Recognition: unknown
BIT.UA-AAUBS at ArchEHR-QA 2026: Evaluating Open-Source and Proprietary LLMs via Prompting in Low-Resource QA
Pith reviewed 2026-05-07 16:40 UTC · model grok-4.3
The pith
Domain-adapted open-source LLMs can match proprietary models in clinical question answering through optimized prompt engineering in low-resource settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Without access to training data or the ability to update model weights due to privacy regulations, carefully designed prompts applied to domain-adapted open-source LLMs enable performance that rivals or approaches that of proprietary models in clinical question answering tasks, as shown by leading results in key subtasks of the shared task.
What carries the argument
Prompt engineering strategies including task decomposition, Chain-of-Thought, in-context learning, majority voting, and LLM-as-a-judge ensembling, applied without any fine-tuning or weight updates.
If this is right
- Proprietary LLMs maintain strong performance across different prompt formulations in clinical domains.
- Domain-adapted open-source models become viable alternatives when paired with optimized prompts.
- Ensembling techniques such as majority voting and LLM judging enhance the robustness of predictions.
- Prompt-only methods allow effective solutions in data-scarce and privacy-sensitive healthcare QA scenarios.
Where Pith is reading between the lines
- Similar prompting techniques may apply to other domains with regulatory data restrictions, reducing dependence on proprietary services.
- The success of domain-adapted bases suggests that pre-adaptation is a key enabler for open-source competitiveness.
- Automatic metrics from the shared task may need supplementation with human expert review to confirm clinical safety.
- Future work could test these prompts on diverse clinical datasets beyond the shared task.
Load-bearing premise
That the shared task test set and automatic metrics accurately reflect real-world clinical performance and that LLM outputs contain no medically harmful inaccuracies or hallucinations.
What would settle it
Conducting a blind evaluation by medical experts on the generated answers for factual accuracy, safety, and alignment with patient records would reveal if the competitive performance translates to reliable clinical use.
Figures






read the original abstract
This paper presents the joint participation of the BIT.UA and AAUBS groups in the ArchEHR-QA 2026 shared task, which focuses on clinical question answering and evidence grounding in a low-resource setting. Due to the absence of training data and the strict data privacy constraints inherent to the healthcare domain (e.g. GDPR), we investigate the capabilities of Large Language Models (LLMs) without weight updates. We evaluate several state-of-the-art proprietary models and locally deployable open-source alternatives using various prompt engineering strategies, including task decomposition, Chain-of-Thought, and in-context learning. Furthermore, we explore majority voting and LLM-as-a-judge ensembling techniques to maximize predictive robustness. Our results demonstrate that while proprietary models exhibit strong resilience to prompt variations, domain-adapted open-source models (such as MedGemma 3 27B) achieve highly competitive performance when paired with the right prompt. Overall, our prompt-based approach proved highly effective, securing 1st place in Subtask 4 (evidence citation alignment) and 3rd place in Subtask 3 (patient-friendly answer generation). All code, results, and prompts are available on our GitHub repository: https://github.com/bioinformatics-ua/ArchEHR-QA-2026.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper reports the joint participation of the BIT.UA and AAUBS teams in the ArchEHR-QA 2026 shared task on clinical question answering and evidence grounding in a low-resource setting. Due to privacy constraints, the authors rely on prompting strategies with both proprietary and open-source LLMs, including task decomposition, Chain-of-Thought, in-context learning, majority voting, and LLM-as-a-judge ensembling. They highlight the resilience of proprietary models to prompt variations and the competitiveness of domain-adapted open-source models like MedGemma 3 27B, achieving 1st place in Subtask 4 (evidence citation alignment) and 3rd place in Subtask 3 (patient-friendly answer generation).
Significance. If the reported rankings and observations hold, this work demonstrates the viability of prompt engineering for clinical QA tasks where fine-tuning is prohibited by data privacy regulations. It provides evidence that carefully designed prompts can enable open-source models to compete with proprietary ones in specialized domains, which is valuable for reproducible and accessible AI in healthcare. The public release of code, results, and prompts further enhances its utility for the community.
major comments (2)
- Abstract: the assertion that the prompt-based approach 'proved highly effective' and that domain-adapted models 'achieve highly competitive performance' is not accompanied by any numerical scores, ablation studies, or error analysis within the manuscript, forcing readers to consult the external leaderboard or GitHub for verification.
