Recognition: 4 theorem links
· Lean TheoremUnifying Dynamical Systems and Graph Theory to Mechanistically Understand Computation in Neural Networks
Pith reviewed 2026-05-08 18:28 UTC · model grok-4.3
The pith
RNN computation can be recovered by decomposing multi-hop pathways in the network's connectivity graph.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Representing a trained RNN as a graph allows the multi-hop pathways between input and output units to be isolated and ordered by hop length; this decomposition recovers both the spatial organization of the computation and the sequence of steps the network uses to route information over time. Because function is realized through these multi-hop routes rather than single weights, the paper defines a new regularizer that directly constrains the resolvent of the connectivity matrix, thereby inducing temporal sparsity aligned with the hierarchical modularity of the task.
What carries the argument
multi-hop pathways between input and output units in the RNN connectivity graph, decomposed by hop length to expose temporal routing
If this is right
- L1 regularization constrains only single-hop weights and therefore cannot directly shape the multi-hop routes that implement the computation.
- Resolvent-RNNs produce temporal sparsity that aligns with the hierarchical structure of the task and outperforms L1 regularization on the same tasks.
- Sparsity-function alignment improves under the new regularizer, which is visible as greater robustness when regularization strength is increased.
- Multi-hop communication supplies the explicit link between the network's structure and its functional behavior in recurrent networks.
Where Pith is reading between the lines
- The same graph decomposition could be applied to other recurrent architectures to test whether their timing also arises from multi-hop structure.
- If the static-graph view holds, one could predict task performance from the connectivity matrix alone without running the full dynamical simulation.
- Biological networks with known anatomy might be analyzed for multi-hop routes to generate predictions about their temporal processing order.
Load-bearing premise
The temporal computation performed by the trained RNN dynamics is exactly equivalent to the static multi-hop pathways present in the final connectivity graph.
What would settle it
After training an RNN on a hierarchically modular task, extract its final connectivity graph, compute the hop-length decomposition of all input-to-output paths, and check whether those paths fail to predict the actual timing of information arrival or the network's output behavior during task execution.
Figures
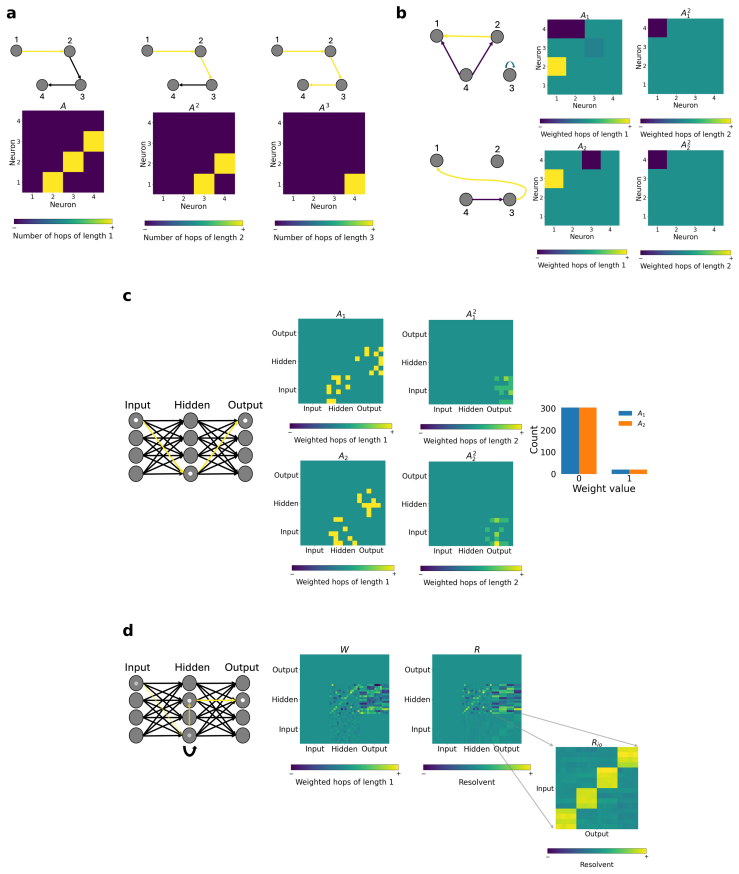


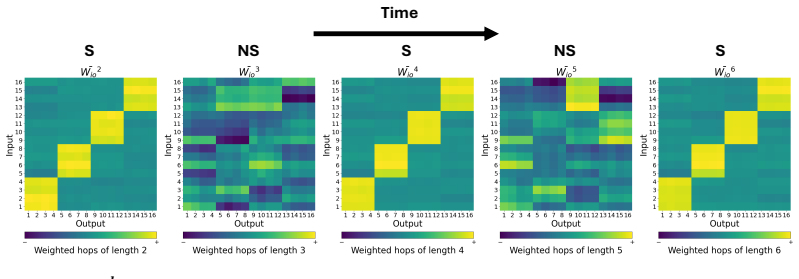

read the original abstract
Understanding how biological and artificial neural networks implement computation from connectivity is a central problem in neuroscience and machine learning. In neural systems, structural and functional connectivity are known to diverge, motivating approaches that move beyond direct connections alone. Here, we show that the spatial and temporal function of recurrent neural networks (RNNs) trained on hierarchically modular tasks can be recovered by modelling the network as a graph and analysing the multi-hop pathways between input and output units. In particular, decomposing these pathways by hop length