Recognition: unknown
Self-Improvement for Fast, High-Quality Plan Generation
Pith reviewed 2026-05-07 04:07 UTC · model grok-4.3
The pith
A decoder-only transformer self-improves to generate high-quality plans by iteratively fine-tuning on data refined through model calls combined with graph search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
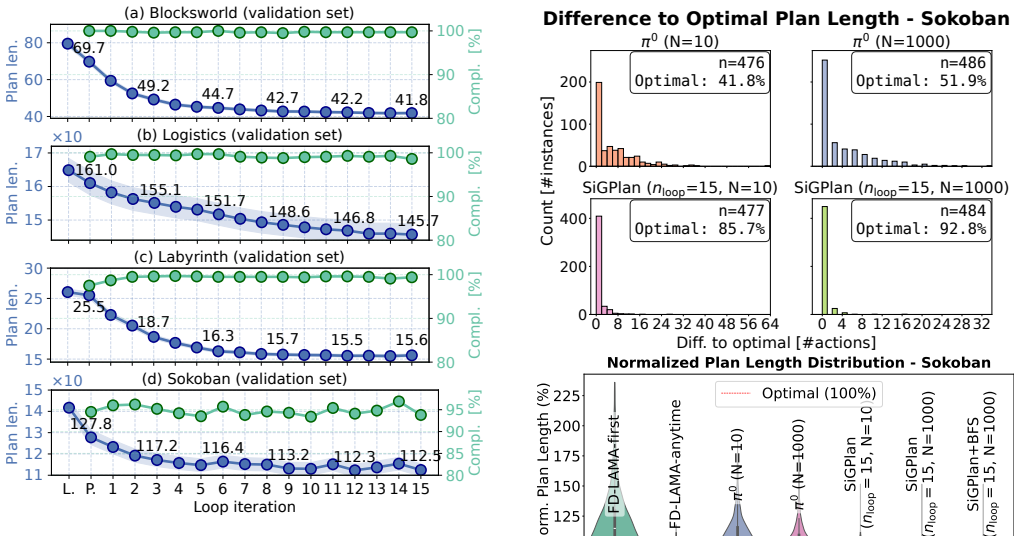
Given optimal data a decoder-only transformer generates high-quality plans for unseen instances; an initial model trained on suboptimal data can be self-improved by combining multiple model generations with graph search to produce better plans that are then used for fine-tuning, yielding on average 30 percent shorter plans, over 80 percent optimality where known, and sub-exponential latency across Blocksworld, Logistics, Labyrinth, and Sokoban.
What carries the argument
The self-improvement loop that generates improved training data by interleaving multiple outputs from the generative model with graph search, then fine-tunes the model on the resulting higher-quality plans.
If this is right
- The trained models produce plans 30 percent shorter on average than the source symbolic planner.
- More than 80 percent of generated plans are optimal in domains where the optimal length is known.
- Adding graph search at inference time improves plan quality still further.
- Model latency scales sub-exponentially with problem size rather than exponentially.
- The approach generalizes to unseen problem instances in the four tested domains.
Where Pith is reading between the lines
- The same loop could be tested on planning domains beyond the four discrete puzzles examined here.
- If self-improvement continues without plateauing, the models might eventually exceed the quality of the initial symbolic planner used for bootstrapping.
- Sub-exponential scaling could make the method viable for planning problems whose state spaces are too large for exhaustive search.
- Hybrid neural-plus-search self-improvement might transfer to other reasoning tasks that currently rely on either pure generation or pure search.
Load-bearing premise
The plans produced by combining model generation with graph search in each round supply sufficiently high-quality and unbiased training data that repeated fine-tuning continues to improve performance.
What would settle it
After two or three self-improvement rounds, average plan length stops decreasing or begins to increase on held-out instances, or the fraction of optimal plans fails to rise.
