Most ReLU Networks Admit Identifiable Parameters
Pith reviewed 2026-05-21 08:26 UTC · model grok-4.3
The pith
For ReLU networks with input and hidden layers of width at least two, an open set of parameters are identifiable from the realized function up to scaling and permutation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The realization map of a ReLU network is generically injective up to scaling and permutation of hidden neurons whenever every layer has width at least two. Consequently the functional dimension equals the total number of parameters minus the total number of hidden neurons, and the set of parameters that realize a given function is discrete outside the standard symmetries.
What carries the argument
Weighted polyhedral complexes that encode the arrangement of linear regions, their bounding hyperplanes, and the linear coefficients on each region, thereby exposing hidden parameter redundancies beyond scaling and permutation.
If this is right
- The functional dimension of every such architecture equals the number of parameters minus the number of hidden neurons.
- Even a minimal functional representation can still possess non-trivial parameter redundancies.
- For an open dense set of parameters the realized function cannot be matched by any shallower network.
Where Pith is reading between the lines
- Training dynamics may converge to isolated points in parameter space once scaling and permutation are quotiented out.
- The polyhedral-complex description could be used to count the number of distinct linear regions realized by a generic network.
- The same counting argument might apply to other piecewise-linear activations that induce polyhedral partitions.
Load-bearing premise
The weighted polyhedral complex framework captures every possible hidden redundancy that could make parameters non-identifiable beyond scaling and permutation.
What would settle it
Exhibit a concrete ReLU network with all widths at least two together with a positive-measure open set of parameters inside which two distinct (non-scaling, non-permutation) parameter vectors realize identical functions.
Figures










read the original abstract
We study the realization map of deep ReLU networks, focusing on when a function determines its parameters up to scaling and permutation. To analyze hidden redundancies beyond these standard symmetries, we introduce a framework based on weighted polyhedral complexes. Our main result shows that for every architecture whose input and hidden layers have width at least two, there exists an open set of identifiable parameters. This implies that the functional dimension of every such architecture is exactly the number of parameters minus the number of hidden neurons. We further show that minimal functional representations can still have non-trivial parameter redundancies. Finally, we establish a generic depth hierarchy, whereby for an open set of parameters the realized function cannot be represented generically by any shallower network.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the realization map of deep ReLU networks, introducing a weighted polyhedral complex framework to detect hidden redundancies beyond per-neuron scaling and discrete permutation symmetries. The central claim is that for every architecture with input dimension and all hidden-layer widths at least 2, there exists a nonempty open set of identifiable parameters; consequently the functional dimension equals the total parameter count minus the number of hidden neurons. Additional results establish that minimal functional representations may retain non-trivial redundancies and that, generically, the realized function cannot be expressed by any shallower network.
Significance. If the main existence result holds, the work supplies a sharp geometric characterization of the identifiability locus for ReLU networks and a precise formula for functional dimension. The weighted-polyhedral-complex construction is a novel tool that could be useful for analyzing other piecewise-linear architectures; the generic depth-hierarchy statement also strengthens the literature on expressivity across depths.
major comments (1)
- [Main-result section] Main-result section (proof of the open-set claim): the argument that the weighted polyhedral complex exhausts all continuous redundancies is load-bearing. A concrete verification is needed that no additional continuous equivalences (for example, layer-wise weight redistributions that preserve the piecewise-linear map on a positive-measure set of activation patterns) can occur when all widths are at least 2; without this, the claimed open set of identifiable parameters could be empty.
minor comments (1)
- [Abstract] The abstract states that minimal functional representations 'can still have non-trivial parameter redundancies' but gives no concrete example; adding a low-dimensional illustration would clarify the distinction between functional and parametric minimality.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive report. The single major comment raises a valid point about the completeness of our argument that the weighted polyhedral complex captures all continuous redundancies. We address it below and indicate the revision we will make.
read point-by-point responses
-
Referee: [Main-result section] Main-result section (proof of the open-set claim): the argument that the weighted polyhedral complex exhausts all continuous redundancies is load-bearing. A concrete verification is needed that no additional continuous equivalences (for example, layer-wise weight redistributions that preserve the piecewise-linear map on a positive-measure set of activation patterns) can occur when all widths are at least 2; without this, the claimed open set of identifiable parameters could be empty.