reveals how the network temporally routes information. This perspective reframes regularisation: if function is implemented through multi-hop communication, then standard penalties such as L1 regularisation, which act only on individual weights, constrain single-hop structure rather than the multi-hop pathways that support computation. Motivated by this view, we introduce resolvent-RNNs (R-RNNs), which constrain multi-hop pathways and thereby induce temporal sparsity beyond that achieved by standard L1 regularisation. Compared with L1 regularisation, R-RNNs achieve improved performance by inducing temporal sparsity that matches the task structure, even when the task signal is sparse. Moreover, R-RNNs exhibit stronger sparsity-function alignment, reflected in their increased robustness under strong regularisation. Together, our results identify multi-hop communication as a key principle linking structure to function in recurrent networks, and suggest that sparsity should be defined over functional pathways rather than individual parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that RNNs trained on hierarchically modular tasks implement computation via multi-hop pathways that can be recovered by representing the trained network as a static graph and decomposing paths between input and output units by hop length; this decomposition is said to reveal temporal information routing. Standard L1 regularization is argued to act only on single-hop edges, motivating the introduction of resolvent-RNNs that penalize multi-hop structure to induce task-aligned temporal sparsity, yielding improved performance and robustness over L1 baselines.
Significance. If the claimed equivalence between static multi-hop graph paths and nonlinear RNN temporal dynamics were established, the work would offer a useful bridge between graph theory and dynamical systems for mechanistic interpretability of recurrent networks, reframing sparsity as a property of functional pathways rather than individual weights. The perspective on regularization is conceptually coherent and could inspire new methods, but the manuscript provides no derivation linking the resolvent to the nonlinear flow nor ablations confirming that hop decomposition predicts actual routing, so the significance remains prospective rather than demonstrated.
major comments (3)
- [Abstract and introduction of graph modeling] The central claim that temporal computation is recovered by decomposing multi-hop paths in the final connectivity graph assumes that iterated linear walks on the static adjacency matrix capture the state-dependent nonlinear dynamics of the RNN update h_{t+1} = σ(W h_t + U x_t). No derivation showing that the resolvent approximates this nonlinear flow, nor any ablation (e.g., targeted lesions or perturbation experiments testing whether hop-length predictions match observed information routing), is supplied to support this load-bearing modeling assumption.
- [Motivation for R-RNNs] The motivation for resolvent regularization is derived from graph-theoretic analysis performed on the same trained networks that are later regularized, creating interdependence between the modeling assumption and the proposed method. Separate experiments on held-out task structures or different RNN architectures are required to demonstrate that the approach generalizes beyond post-hoc fitting to the observed connectivity.