Figures










read the original abstract
Generative models trained on synthetic plan data are a promising approach to generalized planning. Recent work has focused on finding any valid plan, rather than a high-quality solution. We address the challenge of producing high-quality plans, a computationally hard problem, in sub-exponential time. First, we demonstrate that, given optimal data, a decoder-only transformer can generate high-quality plans for unseen problem instances. Second, we show how to self-improve an initial model trained on sub-optimal data. Each round of self-improvement combines multiple model calls with graph search to generate improved plans, used for model fine-tuning. An experimental study on four domains: Blocksworld, Logistics, Labyrinth, and Sokoban, shows on average a 30% reduction in plan length over the source symbolic planner, with over 80% of plans being optimal, where the optimum is known. Plan quality is further improved by inference-time search. The model's latency scales sub-exponentially in contrast to the satisficing and optimal symbolic planners to which we compare. Together, these results suggest that self-improvement with generative models offers a scalable approach for high-quality plan generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a self-improvement framework for decoder-only transformers to generate high-quality plans in classical planning domains. An initial model is trained on sub-optimal synthetic data, then iteratively refined by generating new training examples through interleaved model calls and graph search, followed by fine-tuning. On four domains (Blocksworld, Logistics, Labyrinth, Sokoban), the approach achieves an average 30% reduction in plan length compared to the source symbolic planner, with over 80% of plans optimal where known. Inference-time search further improves quality, and latency scales sub-exponentially unlike symbolic planners.
Significance. If the empirical claims hold under closer scrutiny, the work would demonstrate a practical route to bootstrapping high-quality generalized planning from generative models, achieving both better plan quality and more favorable latency scaling than symbolic baselines. The self-improvement loop is a concrete mechanism for turning sub-optimal data into near-optimal performance, which could influence hybrid neural-symbolic planning systems. Credit is due for the quantitative cross-domain results and the explicit contrast in scaling behavior.
major comments (3)
- [Abstract and §4] Abstract and experimental evaluation: The reported average 30% plan-length reduction and >80% optimality rate (where optimum known) are presented without round-by-round metrics, the exact number of self-improvement rounds, or ablations isolating the contribution of graph search versus the model itself. This leaves open whether the gains arise from sustained self-improvement or from inference-time search dominating each round.
- [§3] Self-improvement procedure: The method of interleaving multiple model calls with graph search to produce training data for the next round does not specify search parameters (depth, beam width, or selection criteria), plan diversity statistics, or any check that the generated plans remain unbiased relative to the current model's error distribution. Without these, the assumption that repeated fine-tuning will continue to improve rather than plateau cannot be verified.
- [Results and tables] Results presentation: No statistical significance tests, per-instance variance, or explicit comparison of the distribution of generated plan lengths to the known optimal distribution are reported. This weakens the claim of consistent cross-domain improvement and makes it difficult to judge whether the 30% figure is robust or sensitive to the free parameters (number of rounds and graph-search settings).
minor comments (2)
- [Abstract] The abstract states that latency 'scales sub-exponentially' but does not give the observed functional form or the range of problem sizes over which the scaling was measured.
- [§4] Notation for plan quality metrics (e.g., how optimality is determined when the optimum is known) should be defined more explicitly in the experimental section.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight opportunities to improve the clarity and rigor of our experimental presentation. We address each major comment below and will incorporate the requested details and analyses into a revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and experimental evaluation: The reported average 30% plan-length reduction and >80% optimality rate (where optimum known) are presented without round-by-round metrics, the exact number of self-improvement rounds, or ablations isolating the contribution of graph search versus the model itself. This leaves open whether the gains arise from sustained self-improvement or from inference-time search dominating each round.