Authors: We appreciate the referee highlighting the need for explicit verification that the weighted polyhedral complex rules out additional continuous equivalences. In the proof of the main theorem, the complex is constructed from the full collection of activation patterns and the associated affine maps on each polyhedral region; any continuous redundancy must map this complex to itself. Layer-wise redistributions that preserve the overall piecewise-linear function on a positive-measure set would have to preserve both the hyperplane arrangement and the linear coefficients on each chamber. When every hidden width is at least 2, the only transformations that achieve this are the standard per-neuron scalings (which are already quotiented out) and discrete permutations. We agree that this implication is not spelled out as explicitly as it could be and will add a short clarifying paragraph (or small lemma) in the revised main-result section that directly rules out non-trivial layer-wise redistributions for widths >=2, thereby confirming that the open set of identifiable parameters is nonempty. revision: partial
Circularity Check
No circularity: existence proof via new geometric framework
full rationale
The paper's derivation is a self-contained mathematical existence proof. It introduces the weighted polyhedral complex framework to characterize redundancies in the realization map of ReLU networks beyond scaling and permutation symmetries, then proves that for architectures with input and hidden widths at least 2 there exists a nonempty open set of parameters identifiable up to those symmetries. This directly yields the functional-dimension formula as #parameters minus #hidden neurons. No step reduces a claimed prediction or theorem to a fitted quantity, a self-referential definition, or a load-bearing self-citation whose validity depends on the present result; the framework and its properties are developed and applied within the paper itself as independent mathematical content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The realization map of a ReLU network can be faithfully represented by a weighted polyhedral complex that encodes all linear regions and their weights.
invented entities (1)
-
weighted polyhedral complex
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a framework based on weighted polyhedral complexes... tropical weight cf(σ) := (AP − AQ)eP/σ
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalphaCoordinateFixationCert unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
functional dimension ... exactly the number of parameters minus the number of hidden neurons
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Simone Bombari, Mohammad Hossein Amani, and Marco Mondelli
URL https://proceedings.mlr.press/v139/nguyen21g.html. Simone Bombari, Mohammad Hossein Amani, and Marco Mondelli. Memorization and optimization in deep neural networks with minimum over-parameterization. In Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=x8DNliTBSYY. Andrea Montanari and Yiqiao Zhong. The inte...
work page 2022
-
[2]
URL http://proceedings.mlr.press/v49/eldan16.html
PMLR. URL http://proceedings.mlr.press/v49/eldan16.html. Matus Telgarsky. benefits of depth in neural networks. In 29th Annual Conference on Learning Theory , volume 49 of Proceedings of Machine Learning Research , pages 1517–1539, Columbia University, New York, New York, USA, 2016. PMLR. URL https://proceedings.mlr.press/v49/telgarsky16.html. Hrushikesh ...
-
[3]
URL https://arxiv.org/abs/2601.01417. 37 A Remarks on Previous Identifiability Results and Constructions This appendix clarifies two points relevant to comparison with prior work: first, the distinction between uniqueness within restricted parameter classes and identifiability in the full parameter space; second, the way in which our construction differs ...
-
[4]
among all parameters η,
-
[5]
among all generic parameters η, or
-
[6]
These are progressively weaker notions of uniqueness and should not be conflated
only among parameters η belonging to some restricted class, for example parameters satisfying geo- metric conditions such as TPIC and LRA. These are progressively weaker notions of uniqueness and should not be conflated. In this hierarchy, the result of Rolnick and Kording (2020) is of the third type, being formulated on a restricted class of parameters s...