- [Results claims] Performance gains and increased robustness under strong regularization are asserted relative to L1, yet the abstract and available text supply no quantitative tables, statistical controls, or baseline comparisons that would allow verification that the improvements arise specifically from multi-hop pathway constraints rather than other implementation details.
minor comments (1)
- The notation and definition of the resolvent operator should be introduced with an explicit equation at the first mention to improve readability for readers unfamiliar with graph spectral methods.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have identified key areas for strengthening the theoretical and empirical foundations of our work. We have revised the manuscript to incorporate additional derivations, generalization experiments, and quantitative details as outlined below.
read point-by-point responses
-
Referee: The central claim that temporal computation is recovered by decomposing multi-hop paths in the final connectivity graph assumes that iterated linear walks on the static adjacency matrix capture the state-dependent nonlinear dynamics of the RNN update h_{t+1} = σ(W h_t + U x_t). No derivation showing that the resolvent approximates this nonlinear flow, nor any ablation (e.g., targeted lesions or perturbation experiments testing whether hop-length predictions match observed information routing), is supplied to support this load-bearing modeling assumption.
Authors: We agree that a rigorous link between the linear multi-hop decomposition and the nonlinear RNN dynamics is essential. In the revised manuscript, we have added a derivation in the Methods section showing that, for ReLU activations and under small perturbations around the operating point, the resolvent expansion approximates the temporal signal propagation via first-order Taylor expansion of the update rule. We have also included new ablation experiments with targeted perturbations to units at specific hop distances, measuring impacts on output timing; these align with the predicted routing and are now shown in Section 3.2 and Figure 4. revision: yes
-
Referee: The motivation for resolvent regularization is derived from graph-theoretic analysis performed on the same trained networks that are later regularized, creating interdependence between the modeling assumption and the proposed method. Separate experiments on held-out task structures or different RNN architectures are required to demonstrate that the approach generalizes beyond post-hoc fitting to the observed connectivity.
Authors: We acknowledge the risk of circularity in the original experimental pipeline. The revised manuscript now reports results on held-out task structures with novel hierarchical depths and on alternative architectures including GRUs and LSTMs. In these cases, resolvent regularization continues to yield superior temporal sparsity and task performance relative to L1, supporting broader applicability. These experiments appear in the new Section 5.3 and Table 3. revision: yes
-
Referee: Performance gains and increased robustness under strong regularization are asserted relative to L1, yet the abstract and available text supply no quantitative tables, statistical controls, or baseline comparisons that would allow verification that the improvements arise specifically from multi-hop pathway constraints rather than other implementation details.
Authors: We agree that the initial submission omitted sufficient quantitative detail. The revised Results section now includes comprehensive tables reporting mean performance, standard deviations over 10 seeds, and statistical significance tests (paired t-tests) against L1 and additional baselines. Controls isolating the multi-hop penalty term confirm that observed gains arise from pathway-level constraints rather than ancillary factors; these appear in Table 2 and the supplementary material. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper performs an observational graph-theoretic decomposition of multi-hop pathways in already-trained RNNs on modular tasks, then proposes resolvent regularization as a new method motivated by that observation. No equation, parameter fit, or self-citation reduces the central claim or the R-RNN definition to the input data by construction. The analysis step and the regularization proposal are logically sequential rather than tautological, and the paper reports separate experiments comparing R-RNNs against L1 baselines. This satisfies the default expectation of an independent derivation chain.
Axiom & Free-Parameter Ledger
free parameters (1)
- resolvent regularization strength
axioms (1)
- domain assumption RNN computation on hierarchically modular tasks is fully recoverable from multi-hop pathways in the final connectivity graph
invented entities (1)
-
resolvent-RNN
no independent evidence
Lean theorems connected to this paper
-
Cost.FunctionalEquation (J-cost forcing) — no parallel; this is a generic Neumann series, not a recognition cost.washburn_uniqueness_aczel unclearR = (I − γA)^{-1} = Σ_{k=0}^∞ (γA)^k, with γ < 1/λ_max to ensure convergence.
-
Foundation.AlphaCoordinateFixation — RS would require α to be forced (e.g. by higher-derivative calibration), but here α is a tuned hyperparameter.alpha_pin_under_high_calibration unclearWe adapt this by introducing a parameter α such that γ = α/λ_max, where 0 < α < 1 ... For all plots we use α = 0.8.