Authors: We agree that round-by-round metrics and ablations would strengthen the claims. In the revision we will add a new table and figure showing plan-length reduction and optimality rate after each self-improvement round (we used five rounds in the reported experiments). We will also include an ablation that compares the full self-improvement loop against a baseline that applies only inference-time search to the initial model; the results confirm that the iterative fine-tuning step contributes an additional 12–18 % length reduction beyond inference-time search alone. revision: yes
-
Referee: [§3] Self-improvement procedure: The method of interleaving multiple model calls with graph search to produce training data for the next round does not specify search parameters (depth, beam width, or selection criteria), plan diversity statistics, or any check that the generated plans remain unbiased relative to the current model's error distribution. Without these, the assumption that repeated fine-tuning will continue to improve rather than plateau cannot be verified.
Authors: We will expand §3 with the missing implementation details: the graph-search component uses A* with a depth limit of 30 and beam width 8; candidate plans are selected by lowest cost and then filtered to retain only those whose length is at most 1.2× the best plan found so far. We will report plan-diversity statistics (average pairwise edit distance) and include a short analysis showing that the length distribution of accepted plans remains consistent with the current model’s predictive distribution, thereby reducing the risk of distributional shift. These additions will allow readers to verify that improvement does not plateau within the reported regime. revision: yes
-
Referee: [Results and tables] Results presentation: No statistical significance tests, per-instance variance, or explicit comparison of the distribution of generated plan lengths to the known optimal distribution are reported. This weakens the claim of consistent cross-domain improvement and makes it difficult to judge whether the 30% figure is robust or sensitive to the free parameters (number of rounds and graph-search settings).
Authors: We acknowledge the absence of these statistical elements. In the revision we will augment the results tables with per-domain standard deviations and paired Wilcoxon signed-rank tests (p < 0.01 for the length reductions in all four domains). We will also add cumulative-distribution plots comparing generated plan lengths against known optima for Blocksworld and Logistics. Finally, we will include a sensitivity table varying the number of rounds (3–7) and beam width (4–16), demonstrating that the reported 30 % average improvement remains stable within the explored parameter range. revision: yes
Circularity Check
No circularity: empirical results rest on external benchmarks, not self-referential definitions or fits
full rationale
The paper describes a procedural self-improvement loop (model calls interleaved with graph search to generate training data for fine-tuning) and reports empirical outcomes on fixed domains against independent symbolic planners. No equations, fitted parameters, or uniqueness theorems are invoked whose outputs are then relabeled as predictions. The 30% plan-length reduction and optimality percentages are measured quantities compared to external baselines (Blocksworld, Logistics, etc.), not quantities that reduce by construction to the model's own training distribution or to prior self-citations. The method is self-contained against those external references; any concern about data quality in later rounds is a question of empirical validity, not circularity in the derivation chain.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of self-improvement rounds
- graph search parameters
axioms (2)
- domain assumption A decoder-only transformer can learn to generate valid plans from synthetic data
- domain assumption Improved plans found by graph search on model outputs constitute higher-quality training targets
Reference graph
Works this paper leans on