- The manuscript provides no detailed description of the exact prompt templates, the specific configurations for majority voting or LLM-as-a-judge ensembling, or the full list of evaluated models beyond the single example of MedGemma 3 27B; these omissions undermine the ability to reproduce or extend the comparative observations on prompt resilience.
minor comments (2)
- Abstract: the title references evaluation of 'Open-Source and Proprietary LLMs' but the text does not enumerate all models tested or provide a summary table of their relative performances across subtasks.
- Consider including a dedicated results section or table that reports the official shared-task metrics for each subtask and model-prompt combination to improve clarity and allow direct comparison with other participants.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address each major comment below and will incorporate changes to improve clarity and reproducibility.
read point-by-point responses
-
Referee: Abstract: the assertion that the prompt-based approach 'proved highly effective' and that domain-adapted models 'achieve highly competitive performance' is not accompanied by any numerical scores, ablation studies, or error analysis within the manuscript, forcing readers to consult the external leaderboard or GitHub for verification.
Authors: We agree that the abstract would be strengthened by direct numerical support. While the manuscript body reports our shared-task rankings and comparative observations, we will revise the abstract to include key performance scores for Subtasks 3 and 4. This will allow readers to assess effectiveness without external lookup. Ablation studies and error analyses appear in the results section; we will ensure they are clearly cross-referenced from the abstract in the revision. revision: yes
-
Referee: The manuscript provides no detailed description of the exact prompt templates, the specific configurations for majority voting or LLM-as-a-judge ensembling, or the full list of evaluated models beyond the single example of MedGemma 3 27B; these omissions undermine the ability to reproduce or extend the comparative observations on prompt resilience.
Authors: The manuscript already states that all prompts, code, results, and model lists are publicly released on GitHub to support full reproducibility. To further address self-containment, we will add an appendix in the revised version that includes representative prompt templates, exact configurations for majority voting and LLM-as-a-judge ensembling, and the complete list of evaluated models (both proprietary and open-source). revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a systems report documenting participation in the ArchEHR-QA 2026 shared task. It describes empirical evaluation of LLMs using prompting techniques (task decomposition, Chain-of-Thought, in-context learning, majority voting, LLM-as-a-judge) in a low-resource setting with no training data or weight updates. Central claims consist of observed performance rankings (1st in Subtask 4, 3rd in Subtask 3) and comparative statements about prompt resilience and model competitiveness, all directly verifiable against the official shared-task leaderboard and metrics. No equations, derivations, fitted parameters, or load-bearing self-citations appear; the work contains no predictive modeling or theoretical chain that could reduce to its own inputs by construction. The absence of any such structure makes circularity impossible.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Patients increasingly seek to understand their health conditions and clinical course by review- ing their electronic health records (EHRs). How- ever,clinicalnotesarenotoriouslycomplex,lengthy, and filled with medical jargon, making it difficult for patients to extract clear, accurate answers to their questions. The ArchEHR-QA 2026 (Soni and ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
LLM-as-a-judge
Background Large Language Models in Clinical NLP.Until re- cently, state-of-the-art clinical natural language pro- cessing relied heavily on domain-specific, encoder- only architectures, such as ClinicalBERT (Huang et al., 2019), which required extensive supervised fine-tuning. Recently, the paradigm has shifted to- ward generative LLMs. Models such as GP...
2019
-
[3]
mini- malandsufficient
Methodology Given the extreme low-resource constraints of this competition, comprising a development set of only 20 samples, our methodology strictly uti- lizespromptengineeringovertraditionalfine-tuning. Across the pipeline, each of the four Subtasks in- corporates an LLM component. To quantify the performance gap between state-of-the-art propri- etary m...