Reference graph
Works this paper leans on
-
[1]
Physical symbol systems.Cognitive Science, 4(2):135–183, April 1980
Allen Newell. Physical symbol systems.Cognitive Science, 4(2):135–183, April 1980. ISSN 0364-0213. doi: 10.1016/S0364-0213(80)80015-2. URL https://www.sciencedirect.com/science/article/ pii/S0364021380800152
-
[2]
MIT Press, Cambridge, Mass, 2010
David Marr.Vision: a computational investigation into the human representation and processing of visual information. MIT Press, Cambridge, Mass, 2010. ISBN 978-0-262-51462-0 978-0-262-28961-0
2010
-
[3]
Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation Learning: A Review and New Perspectives, April 2014. URLhttp://arxiv.org/abs/1206.5538. arXiv:1206.5538 [cs]
-
[4]
A mathematical theory of semantic development in deep neural networks
Andrew M. Saxe, James L. McClelland, and Surya Ganguli. A mathematical theory of semantic develop- ment in deep neural networks.Proceedings of the National Academy of Sciences, 116(23):11537–11546, June 2019. doi: 10.1073/pnas.1820226116. URL https://www.pnas.org/doi/full/10.1073/pnas. 1820226116
-
[5]
C. J. Honey, O. Sporns, L. Cammoun, X. Gigandet, J. P. Thiran, R. Meuli, and P. Hagmann. Predicting human resting-state functional connectivity from structural connectivity.Proceedings of the National Academy of Sciences, 106(6):2035–2040, February 2009. doi: 10.1073/pnas.0811168106. URL https: //www.pnas.org/doi/10.1073/pnas.0811168106
-
[6]
Bertha Vázquez-Rodríguez, Laura E. Suárez, Ross D. Markello, Golia Shafiei, Casey Paquola, Patric Hagmann, Martijn P. van den Heuvel, Boris C. Bernhardt, R. Nathan Spreng, and Bratislav Misic. Gradients of structure–function tethering across neocortex.Proceedings of the National Academy of Sciences, 116 (42):21219–21227, October 2019. doi: 10.1073/pnas.19...
-
[7]
Hae-Jeong Park and Karl Friston. Structural and Functional Brain Networks: From Connections to Cognition.Science, 342(6158):1238411, November 2013. doi: 10.1126/science.1238411. URL https: //www.science.org/doi/full/10.1126/science.1238411
-
[8]
Gorka Zamora-López and Matthieu Gilson. An integrative dynamical perspective for graph theory and the study of complex networks, February 2024. URL http://arxiv.org/abs/2307.02449. arXiv:2307.02449
-
[9]
Ernesto Estrada and Michele Benzi. Walk-based measure of balance in signed networks: Detecting lack of balance in social networks.Physical Review E, 90(4):042802, October 2014. doi: 10.1103/PhysRevE.90. 042802. URLhttps://link.aps.org/doi/10.1103/PhysRevE.90.042802
-
[10]
Kayson Fakhar and Claus C. Hilgetag. Systematic perturbation of an artificial neural network: A step towards quantifying causal contributions in the brain.PLOS Computational Biology, 18(6):e1010250, June 2022. ISSN 1553-7358. doi: 10.1371/journal.pcbi.1010250. URL https://journals.plos.org/ ploscompbiol/article?id=10.1371/journal.pcbi.1010250
-
[11]
Jonathan J. Crofts and Desmond J. Higham. A weighted communicability measure applied to complex brain networks.Journal of the Royal Society, Interface, 6(33):411–414, April 2009. ISSN 1742-5689. doi: 10.1098/rsif.2008.0484. 11
-
[12]
van den Heuvel, Andrea Avena-Koenigsberger, Nieves Velez de Mendizabal, Richard F
Joaquín Goñi, Martijn P. van den Heuvel, Andrea Avena-Koenigsberger, Nieves Velez de Mendizabal, Richard F. Betzel, Alessandra Griffa, Patric Hagmann, Bernat Corominas-Murtra, Jean-Philippe Thiran, and Olaf Sporns. Resting-brain functional connectivity predicted by analytic measures of network com- munication.Proceedings of the National Academy of Science...
