: April 2026. [Online]. Available: https://docs.alcf.anl.gov/polaris/getting-started
work page 2026
-
[41]
NVIDIA Corporation, “NVIDIA CUDA Toolkit,” 2026, accessed: April
work page 2026
-
[42]
Available: https://developer.nvidia.com/cuda-toolkit
[Online]. Available: https://developer.nvidia.com/cuda-toolkit
-
[43]
ROCm: Open Software Platform for GPU Compute,
Advanced Micro Devices, Inc., “ROCm: Open Software Platform for GPU Compute,” 2026, accessed: April 2026. [Online]. Available: https://rocm.docs.amd.com
work page 2026
-
[44]
Intel Corporation, “Intel oneAPI Toolkits,” 2026, accessed: April 2026. [Online]. Available: https://www.intel.com/content/www/us/en/develope r/tools/oneapi/overview.html
work page 2026
-
[45]
Intel oneAPI Level Zero Specification,
——, “Intel oneAPI Level Zero Specification,” 2026, accessed: April
work page 2026
-
[46]
Available: https://oneapi-src.github.io/level-zero-spec
[Online]. Available: https://oneapi-src.github.io/level-zero-spec
-
[47]
Recent developments in the general atomic and molecular electronic structure system,
G. M. Barca, C. Bertoni, L. Carrington, D. Datta, N. De Silva, J. E. Deustua, D. G. Fedorov, J. R. Gour, A. O. Gunina, E. Guidezet al., “Recent developments in the general atomic and molecular electronic structure system,”The Journal of chemical physics, vol. 152, no. 15,
-
[48]
Recent developments in the general atomic and molecular electronic structure system,
[Online]. Available: https://www.doi.org/10.1063/5.0005188
-
[49]
DBSCAN clustering algorithm based on density,
D. Deng, “DBSCAN clustering algorithm based on density,” in2020 7th international forum on electrical engineering and automation (IFEEA). IEEE, 2020, pp. 949–953. [Online]. Available: https: //www.doi.org/10.1109/IFEEA51475.2020.00199
-
[50]
Unsupervised K-means clustering algorithm,
K. P. Sinaga and M.-S. Yang, “Unsupervised K-means clustering algorithm,”IEEE access, vol. 8, pp. 80 716–80 727, 2020. [Online]. Available: https://www.doi.org/10.1109/ACCESS.2020.2988796
-
[51]
Generalized Slow Roll for Tensors
D. De Sensi, S. Di Girolamo, K. H. McMahon, D. Roweth, and T. Hoefler, “An in-depth analysis of the slingshot interconnect,” in SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2020, pp. 1–14. [Online]. Available: https://www.doi.org/10.1109/SC41405.2020.00039
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/sc41405.2020.00039 2020
-
[52]
Argonne Leadership Computing Facility, “Running Jobs on Aurora,” 2026, Accessed: April 2026. [Online]. Available: https://docs.alcf.anl. gov/aurora/running-jobs-aurora
work page 2026
-
[53]
T. H. Project, “hpcanalysis,” https://gitlab.com/draganaurosgrbic/hpcana lysis, 2026
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.