2000
-
[4]
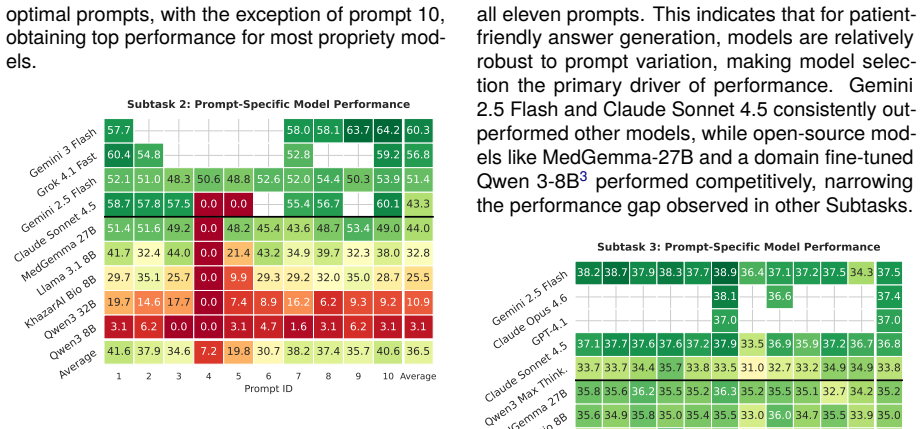
Results We employed a two-stage evaluation methodology across all four Subtasks. In the initial stage, we conducted extensive validation on the 20-case de- velopment set, evaluating a representative, though non-exhaustive, pool of state-of-the-art proprietary models (e.g., Gemini 3 Flash (Doshi and The Gem- ini Team, 2025), Gemini 2.5 Flash (Comanici et a...
2025
-
[5]
Why is he not eatin feeling weak and shakey loosin weight
Error Analysis Subtask 1: Question Interpretation Error Analy- sis.The model occasionally failed to transform pa- tient narratives into professional clinical queries. In Case 129, it generated an informal, query with lots of spelling errors (“Why is he not eatin feeling weak and shakey loosin weight...”) rather than the re- quired concise clinical formula...
-
[6]
Our findings high- lightseveralkeydynamicsregardingmodelscaling, open-source viability, and the practical trade-offs of ensemble methodologies in clinical applications
Discussion In this work, we aimed to evaluate the limits of LLMs in the extreme low-resource biomedical set- ting of the ArchEHR competition, relying primarily on prompt engineering and model selection rather than supervised fine-tuning. Our findings high- lightseveralkeydynamicsregardingmodelscaling, open-source viability, and the practical trade-offs of...
2024
-
[7]
Conclusion This study investigated the efficacy of LLMs in the extreme low-resource clinical setting of the ArchEHRcompetition. Bysystematicallyevaluating zero-shot, few-shot, and CoT prompting strategies alongside ensemble methodologies, we demon- strated that state-of-the-art LLMs can achieve highly competitive performance across complex biomedical NLP ...
-
[8]
Limitations While our work showed good results, this study has several notable limitations. First, due to the ex- treme low-resource nature of the shared task (only 20 development cases), there is a persistent risk that our few-shot prompts and ensemble configu- rations are partially overfit to the development dis- tribution, despite our efforts to utiliz...
-
[9]
human-in-the-loop
Ethical Considerations The deployment of generative LLMs in clinical set- tingscarriesprofoundethicalimplications, primarily concerning patient safety and data privacy. Gen- erative models are inherently prone to hallucina- tion. While our system achieved high precision in evidence alignment (Subtask 4) and grounding (Subtask 3), the risk of clinical hall...
-
[10]
Acknowledgments This work was funded by FEDER - Fundo Europeu de Desenvolvimento Regional funds through Programa Regional do Centro, within project CENTRO2030-FEDER-02595400 and by the Foundation for Science and Tech- nology (FCT) through the contract https: //doi.org/10.54499/UID/00127/2025. Richard A. A. Jonker is funded by the FCT doctoral grant PRT/BD...
-
[11]
Bibliographical References 104th United States Congress. 1996. Health Insur- ance Portability and Accountability Act of 1996 (HIPAA). Public Law 104-191, 110 Stat. 1936. Anthropic. 2025. Introducing claude sonnet 4.5. Anthropic News. Accessed: 2026-03-10. TomBBrown,BenjaminMann,NickRyder,Melanie Subbiah,JaredKaplan,PrafullaDhariwal,Arvind Neelakantan, Pra...
work page internal anchor Pith review arXiv 1996
-
[12]
Tuning language models as training data generators for augmentation-enhanced few-shot learning. InInternational Conference on Machine Learning, pages 24457–24477. PMLR. OpenAI. 2025. Introducing gpt-4.1 in the api. Ope- nAI Blog. Accessed: 2026-03-10. Qwen Team. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388. PranabSahoo,AyushKumarSingh,Srip...
work page internal anchor Pith review arXiv 2025
-
[13]
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
A systematic survey of prompt engineer- ing in large language models: Techniques and applications.arXiv preprint arXiv:2402.07927, 1. Maximilian Schall and Gerard de Melo. 2025. The hiddencostofstructure: Howconstraineddecod- ing affects language model performance. InPro- ceedings of the 15th International Conference on Recent Advances in Natural Language...
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.