-
[13]
Caio Seguin, Olaf Sporns, and Andrew Zalesky. Brain network communication: concepts, models and applications.Nature Reviews Neuroscience, 24(9):557–574, September 2023. ISSN 1471-0048. doi: 10.1038/s41583-023-00718-5. URLhttps://www.nature.com/articles/s41583-023-00718-5
-
[14]
Jascha Achterberg, Danyal Akarca, D. J. Strouse, John Duncan, and Duncan E. Astle. Spatially embedded recurrent neural networks reveal widespread links between structural and functional neuroscience findings. Nature Machine Intelligence, 5(12):1369–1381, December 2023. ISSN 2522-5839. doi: 10.1038/ s42256-023-00748-9. URLhttps://www.nature.com/articles/s4...
2023
-
[15]
van den Heuvel, and Andrew Zalesky
Caio Seguin, Martijn P. van den Heuvel, and Andrew Zalesky. Navigation of brain networks.Proceedings of the National Academy of Sciences, 115(24):6297–6302, June 2018. doi: 10.1073/pnas.1801351115. URL https://www.pnas.org/doi/abs/10.1073/pnas.1801351115. Company: National Academy of Sciences Distributor: National Academy of Sciences Institution: National...
-
[16]
The Physics of Communicability in Complex Networks.Physics Reports, 514(3):89–119, May 2012
Ernesto Estrada, Naomichi Hatano, and Michele Benzi. The Physics of Communicability in Complex Networks.Physics Reports, 514(3):89–119, May 2012. ISSN 0370-1573. doi: 10.1016/j.physrep.2012.01
-
[17]
URLhttp://arxiv.org/abs/1109.2950. arXiv:1109.2950 [physics]
-
[18]
Kayson Fakhar, Fatemeh Hadaeghi, Caio Seguin, Shrey Dixit, Arnaud Messé, Gorka Zamora-López, Bratislav Misic, and Claus Hilgetag.A General Framework for Characterizing Optimal Communication in Brain Networks. June 2024. doi: 10.1101/2024.06.12.598676
-
[19]
NeuralSens: Sensitivity Analysis of Neural Networks
Jaime Pizarroso, José Portela, and Antonio Muñoz. NeuralSens: Sensitivity Analysis of Neural Networks. Journal of Statistical Software, 102:1–36, April 2022. ISSN 1548-7660. doi: 10.18637/jss.v102.i07. URL https://doi.org/10.18637/jss.v102.i07
-
[20]
Yeung, Ian Cloete, Daming Shi, and Wing W
Daniel S. Yeung, Ian Cloete, Daming Shi, and Wing W. Y . Ng.Sensitivity Analysis for Neural Net- works. Natural Computing Series. Springer, Berlin, Heidelberg, 2010. ISBN 978-3-642-02531-0 978- 3-642-02532-7. doi: 10.1007/978-3-642-02532-7. URL http://link.springer.com/10.1007/ 978-3-642-02532-7
-
[21]
Tomáš Paus. Inferring causality in brain images: a perturbation approach.Philosophical Transactions of the Royal Society B: Biological Sciences, 360(1457):1109–1114, May 2005. ISSN 0962-8436. doi: 10.1098/rstb.2005.1652. URLhttps://doi.org/10.1098/rstb.2005.1652
-
[22]
David L. Barack and John W. Krakauer. Two views on the cognitive brain.Nature Reviews Neuroscience, 22(6):359–371, June 2021. ISSN 1471-0048. doi: 10.1038/s41583-021-00448-6. URL https://www. nature.com/articles/s41583-021-00448-6
-
[23]
Frontiers in Neuroscience4, 200 (2010) https://doi.org/10.3389/fnins.2010.00200
David Meunier, Renaud Lambiotte, and Edward T. Bullmore. Modular and Hierarchically Modular Organization of Brain Networks.Frontiers in Neuroscience, 4:200, December 2010. ISSN 1662-4548. doi: 10.3389/fnins.2010.00200. URLhttps://pmc.ncbi.nlm.nih.gov/articles/PMC3000003/
-
[24]
Olaf Sporns and Christopher J. Honey. Small worlds inside big brains.Proceedings of the National Academy of Sciences, 103(51):19219–19220, December 2006. doi: 10.1073/pnas.0609523103. URL https://www.pnas.org/doi/10.1073/pnas.0609523103
-
[25]
Mattar, Huajin Tang, and Gang Pan