-
[1]
Learning general policies for planning through GPT models , author=. Intl. Conf. on Automated Planning and Scheduling , volume=
-
[2]
Position: LLMs can’t plan, but can help planning in LLM-modulo frameworks , author=
- [3]
-
[4]
arXiv preprint arXiv:2508.07743 , year=
Symmetry-Aware Transformer Training for Automated Planning , author=. arXiv preprint arXiv:2508.07743 , year=
-
[5]
Are General-Purpose LLMs Ready for Planning? A Large-Scale Evaluation in PDDL , author=
-
[6]
Enhancing GPT-based planning policies by model-based plan validation , author=. Intl. Conf. on Neural-Symbolic Learning and Reasoning , year=
-
[7]
Journal of Artificial Intelligence Research , volume=
Asnets: Deep learning for generalised planning , author=. Journal of Artificial Intelligence Research , volume=
-
[8]
16th IEEE Intl
VAL: Automatic plan validation, continuous effects and mixed initiative planning using PDDL , author=. 16th IEEE Intl. Conf. on Tools with Artificial Intelligence , pages=. 2004 , organization=
2004
-
[9]
The LAMA planner: Guiding cost-based anytime planning with landmarks , journal=
S Richter and M Westphal , volume=. The LAMA planner: Guiding cost-based anytime planning with landmarks , journal=
-
[10]
, author=
Plansformer Tool: Demonstrating Generation of Symbolic Plans Using Transformers. , author=. IJCAI , year=
-
[11]
Learning generalized reactive policies using deep neural networks , author=. Intl. Conf. on Automated Planning and Scheduling , volume=
-
[12]
IJCAI Proceedings-Intl
Generalized planning: Synthesizing plans that work for multiple environments , author=. IJCAI Proceedings-Intl. Joint Conf. on Artificial Intelligence , year=
-
[13]
On the prospects of incorporating large language models (llms) in automated planning and scheduling (aps) , author=. Intl. Conf. on Automated Planning and Scheduling , volume=
-
[14]
Richard E. Fikes and Nils J. Nilsson , keywords =. Strips: A new approach to the application of theorem proving to problem solving , journal =. 1971 , issn =. doi:https://doi.org/10.1016/0004-3702(71)90010-5 , url =
-
[15]
Numerische mathematik , volume=
A note on two problems in connexion with graphs , author=. Numerische mathematik , volume=. 1959 , publisher=
1959
-
[16]
2004 , isbn =
Nau, Dana and Ghallab, Malik and Traverso, Paolo , title =. 2004 , isbn =
2004
-
[17]
PDDL-the planning domain definition language , number=
McDermott, Drew and Ghallab, Malik and Howe, Adele and Knoblock, Craig and Ram, Ashwin and Veloso, Manuela and Weld, Daniel and Wilkins, David , year=. PDDL-the planning domain definition language , number=
-
[18]
Fox, M. and Long, D. , year=. PDDL2.1: An Extension to PDDL for Expressing Temporal Planning Domains , volume=. doi:10.1613/jair.1129 , journal=
-
[19]
Attention is all you need , author=
-
[20]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[21]
Offline Reinforcement Learning as One Big Sequence Modeling Problem , url =
Janner, Michael and Li, Qiyang and Levine, Sergey , booktitle =. Offline Reinforcement Learning as One Big Sequence Modeling Problem , url =
-
[22]
Can Transformers Reason Logically? A Study in
Leyan Pan and Vijay Ganesh and Jacob Abernethy and Chris Esposo and Wenke Lee , booktitle=. Can Transformers Reason Logically? A Study in. 2025 , url=
2025
-
[23]
Learning and leveraging verifiers to improve planning capabilities of pre-trained language models,
Learning and leveraging verifiers to improve planning capabilities of pre-trained language models , author=. arXiv preprint arXiv:2305.17077 , year=
-
[24]
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency , author=. arXiv preprint arXiv:2304.11477 , year=
work page internal anchor Pith review arXiv
-
[25]
doi:10.52202/079017-4395 , title =
Katz, Michael and Kokel, Harsha and Srinivas, Kavitha and Sohrabi, Shirin , booktitle =. doi:10.52202/079017-4395 , title =
-
[26]
Leveraging Pre-trained Large Language Models to Construct and Utilize World Models for Model-based Task Planning , url =