work page 2020
- [8]
-
[9]
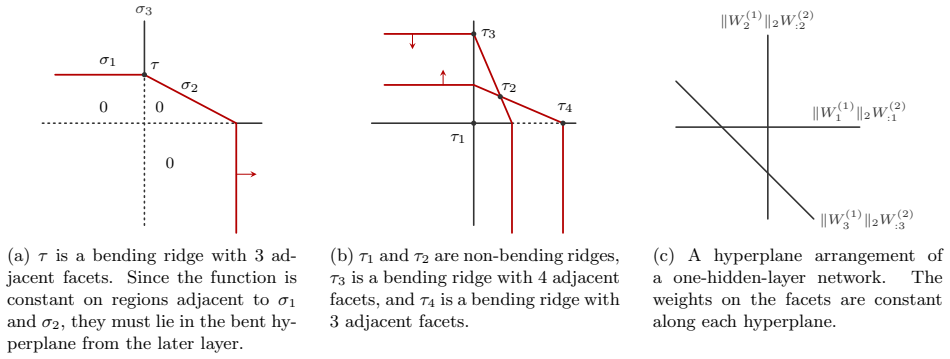
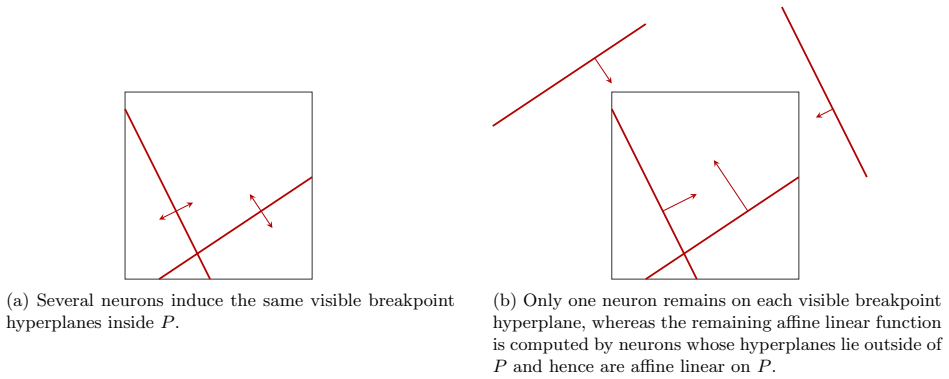
the remaining k neurons have breakpoint hyperplanes disjoint from P . Proof. Group the neurons of f according to the visible hyperplane they induce in relint( P ). For each j ∈ [n], let Ij be the set of neurons whose breakpoint hyperplane in relint( P ) is Hj, and let K be the set of neurons whose nonzero locus does not appear as breakpoint of the final f...
-
[10]
˜f(x) = f(x) for all x ∈ P
-
[11]
exactly n neurons of ˜f have breakpoint hyperplanes intersecting relint( P ), namely H1, . . . , Hn
-
[12]
the remaining N − n neurons have breakpoint hyperplanes disjoint from P . Write ˜f(x) = g(x) + h(x) for all x ∈ P, where g is the subnetwork consisting of the n visible neurons and h is the subnetwork consisting of the remaining N − n neurons. Then h is affine linear on P , since all of its breakpoint hyperplanes are disjoint from P . Moreover, g(x) = fθ(...
-
[13]
ϕ: Vfθ → VA is a map from the set of candidate bent hyperplanes of fθ to the set of hidden neurons of A such that for every edge ( u, v) ∈ Efθ, if ϕ(u) = (i, ℓ) and ϕ(v) = (j, k), then ℓ < k
-
[14]
s = {s(σ)}σ∈Bd−1 θ is an assignment of an activation pattern to each facet σ ∈ B d−1 θ . For such a configuration, we write φ: Bd−1 θ → VA with φ(σ) := ϕ(π(σ)), where π : Bd−1 θ → Vfθ maps a facet to its unique candidate bent hyperplane. Definition C.2. Let (ϕ, s) be a discrete fiber configuration for fθ with respect to A, and let φ(σ) = ϕ(π(σ)) as above....
-
[15]
the facet σ is contained in the bent hyperplane of the neuron φ(σ) in the realization η, and 42
-
[16]
Definition C.3 (Configuration variety)
the activation pattern induced by η on σ is equal to s(σ). Definition C.3 (Configuration variety). For an architecture A and a discrete fiber configuration ( ϕ, s) for fθ, let φ(σ) = ϕ(π(σ)) for all σ ∈ B d−1 θ . The configuration variety V(ϕ,s) ⊆ ΘA × RBd−1 θ × RBd−1 θ is the algebraic variety in the variables η = (W (ℓ), b(ℓ))ℓ∈[L+1] and (λσ, δσ)σ∈Bd−1 ...
-
[17]
Geometric Alignment: gσ(η) = δσλσaσ and tσ(η) = δσλσβσ
-
[18]
Tropical Weight Matching: λσvσ(η) = cθ(σ)
-
[19]
Sign Equation: δ2 σ = 1. For fixed activation patternss(σ), all expressions gσ(η), tσ(η), and vσ(η) are polynomial in the parameters η. Hence the above equations define an algebraic variety. We denote by πA(V(ϕ,s)) the projection onto Θ A and call this the configuration set. For a CPWL function f and an architecture A, let ˜S(f, A) = {η ∈ ˜ΘA | f = fη} be...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.