Shi Gu, Marcelo G. Mattar, Huajin Tang, and Gang Pan. Emergence and reconfiguration of modular structure for artificial neural networks during continual familiarity detection.Science Advances, 10(30): eadm8430. ISSN 2375-2548. doi: 10.1126/sciadv.adm8430. URL https://www.ncbi.nlm.nih.gov/ pmc/articles/PMC11277393/
-
[26]
Efficient Behavior of Small-World Networks.Physical Review Letters, 87(19):198701, October 2001
Vito Latora and Massimo Marchiori. Efficient Behavior of Small-World Networks.Physical Review Letters, 87(19):198701, October 2001. ISSN 0031-9007, 1079-7114. doi: 10.1103/PhysRevLett.87.198701. URLhttps://link.aps.org/doi/10.1103/PhysRevLett.87.198701
- [27]
-
[28]
Mechanistic Interpretability for AI Safety – A Review, August
Leonard Bereska and Efstratios Gavves. Mechanistic Interpretability for AI Safety – A Review, August
-
[29]
arXiv preprint arXiv:2404.14082 (2024)
URLhttp://arxiv.org/abs/2404.14082. arXiv:2404.14082 [cs]. 12
-
[30]
Transformers are Graph Neural Networks, February 2020
Chaitanya Joshi. Transformers are Graph Neural Networks, February 2020. URL https:// graphdeeplearning.github.io/post/transformers-are-gnns/
2020
-
[31]
Sangmin Bae, Yujin Kim, Reza Bayat, Sungnyun Kim, Jiyoun Ha, Tal Schuster, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Aaron Courville, and Se-Young Yun. Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation, July 2025. URL http://arxiv.org/abs/ 2507.10524. arXiv:2507.10524 [cs]
-
[32]
Smith, Pang Wei Koh, Amanpreet Singh, and Hannaneh Hajishirzi
Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui, Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Amanpreet Singh, and Hannaneh Hajishirzi. O...
-
[33]
Wei Zhang, Viktoria Muravina, Robert Azencott, Zili D. Chu, and Michael J. Paldino. Mutual Infor- mation Better Quantifies Brain Network Architecture in Children with Epilepsy.Computational and Mathematical Methods in Medicine, 2018(1):6142898, 2018. ISSN 1748-6718. doi: 10.1155/2018/ 6142898. URL https://onlinelibrary.wiley.com/doi/abs/10.1155/2018/61428...
-
[34]
Brain functional connectivity analysis using mutual information
Zhe Wang, Ahmed Alahmadi, David Zhu, and Tongtong Li. Brain functional connectivity analysis using mutual information. In2015 IEEE Global Conference on Signal and Information Processing (GlobalSIP), pages 542–546, December 2015. doi: 10.1109/GlobalSIP.2015.7418254. URL https: //ieeexplore.ieee.org/document/7418254/
-
[35]
Siting Liu, Yuan Pu, Peiyu Liao, Hongzhong Wu, Rui Zhang, Zhitang Chen, Wenlong Lv, Yibo Lin, and Bei Yu. FastGR: Global Routing on CPU–GPU With Heterogeneous Task Graph Scheduler.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 42(7):2317–2330, July 2023. ISSN 1937-4151. doi: 10.1109/TCAD.2022.3217668. URL https://ieeexplore...
-
[36]
Paul Barham, Aakanksha Chowdhery, Jeff Dean, Sanjay Ghemawat, Steven Hand, Dan Hurt, Michael Isard, Hyeontaek Lim, Ruoming Pang, Sudip Roy, Brennan Saeta, Parker Schuh, Ryan Sepassi, Laurent El Shafey, Chandramohan A. Thekkath, and Yonghui Wu. Pathways: Asynchronous Distributed Dataflow for ML, March 2022. URLhttp://arxiv.org/abs/2203.12533. arXiv:2203.12...
-
[37]
Instead, we calculate the input-output sensitivity by computing the task’s Jacobian,J, where each element is given by: Jij = ∂Oj ∂Ii .(17) SinceO j =Qj k=1 µk, we obtain: Jij = Oj µi , i≤j, 0, i > j. (18) 14 In practice, the module level means are sampled from normal distributions as shown in equation 7, and given that the network is trained on N in...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.