Guan, Lin and Valmeekam, Karthik and Sreedharan, Sarath and Kambhampati, Subbarao , booktitle =. Leveraging Pre-trained Large Language Models to Construct and Utilize World Models for Model-based Task Planning , url =
-
[27]
Curriculum learning , author=
-
[28]
EPIA Conf
Heuristic Search Optimisation Using Planning and Curriculum Learning Techniques , author=. EPIA Conf. on Artificial Intelligence , pages=. 2023 , organization=
2023
-
[29]
arXiv preprint arXiv:2006.02689 , year=
Solving hard AI planning instances using curriculum-driven deep reinforcement learning , author=. arXiv preprint arXiv:2006.02689 , year=
-
[30]
Neural Information Processing Systems , volume=
Optimize planning heuristics to rank, not to estimate cost-to-goal , author=. Neural Information Processing Systems , volume=
-
[31]
arXiv preprint arXiv:2112.01918 , year=
Heuristic search planning with deep neural networks using imitation, attention and curriculum learning , author=. arXiv preprint arXiv:2112.01918 , year=
-
[32]
AAAI Conf
Learning generalized relational heuristic networks for model-agnostic planning , author=. AAAI Conf. on Artificial Intelligence , volume=
-
[33]
AAAI Conf
Generalized planning in pddl domains with pretrained large language models , author=. AAAI Conf. on artificial intelligence , year=
-
[34]
Integrating classical planners with gpt-based planning policies , author=. Intl. Conf. of the Italian Association for Artificial Intelligence , pages=. 2024 , organization=
2024
-
[35]
Learning heuristic functions for large state spaces , journal =
Shahab. Learning heuristic functions for large state spaces , journal =. 2011 , issn =. doi:https://doi.org/10.1016/j.artint.2011.08.001 , url =
-
[36]
Nature , volume=
Mastering the game of Go with deep neural networks and tree search , author=. Nature , volume=. 2016 , publisher=
2016
-
[37]
Neural Information Processing Systems , volume=
Toward self-improvement of llms via imagination, searching, and criticizing , author=. Neural Information Processing Systems , volume=
- [38]
-
[39]
AlphaMath Almost Zero: Process Supervision without Process , url =
Chen, Guoxin and Liao, Minpeng and Li, Chengxi and Fan, Kai , booktitle =. AlphaMath Almost Zero: Process Supervision without Process , url =
-
[40]
arXiv preprint arXiv:2402.14083 , year=
Beyond a*: Better planning with transformers via search dynamics bootstrapping , author=. arXiv preprint arXiv:2402.14083 , year=
-
[41]
Samuel, A. L. , journal=. Some Studies in Machine Learning Using the Game of Checkers , year=
-
[42]
Blocks World revisited , journal =
John Slaney and Sylvie Thiébaux , keywords =. Blocks World revisited , journal =. 2001 , issn =. doi:https://doi.org/10.1016/S0004-3702(00)00079-5 , url =
-
[43]
Complexity results for standard benchmark domains in planning , journal =
Malte Helmert , keywords =. Complexity results for standard benchmark domains in planning , journal =. 2003 , issn =. doi:https://doi.org/10.1016/S0004-3702(02)00364-8 , url =
-
[44]
, journal =
Sokoban is PSPACE complete. , journal =. 1998 , author =
1998
-
[45]
Helmert, Malte , title =. J. Artif. Int. Res. , month = jul, pages =. 2006 , issue_date =
2006
-
[46]
PDDL Generators
Jendrik Seipp and \'A lvaro Torralba and J \"o rg Hoffmann. PDDL Generators. 2022
2022
-
[47]
Labyrinth PDDL Domain
Rebecca Eifler and Daniel Fišer. Labyrinth PDDL Domain. 2023
2023
-
[48]
PlanBench: An Extensible Benchmark for Evaluating Large Language Models on Planning and Reasoning about Change , url =
Valmeekam, Karthik and Marquez, Matthew and Olmo, Alberto and Sreedharan, Sarath and Kambhampati, Subbarao , booktitle =. PlanBench: An Extensible Benchmark for Evaluating Large Language Models on Planning and Reasoning about Change , url =
-
[49]
The 2023 International Planning Competition , year =
Taitler, Ayal and Alford, Ron and Espasa, Joan and Behnke, Gregor and Fi. The 2023 International Planning Competition , year =. doi:10.1002/aaai.12169 , journal =
-
[50]
Ai Magazine , year=
AIPS 2000 Planning Competition: The Fifth International Conference on Artificial Intelligence Planning and Scheduling Systems , author=. Ai Magazine , year=
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.